

MADDPG(Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments...
source link: https://gyh75520.github.io/2018/11/19/MADDPG/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

MADDPG(Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments)算法
由于环境状态由多个Agent的行为共同决定,本身具有不稳定性(non-stationarity),这就导致 Q-learning 算法很难训练,policy gradient 算法的方差会随着智能体的增加变得更大。
本文提出了一种AC方法的变体 MADDPG ,每个 agent 学习的过程中都可以知晓其他 agent 的策略,进行中心化训练和非中心化执行,取得了显著效果。
在 multi-agent 环境中,大多数的设置是 agent 不能直接知道其他 agent的 action,policy 等信息的,
传统强化学习方法很难用在multi-agent环境上,一个主要的原因是每个agent的策略在训练的过程中都是不断变化的,这导致对每个agent个体来说,环境都是不稳定的,即有P(s‘|s,a,π1,…,πN)≠P(s‘|s,a,π‘1,…,π‘N)P(s‘|s,a,π1,…,πN)≠P(s‘|s,a,π1‘,…,πN‘),对任意的πi≠π‘iπi≠πi‘。
某种程度上来说,一个agent根据这种不稳定的环境状态来优化策略是毫无意义的,在当前状态优化的策略在下一个变化的环境状态中可能又无效了。这就导致不能直接使用经验回放(experience replay)的方法进行训练,这也是Q-learning失效的原因。对于policy gradient方法来说,随着agent数量增加,环境复杂度也增加,这就导致通过采样来估计梯度的优化方式,方差急剧增加。
这些问题归根到底,是因为agent之间没有交互,不知道队友或者对手会采取什么策略,导致只根据自己的情况来选择动作,而忽略了整体。作者提出的解决方法也很简单:采用中心化的训练和非中心化的执行。即在训练的时候,引入可以观察全局的critic来指导actor训练,而测试的时候只使用有局部观测的actor采取行动。
既然在实际中不知道其他 agent 的信息,但是其他的 agent 的信息能够很好的帮助学习,很自然的就会想:那么我们就在训练的时候使用这些信息,实际运用的时候的不用这些信息,那就不就很自然地学习出一个更好的 agent 了。
更进一步:我们想要在off-line的时候利用更多的信息学习出一个拥有比较好policy的agent,但是为了能够在实际的设置中使用,这个agent的policy的输入与输出在训练与实际使用的时候应该一样,所以无法直接把额外的信息直接结合在policy的输入中,那么有一种想法就是这些额外的信息既然无法直接用,那么就拿来做更准确的梯度的估计,那么很直观的想法就是用AC。
主要的原因是:AC分为actor,critic,如果实际使用中不进行训练的话,那么on-line与off-line的共同点就是actor,所以这里的actor我可以设计的尽可能通用,比如只采用自己的observation, πi(a|oi)πi(a|oi) ,然后将额外的信息交给critic,让critic能够帮助 policy 算出更准确的梯度。
先画一个简图来说明DDPG结构的输入输出: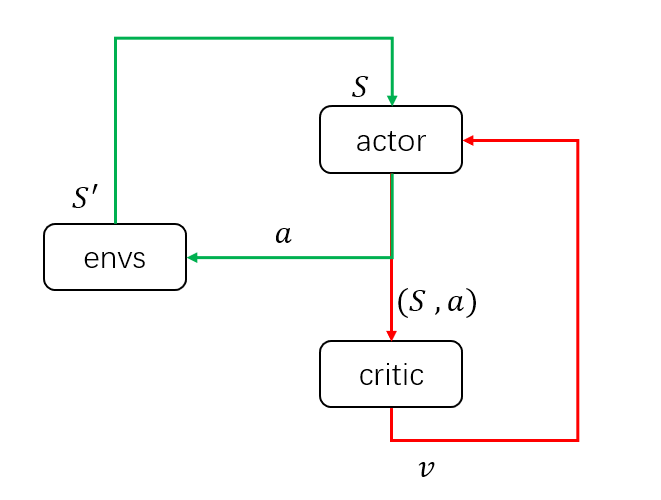
当策略训练好后,只需要actor与环境交互,即只需要绿色的循环,其中actor的输入为环境状态SS,输出为具体动作 aa 。而在训练过程中,需要critic获得当前的环境状态和actor采取的动作,组成状态动作对(S,a)作为输入,输出状态动作对的价值V(或Q)来评估当前动作的好坏,并帮助actor改进策略。
接着是 MADDPG,以两个agent为例,同样画出输入输出的简图如下: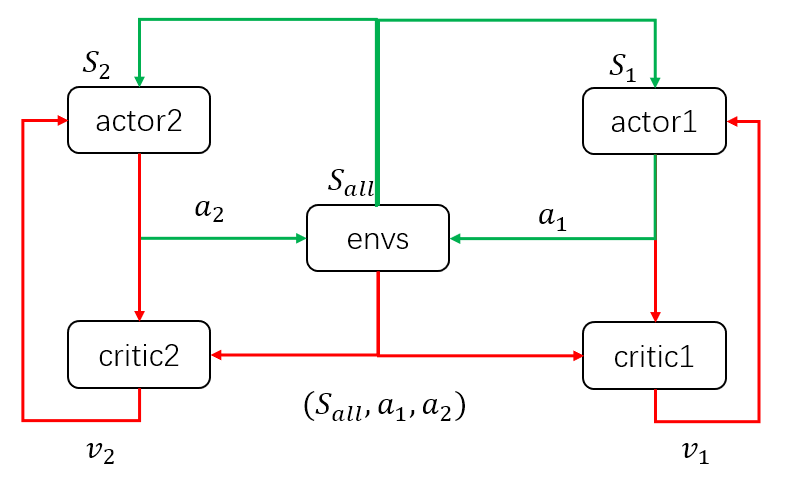
当模型训练好后,只需要两个actor与环境交互,即只需要绿色的循环。这里区别于单个agent的情况,每个agent的输入状态是不一样的。环境输出下一个全信息状态SallSall后,actor1 和 actor2 只能获取自己能够观测到的部分状态信息S1,S2S1,S2。而在训练过程中,critic1和critic2可以获得全信息状态,同时还能获得两个 agent 采取的策略动作a1,a2a1,a2。也就是说,actor虽然不能看到全部信息,也不知道其他actor的策略,但是每个actor有一个上帝视角的导师,这个导师可以观测到所有信息,并指导对应的actor优化策略。
整个过程为中心化的训练和去中心化的执行。这种改进,理论上将之前环境不稳定的问题得以缓解。
即P(s‘|s,a,π1,…,πN)≠P(s‘|s,a,π‘1,…,π‘N)P(s‘|s,a,π1,…,πN)≠P(s‘|s,a,π1‘,…,πN‘),对任意的πi≠π‘iπi≠πi‘
转变为
P(s‘|s,a1,…,aN,π1,…,πN)=P(s‘|s,a1,…,aN)=P(s‘|s,a1,…,aN,π‘1,…,π‘N)P(s‘|s,a1,…,aN,π1,…,πN)=P(s‘|s,a1,…,aN)=P(s‘|s,a1,…,aN,π1‘,…,πN‘) for any πi≠π‘iπi≠πi‘。
Inferring Policies of Other Agents
知道其他agent的策略这个假设其实特别强, 放宽假设:知道对手的action,不知道对手的policy。然后通过观察到的action来拟合出对手的policy
所以可以采用极大似然估计来估计policy,另外加上一个entropy让policy不会太确定:
loss = 交叉熵 + 自熵
critic更新的时候使用估计出来的 policy。
Agents with Policy Ensembles
很多时候agent使用的策略只对当前的其他agent使用的策略有效,一旦其他agent稍微变化效果就变差,所以在这里我们对每个agent都训练k个不同的策略,然后在每次play的时候就在这个策略集中随机挑选一个,那么这样就有可能能够学出k个不同的策略,但是在实际中,我们只使用一个policy,所以我们可以利用这k个策略来做权衡,学习出一个总的策略:
对于每个sub policy单独采用MADDPG学习
https://www.youtube.com/watch?time_continue=20&v=QCmBo91Wy64
REF:
- Lowe R , Wu Y , Tamar A , et al. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments[J]. 2017.
- http://www.cnblogs.com/initial-h/p/9429632.html
- https://zhuanlan.zhihu.com/p/32333293
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK