

论文笔记随笔 - 1
source link: https://kiprey.github.io/2022/03/other_paper_notes/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

这里存放阅读论文/读代码时所记录下的一些零碎笔记。
由于这部分活动在记录笔记时,出于时间与重要性考虑,只会记录下较为重要的一部分,不会完整记录,因此单篇笔记的篇幅不会太长。
原先是想着把这些随笔放到周报里去,但是这会打乱周报的排版,思来想去还是想单独立一篇文章出来。
一、Address Sanitizer LLVM 3.1
阅读 Address Sanitizer LLVM 3.1 最早期的源代码。
-
Asan 使用 8 字节映射至 1字节的粗粒度内存映射。每块虚拟内存都会对应一块 shadow memory。
8字节的粗粒度,是因为 malloc 返回地址会对齐8字节。
其中 shadow byte 上的值表示 origin memory 中前 n 个字节是可访问的。
-
Asan 会在 LLVM pass 过程的末尾,对所有的内存读写操作进行插桩,检查当前访问的内存地址所对应的 shadow byte 的值是否说明当前地址可访问。如果不可访问则直接abort。
-
对于溢出检测,asan 会在用户内存的左右两边分别加上一块大小固定的 redzone,其中 redzone 所对应的 shadow memory 将会被加毒。这样当访问到 redzone 时将触发 asan。
加毒(poison) 指的是将某块用户内存所对应的 shadow memory 标记为不可访问。
-
对于栈内存来说,它会先分配一块 原始栈大小 + (等待被 redzone 检测的变量个数 + 1) * redzone 大小的内存,然后修改那些目标变量的 alloc 指令的偏移量。(poisonStackInFunction 函数)
之后,将一些栈上的信息放入当前栈帧最左边的 redzone里。
在函数头部,插入给当前栈帧 redzone 加毒的操作;并在所有 ret 语句之前插入 redzone 解毒的操作。
对于当前函数,若当前函数执行了一些 noret 的函数(例如 exit、execve),则在执行这些 noret 函数之前,必须对其解毒,防止误报。处理 no ret call 是为了防止有不返回的函数调用导致调用后栈上的 poison 信息没有被处理。
-
但需要注意的是,asan 只会在全局变量的右边加 redzone。 (insertGlobalRedzones 函数)
同时,虽然全局变量的 redzone 的添加操作是以插桩的形式加入程序中,但全局变量的加毒解毒操作是位于 runtime 中。
-
Asan 会 hook memcpy 等内存处理或字符串处理的 lib 函数,以达到更好的效果。(InitializeAsanInterceptors 函数)
-
asan 除了检测 内存越界读写以外,它同样检测 UAF 和 use after return。
-
asan hook 掉了 malloc、free、realloc 等函数,创建了自己的内存管理机制,在分配内存时对内存解毒,在释放内存时加毒。
对于动态分配的内存,一共有三种主要状态,分别是:可分配、检疫、已分配。当某个内存块被释放时,该内存块将会被设置为检疫状态,并放置到检疫队列中。等到检疫队列数量超过阈值后,再将其中的检疫内存放回可分配内存池中。这样做的目的是为了延长某块内存从被释放到被二次分配的过程,延长检测 UAF 的窗口期。
-
use after return
在替换栈帧上原始 alloc 为新 alloc 之前,asan 会先分配一块 fake stack, 然后在替换 alloc 指令时,将其地址替换为 fake stack。这样,带有 redzone 的局部变量就会 alloc 在 fake stack 上,而不是 origin stack。
在当前函数结束时,fake stack 会被重新加毒,注意此时不会回收 fake stack。
那么 fake stack 在什么时候被回收呢?在分配 fake stack时。分配时会同步检测 fake stack 的调用栈,遍历调用栈中的每个 fake stack,判断当前 fake stack 所对应的 real_stack 地址是否大于当前的运行时栈。如果大于则说明该 fake stack 已经没有用处了,因此将会被释放。
-
-
asan 第一版存在局限性,例如不会检测到结构体成员之间内存对齐的那一小部分内存的越界,以及不会检测这种越界到另一块用户可读写内存中的情况等等,不过总体上实现效果非常优秀。
这里感谢 sad 师傅分享的笔记。
二、HFL: Hybrid Fuzzing on the Linux Kernel
论文 HFL: Hybrid Fuzzing on the Linux Kernel 结合 fuzz 技术和符号执行技术,主要解决三个问题:
-
由 syscall 参数所决定的间接控制流改变,会使得符号执行效率低下。(主要是这种:

- random fuzz 无法高效处理那些函数指针表索引来自参数的情况。
- 符号执行技术用一个 symbol 来索引函数表可能会导致符号解引用,而且还需要符号探索整个值空间
解决方案:基于 kernel src 做了一个离线转换器,用于在编译时将间接控制流转换成直接控制流:

-
需要推断 syscall 调用序列和依赖关系,以便于控制和匹配内部系统状态,防止 fuzz 效率低效
解决方法:
-
首先使用静态分析技术(占大头的应该是指针分析技术),在多个 syscall 中收集对相同内存位置进行读写的内存读写对 集合(candidates)。这种内存读写是分开的,即在一个 syscall 中 write,在另一个 syscall 中 read。
-
之后在 runtime 中验证这些 candidates。因为静态分析会产生一些误报,因此需要在执行时检测某个内存读写对是否确实会访问相同的内存位置,如果是则说明遍历到的 candidate 是真正的依赖关系对。
同时写操作的 syscall 一定在读操作的前面,因为只有先写才能读。
-
使用符号执行技术,确定 syscall 参数之间的依赖关系。例如 syscall2 中的参数等于 syscall1 中的某个参数,具体的看下面工作流程图可得知。
工作流程如下:
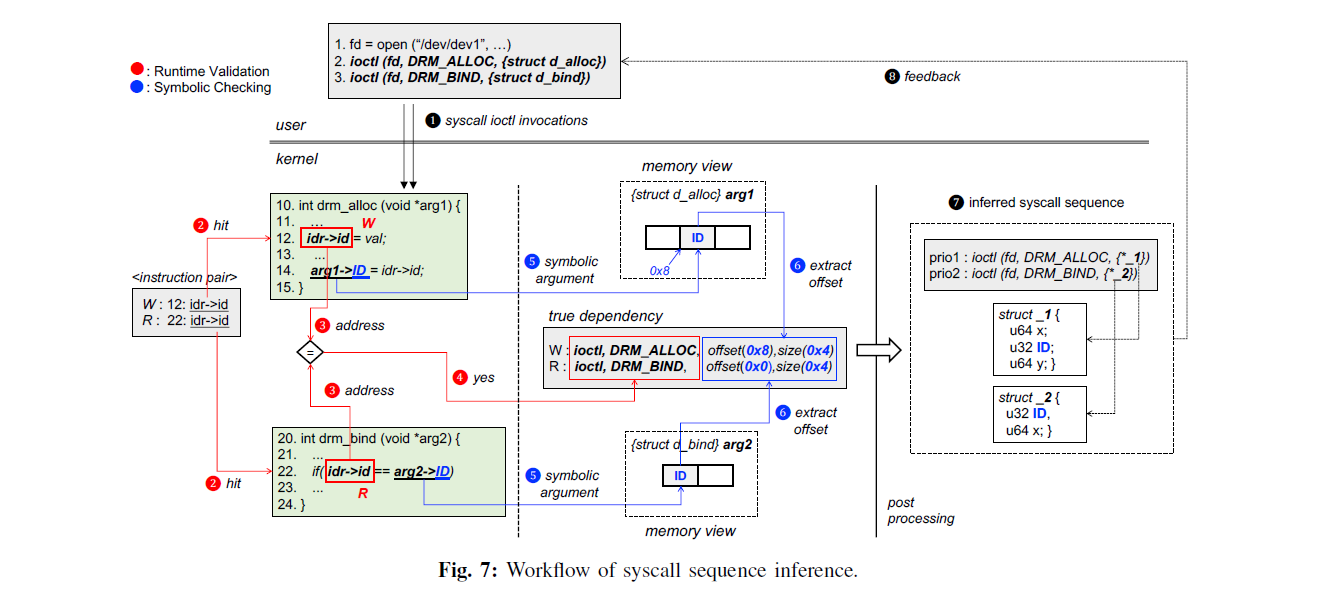
-
-
推断用于调用 syscall 的嵌套参数类型。这里还是用的老一套方法,检测 copy_from_user 函数以检测 syscall 嵌套参数的情况。这个其实不用多说,一张图胜过千言万语。
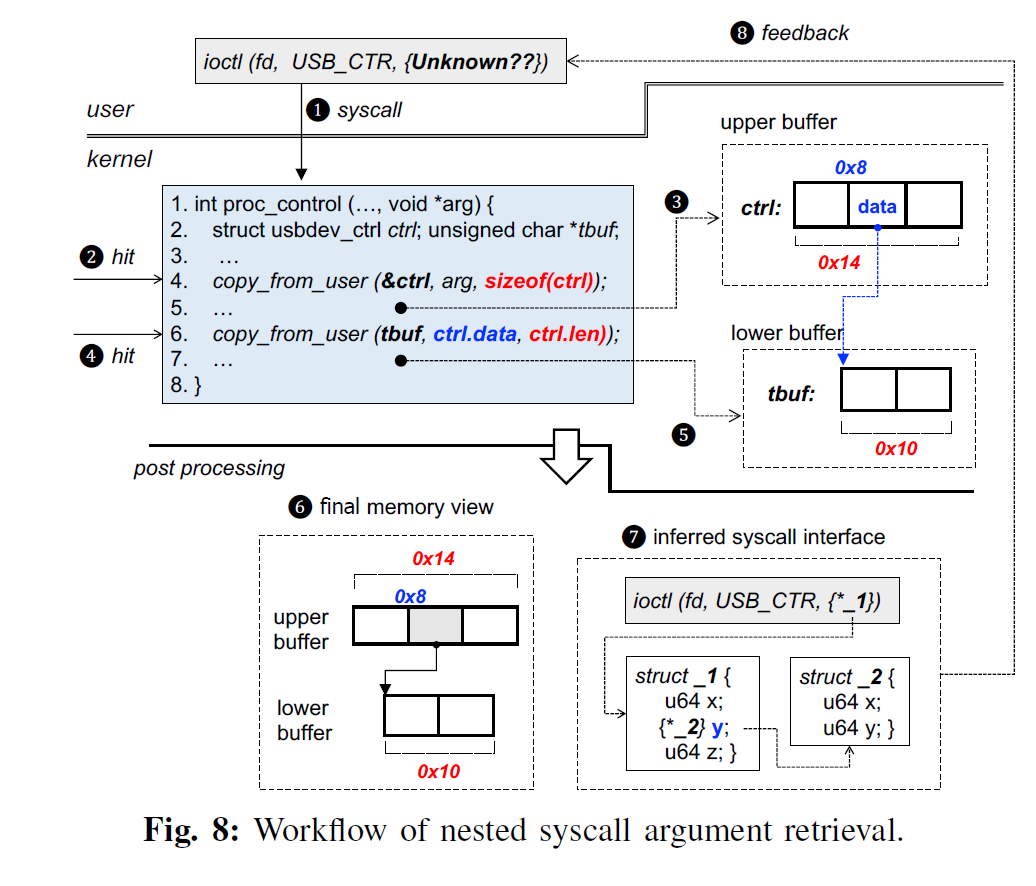
除了上面这三个问题以外,hybrid fuzz 中 fuzz 和 symbolic excution 切换的时机也很关键,其 fuzzer 内部维持了一个频率表,用于统计每个分支的 true/false 评估数量。我个人对这个设计还挺感兴趣,但是源码存放的网站已经被关闭,找不到源码了。
三、MoonShine: Optimizing OS Fuzzer Seed
论文 MoonShine: Optimizing OS Fuzzer Seed。这篇论文主要说明如何从真实系统调用序列中提取 OS Fuzzer 种子(种子蒸馏),同时保留依赖关系。它给出了两个有意思的依赖关系定义:对于 syscall Ci、Cj 来说,
-
显式依赖:若 Ci 生成的值用做 Cj 的参数输入时,则说明 Cj 依赖 Ci ,那么自然得先调用 Ci 再调用 Cj。
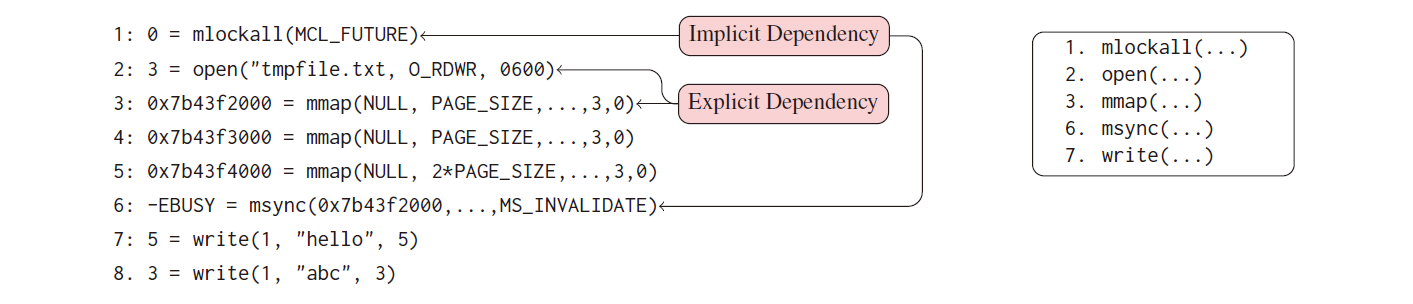
-
隐式依赖:若 Ci 在执行过程中会通过共享变量读写来影响 Cj 的执行,则说明 Cj 依赖 Ci 的执行。

MoonShine 建立依赖关系的流程是这样的:
-
对于显式依赖来说,MoonShine 主要构建依赖关系图,通过调用序列,将 syscall 返回值和对应的 syscall 参数相连接,来确定显式依赖。
-
对于隐式依赖来说,MoonShine 主要通过分析一对 syscall 之中的读写依赖项来确定依赖关系。即,若 Ci 读取的全局变量集合与 Cj 写入的全局变量集合之间存在交集,则说明这两个 syscall 之间存在隐式依赖关系。但需要注意的是,受限于静态分析的精度,其隐式依赖关系可能会被高估或者低估。
需要注意的是
- 如果 Ci 隐式依赖与 Cj,而 Cj 显式依赖于 Ck,则可说明 Ci 隐式依赖于 Ck
- 如果 Ci 显式依赖与 Cj,而 Cj 隐式依赖于 Ck,则可说明 Ci 显式依赖于 Ck
算法伪代码如下所示,伪代码还是比较好理解的:

以下是整体的算法思路:
- 首先是根据 coverage 对 syscall 进行排序,优先处理 coverage 更高的 syscall。
- 之后遍历 syscall 序列,获取其隐式依赖和显式依赖,并将其添加进语料序列中。

四、Scalable Fuzzing of Program Binaries with E9AFL
阅读论文 Scalable Fuzzing of Program Binaries with E9AFL:
e9afl 是一个可对无符号二进制程序插桩实现覆盖率反馈的工具,插桩后的程序可以直接用于 AFL 中进行 fuzz。相对于其他针对纯二进制文件进行 fuzz 的方法,它的优势在于插桩后的 overhead 还能保证在较低水平,同时还保证较高的精度。
整个插桩过程主要分为三步:
-
设计待插入的 trampoline template。这个没啥好说的,基本和 AFL 插桩方式对齐:

-
运行时插入。这步主要做的是将 fork server 和共享内存初始化等操作注入进 binary 中,使得在执行 main 函数前就执行这些操作。
-
确定待插桩的指令位置集合。e9afl 自己实现了一个轻量级控制流分析,以查找所有可能的 jump targets,其中包括直接目标和间接目标。间接目标的检测是通过分析数据段上的跳转表和指向代码的指针所确定的。
有意思的是,虽然静态控制流分析可能会存在一些精度误差(jump targets 多分析或者少分析),但是这些误差对整个 fuzz 过程不会造成太大的影响。
需要注意的是,如果 e9afl 只是插桩 trampoline 但不对其进行任何优化的话,整个程序的执行速度将会非常的慢。虽然 forkserver 对二进制程序的启动速度进行优化,但 fork 出的子进程将会大量触发页错。这是因为这些子进程会经常执行到 trampoline,因此会触发到 trampoline 所在页的页错误。
页错误是制约 e9afl 性能影响的关键,因此需要对其进行优化。这里它提出了三种优化策略:
-
trampoline ordering
使用与 patch 指令所对应的顺序,来在内存上分配 trampoline 内存。
什么意思呢?个人认为是这样的,对于相同代码区域(假设函数级的代码区域),e9afl 尽可能地将这个函数中所会用到的 trampoline,全部集中分配到某个页面(或者某个集中内存页区域里)。换句话说,尽可能让 patch 点相邻的指令,其 trampoline 也相邻。
这背后的原理是:对于一个函数来说,这个函数中的 trampoline 大概率是会大半都被执行的,那么如果将这个函数中的 trampoline 全都集中到一起,当函数执行第一个 trampoline1 时触发页错(正常现象),则接下来函数继续执行下面的 trampoline2 时就不再触发页错了,因为 trampoline1 和 2 位于同一块内存区域。
-
instruction selection
由于上一步优化策略在某些时刻可能不会起作用,例如 patch 时用到了指令双关技术,导致能跳转的 trampoline 地址有限。这一步的优化策略将尝试在基本块中的其他位置进行插桩,而不只是局限在每个基本块的块首。e9afl 会搜索同一基本块中是否存在其它 size>=5byte 的指令,并对该指令进行插桩。
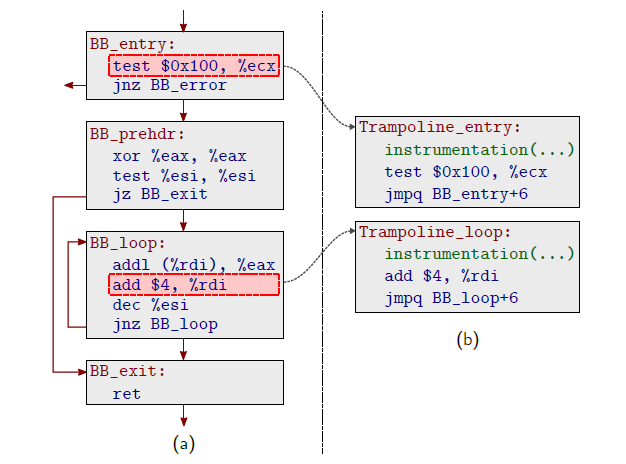
-
bad block elimination
如果上面两个步骤的优化都无法完成,则说明相应的 trampoline 大概率会触发 page fault 并降低 fuzz 速度。那么这一步的优化,就主要侧重于删除一些不必要的 trampoline 插桩。
例如,假设通过 BasicBlockA 的所有路径都会通过到 BasicBlockB,那么只需检测这两个块中的其中一个的覆盖信息即可,这属于路径微分问题。
注:e9afl 将那些无法应用上述两步优化的基本块,称作为 bad block;反之为 good block。
但在这里 e9afl 更侧重于消减掉 bad block 的插桩,其做法如下:
-
初始时,按照以下规则为每个基本块打标签:
- 为每个 good blocks 初始时打上 unoptimized 标签
- 为每个可能是间接跳转目标的 bad blocks 初始时打上 unpotimized 标签
- 其他 bad blocks 初始时打上 optimized 标签
-
接下来,尝试解决 path differentation problem。对于任意满足以下条件的 sub-paths σ=<A→…→B> :
<A, B>这一对基本块是 unoptimized<A,B>之间的基本块全都是 optimized
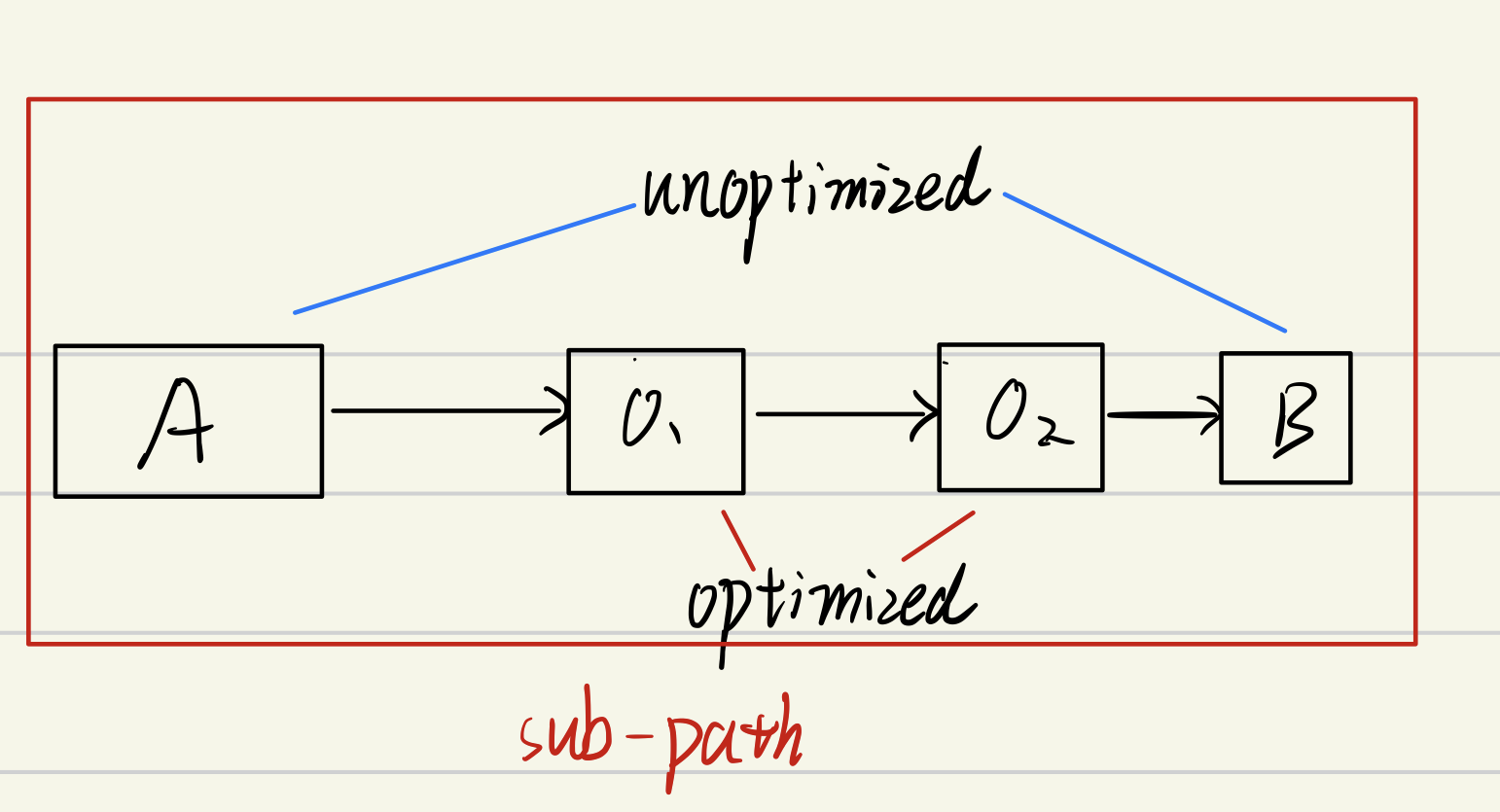
若对于相同的
<A,B>对来说,存在至少两个 sub-paths σ1、σ2,则说明违反了 path differentiation 属性,需要对其进行修补。修补方式是:贪心地将 σ1、σ2 中 optimized 的基本块修改为 unpotimized,并一直递归这个过程,直到没有任何 sub-paths 违背了这个属性。
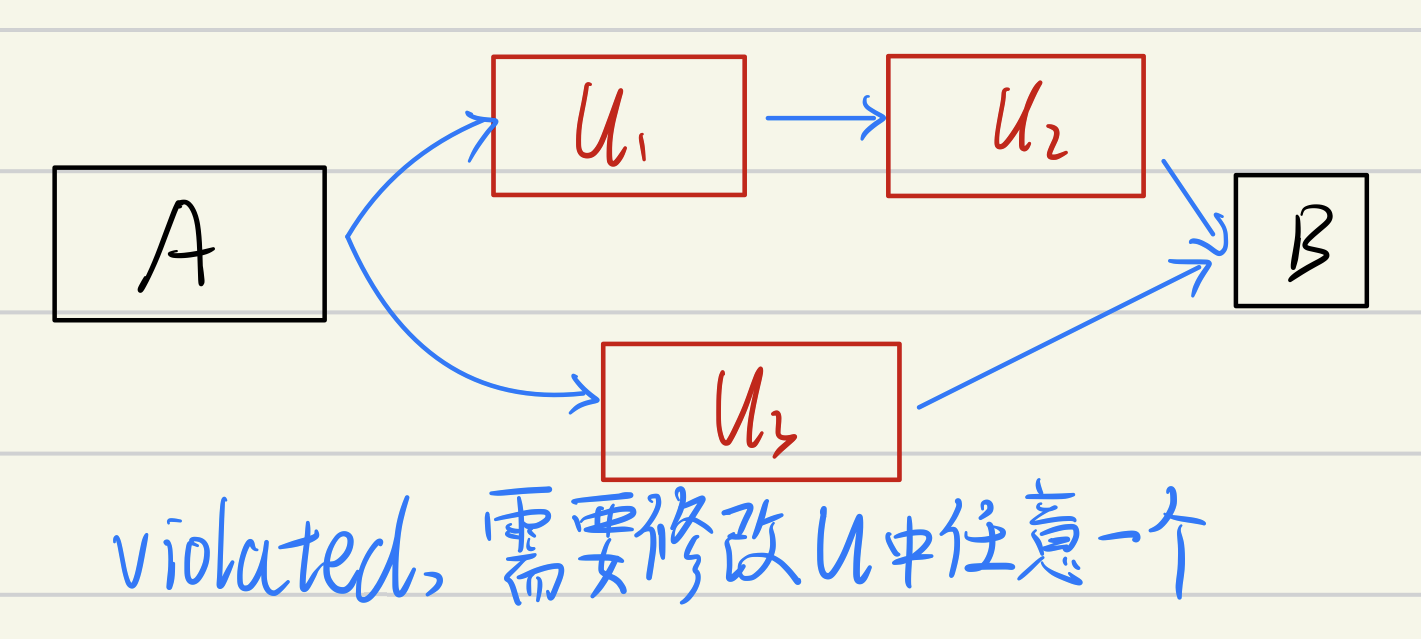
-
最后是 e9afl 的评估效果,可以看到测试效果还是相当不错的,同时 e9afl 也能处理规模较大的文件,例如 chrome:
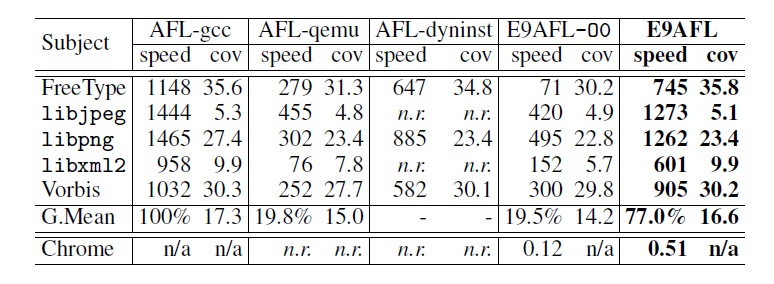
五、NTFUZZ: Enabling Type-Aware Kernel Fuzzing on Windows with Static Binary Analysis
论文 NTFuzz 提出了一个比较有意思的做法:
通过静态分析技术,将 documented 的用户 API 函数参数类型信息,传播至 undocumented 的系统调用参数类型,以弥补这两者之中的信息鸿沟。
- fuzzer 很难在没有参数类型信息的情况下,很好的 fuzz 或触发 bug
- undocumented 的系统调用通常会和 documented 的 API 函数相关联
- 尽管 API 函数最终会进行系统调用,但 API 函数级别的 fuzz 不大可能会触发到 bug。这应该是因为 API 函数会事先对参数做一些过滤操作。
以下是 NTFuzz 的架构图,其中主要分为静态分析和动态内核 fuzzer 两部分:
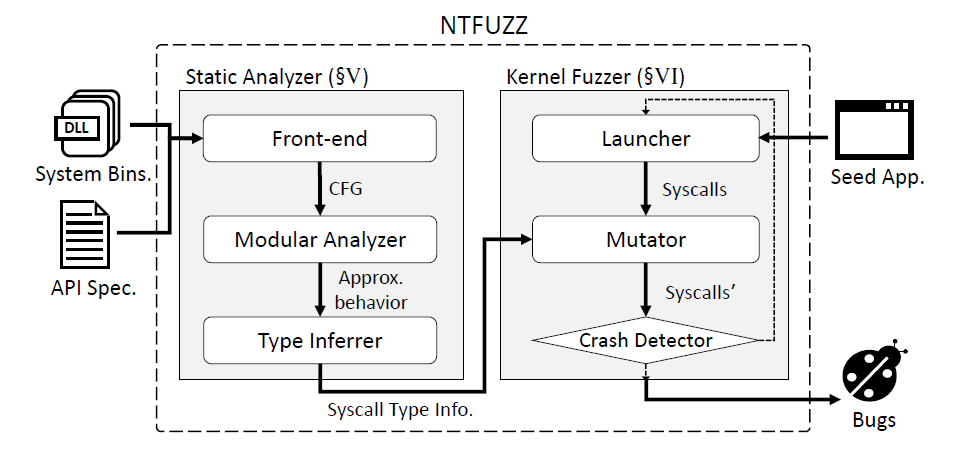
其中比较关键的是静态分析器中的 Modular Analyzer,以 Function 为一个基本的分析单位,其基本算法思路如下:

初始时,输入 CFG、调用图、API描述。之后对 callGraph 使用拓扑排序,自底向上的去遍历每个函数(即先分析 callee,再分析 caller)。这样做的目的是为了可以在分析调用图上层函数时,直接使用先前已分析好的下层函数 summaries,降低时间开销。每次执行 summarize 操作分析函数时,会记录下这个函数所调用的 syscall,以及其内存状态的变动情况。
但这种函数分析顺序无法处理递归调用和间接调用两种情况,因此 NTFuzz 只是简单的将其省略。除此之外,静态分析器还必须能够
- 跨函数追踪数据流。
- 追踪过程间的内存状态。例如可能某个内存位置在某个函数中被修改,然后用到了另一个函数中去,那么这种使用情况就必须能够追踪的到。
接下来我们来重点看看静态分析器的三个部分:
-
Front-end
前端主要做了几件事情:读入 API 描述;将二进制文件解析成基本的 IR 语句并生成 CFG。其中,API 描述主要靠 Windows SDK 来获取,其代码内部的结构化注释也能很好的为 NTFuzz 提供类型信息。除此之外,解析出的 IR 省略了很多与类型信息或内存状态变动无关的 opcode,只留下了几个较为重要的:

有意思的是,这之中省略了一元运算符和分支跳转等指令。这可能是因为一元运算符通常不涉及内存修改,而分支跳转信息也会保存在所建立的 CFG 边上。
为了减小静态分析的 callGraph 大小,NTFuzz 先从带有 sysenter 指令的 syscall stub 函数开始,自底向上分析一个个函数的caller,直到遇到第一个 documented 的 API 函数,这样分析出来的函数集合称为 S1。但需要注意的是只分析 S1 是不够用的,因为这里面并没有包含其它可能会被 S1 中函数所调用的修改内存状态函数,因此在分析出 S1 后,还需要从 S1 函数集合出发,分析那些所有会被 S1 中函数所调用到的函数集合 S2。这样处理后,S1 + S2 集合便是 NTFuzz 需要进行静态分析的目标函数集合。
-
Modular Analyzer
整篇文章中最重要的部分就在这一小节中。
这一部分将会对目标函数集合依次执行 summarize 操作。整体上,该阶段会用到流敏感静态分析技术,这也是为了更好的支持指针分析技术。正如先前所说,这一步会记录下每个函数传递给 syscall 的参数值(注意这个值是抽象的,并非绝对的值),以及在函数进入和退出前后其内存状态的改变情况。具体来说,这步分为两个部分:抽象域(abstract domain) 和抽象语义(abstract semantics)。
抽象域(Abstract Domain),个人认为是用于在为函数提取 summary 时,指定其中某些变量或值的范围。其定义的抽象域主要有以下几种:

乍一看有亿点点复杂(实际上刚接触确实比较复杂),需要一点一点的啃。
-
集合 Z,表示的是整数集合。(就是高中数学的那个 Z 集合)
-
集合 I,表示抽象的整数集合。先引入一下 symbol 的概念,symbol 表示每个函数参数所引入的一个新的符号。因为我们在静态分析阶段没法确定各个函数调用的参数具体是什么值,因此需要用个符号来代替,有点类似符号执行的思想。例如
int func(int a ) {
int b = a*3+1;
return b;
}此时在静态分析阶段,我们可以粗略的认为参数 a 的数值为一个 symbol α,那么变量 b 的数值便是 α∗3+1。
因此,我们可以使用 a∗symbol+b 的形式来表示一个符号整数。当 a 为 0 时,则表示一个具体整数;a 不为 0 时,则表示一个符号整数。
比较有意思的是符号整数还并上了一个倒T和正T 集合后,才构成抽象整数集合 I。其中,
- 倒T 表示的是没有实际分析意义的整数集合。
- 正T 表示的是任意一个整数集合。
这里给出了倒T和正T 与普通整数的相加操作:
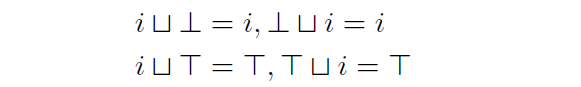
因为倒T集合中的元素没有实际分析意义,因此如果倒T集合与一个有分析意义的 i 相加,则保留 i。
由于正T表示的是任意整数集合,因此任意整数集合与其他整数相加,则仍然为一个任意整数集合,即正T集合。
个人猜测这种加法所保留的结果,会更偏向于保留更有意义的集合。其优先级排序大体为 正T>i>倒T。
接下来我们来简单看看两个符号整数相加的结果:
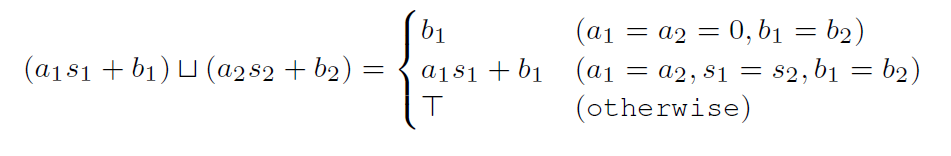
可以看到,只有在一些非常限制的条件下,两个符号整数相加才能得到确定的结果,否则其结果集合将非常的大,用 正T 集合来表示。
-
集合 V,表示函数中某个值的抽象。我们可以使用三个集合来确定一个变量的属性,分别是抽象值集合(数值取哪些),抽象位置集合(该变量存到了哪里),以及抽象类型集合(这个值的类型可以是哪些)。对于某个特定的抽象值 V 来说,使用三元组表示,其可选的数值是 集合I的子集;可选的内存位置是集合L幂集的子集;可选的类型是集合T幂集的子集。
因此对于整个抽象值集合V来说,V的集合范围便是 集合 I x 集合L幂集 x 集合T 幂集。注意,2T 表示集合 T 的幂集。
内存位置用幂集子集来表示,是因为一个指针在静态分析时可能会指向多个内存位置;类型同理。
-
集合L,表示抽象内存位置集合。抽象内存位置可能有以下几种:
-
全局变量区某个固定的位置,因此用 Global(Z) 表示所有可能的全局变量集合
-
栈区某个固定位置,用二元组 (f, o) 表示函数 f 栈帧上相对偏移为 o 的位置,因此用 Stack(function ∗ Z) 表示所有可能的栈变量位置集合;堆区同理,不过堆区用的是 (a, o) 表示堆变量位置,表示地址 a 上相对偏移为 o 的位置。
上面这些都表示的是静态分析中相对较为固定的内存位置。
-
除了上面几种以外,还有一种内存位置是需要考虑的:符号指针 s 和指针偏移量为 o 的内存位置,用 SymLoc(s, o) 来指定抽象内存位置。
-
-
集合T,表示类型约束集合。对于一个变量来说,其类型,要么是一个确定的类型,要么就和 symbol 类型一样。注意这里是约束的集合,因此如果某个类型的约束集合为空,则表示可以为任何类型。
抽象语义(Abstract Semantics),个人认为是对 expr 或 stmt 具体干了什么做了一个描述。要理解这个得先把先前说的 IR 搬过来:
现在我们再来尝试理解对 expr 的 evaluation,一个一个来:

其中,V表示的是,在抽象状态 S 下,给定一个 expr ,返回其表示的 Abstract Value。
我们先看看什么是抽象状态 S:
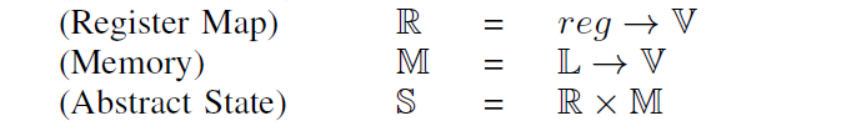
我们可以很容易的知道,抽象状态 S 保存了寄存器->V 的映射关系,以及内存位置 L -> V 的映射关系,这样的一个二维元组。简单来说,一个 State 保存了所有关于值的东西,即所有寄存器对应的值和所有内存位置对应的值。
因此,我们用 S[0] 来表示状态 S 下寄存器的映射关系 R,S[1] 表示状态 S 下内存位置的映射关系 M。
- V(reg)(S):这个公式是比较好理解的。对于状态S,若传入一个 reg,则会先获取状态 S 下的寄存器映射关系 R(即 S[0]),之后使用 reg 作为该映射关系的键,获取其值。
- V([e])(S):对于状态S,若传入一个表达式 e,则返回 e 所对应的内存位置上的值。这个公式等号后面的内容要拆开看。首先,我们需要获取表达式 e 所对应的 Abstract Value,即 V(e)(S)。返回的 Abstract Value 是一个三元组,其第1个 field 为 Memory Location(下标从0开始),因此 V(e)(S)[1]表示表达式 e 所有的内存位置集合。最后便是尝试访问在状态 S 下,其 Abstract Value 的所有内存位置,即 ⋃S[1][l]|l∈V(e)(S)[1]
- V(i)(S) :对于状态 S,获取整数表达式 i 所对应的 Abstract Value。
- 当 i=0 时,我们无法区分 i 是整数 0 还是空指针 NULL,因此只能忽略其类型约束。
- 当 i∈DataSection,则我们可以确定 i 是一个指向全局变量的指针值。因为 i 所指向的数值并非我们所关心的,因此用倒 T 表示。
- 其他情况下则认为 i 是一个普通整型。
- V(e1∗e2)(S):对于状态 S,获取其二元操作后的值。有个特殊的点在于,对于操作数组元素时,被操作的数组元素的 Memory Location,会被设置为 Array Base Memory Location,而不是精确的数组元素位置。这是为了防止索引范围爆炸所导致的内存位置爆炸。
接下来我们再试着理解 Stmt 的 evaluation:

其中,m[k→v] 表示把 m 从映射 k 强更新为 v;箭头上打个 w 表示是弱更新。在了解完 expr 相关的表达式后,我们可以较为容易的理解 Put、Store 和 update 原语,因此不再赘述。而对于 Call 原语来说,由于调用的函数可能会产生副作用(例如修改内存等等),因此需要额外处理。
这里,将一个函数的副作用定义为一个二元组,这样的二元组可以保存 什么样的参数导致什么样的内存修改 的信息:

而 apply 操作所要做的事情,就是将 Side Effect 中的 Update Set,apply 进状态 S 中:
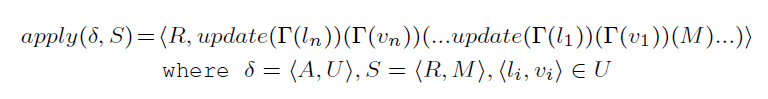
apply 原语中有个倒 L 符号,个人理解是,将某个函数对某个内存位置上的值,映射为另一个函数上另一个内存位置上的值。这么说有点拗口,举个简单的例子:caller 有个变量,位于 STACK(caller,−0x40),而 callee 则会访问 STACK(callee,−0x80)(caller 的局部变量),虽然看上去两个函数使用了不同的内存位置,但本质上这两个都指向的是同一个内存位置,因此需要做一个映射代换,那么倒L符号起到的就是这个替换作用。
-
-
Type Inferrer
类型推断器将会使用上一步所生成出的 summary 进行类型推断。难点在于结构体类型和数组类型推断。
首先是结构体类型推断。对于位于堆上的结构体来说,Inferrer 可以通过分析堆块所对应的状态来得出;但对于位于栈上的结构体来说,由于不像堆块那样隐含着边界信息,因此其他 field 可能会被误认为是其他的局部变量,很难去区分开到底栈上结构体中有哪些 field:

NTFuzz 在这里提出了一种启发式策略:通过函数中的内存访问模式,来判断某个栈变量是否为结构体中的一部分。
通俗的说,若某个相邻栈变量在初始化后从未使用,则说明这个变量是栈结构体中的一部分,将会被传递给 syscall;若这样的变量连初始化操作也没有,则说明这样的变量将会被 syscall 初始化。
其次是数组类型推断。数据类型分为两部分:数组元素类型和数组大小。其中数组元素类型可以通过 documented API 来获取;而数组大小可以通过 SAL 注释或者 API 参数的 size 参数来获取,以及还可以通过观察内存分配模式来获取。
有相当一部分 API 中的参数包含了数组指针和数组大小两部分,因此可以通过分析这些 API 来获取大小。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK