

UNREAL(UNsupervised REinforcement and Auxiliary Learning)算法
source link: https://gyh75520.github.io/2018/08/30/Unreal/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

UNREAL(UNsupervised REinforcement and Auxiliary Learning)算法
作者通过添加辅助任务增强了A3C(Asynchronous Actor Critic)算法。这些辅助任务共享网络参数,但是它们的价值函数是通过 n-step 的 off-policy 的 Q-Learning 来学习的。辅助任务只用于学习更好的表示,而不直接影响主任务的任务control。这种改进被称为UNREAL(Unsupervised Reinforcement and Auxiliary Learning),在性能和训练效率方面优于A3C。
A3C 算法充分使用了 Actor-Critic 框架,是一套完善的算法,因此,我们很难通过改变算法框架的方式来对算法做出改进。UNREAL 算法在 A3C 算法的基础上,另辟蹊径,通过在训练 A3C 的同时,训练多个辅助任务来改进算法。UNREAL 算法的基本思想来源于我们人类的学习方式。人要完成一个任务,往往通过完成其他多种辅助任务来实现。比如说我们要收集邮票,可以自己去买,也可以让朋友帮忙获取,或者和其他人交换的方式得到。UNREAL 算法通过设置多个辅助任务,同时训练同一个 A3C 网络,从而加快学习的速度,并进一步提升性能。
UNREAL 算法本质上是通过训练多个面向同一个最终目标的任务来提升行动网络的表达能力和水平,符合人类的学习方式。值得注意的是,UNREAL 虽然增加了训练任务,但并没有通过其他途径获取别的样本,是在保持原有样本数据不变的情况下对算法进行提升,这使得 UNREAL 算法被认为是一种无监督学习的方法。基于 UNREAL 算法的思想,可以根据不同任务的特点针对性地设计辅助任务,来改进算法。
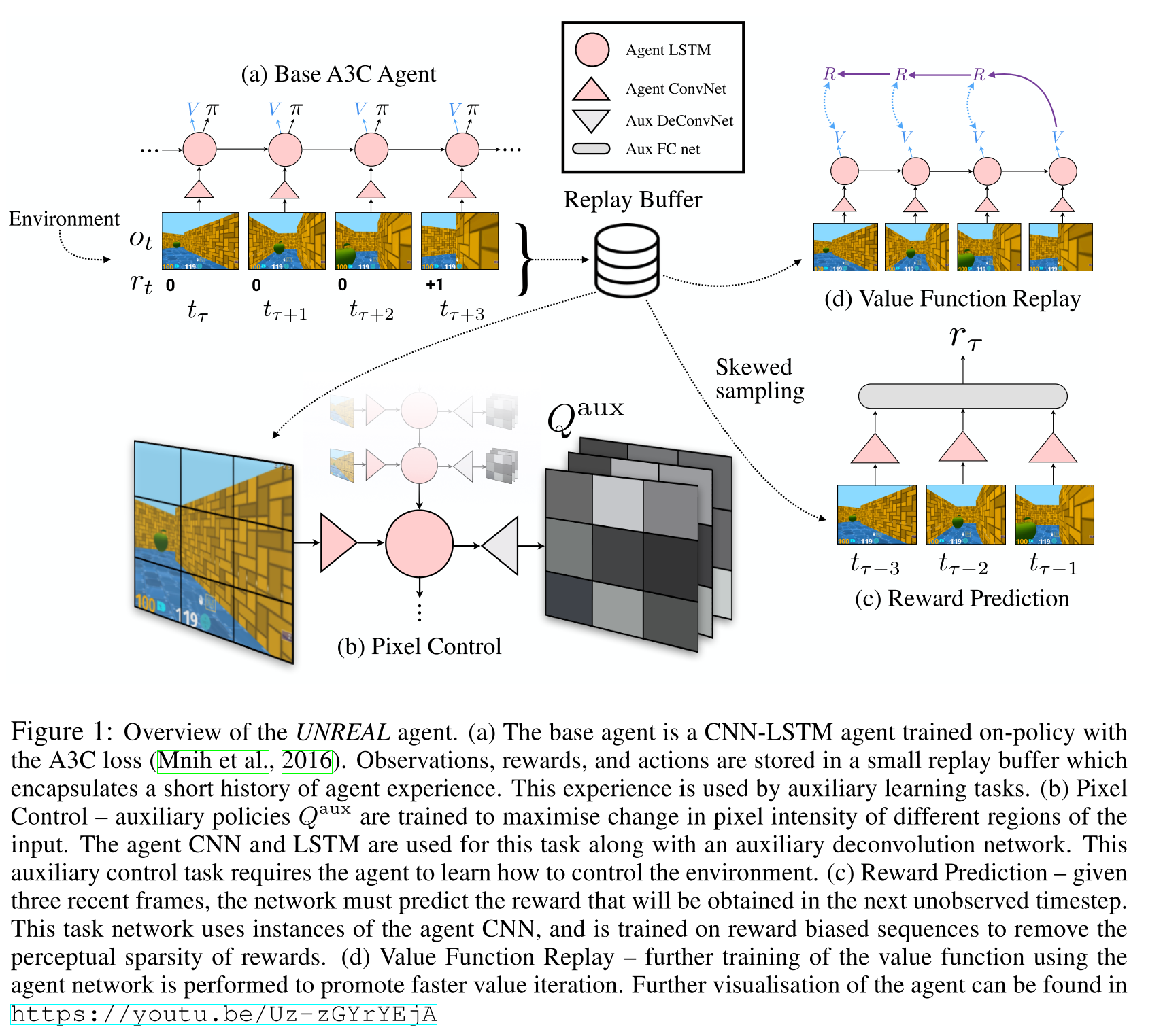
更详细的网络结构(来自 https://github.com/miyosuda/unreal) :
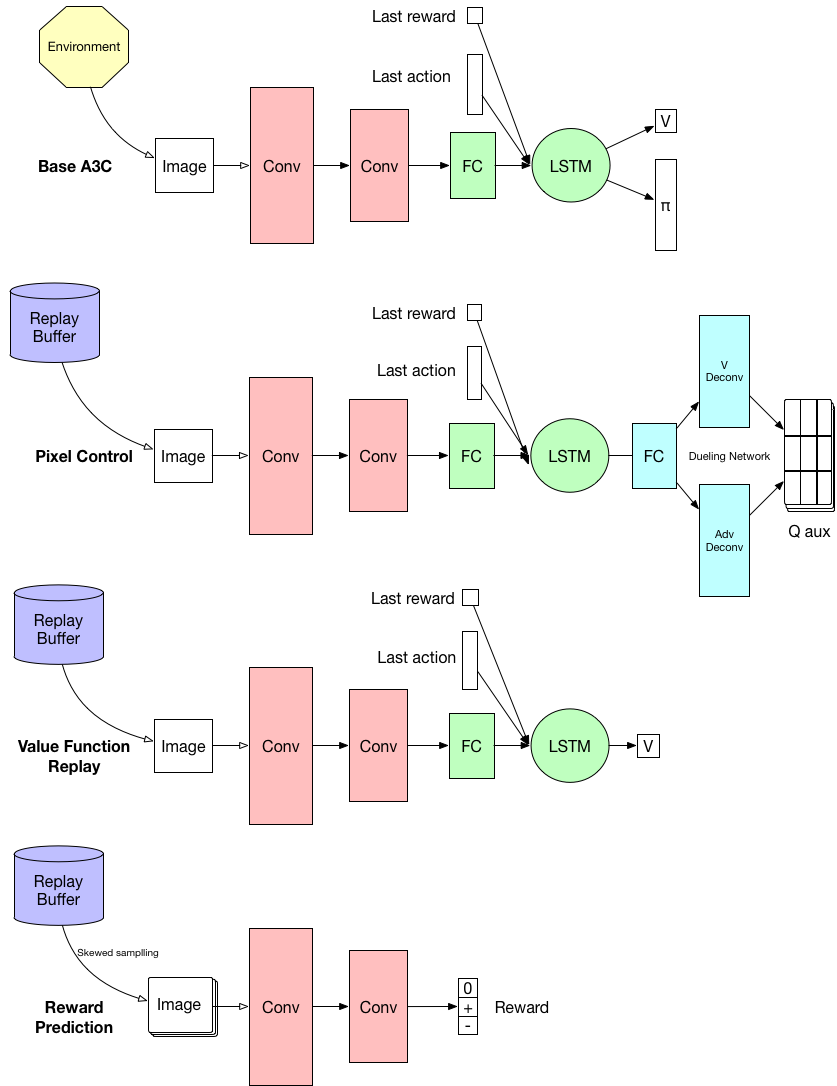
AUXILIARY CONTROL TASKS
包括像素控制和隐藏层激活控制。
像素控制(Pixel Control)
像素控制是指控制输入图像的变化,使得图像的变化最大。因为图像变化大往往说明Agent在执行重要的环节,通过控制图像的变化能够改善动作的选择。
如何定义该任务的 pseudo-reward:
将网络输入的 84x84 RGB 图片裁剪成 80x80 的图片,将裁剪的图片以 4x4 cell 为单位分成 20x20 个 gird,每个 cell 的 reward 通过计算每个pixel 和 channels 的像素差的平均值得到。网络最后的输出是 NactNact x20x20 的 QauxQaux。
具体的网络结构参照图
特征控制(Feature Control)
隐藏层激活控制则是控制隐藏层神经元的激活数量,目的是使其激活量越多越好。这类似于人类大脑细胞的开发,神经元使用得越多,可能越聪明,也因此能够做出更好的选择。
类似于 Pixel Control 对 pseudo-reward 的定义,我们计算隐藏层的神经元激活数量作为reward。网络最后的输出也是 NactNact x20x20 的 QauxQaux。
为了更好的理解辅助控制任务,我们和另外两种很自然的辅助任务的方法做比较。
第一个baseline是pixel reconstruction loss,类似于DSR中对 ϕ(si)ϕ(si)进行反卷积,能够使得网络能够更好的区分不同的状态。
第二个baseline是input change prediction loss,这个可以被看作是预测立即的reward,reward的计算类似Pixel Control。( pixel control 是control任务,它预测的是Q值)。
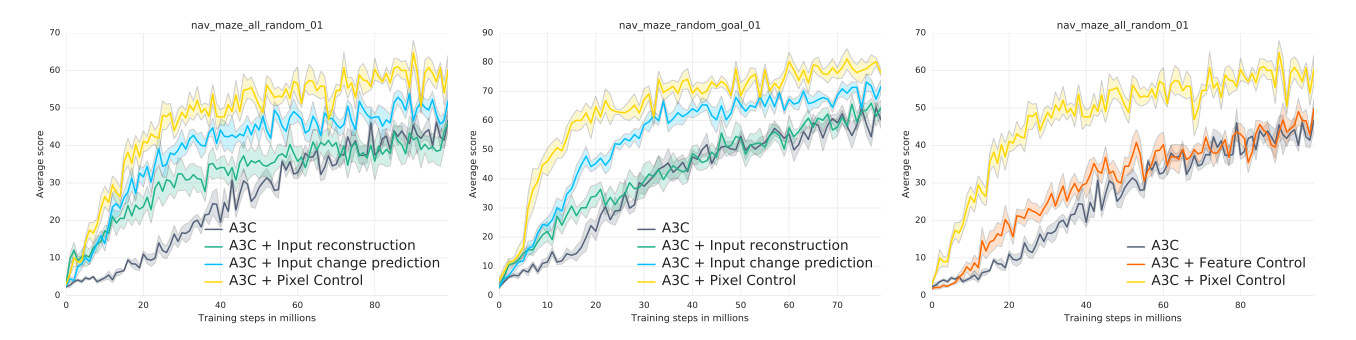
从上图可以看出,pixel reconstruction 可以加速初始的学习,但是会损坏最后的得分。因为它过于专注于重建视觉输入中不相关的部分而没有专注于和奖励有关的部分。
AUXILIARY REWARD TASKS
因为在很多场景下,回馈 r 并不是每时每刻都能获取的(比如在 Labyrinth 中吃到苹果才能得1分),所以让神经网络能够预测回馈值会使其具有更好的表达能力。
为了学习到最大化reward的policy,Agent 需要能识别出那些可能会产生高 reward 的状态。对 rewarding 状态有良好表示的 Agent能够学习到更好的价值函数,这也意味着Agent能够更容易和更好的学习到策略。
与学习价值函数和学习策略不同,Reward Prediction 任务仅仅只是用来优化Agent 的 features,因此加入 Reward Prediction 不会对原有的价值函数和策略产生偏差。
在 UNREAL 算法中,使用历史连续多帧的图像输入来预测下一步的 reward 作为训练目标,这是一个三分类任务,预测值为 +,0,- 的概率。至关重要的是,由于奖励往往是稀疏的,我们使用 skewed 技术使得 P(r!=0)=P(r=0)=0.5P(r!=0)=P(r=0)=0.5。能这么做的原因,我猜测是因为这只是一个监督学习。我们只需要将 replay memory 分割成两个集合,分别是reward = 0 的样本和 reward != 0 的样本。
另一个细节是,这里并没有用 LSTM。作者也解释了原因,大概是说这个 auxiliary task,reward prediction 的目的是关注 immediate reward, rather than long-term returns。
Value Function Replay
相当于从replay buffer中重新采样进行 V 值函数回归。这一部分相当于将A3C输出的V值网络训练的更好,V值网络更好,策略网络也会更好。
UNREAL
结合上述的辅助任务,得到UNREAL算法,Loss函数如下:
其中 VR = Value Function Replay, PC = Pixel Control, RP = Reward Prediction。
在实际的训练中,Loss被拆分成单独的部分训练。
实验环境
Atari 和 3D迷宫游戏 Labyrinth
- Agent 训练使用的是 n-step Returns,n = 20
- Replay Buffer 的大小 = 2000
- 辅助控制任务使用 off-polcy RL 算法(例如,n-step Q-Learning),这样就可以使用经验回放
Labyrinth:
38% -> 83% human-normalized score.
Significantly faster learning, 11x across all levels.
Atari:
表现更好,更robust。
REF: Jaderberg M, Mnih V, Czarnecki W M, et al. Reinforcement Learning with Unsupervised Auxiliary Tasks[J]. 2016.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK