

uCore实验 - Lab4
source link: https://kiprey.github.io/2020/08/uCore-4/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

uCore实验 - Lab4
- 这里是笔者在完成
uCoreLab 4时写下的一些笔记 - 内容涉及进程/线程管理等
- 内容较多,建议使用右侧导航栏。
-
进程是指一个具有一定独立功能的程序在一个数据集合上的一次动态执行过程,其中包括正在运行的一个程序的所有状态信息。
-
进程是程序的执行,有核心态/用户态,是一个状态变化的过程
-
进程的组成包括程序、数据块和进程控制块PCB。
2) 进程控制块
进程控制块,Process Control Block, PCB。
- 进程控制块是操作系统管理控制进程运行所用的信息集合。操作系统用PCB来描述进程的基本情况以及运行变化的过程。
- PCB是进程存在的唯一标志 ,每个进程都在操作系统中有一个对应的PCB。
- 进程控制块可以通过某个数据结构组织起来(例如链表)。同一状态进程的PCB连接成一个链表,多个状态对应多个不同的链表。各状态的进程形成不同的链表:就绪联链表,阻塞链表等等。
3) 进程状态
进程的生命周期通常有6种情况:进程创建、进程执行、进程等待、进程抢占、进程唤醒、进程结束。
部分周期没有在图中标注。
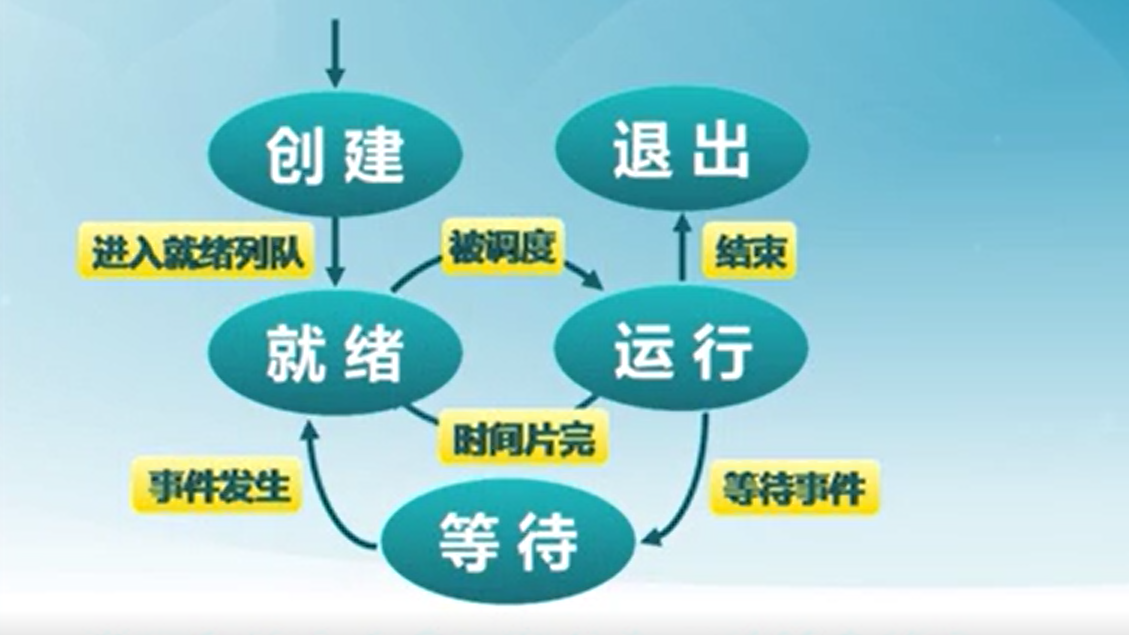
-
引起进程创建的情况:
- 系统初始化,创建idle进程。
- 用户或正在运行的进程请求创建新进程。
-
进程等待(阻塞)的情况:
- 进程请求并等待某个系统服务,无法马上完成。
- 启动某种操作,无法马上完成。
- 需要的数据没有到达。
只有该进程本身才能让自己进入休眠,但只有外部(例如操作系统)才能将该休眠的进程唤醒。
-
引起进程被抢占的情况
- 高优先级进程就绪
- 进程执行当前时间用完(时间片耗尽)
-
唤醒进程的情况:
- 被阻塞进程需要的资源可被满足。
- 被阻塞进程等待的事件到达。
进程只能被别的进程或操作系统唤醒。
-
进程结束的情况
- 正常或异常退出(自愿)
- 致命错误(强制性,例如SIGSEV)
- 被其他进程所
kill(强制)
4) 进程挂起
将处于挂起状态的进程映像在磁盘上,目的是减少进程占用的内存。
其模型图如下
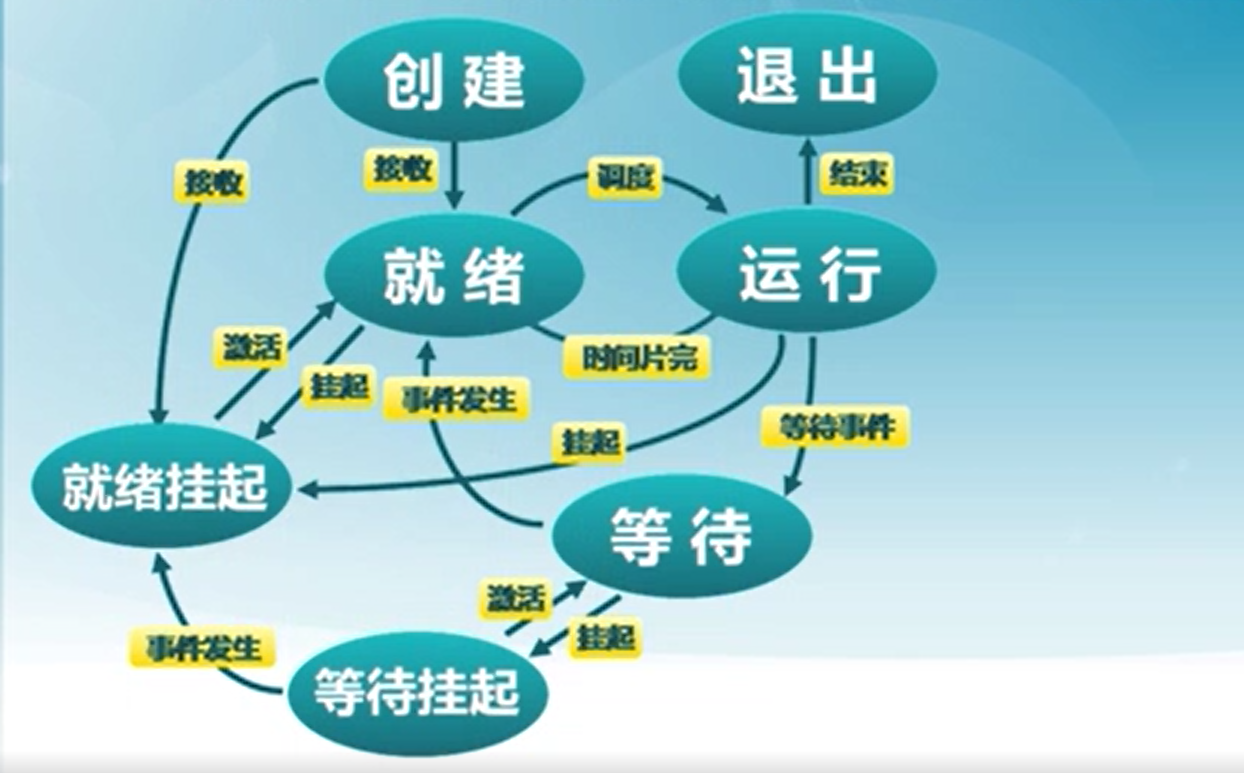
以下是状态切换的简单介绍
- 等待挂起(Blocked-suspend): 进程在外存并等待某事件的出现。
- 就绪挂起(Ready-suspend):进程在外存,但只要进入内存,即可运行。
- 挂起(Suspend):把一个进程从内存转到外存。
- 等待到等待挂起:没有进程处于就绪状态或就绪进程要求更多内存资源。
- 就绪到就绪挂起:当有高优先级进程处于等待状态(系统认为很快会就绪的),低优先级就绪进程会挂起,为高优先级进程提供更大的内存空间。
- 运行到就绪挂起:当有高优先级等待进程因事件出现而进入就绪挂起。
- 等待挂起到就绪挂起:当有等待挂起进程因相关事件出现而转换状态。
- 激活(Activate):把一个进程从外存转到内存
- 就绪挂起到就绪:没有就绪进程或挂起就绪进程优先级高于就绪进程。
- 等待挂起到等待:当一个进程释放足够内存,并有高优先级等待挂起进程。
线程是进程的一部分,描述指令流执行状态,是进程中的指令执行流最小单位,是CPU调度的基本单位。
进程的资源分配角色:进程由一组相关资源构成,包括地址空间、打开的文件等各种资源。
线程的处理机调度角色:线程描述在进程资源环境中指令流执行状态。
2) 优缺点
- 优点:
- 一个进程中可以存在多个线程
- 各个线程可以并发执行
- 各个线程之间可以共享地址空间和文件等资源。
- 缺点:
- 一个线程崩溃,会导致其所属的进程的所有线程崩溃。
3) 用户线程与内核线程
线程有三种实现方式
- 用户线程:在用户空间实现。(POSIX Pthread)
- 内核线程:在内核中实现。(Windows, Linux)
- 轻权进程:在内核中实现,支持用户线程。
a. 用户线程
用户线程是由一组用户级的线程库函数来完成线程的管理,包括线程的创建、终止、同步和调度等。
- 用户线程的特征
- 不依赖于操作系统内核,在用户空间实现线程机制。
- 可用于不支持线程的多进程操作系统。
- 线程控制模块(TCB)由线程库函数内部维护。
- 同一个进程内的用户线程切换速度块,无需用户态/核心态切换。
- 允许每个进程拥有自己的线程调度算法。
- 不依赖于操作系统内核,在用户空间实现线程机制。
- 用户进程的缺点
- 线程发起系统调用而阻塞时,整个进程都会进入等待状态。
- 不支持基于线程的处理机抢占。
- 只能按进程分配CPU时间。
b. 内核线程
内核线程是由内核通过系统调用实现的线程机制,由内核完成线程的创建、终止和管理。
内核线程的特征
- 由内核自己维护PCB和TCB
- 线程执行系统调用而被阻塞不影响其他线程。
- 线程的创建、终止和切换消耗相对较大。
- 以线程为单位进行CPU时间分配。其中多线程进程可以获得更多的CPU时间。
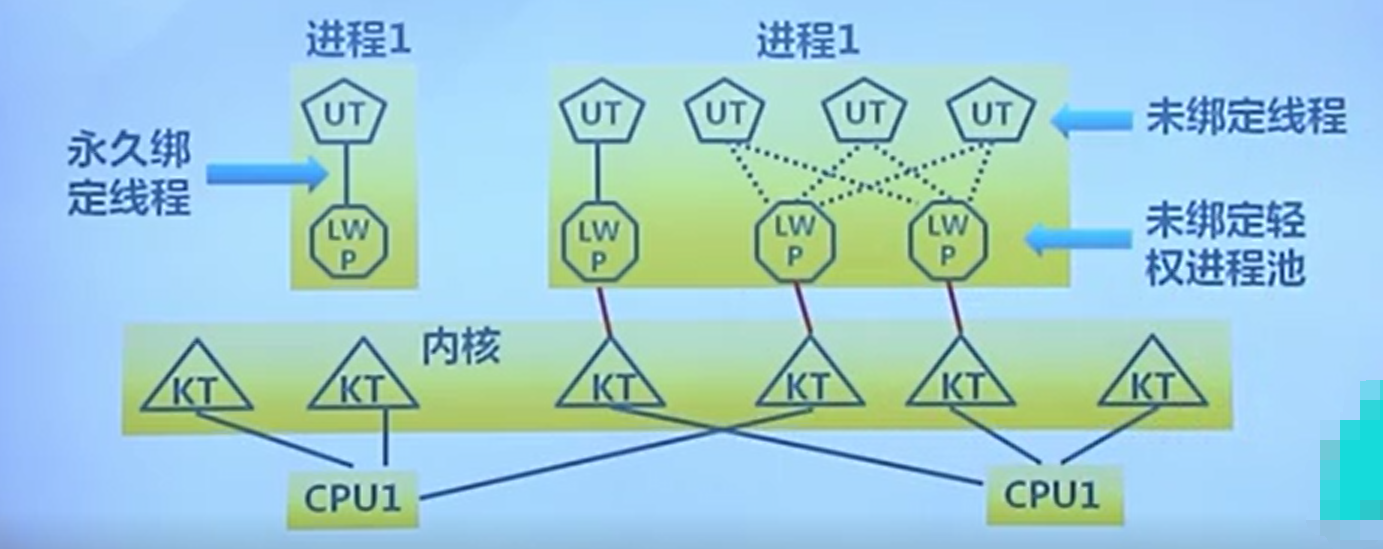
c. 轻权进程
用户线程可以自定义调度算法,但存在部分缺点。而内核线程不存在用户线程的各种缺点。
所以轻权进程是用户线程与内核线程的结合产物。
-
内核支持的用户线程。一个进程可包含一个或多个轻权进程,每个轻权进程由一个单独的内核线程来支持。
-
过于复杂以至于优点没有体现出来,最后演化为单一的内核线程支持。以下是其模型图:
3. 线程与进程的比较
- 进程是资源分配单元,而线程是CPU调度单位。
- 进程拥有一个完整的资源平台,而线程只独享指令流执行的必要资源,例如寄存器与栈。
- 线程具有就绪、等待和运行三种基本状态和状态间的转换关系。
- 线程能减小并发执行的事件和空闲开销。
- 线程的创建时间和终止时间比进程短。
- 同一进程内的线程切换时间比进程短。
- 由于同一进程的各线程间共享内存和文件资源,可不通过内核进行直接通信。
4. 进程控制
1) 进程切换
- 暂停当前进程,保存上下文,并从运行状态变成其他状态。
- 最后调度另一个进程,恢复其上下文并从就绪状态转为运行状态。
进程切换的要求:速度要快。
b. 进程控制块PCB
进程切换涉及到进程控制块PCB结构.
-
内核为每个进程维护了对应的进程控制块(PCB)
-
内核将相同状态的进程的PCB放置在同一队列里。
-
其中,uCore中PCB结构如下
enum proc_state {
PROC_UNINIT = 0, // 未初始化的 -- alloc_proc
PROC_SLEEPING, // 等待状态 -- try_free_pages, do_wait, do_sleep
PROC_RUNNABLE, // 就绪/运行状态 -- proc_init, wakeup_proc,
PROC_ZOMBIE, // 僵死状态 -- do_exit
};
struct context { // 保存的上下文寄存器,注意没有eax寄存器和段寄存器
uint32_t eip;
uint32_t esp;
uint32_t ebx;
uint32_t ecx;
uint32_t edx;
uint32_t esi;
uint32_t edi;
uint32_t ebp;
};
struct proc_struct {
enum proc_state state; // 当前进程的状态
int pid; // 进程ID
int runs; // 当前进程被调度的次数
uintptr_t kstack; // 内核栈
volatile bool need_resched; // 是否需要被调度
struct proc_struct *parent; // 父进程ID
struct mm_struct *mm; // 当前进程所管理的虚拟内存页,包括其所属的页目录项PDT
struct context context; // 保存的上下文
struct trapframe *tf; // 中断所保存的上下文
uintptr_t cr3; // 页目录表的地址
uint32_t flags; // 当前进程的相关标志
char name[PROC_NAME_LEN + 1]; // 进程名称(可执行文件名)
list_entry_t list_link; // 用于连接list
list_entry_t hash_link; // 用于连接hash list
};由于进程数量可能较大,倘若从头向后遍历查找符合某个状态的PCB,则效率会十分低下,因此使用了哈希表作为遍历所用的数据结构。
c. 切换流程
-
uCore中,内核的第一个进程
idleproc会执行cpu_idle函数,并从中调用schedule函数,准备开始调度进程。void cpu_idle(void) {
while (1)
if (current->need_resched)
schedule();
} -
schedule函数会先清除调度标志,并从当前进程在链表中的位置开始,遍历进程控制块,直到找出处于就绪状态的进程。之后执行
proc_run函数,将环境切换至该进程的上下文并继续执行。需要注意的是,这个进程调度过程中不能被CPU中断给打断,原因是这可能造成条件竞争。
void
schedule(void) {
bool intr_flag;
list_entry_t *le, *last;
struct proc_struct *next = NULL;
local_intr_save(intr_flag);
{
current->need_resched = 0;
last = (current == idleproc) ? &proc_list : &(current->list_link);
le = last;
do {
if ((le = list_next(le)) != &proc_list) {
next = le2proc(le, list_link);
if (next->state == PROC_RUNNABLE)
break;
}
} while (le != last);
if (next == NULL || next->state != PROC_RUNNABLE)
next = idleproc;
next->runs ++;
if (next != current)
proc_run(next);
}
local_intr_restore(intr_flag);
} -
proc_run函数会设置TSS中ring0的内核栈地址,同时还会加载页目录表的地址。等到这些前置操作完成后,最后执行上下文切换。同样,设置内核栈地址与加载页目录项等这类关键操作不能被中断给打断。
void proc_run(struct proc_struct *proc) {
if (proc != current) {
bool intr_flag;
struct proc_struct *prev = current, *next = proc;
local_intr_save(intr_flag);
{
// 设置当前执行的进程
current = proc;
// 设置ring0的内核栈地址
load_esp0(next->kstack + KSTACKSIZE);
// 加载页目录表
lcr3(next->cr3);
// 切换上下文
switch_to(&(prev->context), &(next->context));
}
local_intr_restore(intr_flag);
}
} -
切换上下文的操作基本上都是直接与寄存器打交道,所以
switch_to函数使用汇编代码编写,详细信息以注释的形式写入代码中。.text
.globl switch_to
switch_to: # switch_to(from, to)
# save from's registers
movl 4(%esp), %eax # 获取当前进程的context结构地址
popl 0(%eax) # 将eip保存至当前进程的context结构
movl %esp, 4(%eax) # 将esp保存至当前进程的context结构
movl %ebx, 8(%eax) # 将ebx保存至当前进程的context结构
movl %ecx, 12(%eax) # 将ecx保存至当前进程的context结构
movl %edx, 16(%eax) # 将edx保存至当前进程的context结构
movl %esi, 20(%eax) # 将esi保存至当前进程的context结构
movl %edi, 24(%eax) # 将edi保存至当前进程的context结构
movl %ebp, 28(%eax) # 将ebp保存至当前进程的context结构
# restore to's registers
movl 4(%esp), %eax # 获取下一个进程的context结构地址
# 需要注意的是,其地址不是8(%esp),因为之前已经pop过一次栈。
movl 28(%eax), %ebp # 恢复ebp至下一个进程的context结构
movl 24(%eax), %edi # 恢复edi至下一个进程的context结构
movl 20(%eax), %esi # 恢复esi至下一个进程的context结构
movl 16(%eax), %edx # 恢复edx至下一个进程的context结构
movl 12(%eax), %ecx # 恢复ecx至下一个进程的context结构
movl 8(%eax), %ebx # 恢复ebx至下一个进程的context结构
movl 4(%eax), %esp # 恢复esp至下一个进程的context结构
pushl 0(%eax) # 插入下一个进程的eip,以便于ret到下个进程的代码位置。
ret
2) 进程创建
-
在Unix中,进程通过系统调用
fork和exec来创建一个进程。- 其中,
fork把一个进程复制成两个除PID以外完全相同的进程。 exec用新进程来重写当前进程,PID没有改变。
- 其中,
-
fork创建一个继承的子进程。该子进程复制父进程的所有变量和内存,以及父进程的所有CPU寄存器(除了某个特殊寄存器,以区分是子进程还是父进程)。 -
fork函数一次调用,返回两个值。父进程中返回子进程的PID,子进程中返回0。 -
fork函数的开销十分昂贵,其实现开销来源于- 对子进程分配内存。
- 复制父进程的内存和寄存器到子进程中。
而且,在大多数情况下,调用
fork函数后就紧接着调用exec,此时fork中的内存复制操作是无用的。因此,fork函数中使用写时复制技术(Copy on Write, COW)。
a. 空闲进程的创建
-
空闲进程主要工作是完成内核中各个子系统的初始化,并最后用于调度其他进程。该进程最终会一直在
cpu_idle函数中判断当前是否可调度。 -
由于该进程是为了调度进程而创建的,所以其
need_resched成员初始时为1。 -
uCore创建该空闲进程的源代码如下
// 分配一个proc_struct结构
if ((idleproc = alloc_proc()) == NULL)
panic("cannot alloc idleproc.\n");
// 该空闲进程作为第一个进程,pid为0
idleproc->pid = 0;
// 设置该空闲进程始终可运行
idleproc->state = PROC_RUNNABLE;
// 设置空闲进程的内核栈
idleproc->kstack = (uintptr_t)bootstack;
// 设置该空闲进程为可调度
idleproc->need_resched = 1;
set_proc_name(idleproc, "idle");
nr_process++;
// 设置当前运行的进程为该空闲进程
current = idleproc;
b. 第一个内核进程的创建
-
第一个内核进程是未来所有新进程的父进程或祖先进程。
-
uCore创建第一个内核进程的代码如下
// 创建init的主线程
int pid = kernel_thread(init_main, "Hello world!!", 0);
if (pid <= 0) {
panic("create init_main failed.\n");
}
// 通过pid 查找proc_struct
initproc = find_proc(pid);
set_proc_name(initproc, "init"); -
在
kernel_thread中,程序先设置trapframe结构,最后调用do_fork函数。注意该trapframe部分寄存器ebx、edx、eip被分别设置为目标函数地址、参数地址以及kernel_thread_entry地址(稍后会讲)。int
kernel_thread(int (*fn)(void *), void *arg, uint32_t clone_flags) {
struct trapframe tf;
memset(&tf, 0, sizeof(struct trapframe));
tf.tf_cs = KERNEL_CS;
tf.tf_ds = tf.tf_es = tf.tf_ss = KERNEL_DS;
// ebx = fn
tf.tf_regs.reg_ebx = (uint32_t)fn;
// edx = arg
tf.tf_regs.reg_edx = (uint32_t)arg;
// eip = kernel_thread_entry
tf.tf_eip = (uint32_t)kernel_thread_entry;
return do_fork(clone_flags | CLONE_VM, 0, &tf);
} -
do_fork函数会执行以下操作- 分配新进程的PCB,并设置PCB相关成员,包括父进程PCB地址,新内核栈地址,新PID等等。
- 复制/共享当前进程的所有内存空间到子进程里。
- 复制当前线程的上下文状态至子进程中。
- 将子进程PCB分别插入至普通双向链表与哈希表中,设置该子进程为可执行,并最终返回该子进程的PID。
int
do_fork(uint32_t clone_flags, uintptr_t stack, struct trapframe *tf) {
int ret = -E_NO_FREE_PROC;
struct proc_struct *proc;
if (nr_process >= MAX_PROCESS)
goto fork_out;
ret = -E_NO_MEM;
// 首先分配一个PCB
if ((proc = alloc_proc()) == NULL)
goto fork_out;
// fork肯定存在父进程,所以设置子进程的父进程
proc->parent = current;
// 分配内核栈
if (setup_kstack(proc) != 0)
goto bad_fork_cleanup_proc;
// 将所有虚拟页数据复制过去
if (copy_mm(clone_flags, proc) != 0)
goto bad_fork_cleanup_kstack;
// 复制线程的状态,包括寄存器上下文等等
copy_thread(proc, stack, tf);
// 将子进程的PCB添加进hash list或者list
// 需要注意的是,不能让中断处理程序打断这一步操作
bool intr_flag;
local_intr_save(intr_flag);
{
proc->pid = get_pid();
hash_proc(proc);
list_add(&proc_list, &(proc->list_link));
nr_process ++;
}
local_intr_restore(intr_flag);
// 设置新的子进程可执行
wakeup_proc(proc);
// 返回子进程的pid
ret = proc->pid;
fork_out:
return ret;
bad_fork_cleanup_kstack:
put_kstack(proc);
bad_fork_cleanup_proc:
kfree(proc);
goto fork_out;
} -
do_fork函数中的copy_thread函数会执行以下操作-
将
kernel_thread中创建的新trapframe内容复制到该proc的tf成员中,并压入该进程自身的内核栈。 -
设置
trapframe的eax寄存器值为0,esp寄存器值为传入的esp,以及eflags加上中断标志位。设置eax寄存器的值为0,是因为子进程的fork函数返回的值为0。
-
最后,设置子进程上下文的
eip为forkret,esp为该trapframe的地址。
static void
copy_thread(struct proc_struct *proc, uintptr_t esp, struct trapframe *tf) {
proc->tf = (struct trapframe *)(proc->kstack + KSTACKSIZE) - 1;
*(proc->tf) = *tf;
proc->tf->tf_regs.reg_eax = 0;
proc->tf->tf_esp = esp;
proc->tf->tf_eflags |= FL_IF;
proc->context.eip = (uintptr_t)forkret;
proc->context.esp = (uintptr_t)(proc->tf);
} -
-
当该子进程被调度运行,上下文切换后(即此时current为该子进程的PCB地址),子进程会跳转至
forkret,而该函数是forkrets的一个wrapper。static void forkret(void) {
forkrets(current->tf);
}forkrets是干什么用的呢?从current->tf中恢复上下文,跳转至current->tf->tf_eip,也就是kernel_thread_entry。# return falls through to trapret...
.globl __trapret
__trapret:
# restore registers from stack
popal
# restore %ds, %es, %fs and %gs
popl %gs
popl %fs
popl %es
popl %ds
# get rid of the trap number and error code
addl $0x8, %esp
iret
.globl forkrets
forkrets:
# set stack to this new process's trapframe
movl 4(%esp), %esp
jmp __trapret -
kernel_thread_entry的代码非常简单,压入%edx寄存器的值作为参数,并调用%ebx寄存器所指向的代码,最后保存调用的函数的返回值,并do_exit。以
initproc为例,该函数此时的%edx即"Hello world!!"字符串的地址,%ebx即init_main函数的地址。.text.
.globl kernel_thread_entry
kernel_thread_entry: # void kernel_thread(void)
pushl %edx # push arg
call *%ebx # call fn
pushl %eax # save the return value of fn(arg)
call do_exit # call do_exit to terminate current threadkernel_thread函数设置控制流起始地址为kernel_thread_entry的目的,是想让一个内核进程在执行完函数后能够自动调用do_exit回收资源。
3) 进程终止
这里只简单介绍进程的有序终止。
- 进程结束时调用
exit(),完成进程资源回收。 exit函数调用的功能- 将调用参数作为进程的“结果”
- 关闭所有打开的文件等占用资源。
- 释放大部分进程相关的内核数据结构
- 检查父进程是否存活
- 如果存活,则保留结果的值,直到父进程使用。同时当前进程进入僵尸(zombie)状态。
- 如果没有,它将释放所有的数据结构,进程结束。
- 清理所有等待的僵尸进程。
- 进程终止是最终的垃圾收集(资源回收)。
1) 练习1
分配并初始化一个进程控制块。
alloc_proc函数(位于kern/process/proc.c中)负责分配并返回一个新的struct proc_struct结构,用于存储新建立的内核线程的管理信息。ucore需要对这个结构进行最基本的初始化,你需要完成这个初始化过程。
相关实现代码如下
static struct proc_struct * alloc_proc(void) {
struct proc_struct *proc = kmalloc(sizeof(struct proc_struct));
if (proc != NULL) {
//LAB4:EXERCISE1 YOUR CODE
proc->state = PROC_UNINIT;
proc->pid = -1;
proc->runs = 0;
proc->kstack = 0;
proc->need_resched = 0;
proc->parent = NULL;
proc->mm = NULL;
memset(&(proc->context), 0, sizeof(struct context));
proc->tf = NULL;
proc->cr3 = boot_cr3;
proc->flags = 0;
memset(proc->name, 0, PROC_NAME_LEN);
}
return proc;
}
- 请说明proc_struct中
struct context context和struct trapframe *tf成员变量含义和在本实验中的作用是什么?-
struct context context:储存进程当前状态,用于进程切换中上下文的保存与恢复。需要注意的是,与
trapframe所保存的用户态上下文不同,context保存的是线程的当前上下文。这个上下文可能是执行用户代码时的上下文,也可能是执行内核代码时的上下文。 -
struct trapframe* tf:无论是用户程序在用户态通过系统调用进入内核态,还是线程在内核态中被创建,内核态中的线程返回用户态所加载的上下文就是struct trapframe* tf。 所以当一个线程在内核态中建立,则该新线程就必须伪造一个trapframe来返回用户态。思考一下,从用户态进入内核态会压入当时的用户态上下文
trapframe。 -
两者关系:以
kernel_thread函数为例,尽管该函数设置了proc->trapframe,但在fork函数中的copy_thread函数里,程序还会设置proc->context。两个上下文看上去好像冗余,但实际上两者所分的工是不一样的。进程之间通过进程调度来切换控制权,当某个
fork出的新进程获取到了控制流后,首当其中执行的代码是current->context->eip所指向的代码,此时新进程仍处于内核态,但实际上我们想在用户态中执行代码,所以我们需要从内核态切换回用户态,也就是中断返回。此时会遇上两个问题:- 新进程如何执行中断返回? 这就是
proc->context.eip = (uintptr_t)forkret的用处。forkret会使新进程正确的从中断处理例程中返回。 - 新进程中断返回至用户代码时的上下文为? 这就是
proc_struct->tf的用处。中断返回时,新进程会恢复保存的trapframe信息至各个寄存器中,然后开始执行用户代码。
- 新进程如何执行中断返回? 这就是
-
2) 练习2
为新创建的内核线程分配资源
do_fork的作用是,创建当前内核线程的一个副本,它们的执行上下文、代码、数据都一样,但是存储位置不同。在这个过程中,需要给新内核线程分配资源,并且复制原进程的状态。
实现代码如下,详细信息以注释的形式写到代码中:
int do_fork(uint32_t clone_flags, uintptr_t stack, struct trapframe *tf) {
int ret = -E_NO_FREE_PROC;
struct proc_struct *proc;
if (nr_process >= MAX_PROCESS) {
goto fork_out;
}
ret = -E_NO_MEM;
//LAB4:EXERCISE2 YOUR CODE
// 首先分配一个PCB
if ((proc = alloc_proc()) == NULL)
goto fork_out;
// fork肯定存在父进程,所以设置子进程的父进程
proc->parent = current;
// 分配内核栈
if (setup_kstack(proc) != 0)
goto bad_fork_cleanup_proc;
// 将所有虚拟页数据复制过去
if (copy_mm(clone_flags, proc) != 0)
goto bad_fork_cleanup_kstack;
// 复制线程的状态,包括寄存器上下文等等
copy_thread(proc, stack, tf);
// 将子进程的PCB添加进hash list或者list
// 需要注意的是,不能让中断处理程序打断这一步操作
bool intr_flag;
local_intr_save(intr_flag);
{
proc->pid = get_pid();
hash_proc(proc);
list_add(&proc_list, &(proc->list_link));
nr_process ++;
}
local_intr_restore(intr_flag);
// 设置新的子进程可执行
wakeup_proc(proc);
// 返回子进程的pid
ret = proc->pid;
fork_out:
return ret;
bad_fork_cleanup_kstack:
put_kstack(proc);
bad_fork_cleanup_proc:
kfree(proc);
goto fork_out;
}
-
请说明ucore是否做到给每个新fork的线程一个唯一的id?请说明你的分析和理由。
get_pid这个函数其实我一开始是没打算研究的,谁知道竟然出成题目了T_T。uCore中,每个新fork的线程都存在唯一的一个ID,理由如下:
-
在函数
get_pid中,如果静态成员last_pid小于next_safe,则当前分配的last_pid一定是安全的,即唯一的PID。 -
但如果
last_pid大于等于next_safe,或者last_pid的值超过MAX_PID,则当前的last_pid就不一定是唯一的PID,此时就需要遍历proc_list,重新对last_pid和next_safe进行设置,为下一次的get_pid调用打下基础。 -
之所以在该函数中维护一个合法的
PID的区间,是为了优化时间效率。如果简单的暴力搜索,则需要搜索大部分PID和所有的线程,这会使该算法的时间消耗很大,因此使用PID区间来优化算法。 -
get_pid代码如下:// get_pid - alloc a unique pid for process
static int
get_pid(void) {
static_assert(MAX_PID > MAX_PROCESS);
struct proc_struct *proc;
list_entry_t *list = &proc_list, *le;
static int next_safe = MAX_PID, last_pid = MAX_PID;
if (++ last_pid >= MAX_PID) {
last_pid = 1;
goto inside;
}
if (last_pid >= next_safe) {
inside:
next_safe = MAX_PID;
repeat:
le = list;
while ((le = list_next(le)) != list) {
proc = le2proc(le, list_link);
if (proc->pid == last_pid) {
if (++ last_pid >= next_safe) {
if (last_pid >= MAX_PID)
last_pid = 1;
next_safe = MAX_PID;
goto repeat;
}
}
else if (proc->pid > last_pid && next_safe > proc->pid)
next_safe = proc->pid;
}
}
return last_pid;
}
-
3) 练习3
阅读代码,理解 proc_run 函数和它调用的函数如何完成进程切换的。
请移步切换流程
- 在本实验的执行过程中,创建且运行了几个内核线程?
- 两个内核线程,分别是
idleproc和initproc。 - 更多关于
idleproc和initproc的信息请移步 idleproc的创建 和 initproc的创建
- 两个内核线程,分别是
- 语句
local_intr_save(intr_flag);....local_intr_restore(intr_flag);在这里有何作用?请说明理由。- 这两句代码的作用分别是阻塞中断和解除中断的阻塞。
- 这两句的配合,使得这两句代码之间的代码块形成原子操作,可以使得某些关键的代码不会被打断,从而避免引起一些未预料到的错误,避免条件竞争。
- 以进程切换为例,在
proc_run中,当刚设置好current指针为下一个进程,但还未完全将控制权转移时,如果该过程突然被一个中断所打断,则中断处理例程的执行可能会引发异常,因为current指针指向的进程与实际使用的进程资源不一致。
4) 扩展练习
实现支持任意大小的内存分配算法
考虑到现在的slab算法比较复杂,有必要实现一个比较简单的任意大小内存分配算法。可参考本实验中的slab如何调用基于页的内存分配算法来实现first-fit/best-fit/worst-fit/buddy等支持任意大小的内存分配算法。
暂鸽,后补。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK