

go benchmark实践与原理
source link: http://cbsheng.github.io/posts/go_benchmark%E5%AE%9E%E8%B7%B5%E4%B8%8E%E5%8E%9F%E7%90%86/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

go benchmark实践与原理
go自带的benchmark是利器,有了它,开发者可以方便快捷地在测试一个函数方法在串行或并行环境下的基准表现。指定一个时间(默认是1秒),看测试对象在达到或超过时间上限时,最多能被执行多少次和在此期间测试对象内存分配情况。
benchmark常用API:
- b.StopTimer()
- b.StartTimer()
- b.ResetTimer()
- b.Run(name string, f func(b *B))
- b.RunParallel(body func(*PB))
- b.ReportAllocs()
- b.SetParallelism(p int)
- b.SetBytes(n int64)
- testing.Benchmark(f func(b *B)) BenchmarkResult
通过例子看它们之间的组合用法。benchtime默认为1秒。
func BenchmarkFoo(b *testing.B) {
for i:=0; i<b.N; i++ {
dosomething()
}
}最基本用法,测试dosomething()在达到1秒或超过1秒时,总共执行多少次。b.N的值就是最大次数。
func BenchmarkFoo(b *testing.B) {
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
dosomething()
}
})
}如果代码只是像上例这样写,那么并行的goroutine个数是默认等于runtime.GOMAXPROCS(0)。
创建P个goroutine之后,再把b.N打散到每个goroutine上执行。所以并行用法就比较适合IO型的测试对象。
若想增大goroutine的个数,那就使用b.SetParallelism(p int)。
// 最终goroutine个数 = 形参p的值 * runtime.GOMAXPROCS(0)
numProcs := b.parallelism * runtime.GOMAXPROCS(0)要注意,b.SetParallelism()的调用一定要放在b.RunParallel()之前。
并行用法带来一些启示,注意到b.N是被RunParallel()接管的。意味着,开发者可以自己写一个RunParallel()方法,goroutine个数和b.N的打散机制自己控制。或接管b.N之后,定制自己的策略。
要注意b.N会递增,这次b.N执行完,不满足终止条件,就会递增b.N,逼近上限,直至满足终止条件。
// 终止策略: 执行过程中没有竟态问题 & 时间没超出 & 次数没达到上限
// d := b.benchTime
if !b.failed && b.duration < d && n < 1e9 {}公共部分
剩下的API用法就不分串行还是并行了,用在哪种环境下都可以。
Start/Stop/ResetTimer()
这三个都是对 计时统计器 和 内存统计器 操作。
benchmark中难免有一些初始化的工作,这些工作耗时不希望被计算进benchmark结果中。
通常做法是
// 串行情况在for循环之前调用
init() // 初始化工作
b.ResetTimer()
for i:=0; i<b.N; i++ { dosomething() }
// 并行情况在b.RunParallel()之前调用
init() // 初始化工作
b.ResetTimer()
b.RunParallel(func(pb *testing.PB) { dosomething() })剩下的StopTimer()和ResetTimer()呢?可以这样用:
init(); // 初始化工作
b.ResetTimer()
for i:=0; i<b.N; i++ { dosomething1() }
b.StopTimer()
otherWork(); // 例如做一些转换工作
b.StartTimer()
for i:=0; i<b.N; i++ { dosomething2() }也可以这样用:
init(); // 初始化工作
b.ResetTimer()
for i:=0; i<b.N; i++ {
flag := dosomething()
if flag {
b.StopTimer()
} else {
b.StartTimer()
}
}理解好这三个方法本质后灵活运用
func (b *B) StartTimer() {
if !b.timerOn {
// 记录当前时间为开始时间 和 内存分配情况
b.timerOn = true
}
}
func (b *B) StopTimer() {
if b.timerOn {
// 累计记录执行的时间(当前时间 - 记录的开始时间)
// 累计记录内存分配次数和分配字节数
b.timerOn = false
}
}
func (b *B) ResetTimer() {
if b.timerOn {
// 记录当前时间为开始时间 和 内存分配情况
}
// 清空所有的累计变量
}b.Run()
虽然这个方法被暴露了,但其实在源码内部它是被复用的(下文原理部分介绍)。
它作用就是生成一个subbenchmark,每一个subbenchmark都被当成一个普通的Benchmark执行。
有了它,表驱动法派上用场。
func BenchmarkGCMRead(b *testing.B) {
tests := []struct {
keyLength int
valueLength int
expectStale bool
}{
{keyLength: 16, valueLength: 1024, expectStale: false},
{keyLength: 32, valueLength: 1024, expectStale: false},
// more
}
for _, t := range tests {
name := fmt.Sprintf("%vKeyLength/%vValueLength/%vExpectStale", t.keyLength, t.valueLength, t.expectStale)
b.Run(name, func(b *testing.B) {
benchmarkGCMRead(b, t.keyLength, t.valueLength, t.expectStale)
})
}
}b.SetBytes(n int)
这个API用得不多。
形参n表示在b.N次循环中,每一次循环用到了多少字节内存。
最后在benchmark输出结果中会多出MB/s这一项信息。MB/s取值公式如下:
(float64(r.Bytes) * float64(r.N) / 1e6) / r.T.Seconds()意思是这次benchmark每秒大约用了多少MB的内存。
这玩意儿有啥用?个人理解,它可以大概估算堆内存增长趋势来判断GC被触发频率。
例如下面例子,dAtA这种返回值变量一般是被分配在堆上的。最后通过b.SetBytes(int64(total / b.N))来估算下每秒分配多少MB内存。
MB/s值大小的影响要结合GOGC的值来理解,默认GOGC是100,即堆内存增长一倍就被触发GC。如果MB/s值比较小,可以大概认为GC被触发频率较低;反之较高;
for i := 0; i < b.N; i++ {
dAtA, err := github_com_gogo_protobuf_proto.Marshal(pops[i%10000])
if err != nil {
panic(err)
}
total += len(dAtA)
}
b.SetBytes(int64(total / b.N))b.ReportAllocs()
b.ReportAllocs()这个API比较简单,就是打上标记,在benchmark执行完毕后,输出信息会包括B/op和allocs/op这两项信息。
testing.Benchmark()
默认benchmark时间(benchtime)上限是1秒,可以通过-test.benchtime来改变:
var benchTime = flag.Duration("test.benchtime", 1*time.Second, "run each benchmark for duration `d`")前面提及到的终止策略中,注意b.duration < d这个条件。不论你写的benchmark运行停止时耗时是1s、1.1s还是60s,benchmark输出结果都是*/op形式,而不是以时间维度的。所以不能认为1秒最多可执行b.N次。
因此想定制benchmark输出的话,那么使用testing.Benchmark()就是最好的方式。例如想看达到b.N时,究竟花了多长时间。
benchmark输出项含义
go test -bench='^BenchmarkFoo$' -cpu 4,8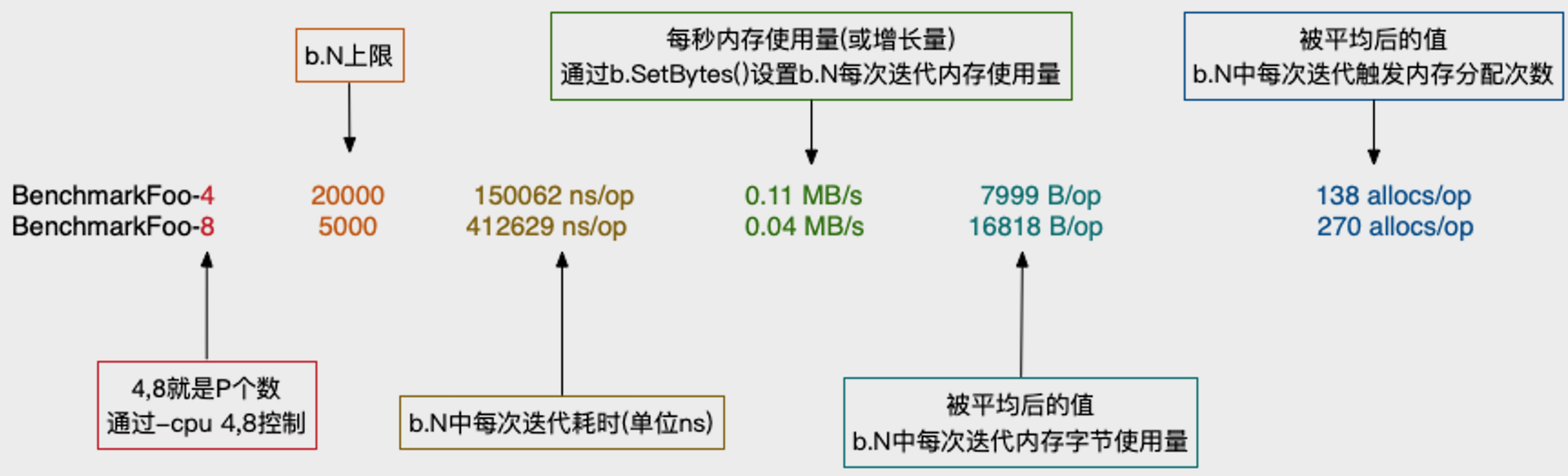
源码太长不做介绍,以单个Benchmark举例串起流程分析下原理。
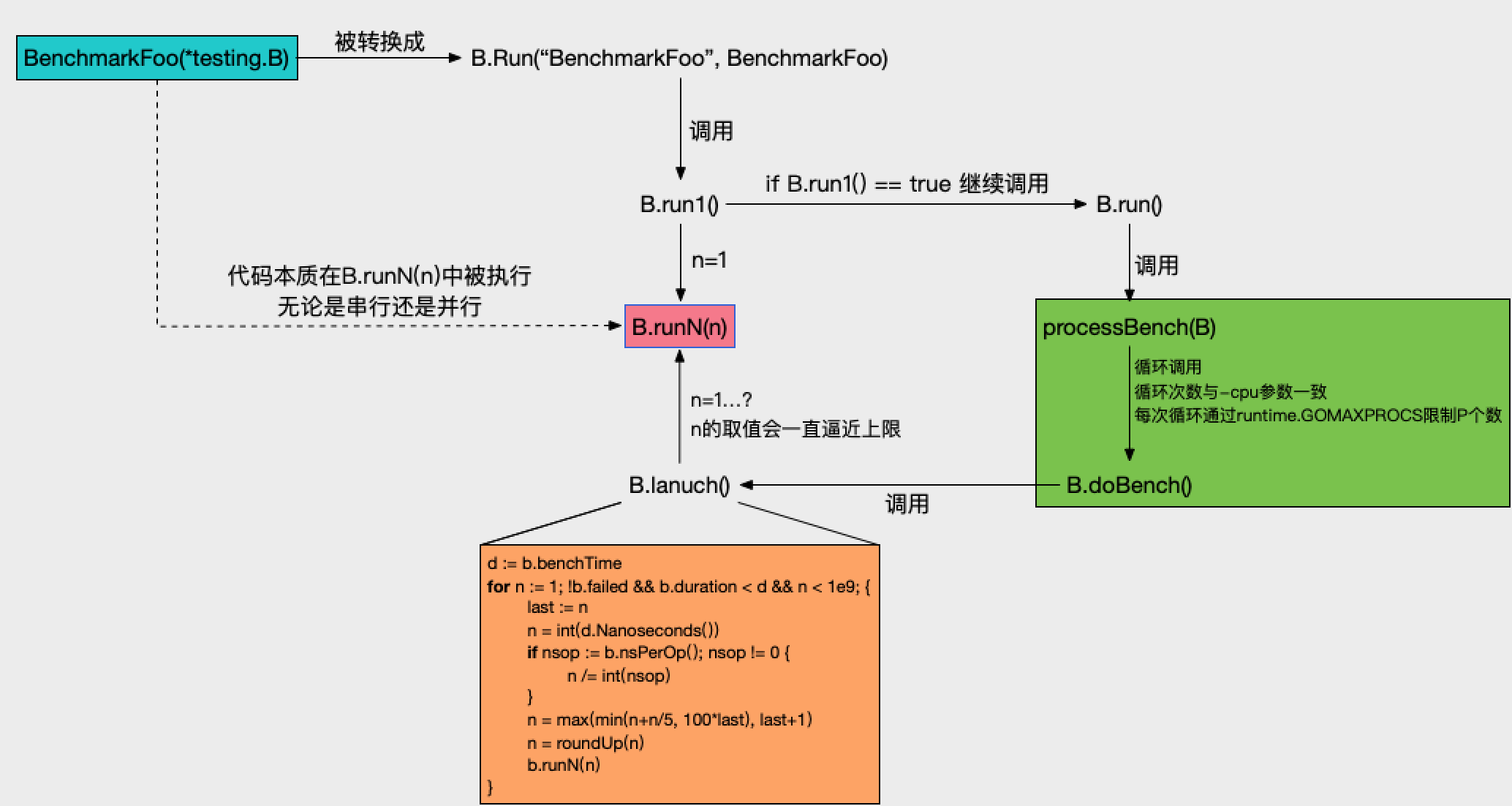
如上图,浅蓝色部分就是开发者自行编写的benchmark方法,调用逻辑按箭头方向依次递进。
B.run1()的作用是先尝试跑一次,在这次尝试中要做 竟态检查 和 当前benchmark是否被skip了。目的检查当前benchmark是否有必要继续执行。
go test 命令有-cpu参数,用于控制benchmark分别在不同的P数量下执行。这里就对应上图绿色部分,每次通过runtime.GOMAXPROCS(n)更新P个数,然后调用B.doBench()。
核心方法是红色部分的B.runN(n)。形参n值就是b.N值,由外部传进。n不断被逼近上限,逼近策略不能过快,过快可能引起benchmark执行超时。
橙色部分就是逼近策略。先通过n/=int(nsop)来估算b.N的上限,然后再通过n=max(min(n+n/5, 100*last), last+1)计算最后的b.N。benchmark可能是CPU型或IO型,若直接使用第一次估算的b.N值会过于粗暴,可能使结果不准确,所以需要做进一步的约束来逼近。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK