

uCore实验 - Lab7
source link: https://kiprey.github.io/2020/09/uCore-7/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

- 这里是笔者在完成
uCoreLab 7时写下的一些笔记 - 内容涉及信号、管程、死锁和进程通信的一些相关实现。
1. 原子操作(Atomic Operator)
-
原子操作是指一次不存在任何中断或失效的操作
-
该操作只有两种情况
- 操作成功执行
- 操作没有执行
不存在出现部分执行的情况
- 操作系统需要利用同步机制在并发执行的同时,保存一些操作是原子操作。
2. 进程的交互关系
相互感知的程度 交互关系 进程间的影响 相互不感知(完全不了解其他进程的存在) 独立 一个进程的操作对其他进程的结果无影响 间接感知(双方都与第三方交互,例如数据共享) 通过共享进行协作 一个进程的结果依赖于共享资源的状态 直接感知(双方直接交互,例如通信) 通过通信进行协作 一个进程的结果依赖于从其他进程获得的信息
进程之间可能出现三种关系:
- 互斥(mutual exclusion):一个进程占用资源,其他进程不能使用
- 死锁(deadlock):多个进程占用部分资源,形成循环等待
- 饥饿(starvation):其他进程可能轮流占用资源,一个进程一直得不到资源
3. 临界区
a. 相关区域的概念
- 临界区(critical section):进程中访问临界资源的一段需要互斥执行的代码。
- 进入区(entry section):检查可否进入临界区的一段代码。如果可以进入,则设置“正在访问临界区”标志
- 退出区(exit section): 清除标志
- 剩余区(remainder section): 代码中的其余部分
b. 临界区的访问规则
空闲则入、忙则等待、有限等待、让权等待(可选)
让权等待:让不能进入临界区的进程暂时释放CPU资源。
c. 临界区的实现方法
1) 禁用中断
-
无中断,无上下文切换,因此无并发
-
硬件将中断处理延迟到中断被启用之后
-
现代计算机体系结构都提供指令来实现禁用中断。
local_irq_save(unsigned long flags);
critical_section
local_irq_restore(unsigned long flags);
-
-
进入临界区:禁止所有中断,并保存标志
-
离开临界区:使能所有中断,并恢复标志
-
-
禁用中断后,进程无法被停止
- 整个系统都会因此停下
- 可能导致其他进程处于饥饿状态
-
临界区可能很长,无法确定响应中断所需的时间
-
仅限于单处理器
-
2) 基于软件的同步解决方法
线程可通过共享一些共有变量来同步它们的行为。
-
Peterson算法(两线程之间的同步互斥算法)
-
int turn; // 表示该谁进入临界区
bool flag[]; // 表示进程是否准备好进入临界区 -
进入区代码
// 设置当前线程想进入临界区
flag[i] = true;
// 先让另一个进程执行
turn = j;
// 如果另一个进程想进入同时也可进入临界区,则当前进程等待
while(flag[j] && turn == j)
; -
退出区代码
// 设置当前线程不想进入临界区
flag[i] = false; -
// 线程Ti的代码
do{
// 设置当前线程想进入临界区
flag[i] = true;
// 先让另一个进程执行
turn = j;
// 如果另一个进程想进入同时也可进入临界区,则当前进程等待
while(flag[j] && turn == j)
;// 忙等待
CRITICAL SECTION
flag[i] = false;
REMAINDER SECTION
}while(true);
-
-
Dekkers算法。逻辑与Peterson类似,为另一种的两线程之间的同步互斥算法。所不同的是这个算法可以很方便的扩展至多个线程。
// 线程Ti的代码
flag[0] = flag[1] = false;
turn = 0;
do{
// 设置当前进程想进入临界区
flag[i] = true;
// 如果上一个进程想进入临界区,则先让它进
while(flag[j] == true)
{
// 如果目前轮到的进程不是当前进程
if(turn != i)
{
// 则取消进入临界区的标记
flag[i] = false;
// 并等待轮到当前进程
while(turn != i)
; // 忙等待
// 一旦轮到当前进程,则设置进入临界区的标记
flag[i] = true;
}
}
CRITICAL SECTION
// 当前进程临界区已经执行完成,轮换至下一个进程
turn = j;
flag[i] = false;
REMAINDER SECTION
}while(true); -
N线程的软件方法(Eisenberg和McGuire)
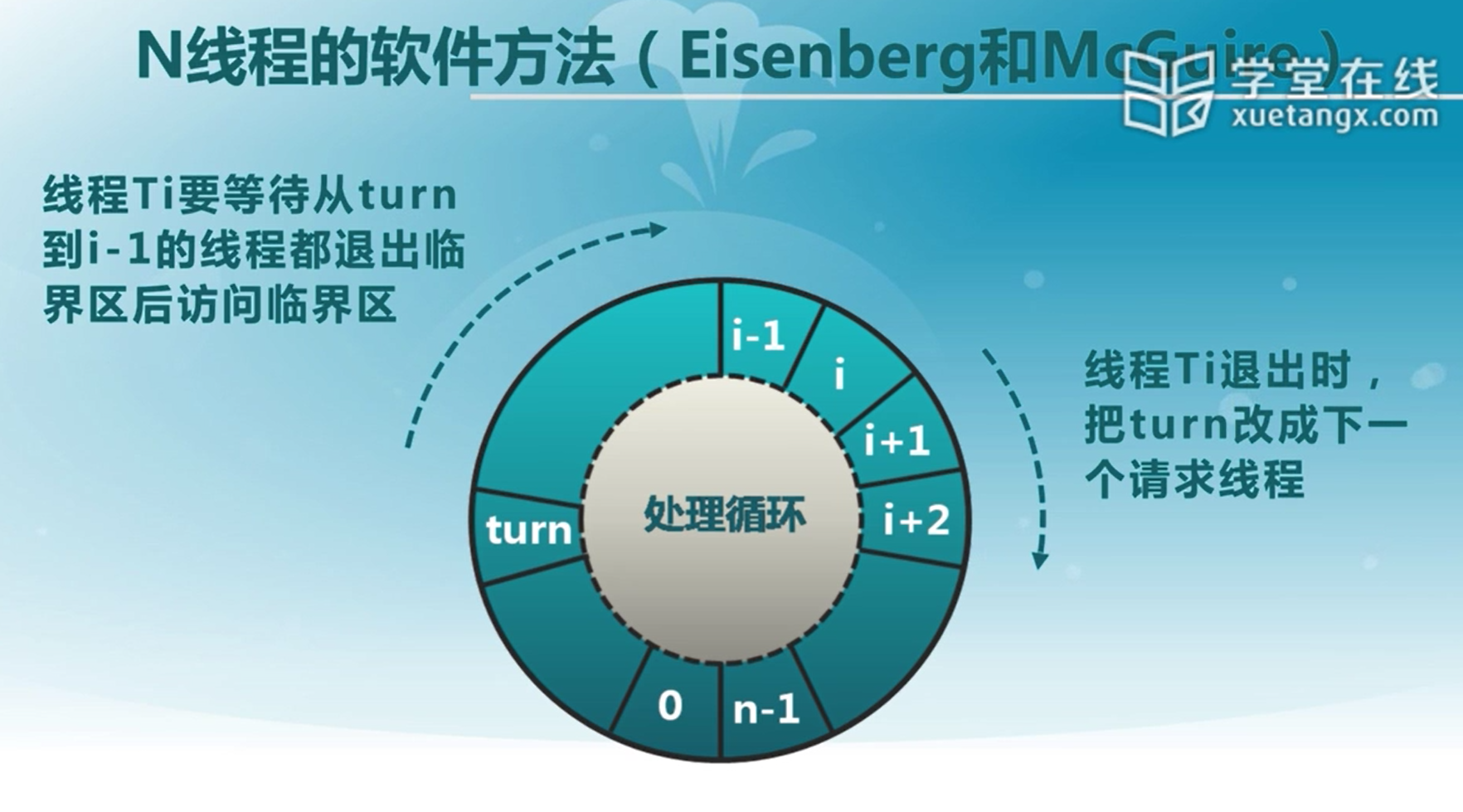
-
- 复杂:需要两个进程间的共享数据项
- 需要忙等待:浪费CPU时间
3) 更高级的抽象方法
-
硬件提供一些同步原语:例如中断禁用,原子操作指令等
-
操作系统提供更高级的编程抽象来简化进程同步:例如锁、信号量,或者用硬件原语来构造、
-
锁(lock)
-
锁是一个抽象的数据结构
- 使用一个二进制变量,用于表示锁定/解锁
- Lock::Acquire() : 锁被释放前一直等待,直到得到锁
- Lock::Release() : 释放锁,唤醒任何等待的进程
-
使用锁来控制临界区访问
lock_next_pid->Acquire();
next_pid = next_pid++;
lock_next_pid->Release();
-
-
原子操作指令
-
现代CPU体系结构都提供一些特殊的原子操作指令
-
测试和置位(Test-and-Set)指令
从内存中获取值,测试该值是否为1,并设置内存单元值为1
bool TestAndSet(bool *target)
{
bool ret = *target;
*target = 1;
return ret;
} -
交换指令(exchange)
交换内存中的两个值
void exchange(bool *a, bool* b)
{
bool tmp = *a;
*a = *b;
*b = tmp;
}
-
-
使用TS指令实现自旋锁(spinlock)
-
自旋忙等待锁
class Lock{
int value = 0;
void Acquire()
{
// 如果锁被释放,则读取并设置value为1
// 如果锁被占用,则一直循环查找
while(test-and-set(value))
; // spin,线程在等待时需要消耗CPU资源
}
void Release()
{
value = 0;
}
} -
无忙等待锁(非自旋锁)
class Lock{
int value = 0;
WaitQueue q;
void Acquire()
{
// 如果锁被释放,则读取并设置value为1
// 如果锁被占用,则一直循环查找
while(test-and-set(value))
{
// 当前进程无法获取到锁,进入等待队列
q.push_back(currentThread->PCB);
// 调度至其他线程中运行
schedule();
}
}
void Release()
{
value = 0;
// 唤醒等待队列中的线程
PCB& t = q.pop_front();
wakeup(t);
}
}
-
-
原子操作锁的特征
-
- 适用于单处理器或者共享主存的多处理器中任意数量的进程同步
- 简单并容易证明
- 支持多临界区
-
-
忙等待消耗处理器时间
-
可能导致饥饿:进程离开临界区时有多个等待进程的情况
-
死锁:拥有临界区的低优先级进程,以及请求访问临界区的高优先级进程获得处理器并等待临界区。
-
-
4. 信号量
a. 相关概念
-
信号量(Semaphore)是操作系统提供的一种协调共享资源访问的方法
- 软件同步是平等线程间的一种同步协商机制
- OS是管理者,地位高于进程
- 用信号量表示系统资源的数量
-
信号量是一种抽象数据类型
- 由一个整数(sem)变量和两个原子操作组成
- P() :
sem--,如果sem<0,则进入等待,否则继续 - V() :
sem++, 如果sem <= 0, 唤醒一个等待进程
-
信号量是被保护的整数变量
- 初始化完成后,只能通过 P() 和 V() 操作修改
- 由操作系统来保证,PV操作是原子操作
-
P() 可能阻塞,但 V() 不会阻塞
-
通常,假定信号量是“公平的”
-
即,线程不会被无限期阻塞在P() 操作中
-
假定信号量等待按先进先出排队
自旋锁不能实现先进先出
-
-
信号量的一种实现方式
与用户自己编写的锁不同,操作系统保证PV操作是原子操作。
class Semaphore{
int sem;
WaitQueue q;
void P()
{
// 由于操作系统的保证,修改变量与条件判断之间不可能会出现条件竞争
sem--;
if(sem < 0){
Add this thread t to q;
block(p);
}
}
void V()
{
sem++;
if(sem <= 0){
Remove a thread t from q;
wakeup(t);
}
}
}
b. 信号量的分类
-
信号量可分为两种信号量
- 二进制信号量,资源数目为0/1
- 资源信号量:资源数目为任何非负值
两者等价,基于某一个可以实现另一个
-
信号量的使用
- 互斥访问:临界区的互斥访问控制
- 条件同步:线程间的事件等待
-
用信号量实现临界区的互斥访问
- 每类资源设置一个信号量,其初值为1
- 必须成对使用P()和V()操作
- P()操作保证互斥访问临界资源
- V()操作在使用后释放临界资源
- PV操作不能次序颠倒,重复或遗漏q
-
- 读/开发代码较为困难。程序员需要能运用信号量机制
- 容易出错。使用的信号量已经被另一个线程占用,或者忘记释放信号量
- 无法处理死锁问题
生产者-消费者问题
-
- 一个或多个的生产者在生成数据后放在一个缓冲区中
- 单个消费者从缓冲区取出数据处理
- 任何时刻只能有一个生产者或消费者可访问该缓冲区
-
- 任何时刻只能有一个线程操作缓冲区(互斥访问)
- 缓冲区为空时,消费者必须等待生产者(条件同步)
- 缓冲区为满时,生产者必须等待消费者(条件同步)
-
用信号量描述每个约束
- 二进制信号量mutex
- 资源信号量
fullBuffers - 资源信号量
emptyBuffers
-
class BoundedBuffer{
mutex = new Semaphore(1);
fullBuffers = new Semaphore(0);
emptyBuffers = new Semaphore(n);
void Deposit(c)
{
// 占用当前的空闲缓冲区(如果当前缓冲区已满,则挂起)
emptyBuffers->P();
// 独占当前缓冲区(如果当前缓冲区正在被使用,则挂起)
mutext->P();
Add c to the buffer;
// 释放当前缓冲区的占用
mutext->V();
// 由于向缓冲区中写入了数据,所以增加满缓冲区的资源数
fullBuffers->V();
}
void Remove(c)
{
fullBuffers->P();
mutext->P();
remove c from the buffer;
mutext->V();
emptyBuffers->V();
}
}需要注意的是,PV操作的顺序一定要对应,否则可能出现死锁情况!
a. 相关概念
- 管程(Monitor)是一种用于多线程互斥访问共享资源的程序结构
- 采用面向对象方法,简化了线程间的同步控制
- 任一时刻最多只有一个线程执行管程代码
- 正在管程中的线程可临时放弃管程的互斥访问,等待事件出现时恢复
- 管程的使用
- 在对象/模块中,收集相关共享数据
- 定义访问共享数据的方法
- 管程的组成
- 一个锁,控制管程代码的互斥访问
- 0-n个条件变量,用于管理共享数据的并发访问
- 引入管程机制的目的:
- 把分散在各进程中的临界区集中起来进行管理
- 防止进程有意或无意的违法同步操作
- 便于用高级语言来书写程序,也便于程序正确性验证。
b. 条件变量
-
条件变量(Condition Variable)是管程内的等待机制
- 进入管程的线程因资源被占用而进入等待状态
- 每个条件变量表示一种等待原因,对应一个等待队列
-
Wait() 操作
- 将自己阻塞在等待队列中
- 唤醒一个等待者或释放管程的互斥访问
-
Signal() 操作
- 将等待队列中的一个线程唤醒
- 如果等待队列为空,则等同空操作
-
用条件变量来解决生产者-消费者问题
该部分代码请结合“用管程解决生产者-消费者问题”理解
class Condition{
int numWaiting = 0;
WaitQueue q;
void Wait(lock)
{
numWaiting++;
add this thread t to q;
release(lock); // 释放原先占有的锁
schedule(); // need mutex
require(lock); // 获取原先被释放的锁
}
void Signal()
{
if(numWaiting > 0)
{
Release a thread t from q;
wakeup(t);
numWaiting--;
}
}
} -
用管程解决生产者-消费者问题
class BoundBuffer{
...
Lock lock;
int count = 0;
Condition notFull, notEmpty;
void Deposit(c)
{
lock->Acquire();
// 如果写入的数据达到缓冲区的最大尺寸
while(count == n)
// 则当前线程等待
notFull.Wait(&lock);
Add c to the buffer;
count++;
notEmpty.Signal();
lock->Release();
}
void Remove()
{
lock->Acquire();
// 如果当前缓冲区为空,则等待
while(count == 0)
notEmpty.Wait(&lock);
Remove c from buffer;
count--;
notFull.Signal();
lock->Release();
}
} -
条件变量的释放处理方式
当T2线程执行Signal函数后,控制权应保留至T2线程结束,还是立即切换回T1线程呢?这两种不同的情况分别为Hasen管程与Hoare管程。
-
Hasen管程
Hasen管程在某个线程执行Signal函数后,控制权不立即移交至另一个线程,而是先执行当前线程。
-
T1线程 T2线程 l.acquire()
…
x.wait()
l.acquire()
…
x.signal()
…
l.release() …
x.release()
-
特点:线程切换次数较少,效率较高,主要用于真实OS和Java中。
- 条件变量的释放只是一个提示
- 需要重新检查条件
-
void Deposit(c)
{
lock->Acquire();
// 注意判断关键字为while
while(count == n)
notFull.Wait(&lock);
Add c to the buffer;
count++;
notEmpty.Signal();
lock->Release();
}
-
-
Hoare管程
Hoare管程在某个线程执行Signal函数后,控制权立即移交至另一个线程。
-
T1线程 T2线程 l.acquire()
…
x.wait()
l.acquire()
…
x.signal() …
l.release()
…
l.release()
-
特点:通常的分析中,T1线程优先执行是更合理的,但需要做多次线程切换,低效。主要见于教科书中
- 条件变量释放同时表示放弃管程访问
- 释放后条件变量的状态可用
-
void Deposit(c)
{
lock->Acquire();
// 注意判断关键字为if
if(count == n)
notFull.Wait(&lock);
Add c to the buffer;
count++;
notEmpty.Signal();
lock->Release();
}
-
-
6. 互斥综合:读者-写者问题
a. 问题描述
- 共享数据的两类使用者
- 读者:只读取数据,不修改
- 写者:读取和修改数据
- 问题描述:对共享数据的读写
- 读-读允许:同一时刻允许多个读者同时读
- 读-写互斥:没有写者时读者才能读; 没有读者时写者才能写。
- 写-写互斥:没有其他写者时写者才能写
b. 用信号量解决问题
以下实现为读者优先。
class Reader_Writer{
mutex WriteMutex = new mutex(1); // 控制读写操作的互斥
mutex CountMutex = new mutex(1); // 控制对读者计数的互斥修改
int Rcount = 0; // 共享变量,需要互斥修改
void Write()
{
P(WriteMutex);
write;
V(WriteMutex);
}
void Read()
{
P(CountMutex);
if(Rcount == 0)
P(WriteMutex);
++Rcount;
V(CountMutex);
read;
P(CountMutex);
--Rcount;
if(Rcount == 0)
V(WriteMutex);
V(CountMutex);
}
}
c. 优先策略
- 读者优先策略
- 只要有读者正在读状态,后来的读者都能直接进入
- 如果读者持续不断的进入,则写者处于饥饿
- 写者优先策略
- 只要有写者就绪,写者应该尽快执行写操作
- 如果写者持续不断的就绪,则读者处于饥饿状态
- 具体使用哪种策略,取决于具体的环境。
d. 用管程解决问题
class Database{
private:
int AR = 0; // active readers
int AW = 0; // active Writers
int WR = 0; // waiting readers
int WW = 0; // waiting writers
Lock lock;
Condition okToRead;
Condition okToWrite;
// 读者开始读
void StartRead()
{
lock.Acquire();
// 如果有写者正在/准备写入数据
while(AW+WW > 0)
{
// 当前读者开始等待写者完成
WR++;
okToRead.wait(&lock);
WR--;
}
// 读者开始读了,激活的读者+1
AR++;
lock.Release();
}
// 读者结束读
void DoneRead()
{
lock.Acquire();
// 读者读取完成,激活的读者-1
AR--;
// 如果当前没有正在读的读者,并且当前有正在等待的写者
if(AR == 0 && WW > 0)
// 激活某个写者开始写入数据
okToWrite.signal();
lock.Release();
}
// 写者准备开始写
void StartWrite()
{
lock.Acquire();
// 如果当前有正在读的读者或正在写的写者
while(AW+AR > 0)
{
// 当前写者等待
WW++;
okToWrite.wait(&lock);
WW--;
}
AW++;
lock.Release();
}
// 写者结束写
void DOneWrite()
{
lock.Acquire();
// 当前写者结束写操作
AW--;
// 如果存在等待的写者
if(WW > 0)
// 唤醒某个等待的写者
okToWrite.signal();
// 如果没有等待的写者,但有等待的读者
else if(WR > 0)
// 唤醒所有读者开始等待数据
okToRead.broadcast();
lock.Release();
}
public:
void Read()
{
// wait until no readers
StartRead();
read database;
// checkout - wake up waiting writers;
DoneRead();
}
void Write()
{
// wait until no readers/writers
StartWrite();
write database;
// checkout - wake up waiting readers/writers;
DoneWrite();
}
}
a. 死锁概念
1) 进程访问资源的流程
- 资源类型R1,R2,…,RmR1,R2,…,Rm: CPU执行时间,内存空间,I/O设备等。
- 每类资源RiRi有WiWi个实例
- 进程访问资源的流程
- 请求/获取:申请空闲资源
- 使用/占用:进程占用资源
- 释放:资源状态由占用变成空闲。
2) 资源分类
- 可重用资源(Reusable Resource)
- 资源不能被删除且自任何时刻只能有一个进程在使用
- 进程释放资源后,其他进程可重用
- 可重用资源示例:硬件如处理器、I/O设备等,软件如文件、数据库等
- 可能出现死锁:每个进程占用一部分资源并请求其他资源
- 消费资源 (Consumable resource)
- 资源创建和销毁
- 消耗资源示例:中断、信号、消息
- 可能出现死锁:进程间相互等待接收对方的消息
3) 出现死锁的必要条件
- 互斥:任何时刻只能有一个进程使用一个资源实例
- 持有并等待:进程保持至少一个资源,并正在等待获取其他进程持有的资源
- 非抢占:资源只能在进程使用后自愿释放
- 循环等待:进程间相互循环等待
b. 死锁处理方法
死锁检测较为复杂,通常由应用程序处理死锁,操作系统会忽略死锁
1) 死锁预防
死锁预防(Deadlock Prevention) : 确保系统永远不会进入死锁状态。
预防是采用某种策略,限制并发进程对资源的请求,使系统在任何时刻都不满足死锁的必要条件。
-
互斥:把互斥的共享资源封装成可同时访问的
-
持有并等待:进程请求资源时,要求它不持有任何其他资源。仅允许进程在开始执行时,一次请求所有需要的资源,但这种做法的资源利用率低。
-
非抢占:如进程请求不能立即分配的资源,则释放已经占用的资源。只在能够同时获得所有需要资源时,才执行分配操作。
-
循环等待:对资源排序,要求进程按顺序请求资源。
2) 死锁避免
死锁避免(Deadlock Avoidance):在使用前进行判断,只允许不会出现死锁的进程请求资源。
利用额外的先验信息,在分配资源时判断是否会出现死锁,只在不会出现死锁时分配资源。
- 要求进程声明需要资源的最大数目。
- 限定提供与分配的资源数量,确保满足进程的最大需求。
- 动态检查资源分配状态,确保不会出现环形等待。
系统资源分配的安全状态
- 当进程请求资源时,系统判断分配后是否处于安全状态。
- 系统处于安全状态:针对所有已占用进程,存在安全序列
- 序列<P1,P2,…,PN><P1,P2,…,PN>是安全的
- PiPi要求的资源 <= 当前可用资源 + 所有PjPj持有资源。其中
j<i。 - 如果PiPi的资源请求不能马上分配,则PiPi等待所有Pj(j<i)Pj(j<i)完成
- PiPi完成后,Pi+1Pi+1可得到所需资源,执行并释放所分配的资源。
- 最终整个序列的所有PiPi都能获得所需资源。
- PiPi要求的资源 <= 当前可用资源 + 所有PjPj持有资源。其中
银行家算法(Banker’s Algorithm)
银行家算法是一个避免死锁产生的算法,以银行借贷分配策略为基础,判断并保证系统处于安全状态。
-
使用的数据结构
n = 线程数量, m = 资源类型数量
- Max(总需求量):n x m 矩阵,线程TiTi最多请求类型RiRi的资源Max[i,j]Max[i,j]个实例
- Available(剩余空闲量):长度为m的向量,当前有Available[i]Available[i]个类型RjRj的资源实例可用
- Allocation(已分配量):n x m 矩阵,线程TiTi当前分配了Allocation[i,j]Allocation[i,j]个RjRj的实例
- Need(未来需要量): n x m矩阵,线程TiTi未来需要Need[i,j]Need[i,j]个RjRj资源实例。
Need[i,j]=Max[i,j]−Allocation[i,j]Need[i,j]=Max[i,j]−Allocation[i,j]
-
安全状态判断
// Work和Finish分别是长度为m和n的向量初始化
Work[m], Finish[n];
Work = Available; // 当前资源剩余空闲量
for(int i = 0; i < n; i++)
Finish[i] = false; // 线程i没结束
// ...每个线程开始运行并分配资源
// 在一段时间后
// 寻找Need比Work小,同时还未结束的线程Ti
while(Finish[i] == false && Need[i] <= Work)
{
// 线程i的资源需求量小于当前剩余空闲资源量,所以该线程可以正常结束,并回收该线程的所有资源
Work += Allocation[i];
Finish[i] = true;
}
// 如果所有线程Ti都满足Finish[i] == true,则系统处于安全状态。
if(Finish == true)
Safe;
else
// 反之,系统处于不安全状态。
NoSafe; -
银行家算法具体设计
-
初始化:RequestiRequesti:线程TiTi的资源请求向量, Requesti[j]Requesti[j]:线程TiTi请求资源RjRj的实例
-
-
如果Requesti<=Need[i]Requesti<=Need[i],则转到步骤2。否则拒绝资源申请,因为线程已经超过了其最大资源要求。
-
如果Requesti<=AvailableRequesti<=Available,转到步骤3。否则,TiTi必须等待,因为资源不可用。
-
通过安全状态判断来确定是否分配资源给TiTi
-
生成一个需要判断状态是否安全的资源分配环境
Available = Available - Request_i;
Allocation[i] = Allocation[i] + Request_i;
Need[i] = Need[i] - Request_i; -
并调用上文的安全状态判断
- 如果返回结果是安全,则将资源分配给TiTi
- 如果返回结果是不安全,系统会拒绝TiTi的资源请求
-
-
-
3) 死锁检测和恢复
死锁检测和恢复(Deadlock Detection & Recovery) : 在检测到运行系统进入死锁状态后进行恢复。
-
- 允许系统进入死锁状态
- 维护系统的资源分配图
- 定期调用死锁检测算法来搜索图中是否存在死锁
- 出现死锁时,用死锁恢复机制进行恢复。
-
- Available(剩余空闲量):长度为m的向量,每种类型可用资源的数量
- Allocation(已分配量):n x m 矩阵,当前分配给各个进程每种类型资源的数量,进程PiPi拥有资源RiRi的Allocation[i,j]Allocation[i,j]个实例。
-
死锁检测算法
该算法与银行家算法类似。
// Work和Finish分别是长度为m和n的向量初始化
Work[m], Finish[n];
Work = Available; // 当前资源剩余空闲量
for(int i = 0; i < n; i++)
{
// 如果当前遍历到的线程占用资源,则设置Finish为false
// 反之,如果当前线程不占用资源,则要么是线程已结束,要么是我们不关心的线程
if(Allocation[i] > 0)
Finish[i] = false; // 线程i没结束
else
Finish[i] = true;
}
// ...每个线程开始运行并分配资源
// 在一段时间后
// 寻找Request比Work小,同时还未结束的线程Ti
while(Finish[i] == false && Request[i] <= Work)
{
// 线程i的资源需求量小于当前剩余空闲资源量,所以该线程可以正常结束,并回收该线程的所有资源
Work += Allocation[i];
Finish[i] = true;
}
// 如果所有线程Ti都满足Finish[i] == true,则系统处于正常状态
if(Finish == true)
NoDeadlock;
else
// 反之,系统处于死锁状态。
Deadlock; -
死锁检测算法的使用
- 死锁检测的时间和周期选择依据
- 死锁多久可能会发生
- 多少进程需要被回滚
- 资源图可能有多个循环,难以分辨”造成“死锁的关键进程
- 死锁检测的时间和周期选择依据
- 进程终止
- 终止所有的死锁线程
- 一次只终止一个进程直到死锁消除
- 终止进程的顺序应该是
- 进程的优先级
- 进程已运行时间以及还需运行时间
- 进程已占用资源
- 进程完成需要的资源
- 进程完成需要的资源
- 终止进程数目
- 进程是交互式还是批处理
- 资源抢占
- 选择被抢占进程:最小成本目标
- 进程回退:返回到一些安全状态,重启进程到安全状态
- 可能会出现饥饿:同一个进程可能一直被选作被抢占者
8. 进程通信
a. 基本概念
-
进程通信(IPC, Inter-Process Communication)是进程进行通信和同步的机制
-
IPC提供2个基本操作:发送操作send和接收操作receive
-
进程通信流程
- 在通信进程间建立通信链路
- 通过send/receive交换信息
-
进程链路特征
- 物理(如:共享内存,硬件总线)
- 逻辑(如:逻辑属性)
1) 直接通信
- 进程必须正确的命名对方
- send(P, message) - 发送信息到进程P
- receive(P, message) - 从进程Q接收信息
- 通信链路的属性
- 自动建立链路
- 一条链路恰好对应一对通信进程
- 每对进程之间只有一个链接存在
- 链接可以是单向,但通常是双向。
2) 间接通信
- 通过操作系统维护的消息队列实现进程间的消息接收和发送
- 每个消息队列都有一个唯一的标识
- 只有共享了相同消息队列的进程,才能够通信。
- 通信链路的属性
- 只有共享了相同消息队列的进程,才建立了连接。
- 连接可以是单向或双向的。
- 消息队列可以与多个进程相关联。
- 通信流程
- 创建一个新的消息队列
- 通过消息队列发送或接收消息
- 销毁消息队列
- 基本通信操作
- send(A, message) - 发送消息到队列A
- receive(A, message) - 从队列A接收消息
3) 阻塞与非阻塞通信
- 进程通信可划分为阻塞(同步)和非阻塞(异步)
- 阻塞通信
- 阻塞发送:发送者在发送消息后进入等待,直到接收者成功收到
- 阻塞接收:接收者在请求接收数据后进入等待,直到成功收到一个消息
- 非阻塞通信
- 非阻塞发送:发送者在消息发送后,可立即进行其他操作
- 非阻塞接收:没有消息发送时,接收者在请求接收消息后,接收不到任何消息
4) 通信链路缓冲
进程发送的消息在链路上可能有3种缓冲方式
- 0容量:发送方必须等待接收方
- 有限容量:通信链路缓冲队列满时,发送方必须等待
- 无限容量:发送方不需要等待
- 信号(signal) :进程间的软件中断通知和处理机制,例如
SIGKILL,SIGSTOP,SIGCONT等 - 信号的接收处理
- 捕获(catch): 执行进程指定的信号处理函数被调用
- 忽略(Ignore):执行操作系统指定的缺省处理,例如进程终止、进程挂起等
- 屏蔽(Mask):禁止进程接收和处理信号(可能是暂时的)
- 不足:传送的信息量小,只有一个信号类型
- 管道(pipe)是进程间基于内存文件的通信机制
- 子进程从父进程继承文件描述符
- 缺省文件描述符: 0 stdin, 1 stdout, 2 stderr
- 进程不知道另一端
- 可能从键盘、文件、程序读取
- 可能写入到终端、文件、程序
- 与管道相关的系统调用
- 读管道:
read(fd, buffer, nbytes)。scanf基于此实现。 - 写管道:
write(fd, buffer, nbytes)。printf基于此实现。 - 创建管道:
pipe(fd)rgfd是两个文件描述符组成的数组rgfd[0]是读文件描述符rgfd[1]是写文件描述符
- 读管道:
d. 消息队列
- 消息队列是由操作系统维护的以字节序列为基本单位的间接通信机制
- 每个消息(message)是一个字节序列
- 相同标识的消息组成按先进先出顺序组成一个消息队列(message queues)
- 消息队列的系统调用
msgget(key, flag): 获取消息队列标识msgsnd(QID, buf, size, flag): 发送消息msgrcv(QID, buf, size, type, flag): 接收消息msgctl(...): 消息队列控制
e. 共享内存
-
共享内存是把同一个物理内存区域同时映射到多个进程的内存地址空间的通信机制。
-
进程间共享
- 每个进程都有私有内存地址空间
- 每个进程的内存地址空间需明确设置共享内存段
-
线程间共享:同一个进程中的线程总是共享相同的内存地址空间
-
优点:快速、方便地共享数据
-
缺点:必须使用额外的同步机制来协调数据访问。
-
共享内存的系统调用
shmget(key, size, flags): 创建共享段shmat(shmid, *shmaddr, flags):把共享段映射到进程地址空间shmdt(*shmaddr): 取消共享段到进程地址空间的映射shmctl(...): 共享段控制- 需要信号量等机制协调共享内存的访问冲突。
填写已有实验。
搜索一下Lab7关键词,只需要将原先lab6kern/trap/trap.c中
case IRQ_OFFSET + IRQ_TIMER:
ticks++;
assert(current != NULL);
sched_class_proc_tick(current);
break;
替换为以下代码即可。
case IRQ_OFFSET + IRQ_TIMER:
ticks ++;
assert(current != NULL);
run_timer_list(); // 注意这里
break;
定时器timer
-
timer_t结构用于存储一个定时器所需要的相关数据,包括倒计时时间以及所绑定的进程。typedef struct {
unsigned int expires; //the expire time
struct proc_struct *proc; //the proc wait in this timer. If the expire time is end, then this proc will be scheduled
list_entry_t timer_link; //the timer list
} timer_t; -
add_timer用于将某个timer添加进timer列表中。处于性能考虑,每个新添加的timer都会按照其
expires属性的大小排列,同时减去上一个timer的expires属性。一个例子:两个尚未添加进列表中的timer:
timer1->expires = 20;
timer2->expires = 38;
将这两个timer添加进列表后:(注意timer2的expires)
+------------+ +----------------------+ +--------------------------+
| timer_list | <---> | timer1->expires = 20 | <---> | timer2->expires = 18 !!! |
+------------+ +----------------------+ +--------------------------+这样,在更新timer_list中的所有timer的expires时,只需递减链首的第一个timer的expire,即可间接达到所有timer的expires减一的目的。
该函数源代码如下
// add timer to timer_list
void add_timer(timer_t *timer) {
bool intr_flag;
local_intr_save(intr_flag);
{
assert(timer->expires > 0 && timer->proc != NULL);
assert(list_empty(&(timer->timer_link)));
list_entry_t *le = list_next(&timer_list);
// 减去每个遍历到的timer的expires
while (le != &timer_list) {
timer_t *next = le2timer(le, timer_link);
if (timer->expires < next->expires) {
next->expires -= timer->expires;
break;
}
timer->expires -= next->expires;
le = list_next(le);
}
// 将当前timer添加至列表中
list_add_before(le, &(timer->timer_link));
}
local_intr_restore(intr_flag);
} -
run_timer_list函数用于更新定时器的时间,并更新当前进程的运行时间片。如果当前定时器的剩余时间结束,则唤醒某个处于WT_INTERRUPTED等待状态的进程。有一点在上个函数中提到过:递减timer_list中每个timer的expires时,只递减链头第一个timer的expires。该函数的源代码如下// call scheduler to update tick related info, and check the timer is expired? If expired, then wakup proc
void run_timer_list(void) {
bool intr_flag;
local_intr_save(intr_flag);
{
list_entry_t *le = list_next(&timer_list);
if (le != &timer_list) {
timer_t *timer = le2timer(le, timer_link);
assert(timer->expires != 0);
// 只递减链头timer的expires
timer->expires --;
while (timer->expires == 0) {
le = list_next(le);
struct proc_struct *proc = timer->proc;
if (proc->wait_state != 0) {
assert(proc->wait_state & WT_INTERRUPTED);
}
else {
warn("process %d's wait_state == 0.\n", proc->pid);
}
wakeup_proc(proc);
del_timer(timer);
if (le == &timer_list) {
break;
}
timer = le2timer(le, timer_link);
}
}
sched_class_proc_tick(current);
}
local_intr_restore(intr_flag);
} -
将timer从timer_list中删除的操作比较简单:设置好当前待移除timer的下一个timer->expires,并将当前timer从链表中移除即可。
// del timer from timer_list
void del_timer(timer_t *timer) {
bool intr_flag;
local_intr_save(intr_flag);
{
if (!list_empty(&(timer->timer_link))) {
if (timer->expires != 0) {
list_entry_t *le = list_next(&(timer->timer_link));
if (le != &timer_list) {
timer_t *next = le2timer(le, timer_link);
next->expires += timer->expires;
}
}
list_del_init(&(timer->timer_link));
}
}
local_intr_restore(intr_flag);
} -
一个简单的例子,
do_sleep函数int do_sleep(unsigned int time) {
if (time == 0) {
return 0;
}
bool intr_flag;
local_intr_save(intr_flag);
// 设置定时器
timer_t __timer, *timer = timer_init(&__timer, current, time);
current->state = PROC_SLEEPING;
current->wait_state = WT_TIMER;
// 启用定时器
add_timer(timer);
local_intr_restore(intr_flag);
// 当前进程放弃CPU资源
schedule();
// 时间到点了,删除当前timer
del_timer(timer);
return 0;
} -
定时器的用处:定时器可以帮助操作系统在经过一段特定时间后执行一些特殊操作,例如唤醒执行线程。可以说,正是有了定时器,操作系统才有了时间这个概念。
理解内核级信号量的实现和基于内核级信号量的哲学家就餐问题
-
哲学家就餐问题
-
uCore中的哲学家就餐主要代码较为简单:每个哲学家拿起叉子,进食,然后放下叉子。
int state_sema[N]; /* 记录每个人状态的数组 */
/* 信号量是一个特殊的整型变量 */
semaphore_t mutex; /* 临界区互斥 */
semaphore_t s[N]; /* 每个哲学家一个信号量 */
struct proc_struct *philosopher_proc_sema[N];
int philosopher_using_semaphore(void * arg) /* i:哲学家号码,从0到N-1 */
{
int i, iter=0;
i=(int)arg;
cprintf("I am No.%d philosopher_sema\n",i);
while(iter++<TIMES)
{ /* 无限循环 */
cprintf("Iter %d, No.%d philosopher_sema is thinking\n",iter,i); /* 哲学家正在思考 */
do_sleep(SLEEP_TIME);
phi_take_forks_sema(i);
/* 需要两只叉子,或者阻塞 */
cprintf("Iter %d, No.%d philosopher_sema is eating\n",iter,i); /* 进餐 */
do_sleep(SLEEP_TIME);
phi_put_forks_sema(i);
/* 把两把叉子同时放回桌子 */
}
cprintf("No.%d philosopher_sema quit\n",i);
return 0;
} -
拿起 / 放下叉子时,由于需要修改当前哲学家的状态,同时该状态是全局共享变量,所以需要获取锁来防止条件竞争。
将叉子放回桌上时,如果当前哲学家左右两边的两位哲学家处于饥饿状态,即准备进餐但没有刀叉时,如果条件符合,则唤醒这两位哲学家并让其继续进餐。
void phi_take_forks_sema(int i) /* i:哲学家号码从0到N-1 */
{
down(&mutex); /* 进入临界区 */
state_sema[i]=HUNGRY; /* 记录下哲学家i饥饿的事实 */
phi_test_sema(i); /* 试图得到两只叉子 */
up(&mutex); /* 离开临界区 */
down(&s[i]); /* 如果得不到叉子就阻塞 */
}
void phi_put_forks_sema(int i) /* i:哲学家号码从0到N-1 */
{
down(&mutex); /* 进入临界区 */
state_sema[i]=THINKING; /* 哲学家进餐结束 */
phi_test_sema(LEFT); /* 看一下左邻居现在是否能进餐 */
phi_test_sema(RIGHT); /* 看一下右邻居现在是否能进餐 */
up(&mutex); /* 离开临界区 */
} -
phi_test_sema函数用于设置哲学家的进食状态。如果当前哲学家满足进食条件,则更新哲学家状态,执行哲学家锁所对应的V操作,以唤醒等待叉子的哲学家所对应的线程。void phi_test_sema(i) /* i:哲学家号码从0到N-1 */
{
if(state_sema[i]==HUNGRY&&state_sema[LEFT]!=EATING
&&state_sema[RIGHT]!=EATING)
{
state_sema[i]=EATING;
up(&s[i]);
}
}
-
-
请给出内核级信号量的设计描述,并说明其大致执行流程
-
内核中的信号量结构体如下,与操作系统理论课所实现的相差不大
typedef struct {
int value;
wait_queue_t wait_queue;
} semaphore_t; -
进入临界区时,uCore会执行
down函数down(&mutex); /* 进入临界区 */
与之相对的,退出临界区时会执行
up函数up(&mutex); /* 离开临界区 */
down函数和up函数分别是_down和_up的wrapper。它们除了传入信号量以外,还会传入一个等待状态wait_state。 -
_down函数会递减当前信号量的value值。如果value在递减前为0,则将其加入至等待队列wait_queue中,并使当前线程立即放弃CPU资源,调度至其他线程。注意其中的原子操作。该函数的源码如下:static __noinline uint32_t __down(semaphore_t *sem, uint32_t wait_state) {
bool intr_flag;
local_intr_save(intr_flag);
if (sem->value > 0) {
// value值递减
sem->value --;
local_intr_restore(intr_flag);
return 0;
}
// 如果在上一步中,值已经为0了,则将当前进程添加进等待队列中
wait_t __wait, *wait = &__wait;
wait_current_set(&(sem->wait_queue), wait, wait_state);
local_intr_restore(intr_flag);
// 进程调度
schedule();
// 从等待队列中删除当前进程
local_intr_save(intr_flag);
wait_current_del(&(sem->wait_queue), wait);
local_intr_restore(intr_flag);
if (wait->wakeup_flags != wait_state) {
return wait->wakeup_flags;
}
return 0;
} -
_up函数实现的功能稍微简单一点:如果没有等待线程则value++,否则唤醒第一条等待线程。注意:
_up函数如果选择唤醒第一条等待线程的话,则value不加一static __noinline void __up(semaphore_t *sem, uint32_t wait_state) {
bool intr_flag;
local_intr_save(intr_flag);
{
wait_t *wait;
// 如果当前等待队列中没有线程等待,则value照常+1
if ((wait = wait_queue_first(&(sem->wait_queue))) == NULL) {
sem->value ++;
}
// 否则如果当前等待队列中存在线程正在等待,则唤醒该线程并开始执行对应代码
else {
assert(wait->proc->wait_state == wait_state);
wakeup_wait(&(sem->wait_queue), wait, wait_state, 1);
}
}
local_intr_restore(intr_flag);
}
-
-
请给出给用户态进程/线程提供信号量机制的设计方案,并比较说明给内核级提供信号量机制的异同
-
内核为用户态进程/线程提供信号量机制时,需要设计多个应用程序接口,而用户态线程只能通过这些内核提供的接口来使用内核服务。借鉴于Linux提供的标准接口,内核提供的这些接口可分别为:
/*Initialize semaphore object SEM to VALUE. If PSHARED then share it
with other processes. */
int sem_init (sem_t *__sem, int __pshared, unsigned int __value);
/* Free resources associated with semaphore object SEM. */
// 将信号量所使用的资源全部释放
int sem_destroy (sem_t *__sem);
/* Open a named semaphore NAME with open flags OFLAG. */
// 开启一个新信号量,并使用给定的flag来指定其标志
sem_t *sem_open (const char *__name, int __oflag, ...);
/* Close descriptor for named semaphore SEM. */
// 将当前信号量所使用的描述符关闭
int sem_close (sem_t *__sem);
/* Remove named semaphore NAME. */
int sem_unlink (const char *__name);
/* Wait for SEM being posted.
This function is a cancellation point and therefore not marked with
__THROW. */
// 一个P操作,如果sem value > 0,则sem value--;否则阻塞直到sem value > 0
int sem_wait (sem_t *__sem);
/* Test whether SEM is posted. */
int sem_trywait (sem_t *__sem);
/* Post SEM. */
// 一个V操作,把指定的信号量 sem 的值加 1,唤醒正在等待该信号量的任意线程。
int sem_post (sem_t *__sem);
/* Get current value of SEM and store it in *SVAL. */
// 获取当前信号量的值
int sem_getvalue (sem_t *__restrict __sem, int *__restrict __sval); -
- 其核心的实现逻辑是一样的
-
- 内核态的信号量机制可以直接调用内核的服务,而用户态的则需要通过内核提供的接口来访问内核态服务,这其中涉及到了用户态转内核态的相关机制。
- 内核态的信号量存储于内核栈中;但用户态的信号量存储于用户栈中。
-
总体任务:完成内核级条件变量和基于内核级条件变量的哲学家就餐问题
- 基于信号量实现完成条件变量实现,给出内核级条件变量的设计描述,并说明其大致执行流程。
-
管程由一个锁和多个条件变量组成,以下是管程和条件变量的结构体代码
typedef struct monitor monitor_t;
typedef struct condvar{
semaphore_t sem; // 条件变量所对应的信号量
int count; // 等待当前条件变量的等待进程总数
monitor_t * owner; // 当前条件变量的父管程
} condvar_t;
typedef struct monitor{
semaphore_t mutex; // 管程锁,每次只能有一个进程执行管程代码。该值初始化为1
semaphore_t next; // the next semaphore is used to down the signaling proc itself, and the other OR wakeuped waiting proc should wake up the sleeped signaling proc.
int next_count; // the number of of sleeped signaling proc
condvar_t *cv; // 当前管程中存放所有条件变量的数组
} monitor_t;注意:
monitor结构中next信号量的功能请在下文结合cond_signal说明来理解。 -
初始化管程时,函数
monitor_init会初始化传入管程的相关成员变量,并为该管程设置多个条件变量并初始化。// Initialize monitor.
void monitor_init (monitor_t * mtp, size_t num_cv) {
int i;
assert(num_cv>0);
mtp->next_count = 0;
mtp->cv = NULL;
// 初始化管程锁为1
sem_init(&(mtp->mutex), 1); //unlocked
sem_init(&(mtp->next), 0);// 注意这里的0
// 分配当前管程内的条件变量
mtp->cv =(condvar_t *) kmalloc(sizeof(condvar_t)*num_cv);
assert(mtp->cv!=NULL);
// 初始化管程内条件变量的各个属性
for(i=0; i<num_cv; i++){
mtp->cv[i].count=0;
sem_init(&(mtp->cv[i].sem),0);
mtp->cv[i].owner=mtp;
}
} -
当某个线程准备离开临界区、准备释放对应的条件变量时,线程会执行函数
cond_signal。该函数同样是这次要实现的函数之一。-
如果不存在线程正在等待带释放的条件变量,则不执行任何操作
-
否则,对传入条件变量内置的信号执行V操作。注意:这一步可能会唤醒某个等待线程。
-
关键的一步! 函数内部接下来会执行
down(&(cvp->owner->next))操作。由于monitor::next在初始化时就设置为0,所以当执行到该条代码时,无论如何,当前正在执行cond_signal函数的线程一定会被挂起。这也正是管程中next信号量的用途。为什么要做这一步呢?原因是保证管程代码的互斥访问。
一个简单的例子:线程1因等待条件变量a而挂起,过了一段时间,线程2释放条件变量a,此时线程1被唤醒,并等待调度。注意!此时在管程代码中,存在两个活跃线程(这里的活跃指的是正在运行/就绪线程),而这违背了管程的互斥性。因此,线程2在释放条件变量a后应当立即挂起以保证管程代码互斥。而
next信号量便是帮助线程2立即挂起的一个信号。
以下是该函数的实现代码:
// Unlock one of threads waiting on the condition variable.
void cond_signal (condvar_t *cvp) {
//LAB7 EXERCISE1: YOUR CODE
cprintf("cond_signal begin: cvp %x, cvp->count %d, cvp->owner->next_count %d\n", cvp, cvp->count, cvp->owner->next_count);
/*
* cond_signal(cv) {
* if(cv.count>0) {
* mt.next_count ++;
* signal(cv.sem);
* wait(mt.next);
* mt.next_count--;
* }
* }
*/
if(cvp->count>0) {
cvp->owner->next_count ++;
up(&(cvp->sem));
down(&(cvp->owner->next));
cvp->owner->next_count --;
}
cprintf("cond_signal end: cvp %x, cvp->count %d, cvp->owner->next_count %d\n", cvp, cvp->count, cvp->owner->next_count);
} -
-
当某个线程需要等待锁时,则会执行
cond_wait函数。而该函数是我们这次要实现的函数之一。-
当某个线程因为等待条件变量而准备将自身挂起前,此时条件变量中的
count变量应自增1。cvp->count++;
-
之后当前进程应该释放所等待的条件变量所属的管程互斥锁,以便于让其他线程执行管程代码。
但如果存在一个已经在管程中、但因为执行
cond_signal而挂起的线程,则优先继续执行该线程。有关“因为执行
cond_signal而挂起的线程”的详细信息,请阅读上方cond_signal函数的介绍来了解。如果程序选择执行
up(&(cvp->owner->next)),请注意:此时mutex没有被释放。因为当前线程将被挂起,原先存在于管程中的线程被唤醒,此时管程中仍然只有一个活跃线程,不需要让新的线程进入管程。if(cvp->owner->next_count > 0)
up(&(cvp->owner->next));
else
up(&(cvp->owner->mutex)); -
释放管程后,尝试获取该条件变量。如果获取失败,则当前线程将在
down函数的内部被挂起。down(&(cvp->sem));
-
若当前线程成功获取条件变量,则当前等待条件变量的线程数减一。
cvp->count--;
这样就结束了吗?想想看为什么当线程成功获取条件变量时,不重新申请管程的互斥锁。
以下是一个简单的流程:线程1执行wait被挂起,释放管程的mutex,之后线程2获取mutex并进入管程,然后执行了signal唤醒线程1,同时挂起自身。在这个过程中,管程中自始自终都只存在一个活跃线程(原先的线程1执行,线程2未进入,到线程1挂起,线程2进入,再到线程1被唤醒,线程2挂起)。而此时mutex在线程1被唤醒前就已被线程2所获取,新线程无法进入管程,因此被唤醒的线程1不需要再次获取mutex。由于管程锁已被获取(不管是哪个线程获取)、管程中只有一个活跃线程,因此我们可以近似将管程锁视为是当前线程获取的。
以下是最终代码:
// Suspend calling thread on a condition variable waiting for condition Atomically unlocks
// mutex and suspends calling thread on conditional variable after waking up locks mutex. Notice: mp is mutex semaphore for monitor's procedures
void
cond_wait (condvar_t *cvp) {
//LAB7 EXERCISE1: YOUR CODE
cprintf("cond_wait begin: cvp %x, cvp->count %d, cvp->owner->next_count %d\n", cvp, cvp->count, cvp->owner->next_count);
/*
* cv.count ++;
* if(mt.next_count>0)
* signal(mt.next)
* else
* signal(mt.mutex);
* wait(cv.sem);
* cv.count --;
*/
cvp->count++;
if(cvp->owner->next_count > 0)
up(&(cvp->owner->next));
else
up(&(cvp->owner->mutex));
down(&(cvp->sem));
cvp->count--;
cprintf("cond_wait end: cvp %x, cvp->count %d, cvp->owner->next_count %d\n", cvp, cvp->count, cvp->owner->next_count);
} -
-
管程中函数的入口出口设计
-
为了让整个管程正常运行,还需在管程中的每个函数的入口和出口增加相关操作,即:
void monitorFunc() {
down(&(mtp->mutex));
//--------into routine in monitor--------------
// ...
//--------leave routine in monitor--------------
if(mtp->next_count>0)
up(&(mtp->next));
else
up(&(mtp->mutex));
} -
这样做的好处有两个
- 只有一个进程在执行管程中的函数。
- 避免由于执行了
cond_signal函数而睡眠的进程无法被唤醒。
-
针对 “避免由于执行了
cond_signal函数而睡眠的进程无法被唤醒“ 这个优点简单说一下- 管程中
wait和signal函数的调用存在时间顺序。例如:当线程1先调用signal唤醒线程2并将自身线程挂起后,线程2在开始执行时将无法唤醒原先的在signal中挂起的线程1。 - 也就是说,只要存在线程在管程中执行了
signal,那么至少存在一个线程在管程中被挂起。 - 此时,就只能在临界区外唤醒挂起的线程1,而这一步在代码中也得到了实现。
- 管程中
-
- 用管程机制实现哲学家就餐问题的解决方案(基于条件变量)
-
这题涉及到了两个函数,分别是
phi_take_forks_condvar和phi_put_forks_condvar。与信号量所实现的哲学家就餐问题类似,大体逻辑是一致的。 -
首先,哲学家需要尝试获取刀叉,如果刀叉没有获取到,则等待刀叉。
void phi_take_forks_condvar(int i) {
down(&(mtp->mutex));
//--------into routine in monitor--------------
// LAB7 EXERCISE1: YOUR CODE
// I am hungry
state_condvar[i]=HUNGRY; /* 记录下哲学家i饥饿的事实 */
// try to get fork
phi_test_condvar(i);
if (state_condvar[i] != EATING) {
cprintf("phi_take_forks_condvar: %d didn't get fork and will wait\n",i);
cond_wait(&mtp->cv[i]);
}
//--------leave routine in monitor--------------
if(mtp->next_count>0)
up(&(mtp->next));
else
up(&(mtp->mutex));
} -
之后,当哲学家放下刀叉时,如果左右两边的哲学家都满足条件可以进餐,则设置对应的条件变量。
void phi_put_forks_condvar(int i) {
down(&(mtp->mutex));
//--------into routine in monitor--------------
// LAB7 EXERCISE1: YOUR CODE
// I ate over
state_condvar[i]=THINKING; /* 哲学家进餐结束 */
// test left and right neighbors
phi_test_condvar(LEFT); /* 看一下左邻居现在是否能进餐 */
phi_test_condvar(RIGHT); /* 看一下右邻居现在是否能进餐 */
//--------leave routine in monitor--------------
if(mtp->next_count>0)
up(&(mtp->next));
else
up(&(mtp->mutex));
} -
以下是哲学家尝试进餐的代码
void phi_test_condvar (i) {
if(state_condvar[i]==HUNGRY&&state_condvar[LEFT]!=EATING
&&state_condvar[RIGHT]!=EATING) {
cprintf("phi_test_condvar: state_condvar[%d] will eating\n",i);
state_condvar[i] = EATING ;
cprintf("phi_test_condvar: signal self_cv[%d] \n",i);
cond_signal(&mtp->cv[i]) ;
}
}
Challenge 1
在ucore中实现简化的死锁和重入探测机制.
在ucore下实现一种探测机制,能够在多进程/线程运行同步互斥问题时,动态判断当前系统是否出现了死锁产生的必要条件,是否产生了多个进程进入临界区的情况。 如果发现,让系统进入monitor状态,打印出你的探测信息。
死锁的相关资料可查阅上文中的死锁来了解。
具体实现暂鸽。
Challenge 2
在ucore下实现下Linux的RCU同步互斥机制。
RCU(Read-Copy Update) 机制适用于读者-写者模型,但更适用于读者多而写者少的情况,因为其行为方式如下:
-
随时可以拿到读锁,在有些设计中甚至不需要锁,即对临界区的读操作随时都可以得到满足,不能被阻塞。因此读者几乎没有什么同步开销。
-
某一时刻只能有一个人拿到写锁,多个写锁需要互斥,写的动作包括 拷贝–修改–宽限窗口到期后删除原值。写者在访问它时首先拷贝一个副本,然后对副本进行修改,最后使用一个回调(callback)机制在适当的时机把指向原来数据的指针重新指向新的被修改的数据。这个时机就是所有引用该数据的CPU都退出对共享数据的操作。
RCU保护的是指针,这一点尤其重要。因为指针赋值是一条单指令,也就是说是一个原子操作。更改指针指向时没必要考虑它的同步,只需要考虑cache的影响.。
-
临界区的原始值为m1,如果存在线程拿到写锁修改了临界区为m2,则在写锁修改临界区之后,如果某个线程拿到了读锁,则获取的临界区的值应该为m2;写锁修改临界区之前,读锁获取的值应为m1。这样的操作通过原子操作来保证。
-
RCU读操作随时都会得到满足,但写锁之后的写操作所耗费的系统资源就相对比较多了,因为需要延迟数据结构的释放与复制被修改的数据结构,并且只有在宽限期之后才会彻底删除原资源。
当一个线程执行删除某个结点的动作后,该结点并不会马上被删除,而是等待所有读取线程全部读取完成后才进行销毁操作,而这样做的原因是这些线程有可能读到了要删除的元素。
从删除结点到销毁节点这之间的过程,称为宽限期(Grace Period)
具体实现暂鸽QwQ
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK