

Le Petit Chercheur Illustré
source link: https://yetaspblog.wordpress.com/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

There is time for dithering in a quantized world of reduced dimensionality!
I’m glad to announce here a new work made in collaboration with Valerio Cambareri (UCL, Belgium) on quantized embeddings of low-complexity vectors, such as the set of sparse (or compressible) signals in a certain basis/dictionary, the set of low-rank matrices or vectors living in (a union of) subspaces.
The title and the abstract are as follows (arxiv link here).
“Time for dithering: fast and quantized random embeddings
via the restricted isometry property”
Recently, many works have focused on the characterization of non-linear dimensionality reduction methods obtained by quantizing linear embeddings, e.g., to reach fast processing time, efficient data compression procedures, novel geometry-preserving embeddings or to estimate the information/bits stored in this reduced data representation. In this work, we prove that many linear maps known to respect the restricted isometry property (RIP), can induce a quantized random embedding with controllable multiplicative and additive distortions with respect to the pairwise distances of the data points beings considered. In other words, linear matrices having fast matrix-vector multiplication algorithms (e.g., based on partial Fourier ensembles or on the adjacency matrix of unbalanced expanders), can be readily used in the definition of fast quantized embeddings with small distortions. This implication is made possible by applying right after the linear map an additive and random “dither” that stabilizes the impact of a uniform scalar quantization applied afterwards.
For different categories of RIP matrices, i.e., for different linear embeddings of a metric spacein
with
, we derive upper bounds on the additive distortion induced by quantization, showing that this one decays either when the embedding dimension
increases or when the distance of a pair of embedded vectors in
decreases. Finally, we develop a novel “bi-dithered” quantization scheme, which allows for a reduced distortion that decreases when the embedding dimension grows, independently of the considered pair of vectors.
In a nutshell, the idea of this article stems from the following observations. There is an ever-growing literature dealing with the design of quantized/non-linear random maps or data hashing techniques for reaching novel dimensionality reduction techniques. More particularly, inside it, some of the works are interested in the accurate control of the number of bits needed to encode the image of the maps, for instance by combining a random linear map with a quantization process approximating the continuous image of the linear map to a finite set of vectors (e.g., using a uniform or a 1-bit quantizer [1,2,3,4]). This quantization is indeed important for instance to reduce and bound the processing time of the quantized signal signatures obtained with this map. In fact, if the quantized map is also an embedding, i.e., if it preserves the pairwise distances of the mapped vectors up to some distortions, we can process the (compact) vector signatures as a proxy to the full processing we would like to perform on the original signals, e.g., for nearest neighbors search or machine learning algorithms.
However, AFAIK, either these random constructions embrace the embedding of general low-complexity vectors sets (possibly continuous) thanks to the quantization of (slow and unstructured) linear random projections (e.g., using a non-linear alteration/quantization of a linear projection reached by a sub-Gaussian random matrix with 
This is rather frustrating when we know that the compressive sensing (CS) literature now offers us a large class of linear embeddings of low-complexity vector sets, i.e., including constructions with fast (possibly with log-linear complexity) projections of vectors. We can think for instance to the projections induced by partial Fourier/Hadamard ensembles [9], random convolutions [10] or the spread-spectrum sensing [11].
Adopting a general formulation federating several definitions available in different works, this embedding capability is mathematically characterized by the celebrated restricted isometry property (or RIP), i.e., a matrix 


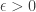
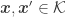
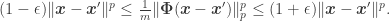
Given such a matrix 
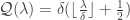


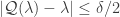
![(1-\epsilon)^{1/p} \|\boldsymbol x - \boldsymbol x'\| - \delta \leq \tfrac{1}{\sqrt[p] m} \|A'(\boldsymbol x) - A'(\boldsymbol x')\|_p \leq (1+\epsilon)^{1/p} \|\boldsymbol x - \boldsymbol x'\| + \delta.](https://s0.wp.com/latex.php?latex=%281-%5Cepsilon%29%5E%7B1%2Fp%7D+%5C%7C%5Cboldsymbol+x+-+%5Cboldsymbol+x%27%5C%7C+-+%5Cdelta+%5Cleq+%5Ctfrac%7B1%7D%7B%5Csqrt%5Bp%5D+m%7D+%5C%7CA%27%28%5Cboldsymbol+x%29+-+A%27%28%5Cboldsymbol+x%27%29%5C%7C_p+%5Cleq+%281%2B%5Cepsilon%29%5E%7B1%2Fp%7D+%5C%7C%5Cboldsymbol+x+-+%5Cboldsymbol+x%27%5C%7C+%2B+%5Cdelta.&bg=ffffff&fg=333333&s=0&c=20201002)
Strikingly, we observe now that, compared to the RIP that only displays a multiplicative distortion 

However, our work actually shows that it is nevertheless possible to design quantized embeddings where this new additive distortion can be controlled (and reduced) with either the dimension 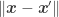
The key is to combine a linear embeddings 
Roughly speaking (see the paper for the correct statements), among other things, we show that if a matrix 


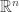


![A(\boldsymbol x) := \mathcal Q(\boldsymbol \Phi \boldsymbol x + \boldsymbol \xi), \quad \mathcal Q(\lambda) = \delta (\lfloor \tfrac{\lambda}{\delta}\rfloor + \tfrac{1}{2}),\ \xi_i \sim_{\rm iid} \mathcal U([0,\delta])](https://s0.wp.com/latex.php?latex=A%28%5Cboldsymbol+x%29+%3A%3D+%5Cmathcal+Q%28%5Cboldsymbol+%5CPhi+%5Cboldsymbol+x+%2B+%5Cboldsymbol+%5Cxi%29%2C+%5Cquad+%5Cmathcal+Q%28%5Clambda%29+%3D+%5Cdelta+%28%5Clfloor+%5Ctfrac%7B%5Clambda%7D%7B%5Cdelta%7D%5Crfloor+%2B+%5Ctfrac%7B1%7D%7B2%7D%29%2C%5C+%5Cxi_i+%5Csim_%7B%5Crm+iid%7D+%5Cmathcal+U%28%5B0%2C%5Cdelta%5D%29&bg=ffffff&fg=333333&s=0&c=20201002)
is such that, with high probability and given a suitable concept of (pre)metric 


where the approximation symbol hides an additive and a multiplicative errors (or distortions).
More precisely, we have with high probability a quantized form of the RIP, or 
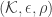

for all 
Interestingly enough, this last additive distortion 

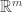
For instance, if one decides to measure the distances with the 
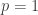

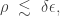
as explained in Prop. 1 of our work.
If we rather focus on using 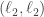
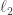

where 

Bi-dithered quantized map: Desiring to preserve the inheritance of the
The principle is really simple. For each row of a RIP matrix, two dithers and thus two measurements are generated (hence doubling the total number 
![\bar A(\boldsymbol x) := \mathcal Q(\boldsymbol \Phi \boldsymbol x \boldsymbol 1_2^T + \boldsymbol \Xi),\ \boldsymbol \Xi \in \mathbb R^{m \times 2},\ \Xi_{ij} \sim_{\rm iid} \mathcal U([0,\delta]),](https://s0.wp.com/latex.php?latex=%5Cbar+A%28%5Cboldsymbol+x%29+%3A%3D+%5Cmathcal+Q%28%5Cboldsymbol+%5CPhi+%5Cboldsymbol+x+%5Cboldsymbol+1_2%5ET+%2B+%5Cboldsymbol+%5CXi%29%2C%5C+%5Cboldsymbol+%5CXi+%5Cin+%5Cmathbb+R%5E%7Bm+%5Ctimes+2%7D%2C%5C+%5CXi_%7Bij%7D+%5Csim_%7B%5Crm+iid%7D+%5Cmathcal+U%28%5B0%2C%5Cdelta%5D%29%2C&bg=ffffff&fg=333333&s=0&c=20201002)
writing 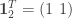

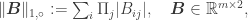
then, provided 
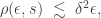
which is much smaller than what is reached in the case of a single dither.
All these results are actually summarized in the following table extracted from the paper (the caption is better understood by reading the paper):

Remark 1 (connection with the “fast JL maps from RIP”-approach): The gist of our work is after all quite similar, in another context, to the standpoint adopted in this paper by Krahmer and Ward for the development of fast Johnson-Lindenstrauss embeddings using the large class of RIP matrix constructions (when combined with a random pre-modulating 
Remark 2 (on the proofs): The proofs developed in our work are not really technical and are all based on the same structure: the (variant of the) RIP allows us to focus on the embedding of the image of a low-complexity vector set (obtained through the corresponding linear map
Remark 3 (on RIP-1 matrices): We do not mention in this post another variant of the RIP above, i.e., embedding 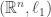

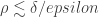
Remark 4 (on 1-bit quantized embeddings): If the set
Open problems:
- Even if Remark 4 above shows us that 1-bit quantized embeddings are reachable with a dithered quantization of RIP-based linear embeddings, it is still an open and challenging problem to understand if fast embeddings can be designed with (undithered) sign operator [5,6,7].
- A generalization of the bi-dithered quantized map above to a multi-dithered version (with of course a careful study of the corresponding increase of the measurement number) could potentially lead us to more advanced and distorted mappings, e.g., where distances are distorted by a polynomial of degree set by the number of dithers attributed to each row of
- [1] P. T. Boufounos and R. G. Baraniuk. 1-bit compressive sensing. In Information Sciences and Systems, 2008. CISS 2008. 42nd Annual Conference on, pages 16–21. IEEE, 2008.
- [2] L. Jacques, J. N. Laska, P. T. Boufounos, and R. G. Baraniuk. Robust 1-bit compressive sensing via binary stable embeddings of sparse vectors. Information Theory, IEEE Transactions on, 59(4):2082–2102, 2013.
- [3] Y. Plan and R. Vershynin. Dimension reduction by random hyperplane tessellations. Dis- crete & Computational Geometry, 51(2):438–461, 2014.
- [4] M. Datar, N. Immorlica, P. Indyk, and V. S. Mirrokni. Locality-sensitive hashing scheme based on p-stable distributions. In Proceedings of the twentieth annual symposium on Computational geometry, pages 253–262. ACM, 2004.
- [5] S. Oymak. Near-Optimal Sample Complexity Bounds for Circulant Binary Embedding. arXiv preprint arXiv:1603.03178, 2016.
- [6] F. X. Yu, A. Bhaskara, S. Kumar, Y. Gong, and S.-F. Chang. On Binary Embedding using Circulant Matrices. arXiv preprint arXiv:1511.06480, 2015.
- [7] F. X. Yu, S. Kumar, Y. Gong, and S.-F. Chang. Circulant binary embedding. arXiv preprint arXiv:1405.3162, 2014.
- [8] R. M. Gray and D. L. Neuhoff. Quantization. Information Theory, IEEE Transactions on, 44(6):2325–2383, 1998.
- [9] H. Rauhut, J. Romberg, and J. A. Tropp. Restricted isometries for partial random circulant matrices. Applied and Computational Harmonic Analysis, 32(2):242–254, 2012.
- [10] J. Romberg. Compressive sensing by random convolution. SIAM Journal on Imaging Sciences, 2(4):1098–1128, 2009.
- [11] G. Puy, P. Vandergheynst, R. Gribonval, and Y. Wiaux. Universal and efficient compressed sensing by spread spectrum and application to realistic Fourier imaging techniques. EURASIP Journal on Advances in Signal Processing, 2012(1):1–13, 2012.
- [12] P. T. Boufounos, S. Rane, and H. Mansour. Representation and Coding of Signal Geometry. arXiv preprint arXiv:1512.07636, 2015.
- [13] A. Rahimi and B. Recht. Random features for large-scale kernel machines. In Advances in neural information processing systems, pages 1177–1184, 2007.
- [14] A. Andoni and P.Indyk. Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions. In Foundations of Computer Science, 2006. FOCS’06. 47th Annual IEEE Symposium on, pages 459–468. IEEE, 2006.
- [15] R. Berinde, A. C. Gilbert, P. Indyk, H. Karloff, and M. J. Strauss. Combining geometry and combinatorics: A unified approach to sparse signal recovery. In Communication, Control, and Computing, 2008 46th Annual Allerton Conference on, pages 798–805. IEEE, 2008.
- [16] L. Jacques. Small width, low distortions: quasi-isometric embeddings with quantized sub- Gaussian random projections. arXiv preprint arXiv:1504.06170, 2015.
- [17] F. Krahmer, R. Ward, “New and improved Johnson-Lindenstrauss embeddings via the restricted isometry property”. SIAM Journal on Mathematical Analysis, 43(3), 1269-1281, 2011.
Quantized sub-Gaussian random matrices are still RIP!
I have always been intrigued by the fact that, in Compressed Sensing (CS), beyond Gaussian random matrices, a couple of other unstructured random matrices respecting, with high probability (whp), the Restricted Isometry Property (RIP) look like “quantized” version of the Gaussian case, i.e., their discrete entries have a probability density function (pdf) that seems induced by a discretized version of the Gaussian pdf.
For instance, two random constructions that are known to allow CS of sparse signals by respecting the RIP, namely the Bernoulli random matrix, with entries identically and independently distributed (iid) as a rv taking 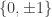
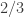

This short post aims simply to show that this fact can be easily understood thanks to known results showing that sub-Gaussian random matrices respect the RIP [3]. Certain of the relations described below are probably very well known in the statistical literature but, as we are always re-inventing the wheel (at least me ;-)), I found anyway interesting to share this through this blog post.
Let’s first recall what a sub-Gaussian random variable (rv) is. For this, I’m following [1]. A random variable 

is finite. In particular, any rv with such a finite norm has a tail bound that decays as fast as the one of a Gaussian rv, i.e., for some 

![\mathbb P[|X| \geq t] \lesssim \exp(- c t^2/L^2).](https://s0.wp.com/latex.php?latex=%5Cmathbb+P%5B%7CX%7C+%5Cgeq+t%5D+%5Clesssim+%5Cexp%28-+c+t%5E2%2FL%5E2%29.&bg=ffffff&fg=333333&s=0&c=20201002)
The set of sub-Gaussian random variables includes for instance the Gaussian, the Bernoulli and the bounded rv’s, as 
In CS theory, it is now well known that if a random matrix 

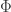

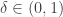

In fact, if 




The simple point I’d like to show here is that a large class of RIP matrices can be generated by quantizing (elementwise) Gaussian and sub-Gaussian random matrices. I’m going to show this by proving that (i) quantizing a Gaussian rv leads to a sub-Gaussian rv, (ii) its sub-Gaussian norm can be easily upper bounded.
But what do I mean by “quantizing”?
This operation is actually defined here through a partition 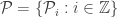
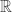



Given a rv 
![c_i(X) := \mathbb E[X|\mathcal P_i] = \mathbb E[X|X\in \mathcal P_i].](https://s0.wp.com/latex.php?latex=c_i%28X%29+%3A%3D+%5Cmathbb+E%5BX%7C%5Cmathcal+P_i%5D+%3D+%5Cmathbb+E%5BX%7CX%5Cin+%5Cmathcal+P_i%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
The quantized version 

with 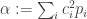
![p_i = \mathbb P(Z = c_i) = \mathbb P(X \in \mathcal P_i) = \mathbb E[1|\mathcal P_i]](https://s0.wp.com/latex.php?latex=p_i+%3D+%5Cmathbb+P%28Z+%3D+c_i%29+%3D+%5Cmathbb+P%28X+%5Cin+%5Cmathcal+P_i%29+%3D+%5Cmathbb+E%5B1%7C%5Cmathcal+P_i%5D&bg=ffffff&fg=333333&s=0&c=20201002)

![\mathbb E|X - \mathcal Q[X]|^2](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%7CX+-+%5Cmathcal+Q%5BX%5D%7C%5E2&bg=ffffff&fg=333333&s=0&c=20201002)
We can thus deduce that, thanks to the definition of the levels 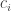

and 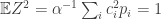
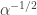
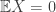

Moreover, for any 
![\mathbb E |Z|^p = \alpha^{-p/2}\,\sum_i |c_i|^p p_i \leq \alpha^{-p/2}\,\sum_i \mathbb E[|X|^p|\mathcal P_i]\, p_i \leq \alpha^{-p/2}\,\mathbb E |X|^p.](https://s0.wp.com/latex.php?latex=%5Cmathbb+E+%7CZ%7C%5Ep+%3D+%5Calpha%5E%7B-p%2F2%7D%5C%2C%5Csum_i+%7Cc_i%7C%5Ep+p_i+%5Cleq+%5Calpha%5E%7B-p%2F2%7D%5C%2C%5Csum_i+%5Cmathbb+E%5B%7CX%7C%5Ep%7C%5Cmathcal+P_i%5D%5C%2C+p_i+%5Cleq+%5Calpha%5E%7B-p%2F2%7D%5C%2C%5Cmathbb+E+%7CX%7C%5Ep.&bg=ffffff&fg=333333&s=0&c=20201002)
Therefore, by definition of the sub-Gaussian norm above, we find
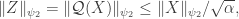
which shows that
For instance, for a Gaussian rv ![\mathcal{P} = \{(-\infty, 0], (0, +\infty)\}](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BP%7D+%3D+%5C%7B%28-%5Cinfty%2C+0%5D%2C+%280%2C+%2B%5Cinfty%29%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)



In consequence, a matrix 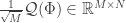


From what is described above, it is clear that the entries of 




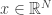


Note that nowhere above we have used the Gaussianity of
Open question:
- What will happen if we quantize a structured random matrix, such as a random Fourier ensemble [2], a spreadspectrum sensing matrix [7] or a random convolution [6]? Or more simply random matrices were only the rows (or the columns) are guaranteed to be independent [1]? Do we recover (almost) known random matrix construction such as random partial Hadamard ensembles ?
References:
[1] R. Vershynin, “Introduction to the non-asymptotic analysis of random matrices”, http://arxiv.org/abs/1011.3027
[2] S. Foucart, H. Rauhut. A mathematical introduction to compressive sensing. Vol. 1. No. 3. Basel: Birkhäuser, 2013.
[3] R. Baraniuk, M. Davenport, R. DeVore, M. Wakin, “A simple proof of the restricted isometry property for random matrices”. Constructive Approximation, 28(3), 253-263, 2008.
[4] S. Mendelson, A. Pajor, N. Tomczak-Jaegermann, “Uniform uncertainty principle for bernoulli and subgaussian ensembles. Constructive Approximation, 28(3):277-289, 2008.
[5] R. M. Gray, D. L. Neuhoff, “Quantization”, IEEE Transactions on Information Theory, 44(6), 2325-2383, 1998.
Quasi-isometric embeddings of vector sets with quantized sub-Gaussian projections
Last January, I was honored to be invited in RWTH Aachen University by Holger Rauhut and Sjoerd Dirksen to give a talk on the general topic of quantized compressed sensing. In particular, I decided to focus my presentation on the quasi-isometric embeddings arising in 1-bit compressed sensing, as developed by a few researchers in this field (e.g., Petros Boufounos, Richard Baraniuk, Yaniv Plan, Roman Vershynin and myself).
In comparison with isometric (bi-Lipschitz) embeddings suffering only from a multiplicative distortion, as for the restricted isometry property (RIP) for sparse vectors sets or Johnson-Lindenstrauss Lemma for finite sets, a quasi-isometric embedding 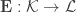





for all 
In the case of 1-bit Compressed Sensing, one observes a quasi-isometric relation between the angular distance of two vectors (or signals) in 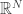

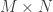
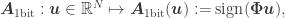
with 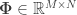
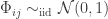

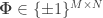
Interestingly, it has been shown in a few works that quasi-isometric 1-bit embeddings exist for 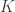

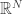
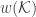
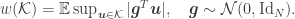
Since the 80’s, this dimension has been recognized as central for instance in characterizing random processes [9], shrinkage estimators in signal denoising and high-dimensional statistics [10], linear inverse problem solving with convex optimization [11] or classification efficiency in randomly projected signal sets [12]. Moreover, for the set of bounded K-sparse signals, we have 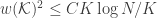
In [2], by connecting the problem to the context of random tessellation of the sphere 
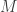
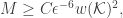
then, for all 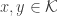
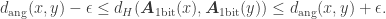
For 
As explained in my previous post on quantized embedding and the funny connection with Buffon’s needle problem, I have recently noticed that for finite sets 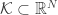

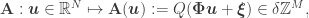
for a (“round-off”) scalar quantizer 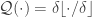
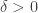

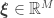
![\xi_i \sim_{\rm iid} \mathcal U([0, \delta])](https://s0.wp.com/latex.php?latex=%5Cxi_i+%5Csim_%7B%5Crm+iid%7D+%5Cmathcal+U%28%5B0%2C+%5Cdelta%5D%29&bg=ffffff&fg=333333&s=0)
In particular, provided 
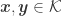
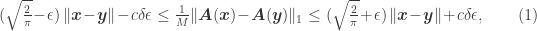
for some general constants 
One observes that the additive distortion of this last relation reads 
Remark: For information, as provided by an anonymous expert reviewer, it happens that a much shorter and elegant proof of this fact exists using the sub-Gaussian properties of the quantized mapping 
In that work, the question remained, however, on how to extend (1) for vectors taken in any (bounded) subset

While I was in Aachen discussing with Holger and Sjoerd during and after my presentation, I realized that the works [2-5] of Plan, Verhsynin, Ai and collaborators provided already many important tools whose adaptation to the mapping 
At the heart of [2] lies the equivalence between 
![d_H(\boldsymbol A_{\rm 1bit}(\boldsymbol x), \boldsymbol A_{\rm 1bit}(\boldsymbol y)) = \frac{1}{M} \sum_i \mathbb I[\mathcal E (\boldsymbol \varphi_i^T \boldsymbol x, \boldsymbol \varphi_i^T \boldsymbol y)],](https://s0.wp.com/latex.php?latex=d_H%28%5Cboldsymbol+A_%7B%5Crm+1bit%7D%28%5Cboldsymbol+x%29%2C+%5Cboldsymbol+A_%7B%5Crm+1bit%7D%28%5Cboldsymbol+y%29%29+%3D+%5Cfrac%7B1%7D%7BM%7D+%5Csum_i+%5Cmathbb+I%5B%5Cmathcal+E+%28%5Cboldsymbol+%5Cvarphi_i%5ET+%5Cboldsymbol+x%2C+%5Cboldsymbol+%5Cvarphi_i%5ET+%5Cboldsymbol+y%29%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
where 


In words, 

Without giving too many details in this post, the work [2] leverages this equivalence to make a connection with tessellation of the 
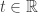
![d^t_H(\boldsymbol A_{\rm 1bit}(\boldsymbol x), \boldsymbol A_{\rm 1bit}(\boldsymbol y)) := \frac{1}{M} \sum_i \mathbb I[\mathcal F^t(\boldsymbol \varphi_i^T \boldsymbol x, \boldsymbol \varphi_i^T \boldsymbol y)],](https://s0.wp.com/latex.php?latex=d%5Et_H%28%5Cboldsymbol+A_%7B%5Crm+1bit%7D%28%5Cboldsymbol+x%29%2C+%5Cboldsymbol+A_%7B%5Crm+1bit%7D%28%5Cboldsymbol+y%29%29+%3A%3D+%5Cfrac%7B1%7D%7BM%7D+%5Csum_i+%5Cmathbb+I%5B%5Cmathcal+F%5Et%28%5Cboldsymbol+%5Cvarphi_i%5ET+%5Cboldsymbol+x%2C+%5Cboldsymbol+%5Cvarphi_i%5ET+%5Cboldsymbol+y%29%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
with now

This distance has an interesting continuity property compared to 

In our context, considering the quantized mapping
![\mathcal Q^t(\boldsymbol x,\boldsymbol y) := \tfrac{\delta}{M}\,\sum_{i=1}^M \sum_{k\in\mathbb Z} \mathbb I[\mathcal F^t(\boldsymbol \varphi_i^T \boldsymbol x + \xi_i - k\delta, \boldsymbol \varphi_i^T \boldsymbol y + \xi_i - k\delta)].](https://s0.wp.com/latex.php?latex=%5Cmathcal+Q%5Et%28%5Cboldsymbol+x%2C%5Cboldsymbol+y%29+%3A%3D+%5Ctfrac%7B%5Cdelta%7D%7BM%7D%5C%2C%5Csum_%7Bi%3D1%7D%5EM+%5Csum_%7Bk%5Cin%5Cmathbb+Z%7D+%5Cmathbb+I%5B%5Cmathcal+F%5Et%28%5Cboldsymbol+%5Cvarphi_i%5ET+%5Cboldsymbol+x+%2B+%5Cxi_i+-+k%5Cdelta%2C+%5Cboldsymbol+%5Cvarphi_i%5ET+%5Cboldsymbol+y+%2B+%5Cxi_i+-+k%5Cdelta%29%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
When 

similarly to the recovering of the Hamming distance in 1-bit case.
The interpretation of 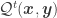
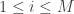
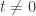
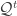
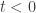
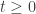
As for 1-bit projections, we can show the continuity of
From this observation, and after a few months of works, I have gathered all these developments in the following paper, now submitted on arxiv:
Briefly, benefiting of the context defined above, this work contains two main results.
First, it shows that given a symmetric sub-Gaussian distribution 
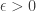
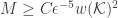
and if the sensing matrix 

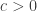
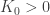

then, given some constant 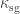
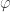


Interestingly, in this quasi-isometric embedding, we notice that the additive distortion is driven by 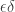

In addition to its common dependence in the precision 



In the particular case where
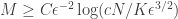
measurements suffice for defining the same embedding with high probability. As explained in the paper, this case allows somehow to mitigate the anti-sparse requirement as sparse vectors in some basis can be made less sparse in another, e.g., for dual bases such as DCT/Canonical, Noiselet/Haar, etc.
The second result concerns the consistency width of the mapping

for a general subset 
Open problem: I’m now wondering if the tools and results above could be extended to other quantizers 
References:
[1] L. Jacques, J. N. Laska, P. T. Boufounos, and R. G Baraniuk. “Robust 1-bit compressive sensing via binary
stable embeddings of sparse vectors”. IEEE Transactions on Information Theory, 59(4):2082–2102, 2013.
[2] Y. Plan and R. Vershynin. “Dimension reduction by random hyperplane tessellations”. Discrete & Computational Geometry, 51(2):438–461, 2014, Springer.
[3] Y. Plan and R. Vershynin. “Robust 1-bit compressed sensing and sparse logistic regression: A convex programming approach”. IEEE Transactions on Information Theory, 59(1): 482–494, 2013.
[4] Y. Plan and R. Vershynin. “One-bit compressed sensing by linear programming”. Communications on Pure and Applied Mathematics, 66(8):1275–1297, 2013.
[5] A. Ai, A. Lapanowski, Y. Plan, and R. Vershynin. “One-bit compressed sensing with non-gaussian measurements”. Linear Algebra and its Applications, 441:222–239, 2014.
[6] P. T. Boufounos. Universal rate-efficient scalar quantization. IEEE Trans. Info. Theory, 58(3):1861–1872, March 2012.
[7] V. K Goyal, M. Vetterli, and N. T. Thao. Quantized overcomplete expansions in
[8] N. T . Thao and M. Vetterli. “Lower bound on the mean-squared error in oversampled quantization of periodic signals using vector quantization analysis”. IEEE Trans. Info. Theory, 42(2):469–479, March 1996.
[9] A. W. Vaart and J. A. Wellner. Weak convergence and empirical processes. Springer, 1996.
[10] V. Chandrasekaran and M. I. Jordan. Computational and statistical tradeoffs via convex relaxation. arXiv preprint arXiv:1211.1073, 2012.
[11] V. Chandrasekaran, B. Recht, P. A Parrilo, and A. S. Willsky. The convex geometry of linear inverse problems. Foundations of Computational mathematics, 12(6):805–849, 2012.
[12] A. Bandeira, D. G Mixon, and B. Recht. Compressive classification and the rare eclipse problem. arXiv preprint arXiv:1404.3203, 2014.
[13] P. T. Boufounos and S. Rane. Efficient coding of signal distances using universal quantized embeddings. In Proc. Data Compression Conference (DCC), Snowbird, UT, March 20-22 2013.
Testing a Quasi-Isometric Quantized Embedding
It took me a certain time to do it. Here is at least a first attempt to test numerically the validity of some of the results I obtained in “A Quantized Johnson Lindenstrauss Lemma: The Finding of Buffon’s Needle” (arXiv)
I have decided to avoid using the too conventional matlab environment. Rather, I took this exercise as an opportunity to learn the “ipython notebooks” and the wonderful tools provided by the SciPy python ecosystem.
In short, for those of you who don’t know it, the ipython notebooks allow you to generate actual scientific HTML reports with (latex rendered) explanations and graphics.
The result cannot be properly presented on this blog (hosted on WordPress), so, I decided to share the report through IPython Notebook Viewer website.
Here it is:
“Testing a Quasi-Isometric Embedding”
(update 21/11/2013) … and a variant of it estimating a “curve of failure” (rather than playing with standard deviation analysis):
“Testing a Quasi-Isometric Embedding with Percentile Analysis”
Moreover, on these two links, you have also the possibility to download the corresponding script for running it on your own IPython notebook system.
If you have any comments or corrections, don’t hesitate to add them below in the “comment” section. Enjoy!
When Buffon’s needle problem meets the Johnson-Lindenstrauss Lemma

(left) Picture of [8, page 147] stating the initial formulation of Buffon’s needle problem (Courtesy of E. Kowalski’s blog) (right) Scheme of Buffon’s needle problem.
Last July, I read the biography of Paul Erdős written by Paul Hoffman and entitled “The Man Who Loved Only Numbers“. This is really a wonderful book sprinkled with many anecdotes about the particular life of this great mathematician and about his appealing mathematical obsessions (including prime numbers).
At one location of this book my attention was caught by the mention of what is called the “Buffon’s needle problem”. It seems to be a very old and well-known problem in the field of “geometrical probability” and I discovered later that Emmanuel Kowalski (Math dep., ETH Zürich, Switzerland) explained it in one of his blog posts.
In short, this problem, formulated by Georges-Louis Leclerc, Comte de Buffon in France in one of the numerous volumes of his impressive work entitled “L’Histoire Naturelle”, is formulated as follows:
“I suppose that in a room where the floor is simply divided by parallel joints one throws a stick (N/A: later called “needle”) in the air, and that one of the players bets that the stick will not cross any of the parallels on the floor, and that the other in contrast bets that the stick will cross some of these parallels; one asks for the chances of these two players.”
The English translation is due to [1]. The solution (published by Leclerc in 1777) is astonishingly simple: for a short needle compared to the separation 
The reason why this problem rang a bell is related to its similarity with a quantization process!
Indeed, think for a while to the needle as the segment formed by two points 


From this observation, if I realized that if we randomly turn these two points with a random rotation 


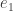
Interestingly enough, after this randomized transformation, the first coordinate of one of the two points (defining the needle extremities), say
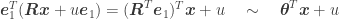
where 


This was really amazing to discover: after these very simple developments, I had in front of me a kind of triple equivalence between Buffon’s needle problem, quantization process in the plane and a well-known linear random projection procedure. This boded well for a possible extension of this context to high-dimensional (random) projection procedures, e.g., those used in common linear dimensionality reduction methods and in the compressed sensing theory.
Actually, this gave me a new point of view for solving these two connected questions: How to combine the well-known Johnson-Lindenstrauss Lemma with a quantization of the embedding it proposes? What (new) distortion of the embedding can we expect from this non-linear operation?
Let me recall the tenet of the JL Lemma: For a set 


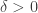
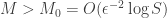

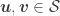

with some possible variants on the selected norms, e.g., from some measure concentration results in Banach space [6], the result is still true with the same condition on 

It took me some while but after having generalized Buffon’s needle problem to a 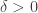

This equivalence was the starting point to discover the following proposition (the main result of the paper referenced above) which can be seen as a quantized form of the Johnson-Lindenstrauss Lemma:
Let 


Moreover, this mapping 

where 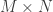
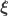
![[0, \delta]^M](https://s0.wp.com/latex.php?latex=%5B0%2C+%5Cdelta%5D%5EM&bg=ffffff&fg=333333&s=0&c=20201002)
Without entering into the details, the explanation of this result comes from the fact that the random projection 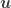

Interestingly, compared to the common JL Lemma, the mapping is now “quasi-isometric“: we observe both an additive and a multiplicative distortions on the embedded distances of 

This kind additive distortion decay was already observed for “binary” (or one-bit) quantization procedure [2, 3, 4] applied on random projection of points (e.g., for 1-bit compressed sensing). Above, we still observe such a distortion for the (multi-bit) quantization above and, moreover, this distortion is combined with a multiplicative one while both decay when
Moreover, for coarse quantization, i.e., for high
the typical size of 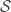
Interested blog reader can have a look to my paper for a clearer (I hope) presentation of this informal summary. His summary is as follows:
“In 1733, Georges-Louis Leclerc, Comte de Buffon in France, set the ground of geometric probability theory by defining an enlightening problem: What is the probability that a needle thrown randomly on a ground made of equispaced parallel strips lies on two of them? In this work, we show that the solution to this problem, and its generalization to
, as soon as
, we can (randomly) construct a mapping from
to
that approximately preserves the pairwise distances between the points of
. This one involves a non-linear distortion of the
.”
Hoping there is no killing bug in my developments, any comments are also welcome.
References:
[1] J. D. Hey, T. M. Neugebauer, and C. M. Pasca, “Georges-Louis Leclerc de Buffons Essays on Moral Arithmetic,” in The Selten School of Behavioral Economics, pp. 245–282. Springer, 2010.
[2] L. Jacques, J. N. Laska, P. T. Boufounos, and R. G. Baraniuk, “Robust 1-Bit Compressive Sensing via Binary Stable Embeddings of Sparse Vectors,” IEEE Transactions on Information Theory, Vol. 59(4), pp. 2082-2102, 2013.
[3] Y. Plan and R. Vershynin, “One-bit compressed sensing by linear programming,” Communications on Pure and Applied Mathematics, to appear. arXiv:1109.4299, 2011.
[4] M. Goemans and D. Williamson, “Improved approximation algorithms for maximum cut and satisfiability problems using semidefinite programming,” Journ. ACM, vol. 42, no. 6, pp. 1145, 1995.
[5] J. F. Ramaley, “Buffon’s noodle problem,” The American Mathematical Monthly, vol. 76, no. 8, pp. 916–918, 1969.
[6] M. Ledoux and M. Talagrand, Probability in Banach Spaces: Isoperimetry and Processes, Springer, 1991.
[7] P. T. Boufounos, “Universal rate-efficient scalar quantization.” Information Theory, IEEE Transactions on 58.3 (2012): 1861-1872.
[8] G. C. Buffon, “Essai d’arithmetique morale,” Supplément à l’histoire naturelle, vol. 4, 1777. See also: http://www. buffon.cnrs.fr
Recovering sparse signals from sparsely corrupted compressed measurements
Last Thursday after an email discussion with Thomas Arildsen, I was thinking again to the nice embedding properties discovered by Y. Plan and R. Vershynin in the context of 1-bit compressed sensing (CS) [1].
I was wondering if these could help in showing that a simple variant of basis pursuit denoising using a 

The answer seems to be positive when you merge these results with the simplified BPDN optimality proof of E. Candès [3]. I have gathered these developments in a very short technical report on arXiv:
Laurent Jacques, “On the optimality of a L1/L1 solver for sparse signal recovery from sparsely corrupted compressive measurements” (Submitted on 20 Mar 2013)
Abstract: This short note proves theinstance optimality of a
Briefly, in the context where a sparse or compressible signal 



where 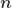

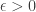

provides, under certain conditions, a bounded reconstruction error (aka

Noticeably, the two conditions (2) and (3) are not unrealistic, I mean, they are not worst than assuming the common restricted isometry property ;-). Indeed, thanks to [1,2], we can show that they hold for random Gaussian matrices as soon as 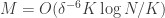

As explained in the note, it seems also that the dependency in 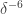
Comments are of course welcome 
References:
[1] Y. Plan and R. Vershynin, “Robust 1-bit compressed sensing and sparse logistic regression: A convex programming approach,” IEEE Transactions on Information Theory, to appear., 2012.
[2] Y. Plan and R. Vershynin, “Dimension reduction by random hyperplane tessellations,” arXiv preprint arXiv:1111.4452, 2011.
[3] E. Candès, “The restricted isometry property and its implications for compressed sensing,” Compte Rendus de l’Academie des Sciences, Paris, Serie I, vol. 346, pp. 589–592, 2008.
[4] L. Jacques, J. N. Laska, P. T. Boufounos, and R. G. Baraniuk, “Robust 1-Bit Compressive Sensing via Binary Stable Embeddings of Sparse Vectors”
IEEE Transactions on Information Theory, in press.
A useless non-RIP Gaussian matrix
Recently, for some unrelated reasons, I discovered that it is actually very easy to generate a Gaussian matrix 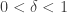


This is maybe obvious and it probably serves to nothing but here is anyway the argument.
Take a 

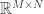




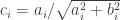
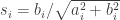
Then, it is easy to show that matrix
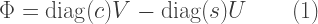
is actually Gaussian except in the direction of
This can be seen more clearly in the case where 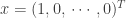


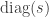



However, 

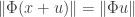
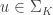


Of course, for the space of
All this is also very close from the “Cancel-then-Recover” strategy developed in [3]. The only purpose of this post to prove the (useless) result that combining two Gaussian matrices as in (1) leads to a non-RIP matrix.
References:
[1] Candes, Emmanuel J., and Terence Tao. “Decoding by linear programming.” Information Theory, IEEE Transactions on 51.12 (2005): 4203-4215.
[2] Baraniuk, Richard, et al. “A simple proof of the restricted isometry property for random matrices.” Constructive Approximation 28.3 (2008): 253-263.
[3] Davenport, Mark A., et al. “Signal processing with compressive measurements.” Selected Topics in Signal Processing, IEEE Journal of 4.2 (2010): 445-460.
Tomography of the magnetic fields of the Milky Way?
I have just found this “new” (well 150 years old actually) tomographical method… for measuring the magnetic field of our own galaxy
“New all-sky map shows the magnetic fields of the Milky Way with the highest precision“
by Niels Oppermann et al. (arxiv work available here)
Selected excerpt:
“… One way to measure cosmic magnetic fields, which has been known for over 150 years, makes use of an effect known as Faraday rotation. When polarized light passes through a magnetized medium, the plane of polarization rotates. The amount of rotation depends, among other things, on the strength and direction of the magnetic field. Therefore, observing such rotation allows one to investigate the properties of the intervening magnetic fields.”
Mmmm… very interesting, at least for my personal knowledge of the wonderful tomographical problem zoo (amongst gravitational lensing, interferometry, MRI, deflectometry).
P.S. Wow… 16 months without any post here. I’m really bad.
Some comments on Noiselets
Recently, a friend of mine asked me few questions about Noiselets for Compressed Sensing applications, i.e., in order to create efficient sensing matrices incoherent with signal which are sparse in the Haar/Daubechies wavelet basis. It seems that some of the answers are difficult to find on the web (but I’m sure they are well known to specialists) and I have therefore decided to share the ones I got.
People could be interested in using Justin’s code since, as it will be clarified from my answers given below, it is already adapted to real valued signals, i.e., it produces real valued noiselets coefficients.
matrix)? Can we use just the real part or just the imaginary part)? Any reason why you’d do one thing or another? complex values in half the noiselet-frequency domain, and concatenate the real and the imaginary part into a real vector of length
complex values in half the noiselet-frequency domain, and concatenate the real and the imaginary part into a real vector of length  . The adjoint (transposed) operation — often needed in most of Compressed Sensing solvers — must of course sum the previously split real and imaginary parts into complex values before to pad the complementary measured domain with zeros and run the inverse noiselet transform.
. The adjoint (transposed) operation — often needed in most of Compressed Sensing solvers — must of course sum the previously split real and imaginary parts into complex values before to pad the complementary measured domain with zeros and run the inverse noiselet transform.To understand the special treatment of the real and the imaginary parts (and not simply by considering it similar to what is done for Random Fourier Ensemble), let us consider the origin, that is, Coifman et al. Noiselets paper.
Recall that in this paper, two kinds of noiselets are defined. The first basis, the common Noiselets basis on the interval ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
The second basis, or Dragon Noiselets, is slightly different. Its elements are symmetric under the change of coordinates 
To be more precise, the two sets

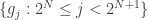
are orthonormal bases for piecewise constant functions at resolution 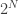
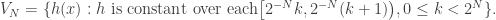
In Coifman et al. paper, the recursive definition of Eq. (2) (and also Eq (4) for Dragon Noiselets), which connects the noiselet functions between the noiselet index 
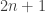
The coefficients involved in Eqs (2) and (4) are simply 
Therefore, in the Noiselet transform 

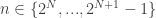
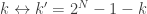
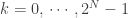
This shows that

with 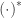

Therefore, for real valued signals, as for Fourier, the two halves of the noiselet spectrum are not independent, and therefore, only one half is necessary to perform useful CS measurements.
Justin’s code is close to this interpretation by using a real valued version of the symmetric Dragon Noiselets described in the initial Coifman et al. paper.
Q2. Are noiselets always binary? or do they take +1, -1, 0 values like Haar wavelets?
Actually, a noiselet of index 

They fill also the whole interval
Update — 26/8/2013:I was obviously wrong above on the values that noiselets can take (Thank you to Kamlesh Pawar for the detection).
Noiselet amplitude can never be zero, however, either the real part or the imaginary part (not both) can vanish for certain
So, to be correct and from few computations, a noiselet of index 
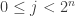
![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002)

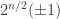

In particular, we see that the amplitude of these noiselets is always 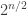
Q3. Walsh functions have the property that they are binary and zero mean, so that one half of the values are 1 and the other half are -1. Is it the same case with the real and/or imag parts of the noiselet transform?
To be correct, Walsh-Hadamard functions have mean equal to 1 if their index is a power of 2 and 0 else, starting with the [0,1] indicator function of index 1.
For Noiselets, they are all of unit average, meaning that the imaginary part has the zero average property. This can be proved easily (by induction) from their recursive definition in Coifman et al. paper (Eqts (2) and (4)). Interestingly, their unit average, that is their projection on the unit constant function, shows directly that a constant function is not sparse at all in the noiselet basis since its “noiselet spectrum” is just flat.
In fact, it is explained in Coifman paper that any Haar-Walsh wavelet packets, that is, elementary functions of formula

with 

Q4. How come noiselets require O(N logN) computations rather than O(N) like the haar transform?
This is a verrry common confusion. The difference comes from the locality of the Haar basis elements.
For the Haar transform, you can use the well known pyramidal algorithm running in 
For the 3 bases Hadamard-Walsh, Noiselets and Fourier, their non-locality (i.e., their support is the whole segment [0, 1]) you cannot run a similar alorithm. However, you can use the Cooley-Tukey algorithm arising from the Butterfly diagrams linked to the corresponding recursive definitions (Eqs (2) and (4) above).
This one is in 
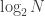
Feel free to comment this post and ask other questions. It will provide perhaps eventually a general Noiselet FAQ/HOWTO
New class of RIP matrices ?
Wouaw, almost one year and half without any post here…. Shame on me! I’ll try to be more productive with shorter posts now
I just found this interesting paper about concentration properties of submodular function (very common in “Graph Cut” methods for instance) on arxiv:
A note on concentration of submodular functions. (arXiv:1005.2791v1 [cs.DM])
Jan Vondrak, May 18, 2010
We survey a few concentration inequalities for submodular and fractionally subadditive functions of independent random variables, implied by the entropy method for self-bounding functions. The power of these concentration bounds is that they are dimension-free, in particular implying standard deviation O(\sqrt{\E[f]}) rather than O(\sqrt{n}) which can be obtained for any 1-Lipschitz function of n variables.
In particular, the author shows some interesting concentration results in his corollary 3.2.
Without having performed any developments, I’m wondering if this result could serve to define a new class of matrices (or non-linear operators) satisfying either the Johnson-Lindenstrauss Lemma or the Restricted Isometry Property.
For instance, by starting from Bernoulli vectors 



Ok, all this is perhaps just due to too early thoughts …. before my mug of black coffee
1000th visit and some Compressed Sensing “humour”
 As detected by Igor Carron, this blog has reached its 1000th visit ! Well, perhaps it’s 1000th robot visit
As detected by Igor Carron, this blog has reached its 1000th visit ! Well, perhaps it’s 1000th robot visit
Yesterday I found some very funny (math) jokes on Bjørn’s maths blog about “How to catch a lion in the Sahara desert” with some … mathematical tools.
Bjørn collected there many ways to realize this task from many places on the web. There are really tons of examples. To give you an idea, here is the Schrodinger’s method:
“At any given moment there is a positive probability that there is a lion in the cage. Sit down and wait.”
or this one :
“The method of inverse geometry: We place a spherical cage in the desert and enter it. We then perform an inverse operation with respect to the cage. The lion is then inside the cage and we are outside.”
So, let’s try something about Compressed Sensing. (Note: if you have something better than my infamous suggestion, I would be very happy to read it as a comment to this post.)
“How to catch a lion in the Sahara desert”
The compressed sensing way: First you consider that only one lion in a big desert is definitely a very sparse situation by comparing lion’s size and the desert area. No need for a cage, just project randomly the whole desert into a dune of just 5 times the lion’s weight ! Since the lion obviously died in this shrinking operation, you use the RIP (!) .. and relaxed, you eventually reconstruct its best tame approximation.
Image: Wikipedia
SPGL1 and TV: Answers from SPGL1 Authors
Following the writing of my previous post, which obtained various interesting comments (many thanks to Gabriel Peyré, Igor Carron and Pierre Vandergheynst), I sent a mail to Michael P. Friedlander and Ewout van den Berg to point them this article and possibly obtain their point of views.
Nicely, they sent me interesting answers (many thanks to them). Here they are (using the notations of the previous post) :
Michael’s answer is about the need of a TV Lasso solver :
“It’s an intriguing project that you describe. I suppose in principle the theory behind spgl1 should readily extend to TV (though I haven’t thought how a semi-norm might change things). But I’m not sure how easy it’ll be to solve the “TV-Lasso” subproblems. Would be great if you can see a way to do it efficiently. “
Ewout on his side explained this :
“The idea you suggest may very well be feasible, as the approach taken in SPGL1 can be extended to other norms (i.e., not just the one-norm), as long as the dual norm is known and there is way to orthogonally project onto the ball induced by the primal norm. In fact, the newly released version of SPGL1 takes advantage of this and now supports two new formulations.
I heard (I haven’t had time to read the paper) that Chambolle has described the dual to the
TV-norm. Since the derivate ofon the appropriate interval is given by the dual norm on
, that part should be fine (for the one norm this gives the infinity norm).
In SPGL1 we solve the Lasso problem using a spectrally projected gradient method, which
means we need to have an orthogonal projector for the one-norm ball of radius. It is not immediately obvious how to (efficiently) solve the related problem (for a given
minimize
subject to
.
However, the general approach taken in SPGL1 does not really care about how the Lasso
subproblem is solved, so if there is any efficient way to solveminimize
subject to
,
then that would be equally good. Unfortunately it seems the complexification trick (see the previous post) works only from the image to the differences; when working with the differences themselves, additional constraints would be needed to ensure consistency in the image; i.e., that
summing up the difference of going right first and then down, be equal to the sum of
going down first and then right.”
In a second mail, Ewout added an explanation on this last remark :
“I was thinking that perhaps, instead of minimizing over the signal it would be possible to minimize over the differences (expressed in complex numbers in the two-dimensional setting). The problem with that is that most complex vectors do not represent difference vectors (i.e., the differences would not add up properly). For such an approach to work, this consistency would have to be enforced by adding some constraints.”
Actually, I saw similar considerations in A. Chambolle‘s paper: “An Algorithm for Total Variation Minimization and Applications”. It is even more clear in the paper he wrote with J.-F. Aujol, “Dual Norms and Image Decomposition Models”. They develop there the notions of TV (semi) norm for different exponent 


where, as for the continuous setting, 




Unfortunately, the G norm computation seems not so obvious that the one of its dual counterpart and an optimization method must be used. I don’t know if this could lead to an efficient implementation of a TV spgl1.
SPGL1 and TV minimization ?
Recently, I was using the SPGL1 toolbox to recover some “compressed sensed” images. As a reminder, SPGL1 implements the method described in “Probing the Pareto Frontier for basis pursuit solutions” of Michael P. Friedlander and Ewout van den Berg. It solves the Basis Pursuit DeNoise (or 


where 



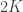



The reason of this post is the following : I’m wondering if SPGL1 could be “easily” transformed into a solver of the Basis Pursuit with the Total Variation (TV) norm. That is, the minimization problem


where 



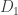
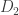


This problem is particularly well designed for the reconstruction of compressed sensed images since most of them are very sparse in the “gradient basis” (see for instance some references about Compressed Sensing for MRI). Minimizing the TV norm, since performed in the spatial domain, is also sometimes more efficient than minimizing the
Therefore, I would say that, as for the initial SPGL1 theoretical framework, it could be interesting to study the Pareto frontier related to 




To explain better that point, let me first summarize the paper of Friedlander and van den Berg quoted above. They proposed to solve 


If I’m right, the key idea is that there exists a 






is decreasing from 


Interestingly, the derivative 
![{[}0, \tau{]}](https://s0.wp.com/latex.php?latex=%7B%5B%7D0%2C+%5Ctau%7B%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002)


As explained, on the point 

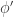

At the end, the whole approach is very efficient for solving high dimensional BPDN problems (such that BPDN for images) and the final computation cost is mainly due to the cost of the forward and transposed multiplication of the matrix/operator
So what happens now if the
The function 




For the rest, I’m unfortunately not sufficiently familiar with convex optimization theory to deduce what is
However, for the 


where 
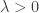
For the TV minimization case, the TV ball 

This is somehow related to one of the lessons provided in the TwIST paper (“A new twIst: two-step iterative shrinkage/thresholding algorithms for image restoration”) of J. Bioucas-Dias and M. Figueiredo about the so-called Moreau function : There is a deep link between some iterative resolutions of a regularized BP problem using a given sparsity metric, e.g. the
Thanks to the implementation of Antonin Chambolle (used also by TwIST), this last canonic TV minimization can be computed very quickly. Therefore, if needed, the required projection on the TV ball above can be also inserted in a potential “SPGL1 for TV sparsity problem”.
OK… I agree that all that is just a very rough intuition. There is a lot of points to clarify and to develop. However, if you know something about all that (or if you detect that I’m totally wrong), or if you just want to comment this idea, feel free to use the comment box below …
Matching Pursuit Before Computer Science
Recently, I have found some interesting references about techniques designed around 1938 and that, in my opinion, could be qualified of (variant of) Matching Pursuit. Perhaps this is something known by a lot of researchers in the right scientific field, but here is however what I recently discovered.
From what I knew until yesterday, when S. Mallat and Z. Zhang [1] defined their greedy or iterative algorithm named “Matching Pursuit” to decompose a signal 


In short, MP is very simple. It reads (using matrix notations)

with at each step

The quantities 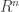
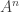
It is proved in [1] that MP converges always to … something, since the energy of the residual 





Dozens (or hundreds ?) of variations of these initial greedy methods have been introduced since their first formulations in the signal processing community. These variations have improved for instance the initial MP rate of convergence through the iterations, or the ability to solve the sparse approximation problem (i.e. finding
Another variation of (O)MP explained by K. Schnass and P. Vandergheynst in [3], splits the sensing part from the reconstruction part in the initial MP algorithm above (adding also the possibility to select more than only one atom per iteration). Indeed, the selection of the best atom 
I introduced more precisely this last (O)MP variation above since it is under this form that I discovered it in the separated works of R.V. Southwell [4] and G. Temple [5] (the last being more readable in my opinion) in 1935 and in 1938 (!!), i.e. before the building of the first (electronic) computers in the 40’s.
The context of the method in the initial Southwell’s work was the determination of stresses in structures. Let’s summarize his problem : the structure was modelized by 




The global problem of Southwell was thus : given a linear system of equations 

Nowadays, the numerical solution seems trivial : take the inverse of 
However, imagine the same problem in the 30’s ! And assume you have to inverse a ridiculously small matrix of size 13×13. It can be really long to solve it analytically and worthless since you are interested in finding 
The technique found by R.V. Southwell and generalized later by Temple [4,5], was dubbed of “Successive Relaxation” inside a more general context named “Successive Approximations”. Mathematically, rewriting that work under notations similar to these of modern Matching Pursuit methods, Successive Relaxation algorithm reads :

where 
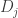

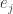

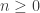

i.e. the component of the
In this framework, since 


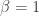
In other words, in the concepts introduced in [3], they designed a Matching Pursuit where they selected for the reconstruction dictionary the orthonormal basis 
An interesting learning of the algorithm above is the presence of the factor
G. Temple in [5] extended also the method to infinite dimensional Hilbert spaces for a different updating step of
By googling a bit on “matching pursuit” and Southwell, I found this presentation of Peter Buhlmann who makes a more general connection between Southwell’s work, Matching Pursuit, and greedy algorithms (around slide 15) in the context of “Iterated Regularization for High-Dimensional Data“.
In conclusion of all that, who is this person who explained that we do nothing but always reinventing the wheel ?
If you want to complete this kind of “archeology of Matching Pursuit” please feel free to add some comments below. I’ll be happy to read them and improve my general knowledge of the topic.
Laurent
References :
[1] : S. G. Mallat and Z. Zhang, Matching Pursuits with Time-Frequency Dictionaries, IEEE Transactions on Signal Processing, December 1993, pp. 3397-3415.
[2] : J. H. Friedman and J. W. Tukey (Sept. 1974). “A Projection Pursuit Algorithm for Exploratory Data Analysis“. IEEE Transactions on Computers C-23 (9): 881–890. doi:10.1109/T-C.1974.224051. ISSN 0018-9340.
[3] : K. Schnass and P. Vandergheynst, Dictionary preconditioning for greedy algorithms, IEEE Transactions on Signal Processing, Vol. 56, Nr. 5, pp. 1994-2002, 2008.
[4] : R. V. Southwell, “Stress-Calculation in Frameworks by the Method of “Systematic Relaxation of Constraints“. I and II. Proc Roy. Soc. Series A, Mathematical and Physical Sciences, Vol. 151, No. 872 (Aug. 1, 1935), pp. 56-95
[5] : G. Temple, The General Theory of Relaxation Methods Applied to Linear Systems, Proc. Roy. Soc. Series A, Mathematical and Physical Sciences, Vol. 169, No. 939 (Mar. 7, 1939), pp. 476-500.
[6] : L. Jacques and C. De Vleeschouwer, “A Geometrical Study of Matching Pursuit Parametrization“, Signal Processing, IEEE Transactions on [see also Acoustics, Speech, and Signal Processing, IEEE Transactions on], 2008, Vol. 56(7), pp. 2835-2848
[7] : R.A. DeVore and V.N. Temlyakov. “Some remarks on greedy algorithms.” Adv. Comput. Math., 5:173–187, 1996.
[8] : Y. C. Pati, R. Rezaiifar, and P. S. Krishnaprasad, “Orthogonal projection pursuit: Recursive function approximation with applications to wavelet decomposition,” in Proceedings of Twenty-Seventh Asilomar Conference on Signals, Systems and Computers, vol. 1, (Pacific Grove, CA), pp. 40-
44, NOV. 1-3, 1993.
[9] : Tropp, J, “Greed is good: algorithmic results for sparse approximation“, IEEE T. Inform. Theory., 2004, 50, 2231-2242
Image credit :
EDSAC was one of the first computers to implement the stored program (von Neumann) architecture. Wikipedia.
First news

I hope I will introduce here some interesting elements about the scientific interests of an humble researcher in applied mathematics. As you will understand, my English is far to be perfect but I’ll try to do my best to express myself correctly (not as a native English however).
To give you an idea, my fields of research are rather various. One of them is “signal representation”, a subtopic of “signal processing”. The term signal has to be understood in its wide sense, I mean, signals living in 1-D (like the record of a piece of music), 2-D or n-D (e.g. images, videos, or multi-modal signals), or on more esoteric spaces like the sphere (imagine the measure of the temperature field all over the world). Signal can also be described as data provided on a given manifold, e.g. like the electric potential on a molecular surface, or this manifold itself like the high dimensional space of all the images produced by a moving camera …
I work also on how to obtain or tune a signal “representation” using concepts, methods or algorithms like *-lets basis, dictionaries, signal sparsity, signal compressibility, Basis Pursuit, *-Matching Pursuits, compressed sensing, … I’m interested also in applications like plenoptic imaging, light field rendering, computational photography, … i.e. new ways to record visible information of the world. So, most of the news I’ll publish here will concern more or less directly one of these elements. I do not plan to write here final reflection or results so be aware that I will write sometimes erroneous explanations (C’est la vie). But I’m sure you’ll help me to improve them by inserting comments.
So, in one word : welcome !
Laurent
Image Credit : Wikipedia.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK