

基于数据分布的对抗防御和攻击
source link: https://yuanjie-ai.github.io/2021/09/07/data-dis-attack-defense/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

在做对抗训练的时候,我时常在想一个问题:PGD、CW 这些攻击算法都会设置迭代步长和阈值,如果模型固定、参数固定,那么每次生成的对抗样本也会是一样的。如果使用 min-max 的方式进行对抗训练,那么模型可能会只认识在某一设置下的数据,如果面对新的分布攻击样本,如 ZOO, UAP, Deepfool 等,岂不是不能很好的防御?
这就又会回到小样本问题,总不能对所有的攻击算法在不同阈值下都生成对抗样本,而应该生成分布尽可能广泛的对抗样。既然提到生成,就不得不考虑 GAN,所以搜了些相关论文,并作整理。注意,所有论文我没看代码,所以不评价好与坏,在不久的将来如果我要发论文,肯定还会做对比算法,到时候回来评价各个算法。未完待续。
advFlow
AdvFlow: Inconspicuous Black-box Adversarial Attacks using Normalizing Flows, NIPS 2020。
这篇论文提出使用 normal flow 模型来生成对抗样本实现内部的 max。使得生成的对抗样本能围绕在干净样本附近,生成的对抗扰动能捕获图片信息,换句话说,可以根据图片信息来生成对抗扰动。

首先预训练一个神经网络 f,这个网络是可逆的:
- 输入为一随机分布 z,而后产生 x;
- 输入为干净样本 x,输入是随机分布 z
整个流程如下:(这篇论文的 github 提供了 gif 来描述这个流程)
输入干净样本,经过 f−1 得到均值和方差下的噪音,将噪音再次经过 f 得到对抗样本,将对抗样本输入目标模型,使用损失来更新均值和方差。以此来实现对抗训练。其中的损失、网络细节我没有看。
Adversarial Distributional Training for Robust Deep Learning, NIPS 2020。
这篇论文和我的关注点一样,果然发顶会手要快。作者认为:对抗训练可不可以理解为数据增强?单个攻击算法并不能代表全部的对抗样本,所以作者提出了 ADT,通过增加熵正则化项,来获取潜在的分布在干净样本周围的对抗样本。以此来作为内部最大化,好的攻击算法才能产生更好的鲁棒性。
由于单个攻击算法不能覆盖全部的扰动,为了避免这个问题,应该找到干净样本附近的对抗样本的分布,而不是单纯的找到一个对抗样本。
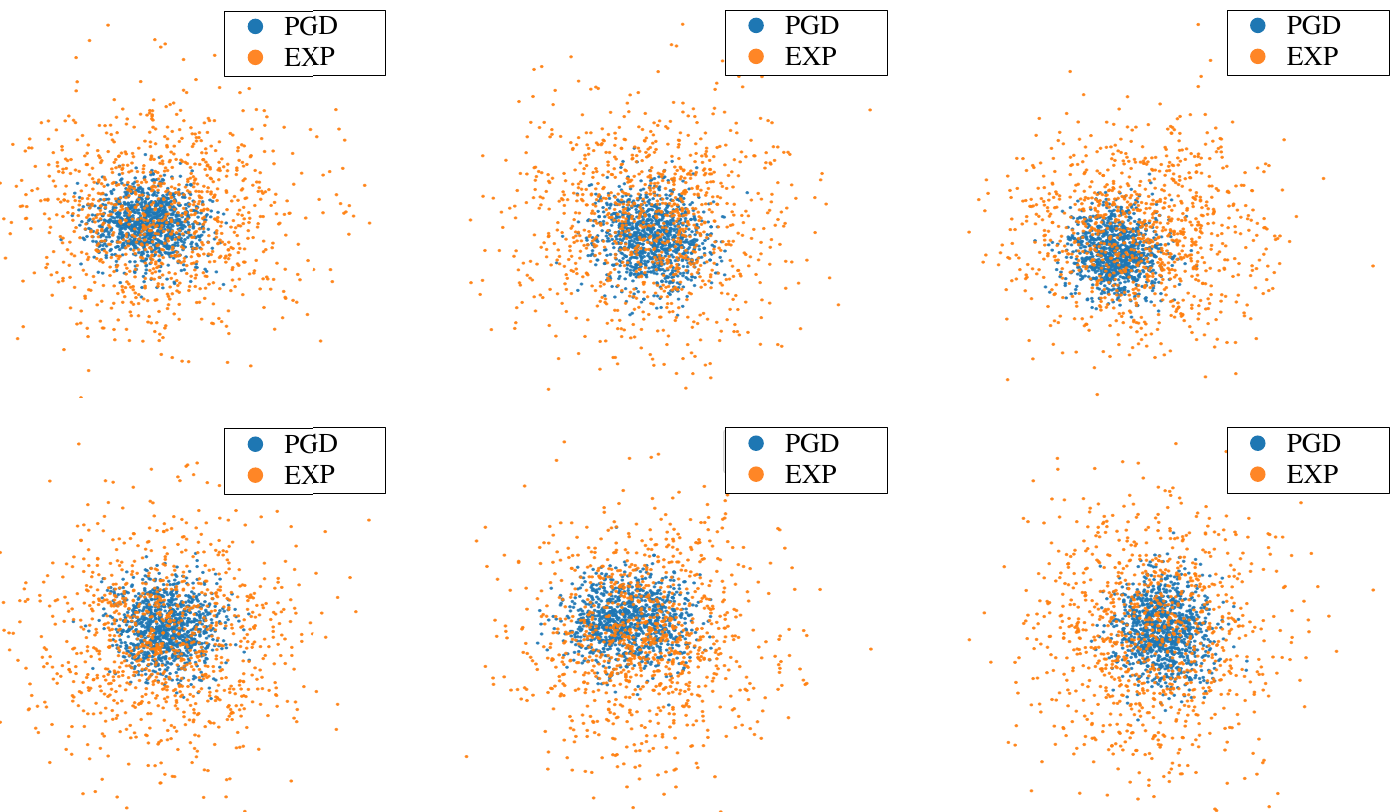
如上图所示,蓝色点是 PGD 产生的对抗样本,黄色点是 ADT 产生的对抗样本。为了使对抗样本的分布具有多样性,增加了熵作为模型损失的一部分,众所周知,熵能衡量系统的稳定性,熵越大越不稳定。也就是,对抗样本的产生方式为:
(1)E[L(f(x+δ),y)]+λH(p(δ))
δ 是对抗扰动,由高斯噪音分布并经过 tanh 函数映射而来。相对于单个攻击算法,上述公式能更好的探索对抗扰动的分布。
Attribute-Guided Adversarial Training for Robustness to Natural Perturbations,发表在 AAAI 2021。
在许多情况下,并不能获得全部的对抗样本,如果预测的对抗样本和训练的对抗样本没有来自同一分布,就会导致鲁棒性的下降。所以本文提出的对抗训练算法中,在内部最大化时,操纵图像属性空间的变化,这样训练出来的模型更具鲁棒性。
这里的属性空间是:翻转算一个属性空间,缩放算一个属性空间,颜色变化又算另一个属性空间。
本文使用的扰动是自然扰动,如图片尺寸和颜色的改变;缩放、旋转、腐蚀等。传统攻击算法的扰动有时会不满足 ‖x−x′‖≤ϵ 的限制,且 ϵ 太大太小都不好,太小了没扰动效果,太大了图像会失真。但是本文的算法能有效的处理自然的扰动,使用 DNN 来生成扰动(看后文的意思是,输入图像,输出对抗样本)。
这篇论文好多话写的我也不明所以,只能说大概流程是:前 N 个 epoch 训练干净样本,后面几个 epoch 训练对数据以迭代的形式进行扰动增强,而扰动增强这里我感觉很玄学。损失为最小化图像的分类损失、以及最大化干净样本与对抗样本在隐层的差异,以及通过 L2 范数限制扰动 α 的范围。
advGAN
Generating Adversarial Examples with Adversarial Networks,发表在 IJCAI 2018,使用 GAN 来生成对抗样本。
通过 GAN 来生成围绕着原始实例的高质量扰动来产生对抗样本,判别器来把关生成图像的质量。
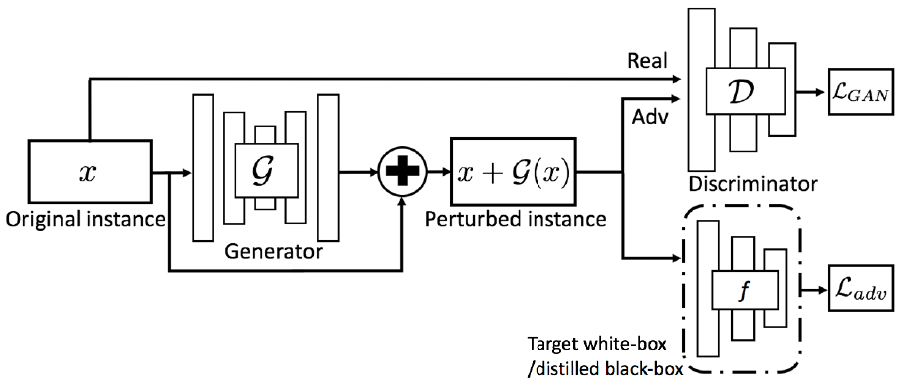
这个图已经把论文的含义表达的差不多了,思路也是简洁明了。输入原始图像,生成扰动并叠加至干净样本。和我最开始的构思一样,可惜被别人发表了。损失函数由三部分组成,一部分是对抗样本的分类损失,一部分是 GAN 的生成和判别损失,一部分是对抗扰动的范围损失,希望扰动范围越大越好。
advGAN++
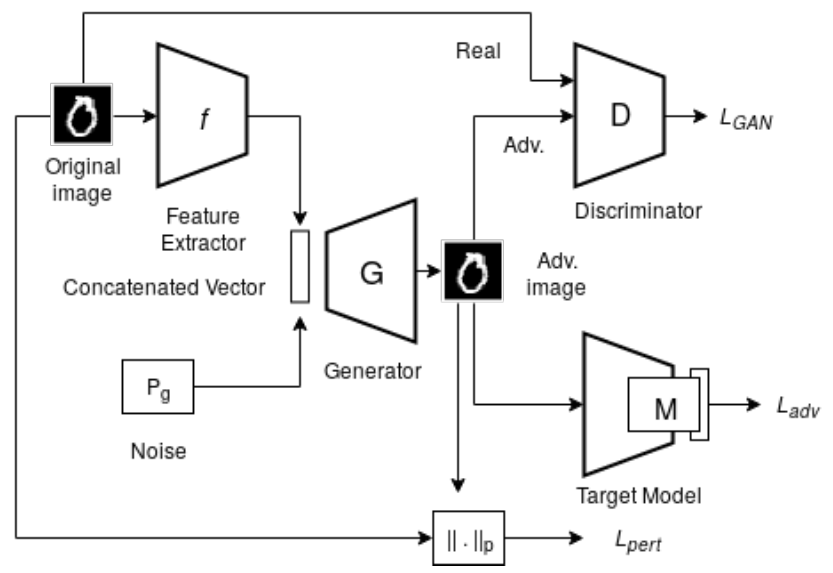
AdvGAN++ : Harnessing latent layers for adversary generation 发表在 ICCV 2019,是基于 advGAN 的改进,之前的 advGAN 是读取全部图像生成对抗扰动,这篇论文发现读取图像的隐层表示生成的对抗扰动会更好,就这样改进了一下。
RobGAN
Rob-GAN: Generator, Discriminator, and Adversarial Attacker,发表在 CVPR 2018。
这篇论文从另一个角度结合了 GAN 和对抗训练,将生成器融入对抗训练,提升判别器的鲁棒性;对抗训练使得 GAN 更快的收敛,并得到更好的生成器,两者互益。这篇论文的出发点同上:生成器生成分布更广阔的数据,使分类器在不可见数据集上获取更好的鲁棒性。
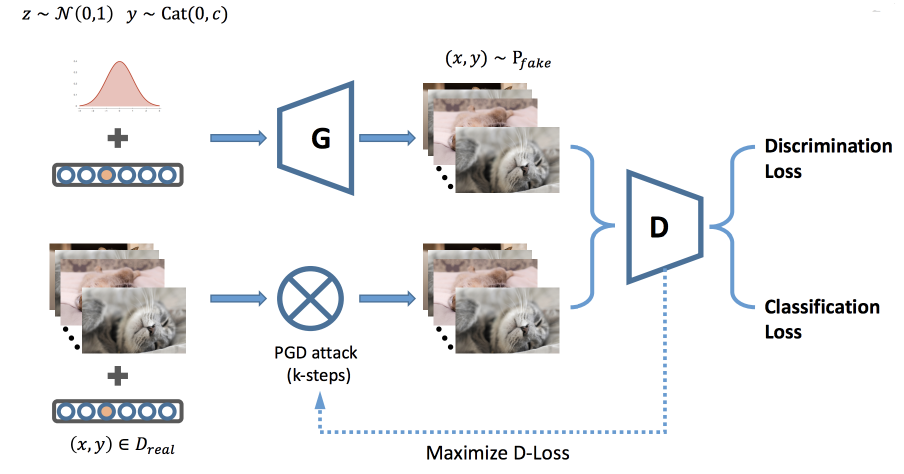
对于 WGAN 的判别器而言,需要判别对抗样本和生成器的虚假样本,所以损失就是使这两者的分类误差达到最小,这里需要注意的是,虚假样本也要加上对抗扰动。
对于鲁棒性差的 GAN 而言,它虽然 smarter 但是 weaker,如下图所示:
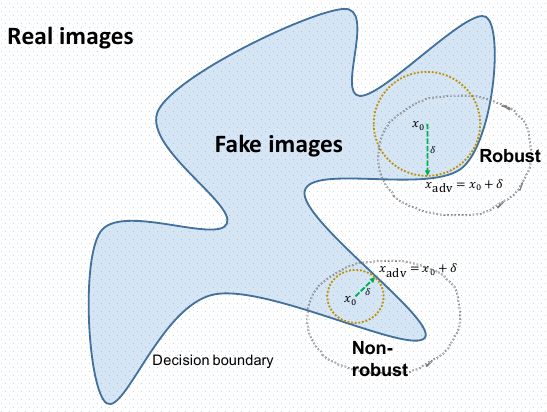
在鲁棒的区域,能有效的抵御攻击而不会错分类。论文给出了一些证明,由于生成网络的任务是欺骗判别器,如果判别器不够鲁棒,那么只需要一点点的更新就可以欺骗判别器。如果判别器鲁棒,那么得到的生成器也会更好。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK