

中科院自动化所人工智能学术论坛总结
source link: https://breezedeus.github.io/2016/10/19/breezedeus-zdh60.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

10月17日,中科院自动化研究所庆祝建所60周年举办了人工智能学术论坛,论坛邀请人工智能相关领域的专家学者做主题学术报告。我们有幸到场聆听几位专家的报告。由于时间原因,只参加了下午3场报告,以下是我们对报告的感受和总结。
谭自忠(TJ Tarn):Next Big Things in Robotics and Automation
谭老师首先介绍了机器人的发展,新技术的应用使得机器人越来越精细,智能。硅谷带来的革命就是把原来大、贵、复杂的系统替换成小、便宜、高性能的微系统。微芯片能够感知、思考、行动甚至互相交流,最终它们将带来智能机器。

谭教授根据不同时期人机交互程度把机器人分为:工业机器人,服务机器人,合作机器人。 谭教授指出,未来机器人的一个发展方向是生物与机械的结合,它们在生物技术、环境、信息技术甚至新药物研发中都会有很好的应用。
李航:拥抱自然语言处理新时代
李老师的报告分成两部分,第一部分介绍人类语言的5个特性,这5个特性让自然语言处理很困难。虽然我们到现在都搞不清楚人脑是怎么处理语言的,但技术上还是可以做一些事让计算机看上去能理解一点人类语言,第二部分就是介绍目前技术上的一些方法。
一、人类语言的5个特性
在第一部分开始,李老师从规模,速度,计算模型,容量四个方面,对比人脑和计算机工作方式的不同:

李老师之后提出导致NLP很难的五个语言特性。第一个特性是人类语言不仅有很多语法规则,还有很多特例(不遵守语法规则)。人类语言是由成千上万的人在漫长的时间内逐步创建而成,很像现在维基百科的创建过程。正是由于这种多人长期的协作导致语言既有规则又有很多特例。

语言的第二个特点是递归性,也即可把短句通过递归的方式组合成很复杂的长句。(好像有本英文书就只有一个句子。)这个特点是由著名的乔姆斯基提出的。虽然很多动物如大猩猩也掌握简单的单词,但它们的语言并不具有递归性,所以其表达能力和人类语言不在一个层级上。更多介绍可见语言的对决:乔姆斯基攻防战。
语言的第三个特点是比喻性。通过比喻可以把多个不相关的概念组合起来产生新的概念。比如“在微信里潜水”就是组合了潜水和在微信中不说话的行为这两个原始概念,还有“上厕所”、“下厨房”也是通过比喻来组合不同的原始词汇。有小孩的朋友应该经常能听到小孩自创的一些比喻性说法。
语言的第四个特点是语言与世界外部知识是相关联的。这也是为什么现在大家都在搞知识图谱。 第五个特点是语言具有互动性。
这五个人类语言特性使得人类语言和计算机工作方式不同,从而导致了让计算机完全理解人类语言变成一大难题。虽然我们现在没法让计算机以人脑理解语言的机理去理解人类语言,但我们可以让计算机去模拟理解语言的结果。报告的第二部分,李老师提出了一些让计算机理解人类语言的技术策略。
二、让计算机理解人类语言的一些技术策略
第一种策略叫任务驱动策略(Task-Driven Strategy)。

比如我们可以把人类理解问题的机理简化,只保留计算机能处理的步骤。以QA为例,人类的处理逻辑包括问题分析、理解、推断、检索、决策、答复产生6个步骤,但我们可以把这个过程简化为分析、检索和答复产生3个步骤,这样计算机就可以解决QA问题了。

我们也可以通过限定任务所在领域来把计算机之前没法做的事变成它能做的。以多轮对话举例,虽然在开放领域很难做好,但是如果只是限制在特定领域,计算机就可能做的很好。我们的一个AI(www.yige.ai)平台就是为了帮助开发者创建特定领域的QA系统,大家可以尝试一下。
而且通过AI LOOP(系统-用户-数据-算法)我们可以持续优化计算机对人类语言的处理效果。
第二种策略叫融合策略(Hybrid Strategy)。我们可以将基于规则,基于统计和基于深度学习的NLP方法进行融合,不断提升计算机的自然语言处理能力。

颜水成:Facial Entertainment–Techniques and Applications
颜老师是国际知名计算机视觉与深度学习专家,现在是360人工智能研究院院长。他的报告主要包括两个方面:深度学习上的一些探索、人脸处理技术和产品。下面分别做简单介绍。
一、深度学习的探索
Network In Network (NIN)
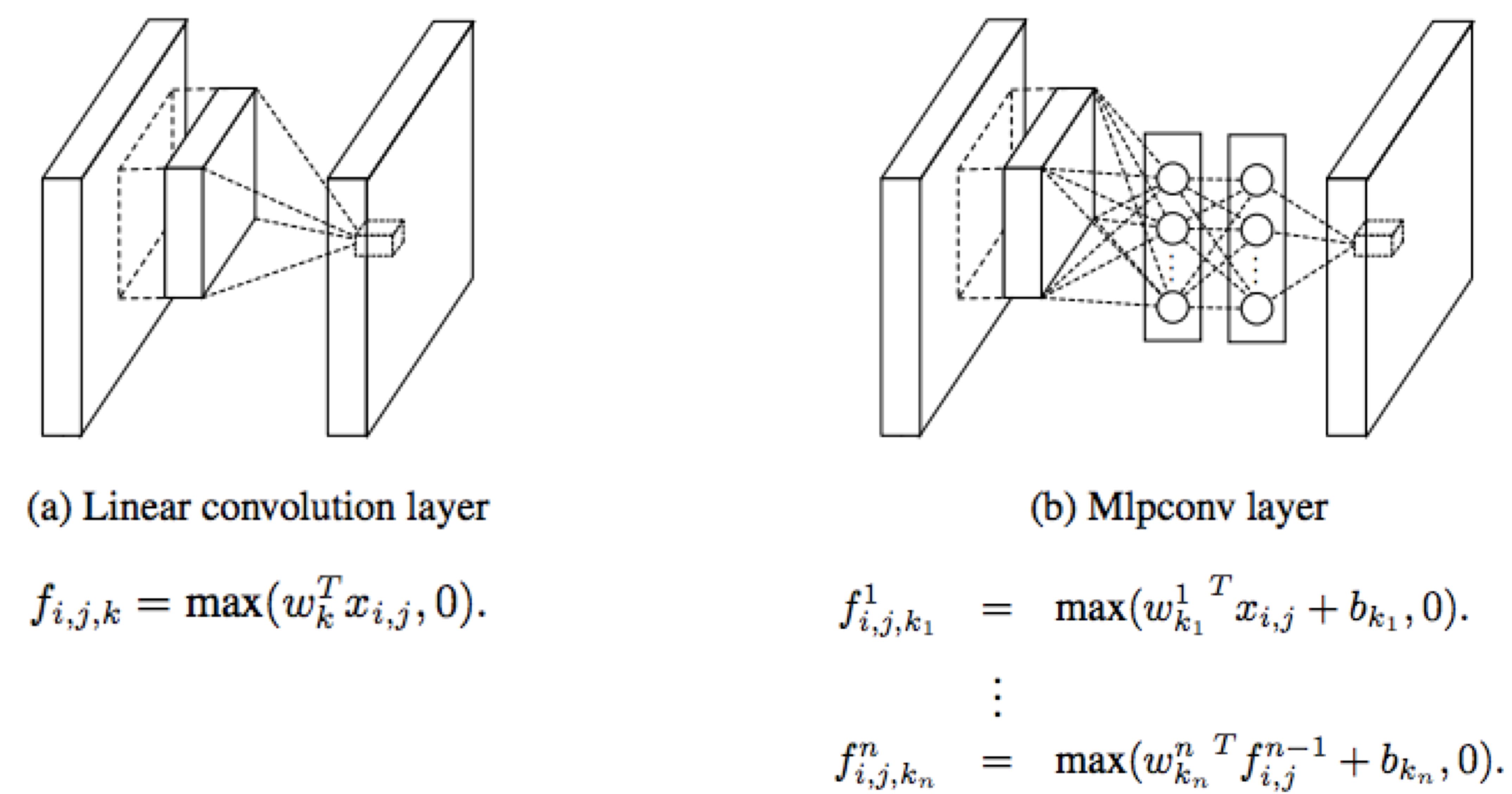
颜老师首先介绍了他们2年前的工作:Network In Network (NIN)。NIN主要包含了2个创新点,第一个是利用MLP模型代替原来卷积层的线性模型(见下图),提升卷积层的非线性性,从而提升其局部表达能力。这个被称为mlpconv层的新卷积层相当于先做一个一般的卷积,再做几个1x1的卷积(只改变filter的个数,不改变feature map的大小)。1x1卷积在很多模型都被使用,比如GoogleNet、ResNet,它有以下作用:
- 实现跨通道的交互和信息整合。
- 进行卷积核通道数的降维和升维,降低模型的参数数量。
更多细节可见这里。
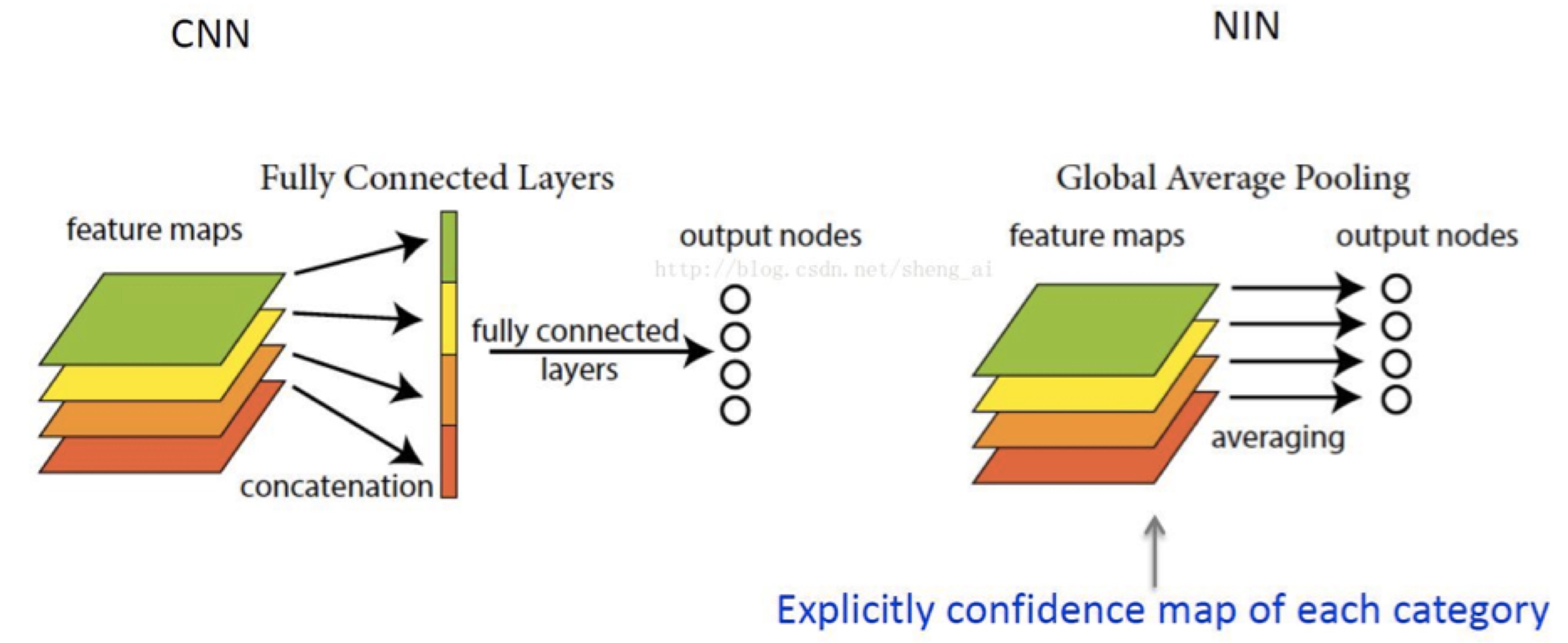
经过多次的卷积层后,最终产生的每个feature map都包含了很高层的全局信息,所以单独一个feature map就应该能代表一个类的特征了。NIN的第二个创新点是把CNN里顶层的全连接层替换为全局平均池化层(见下图,图片来自于这里)。以分类问题为例,最后一层卷积层产生的feature map数量和类别数量相同,在每个feature map上取平均值,这个平均值就代表了对应类的信息,把平均值最后放到softmax函数里就得到此类的概率值。原始CNN中大部分的参数都来自于顶层的全连接层。NIN通过引入全局平均池化层降低了模型参数数量。在保持精度的情况下,NIN能把参数数量压缩为原始CNN的1/10。
More is Less
颜老师他们观察到,很多情况下超过40%的模型结点在ReLU之前获得的值都小于0,所以经过ReLU (max(x, 0))后这些结点都变成0了,它们具体的取值毫无意义。

如果用很低的计算量我们就能预估出哪些结点的取值会小于0,在卷积时就不用再花更多时间去计算它们的精确取值了。基于这个逻辑,颜老师他们提出在原来网络的基础上增加1x1的卷积层,新模型的输出为原模型的输出(逐元素)乘以1x1卷积层的输出。如果1x1卷积层的输出为0,那原始卷积层对应结点就不用再计算了,从而达到降低计算量的作用。这就是所谓的用更复杂的模型结构(More)来获取更低的计算量(Less)。这种方法在很多模型上能达到20%的加速,在某些模型上甚至加速近50%。据说颜老师的这个工作还没正式发表。。。

More is Less这种加速思路比较适合计算能力较差的设备,比如手机。对于计算能力较强的机器,更高模型复杂度会带来更多的调度等开销,最终导致加速效果不明显。
二、人脸处理技术和产品
接下来,颜老师介绍了他们之前在化妆、美颜和人脸增强方面的一些工作。这部分既有技术含量又很实用,相信不会有人不感兴趣。
怎么化妆能变身为女神
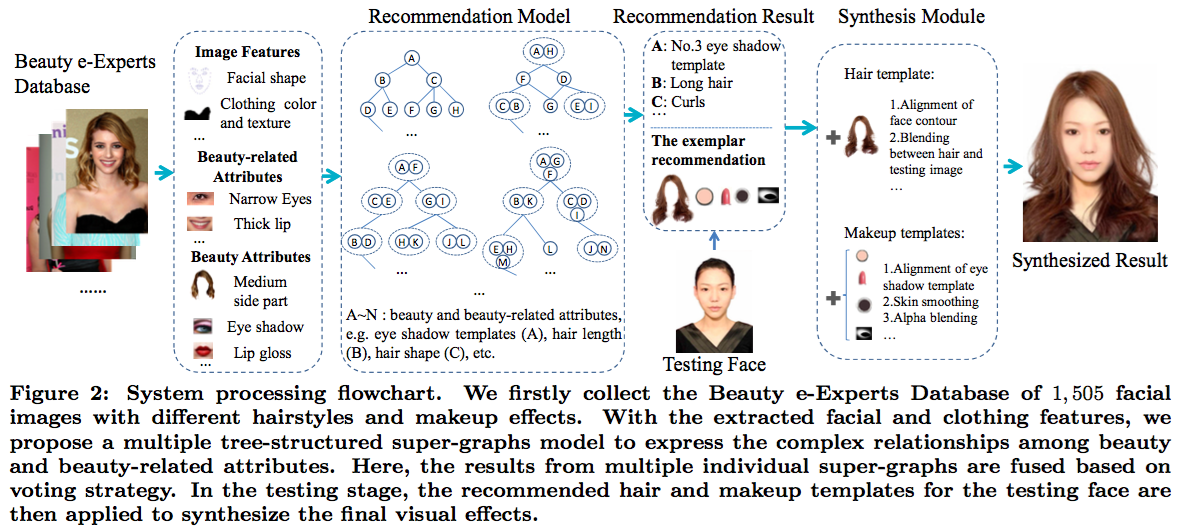
爱美之心姑娘皆有之,但不是每个姑娘都知道怎么化妆。颜老师做了一个产品叫“Beauty e-Expert”,用户只要上传一张人脸照片,Beauty e-Expert会根据用户的脸型和衣服给用户推荐合适的底妆、唇膏、眼影和发型,并把这些推荐的化妆术合成到用户上传的照片上,让用户立刻看到化妆后的效果图。合成部分主要难点在于面部对准,需要准确把假发放到头上,唇膏涂到嘴唇上。算法细节可以参考他们2013年的论文“Wow! You Are So Beautiful Today!”。下图给出了系统处理流程和合成效果。

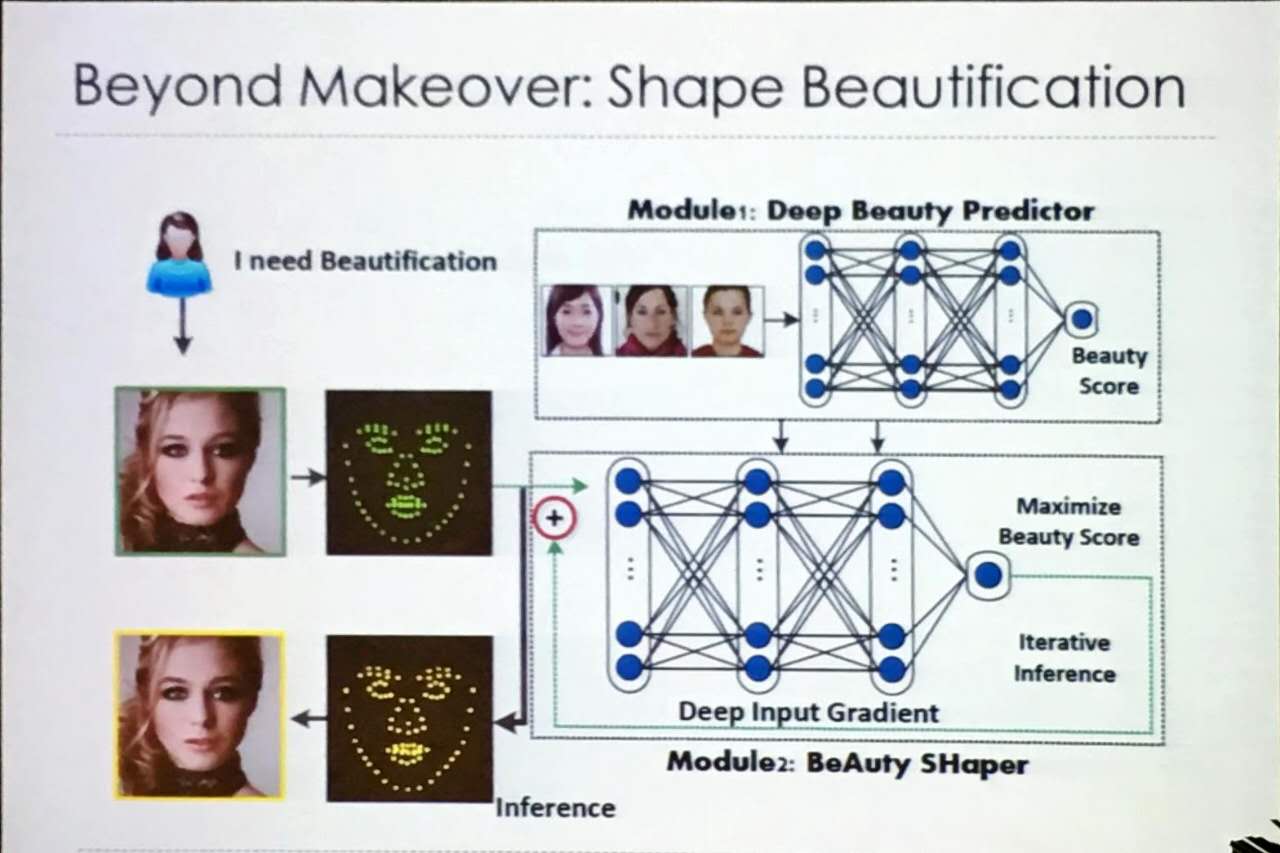
美颜(Facial Beautification)
传统美颜方法是先找脸部的各种特征点,然后对五官做调整,从而达到美颜的效果。颜老师他们提供了一个美颜新思路。首先训练一个深度神经网络预测一张脸型图片的buauty score,预测时把输入作为参数优化,使用梯度上升算法得到更高的beauty score,优化后的输入即为美颜后的结果。
人脸增强(Facial AR)
这部分颜老师演示了实时脸部替换的效果,即把一个人的人脸实时放到另一个头上的效果。以后跟姑娘视频聊天时你可以换个脸了。系统主要用到的技术包含人脸检测、面部跟踪与对标、人脸替换。具体可参考他们2016年刚发表的论文“A Live Face Swapper”。

欢迎大家关注一个AI微信公众号,第一时间获取一个AI的最新消息。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK