

【硬核摄影】给火车拍个全身照
source link: https://divertingpan.github.io/post/train_scanning/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

GitHub项目地址:https://github.com/divertingPan/video_scanner
站在路边的思考
用普通相机拍摄火车的时候,离得近拍不到全貌,或者拍到的全貌带透视,看不清远处。离得远就能拍到完整的形态,但是主体太小了看不清。用录像的办法可以离近的同时,拍到完整的火车形态。但是视线就只能被限制在这一个小窗口内,只能看到一小部分的图像,还是不能自由观察整个火车全貌。
但是,既然录像已经把完整的火车给录下来了,那就可以直接用拼图的方法,把每一帧图像里面新录到的部分往后接上去。从视频一开始出现火车,就将这之后新出现的内容向后延展,直到火车走掉。基本的思路如下图所示。

这时候很明显的发现,这样做的话,由于画面有透视的原因,会使画面不均匀,并且拼接得不太严丝合缝。如果把这个窗口缩窄,只取画面中部的一小部分,这一小部分只要足够小就可以忽略他的透视形变,画面就会均匀很多。这样做顺便还有一个好处,可以避免周围杂物的干扰,理论上只要录像视线内有这一小条能够完整照到火车就是可以的。
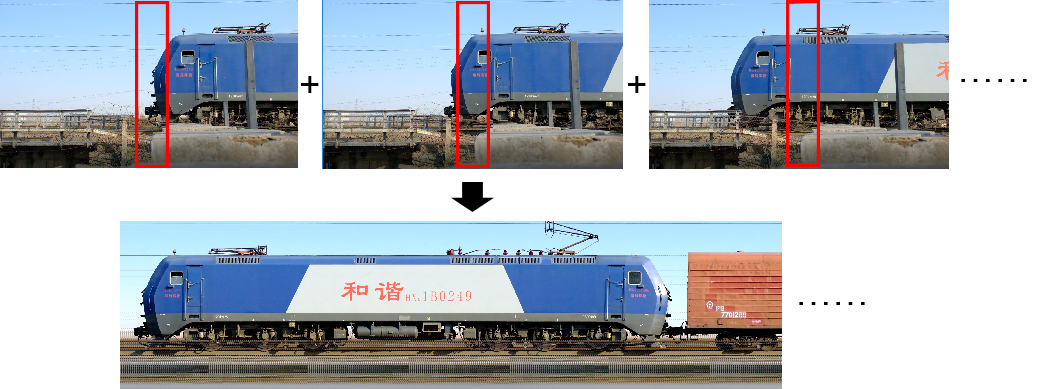
这样的话,可以对视频的每一帧,都剪出中间某个固定宽度的图像然后拼起来就好了。这个窗口可以无限窄(只留1像素宽)吗?这个窗口宽度显然应该和同一个点在两帧之间的距离有关。窗口比这个距离窄,就会丢信息,比这个距离宽,就会有重复出现的内容。如果和这个距离相等,则是刚刚好的。例如下图是前后两帧叠加显示的示意图,同一点的距离就应该作为这个窗口的宽度来拼接图像

同时我们还得确保这个窗口尽量窄,以确保减少透视形变和光照不均。所以说,录像的时候尽量让物体在视频里动的慢一点,也就是让两帧之间同一点的位移尽量小。所以要么拍慢速移动的物体,要么用高速摄影机。当然,为了确保这个动着的东西在画面里不糊,每一帧的快门速度也要尽量快。
那我们干脆算一算快门速度还有这个窗口宽度和实际运动速度之间的关系。利用一些已知信息可以推算图像里的一像素对应实际焦平面上的区域尺寸。
根据TB/T 1010-2016 《铁道车辆轮对及轴承型式与基本尺寸》,大部分的货车轮滚动圆直径是840mm,根据图中所示这个型号是P62k,根据http://www.trainfanz.com/series_info.aspx?Series=55&msg=576的数据,这个车的轴重是21t,又根据GB/T 25024-2019 《机车车辆转向架 货车转向架》的第5.8.a:轴重25t及以下车轮滚动圆直径应为840mm。基本可以确定图中车轮的直径是840mm。

这样,做一个简单的比例换算关系就可知,图片里的1像素=实际该处位置6.83mm。如果在60fps的录像帧率下,若想要窗口宽度为1像素,则火车速度就应该为6.83x60 mm/s,即0.41m/s。录像帧率越高,可接纳的实际火车速度越快,因此在实际录像时为了保证尽量小的窗口间隔,录像帧率尽量选择设备能达到的最大帧率。
假设使用1/8000的快门速度,不出现模糊的火车最高速度应该是6.83/(1/8000) mm/s,即54.64m/s。(意义为在一个像素能识别到的运动距离内,在快门速度时间内走过不超过这样的距离,否则会出现运动残影。可以参考“弥散圆”的概念)虽然为了确保快门速度能够压住运动的物体速度,但是显然1/8000并没有必要。而且快门速度过快同时会导致需要更高的感光度(ISO),导致画面质量降低。而普通列车(指车头拖拉的这种火车)设计的最高速度也就是160km/h,所以推算快门速度只要达到(6.83/1000)/(160/3.6)=1/6507。根据我的实际观察,我所在的这个位置接近火车站,所以火车基本都不是全速从我面前通过的,因此快门速度还可以更慢。
理论的根据车轮估算最低快门速度的完整换算公式应该是快门速度=1/ 车轮直径 ( 像素 )× 火车速度 0.84(×3.6)快门速度=1 / \frac{\text { 车轮直径 }(\text { 像素 }) \times \text { 火车速度 }}{0.84(\times 3.6)}快门速度=1/0.84(×3.6) 车轮直径 ( 像素 )× 火车速度 ,当火车速度是km/h时进行(x3.6),是m/s时不乘。
写个自动化程序
利用python对视频进行一些处理,主要依靠cv2提供的一些工具。首先得打开一个视频
video_path = './DSCF1150.MOV'
vc = cv2.VideoCapture(video_path)
这时,vc就代表了加载进来的视频文件了,利用vc.set(cv2.CAP_PROP_POS_FRAMES, 666666)可以指定一个想象的进度条放在第666666帧上,之后的对帧操作将从这个想象的进度条开始往后操作。如果要从头开始,指定他为0或者直接加载视频就可以。
利用以下操作将获得这个视频的一系列属性参数。fps-每秒帧数,total_frames-视频总帧数,frame_width,frame_height-视频的宽度和高度
fps = vc.get(cv2.CAP_PROP_FPS)
total_frames = int(vc.get(cv2.CAP_PROP_FRAME_COUNT))
frame_width = int(vc.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(vc.get(cv2.CAP_PROP_FRAME_HEIGHT))
当程序每次调用一下rval, frame = vc.read(),就会往后读一帧,rval代表是否成功读到这个帧,frame代表读到的帧图像。因此,读整个视频就可以写成以下样子
for i in range(total_frames):
rval, frame = vc.read()
if not rval:
print('break')
break
读进来的帧的形式为np.ndarray形式的数据,因此方便后续操作。值得注意的是,记住cv2默认的色彩通道为BGR顺序。要么自己记得转一下,要么就一直使用cv2提供的图像处理方法。
如果对视频的所有帧,都取一个固定宽度的图像出来,拼接在一起,那这个图像的宽度就应该是总帧数x窗口宽。所以我们直接初始化一个空的ndarray,img = np.empty((frame_height, total_frames * width, 3), dtype='uint8')
从视频帧中剪出需要的图像段很容易,直接frame[:, position:position+width, :]即可,这个position是一个比较靠图像中间的位置,也是这个窗口的左侧起始边。
往那个空数组里面放图像段的时候有一个小坑。火车从左向右开还是从右向左开的拼接顺序也应该是反过来的。
- 如果从左向右行驶,在空数组上的拼接顺序应该是从最右端开始拼起,即起始位置应该是
pixel_start = total_frames * width - (i + 1) * width - 反之,应该从最左端拼,起始位置是
pixel_start = i * width - i代表的是帧的编号
好,关键组件都到齐了,现在把核心的处理过程完整的写出来,如下:
vc = cv2.VideoCapture(video_path)
vc.set(cv2.CAP_PROP_POS_FRAMES, 0)
total_frames = int(vc.get(cv2.CAP_PROP_FRAME_COUNT))
frame_height = int(vc.get(cv2.CAP_PROP_FRAME_HEIGHT))
img = np.empty((frame_height, int(total_frames * width), 3), dtype='uint8')
for i in range(total_frames):
rval, frame = vc.read()
if not rval:
print('break')
break
if v_left_right.get():
pixel_start = int(total_frames * width) - int((i + 1) * width)
else:
pixel_start = int(i * width)
pixel_end = pixel_start + math.ceil(width)
img[:, pixel_start:pixel_end, :] = frame[:, position:position + math.ceil(width), :]
另外,如果想每隔几个像素取一列,即窗口宽是一个大于0小于1的小数。这样的话需要在涉及到与width进行计算的所有地方进行取整判断。这就是在上面的一些地方反复出现int()以及ceil()的原因。
保存图片的话,直接用cv2.imwrite岂不是太没水平了?其实一个关键的因素在于,如果图片太长,在Ubuntu系统上会有无法显示的bug。所以存图的时候,给他裁开,避免单个图太大。裁图时我们先给一个固定的长度,当图片足够裁出这个长度的段时,就裁剪保存,不够裁就直接把剩余的保存。可是这里我写的不够优雅,希望哪位同学能提供一种更优美的写法。
flag = 0
i = 0
for i in range(int((total_frames * width) / split_width)):
split_start = i * split_width
split_end = split_start + split_width
cv2.imwrite('{}/{}_{}.jpg'.format(save_dir, os.path.split(video_path.get())[-1].split('.')[-2], i),
img[:, split_start:split_end, :])
flag = 1
if not flag or (total_frames * width) % split_width:
i += flag
split_start = i * split_width
cv2.imwrite('{}/{}_{}.jpg'.format(save_dir, os.path.split(video_path.get())[-1].split('.')[-2], i),
img[:, split_start:, :])
使用体验优化
前面那段代码的一些参数可能会随着视频不同而变化,要是每次运行前都打开代码去找实在太麻烦,写在程序开头我也嫌改着麻烦。另外,程序运行过程需要一些时间,没有进度条实在是太不友好。而且,如果加载视频之后能够立刻显示相邻两帧的差异,就能很方便的确定窗口宽度了。
种种迹象表明,现在需要一个界面来接收参数以及做一些显示。
好在python自带有tkinter一个简易的界面制作工具。也不讲什么稳定性美观啥的了,直接搓个界面就行。而且也不考虑那么多“一个用户走进酒吧点了一份炒饭”这样的问题,反正老潘自己用的话绝对不会故意往输入框里给什么核爆炸输入的(何必呢)。
- 我想要显示两帧的差异图,如果还想带一些简单的交互,那就用matplotlib。
- 或许需要一个视频的定位条,用来改变显示的相邻两帧在视频里的位置(例如视频开头可能啥也没有,应该从视频中间取帧)。
- 我还想要视频的打开和保存路径选择,这俩功能每个GUI开发框架必有。
- 打开视频以后显示一下fps、总帧数等信息,这个直接传值给Label那样的控件就行。
- 需要有输入框来接收一些值,包括窗口位置、窗宽度、切割图像的图像宽度。
- 一个按钮来将这些值给处理的函数并且执行。
- 一个进度条,刚好这个处理流程需要从头到尾遍历视频帧,这个进度就可以作为进度条的进度。
首先,每个GUI都要有一个主窗体,
window = tk.Tk()
window.title('scanning video')
window.geometry('1024x500')
font = tf.Font(size=12)
再怎么说,基本的布局还是得科学一点,不然自己用起来肯定不顺手。图像的显示就放在左侧,其他的控制放在右侧,
frame_left = Frame(window)
frame_left.pack(side=LEFT, fill=BOTH, expand=YES)
frame_right = Frame(window)
frame_right.pack(side=LEFT, padx=10, expand=YES)
pack()是指按照顺序排在指定的框架内。可以有各种参数控制不同的排列样式。
先放左侧的东西。一个画布显示图像,一个控制条来当做视频播放条,一个matplotlib自己的工具栏。
fig = Figure(figsize=(8, 4), dpi=72)
canvas = FigureCanvasTkAgg(fig, master=frame_left)
canvas.get_tk_widget().pack(side=TOP, fill=BOTH, expand=YES)
toolbar = NavigationToolbar2Tk(canvas, frame_left)
toolbar.update()
canvas.get_tk_widget().pack(side=TOP, fill=BOTH, expand=YES)
scrollbar_display = Scale(frame_left, orient=HORIZONTAL, from_=0, to=500,
resolution=1, command=display_frames)
scrollbar_display.pack(fill=X)
关于这个Scale,每次他被拖动以后,值就会变,就会执行command对应的函数,也会传进去当前的值,如果函数比较复杂(例如我的这个)就会比较卡,所以合理的优化是必要的。另外,这个Scale的长度to参数貌似必须是确定的,不能是个变量。我试了几种方法都会出错,只有给定数字才对劲。
def display_frames(idx):
global vc, canvas, fig
idx = int(idx)
vc.set(cv2.CAP_PROP_POS_FRAMES, idx)
rval, frame_1 = vc.read()
rval, frame_2 = vc.read()
frame_overlay = ((frame_1.astype(np.int) + frame_2.astype(np.int)) * 0.5).astype(np.uint8)
frame_overlay = cv2.cvtColor(frame_overlay, cv2.COLOR_BGR2RGB)
ax = fig.add_subplot(111)
ax.imshow(frame_overlay)
canvas.draw()
再放右侧的东西,右侧会涉及到一些逻辑操作。首先是打开视频。这里不想解释那么多了,看代码一目了然。
def open_video():
global fig, vc, total_frames, frame_height
fig.clear()
video_path.set(filedialog.askopenfilename(title='choose a video'))
vc = cv2.VideoCapture(video_path.get())
fps = vc.get(cv2.CAP_PROP_FPS)
total_frames = int(vc.get(cv2.CAP_PROP_FRAME_COUNT))
frame_width = int(vc.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(vc.get(cv2.CAP_PROP_FRAME_HEIGHT))
label_video_attr['text'] = '... ......... ...\n' \
'... fps: {} ...\n' \
'... total_frames: {} ...\n' \
'... resolution: {}x{} ...\n' \
'... ......... ...'.format(fps, total_frames, frame_width, frame_height)
display_frames(0)
video_path = StringVar()
video_path.set('... select a video ...')
label_video_path = tk.Label(frame_right, textvariable=video_path, font=font)
label_video_path.pack()
bt_open_video = tk.Button(frame_right, text='open a video', command=open_video, font=font)
bt_open_video.pack()
之后是选择保存路径。这里我设计的是,存文件的时候会在这个路径下建立一个与视频同名的文件夹,然后将分割的图放进去。这个可以在处理函数里面看出来。
def save_img():
save_path.set(filedialog.askdirectory())
save_path = StringVar()
save_path.set('... select save dir ...')
label_save_path = tk.Label(frame_right, textvariable=save_path, font=font)
label_save_path.pack()
bt_save_img = tk.Button(frame_right, text='save dir', command=save_img, font=font)
bt_save_img.pack()
之后显示视频的一些信息,这个会和前面open_video()联动,只要打开了视频就会读取这个视频的这些信息,并且显示在这。
label_video_attr = tk.Label(frame_right, font=font, text='... ......... ...\n'
'... info area ...\n'
'... ......... ...')
label_video_attr.pack()
再下面放三个接受输入值的东西。在程序里调用这些输入框里的值,使用诸如int(text_position.get())来获取到里面的数。
label_position = tk.Label(frame_right, text='position:', font=font)
label_position.pack()
text_position = tk.Entry(frame_right, font=font)
text_position.pack()
label_width = tk.Label(frame_right, text='width:', font=font)
label_width.pack()
text_width = tk.Entry(frame_right, font=font)
text_width.pack()
label_split_width = tk.Label(frame_right, text='split_width:', font=font)
label_split_width.pack()
text_split_width = tk.Entry(frame_right, font=font)
text_split_width.pack()
进度条,以及一个显示是否完成的label。
def process():
......
progressbar['maximum'] = total_frames
for i in range(total_frames):
......
progressbar['value'] = i + 1
progressbar = ttk.Progressbar(frame_right, length=300, cursor='watch')
progressbar.pack()
label_status = tk.Label(frame_right, text='Status: waiting...', font=font)
label_status.pack()
一个用来选择运动方向的单选按钮。可以给每个选项赋予value,然后使用v_left_right.get()获取选中的选项的value。
def process():
......
for i in range(total_frames):
if v_left_right.get():
pixel_start = int(total_frames * width) - int((i + 1) * width)
else:
pixel_start = int(i * width)
v_left_right = IntVar()
radio_left_to_right = tk.Radiobutton(frame_right, text='left to right',
variable=v_left_right, value=1, font=font)
radio_left_to_right.pack()
radio_right_to_left = tk.Radiobutton(frame_right, text='right to left',
variable=v_left_right, value=0, font=font)
radio_right_to_left.pack()
最重要的一个按钮。
bt_process = tk.Button(frame_right, text='process', command=process, font=font)
bt_process.pack()
最后,一个套路化的东西。
window.mainloop()
如果一切正常,窗口如图所示。利用工具栏可以放大图片局部,也可以查看某个点的坐标。
这样就可以收获一些角度刁钻的照片了,比如(封面回收)
(可以当做新的分割线了)
这样还可以将录像极大压缩。一个录像有接近1G,而对应的图像则只有100M左右,不损失画质的情况下减少90%的空间占用。(不过,声音没了)(不过,在高帧率录制时本来也录不上声音)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK