

股票行情数据下载
source link: https://blog.jiahonzheng.com/post/stock-data-download/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

最近,我在折腾 Python 股票选股的事情,摸索出了一种股票行情数据的下载与持久化的方法,就写了本篇博客来记录一下。
数据源选择
TuShare 是一个免费、开源的 Python 财经数据接口包,但其积分体系确实有些门槛,容易让人劝退。不走寻常路,我选择了爬虫方案:爬取东方财富网的股票行情数据。
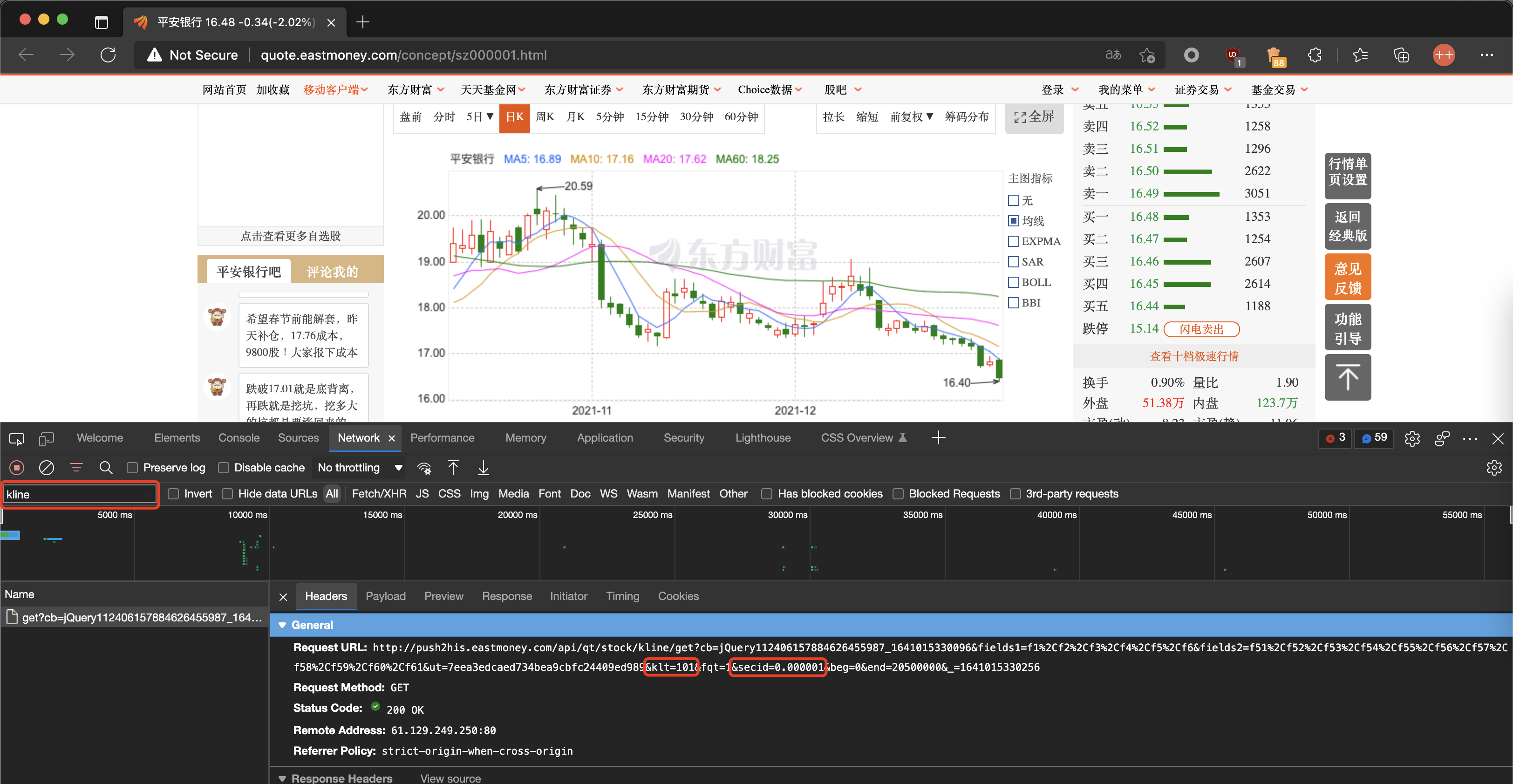
上图是 000001(平安银行) 的行情数据。通过网络抓包,可以发现一个 https://push2his.eastmoney.com/api/qt/stock/kline/get 的请求,其有三个重要的 Query 参数:klt、secid、fqt,分别指行情周期类型、股票代码、价格复权方式。
当我想手撸相关的爬虫代码时,我在 Google 上搜索了 https://push2his.eastmoney.com/api/qt/stock/kline/get ,找到了这篇文章。
文章也是采用爬取财经网站的思路,并将其实现 efinance 在 GitHub 上开源,功能强大,重点是免费且没有积分门槛!
- 支持股票历史日 K 线数据的获取。
- 支持非 A 股的股票 K 线数据的获取(支持输入股票名称以及代码)。
- 支持 ETF K 线数据的获取。
- 支持基金历史净值信息的获取。
- 支持期货历史行情的获取。
efinance 提供了易用的 API 接口,获取行情数据还是非常方便、自然的!
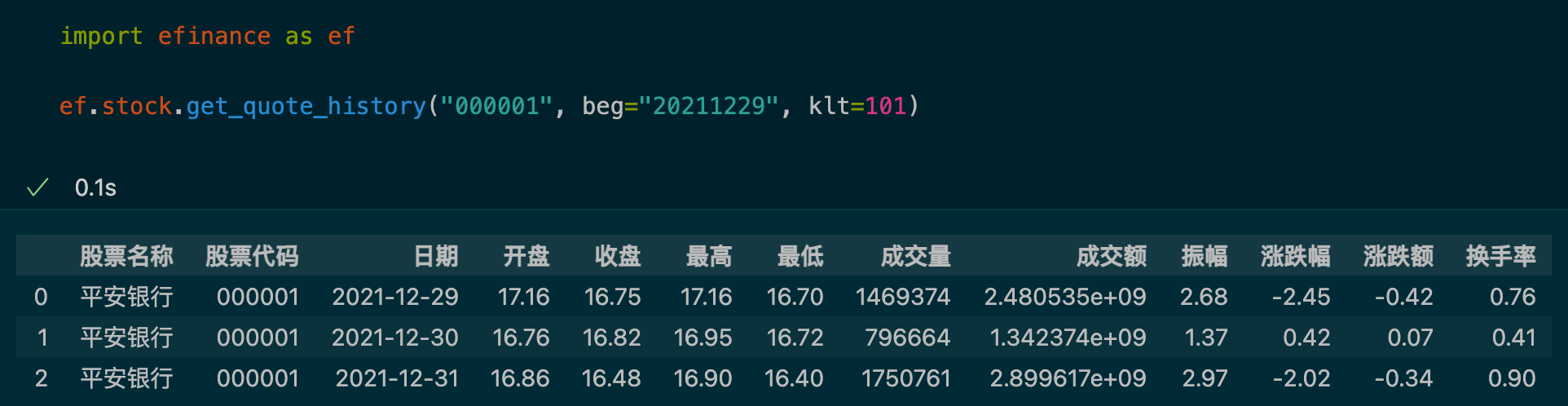
基于 DRY 原则,我打算在该库的基础上,实现数据持久化的能力。
由于预期的选股策略是建立在较大时间周期的(省心),因此我只需要日线、周线和月线数据即可。在实现中,我定义了 KLT 类型,这对应着爬虫语句的 klt 参数,以及 efinance 的输入参数。
- 101: 日线
- 102: 周线
- 103: 月线
为什么要定义 KLT 类型?因为我想有个更好的类型提示体验!当输入错误的 klt 参数时,我希望 Pylance 能够提供错误提示。关于 Pylance 的介绍,可以看看我的另一篇文章 VSCode 搭建 Python 开发环境 。
from typing import Literal
KLT = Literal[101, 102, 103]
与 KLT 对应,我创建了 3 个目录,用于不同时间周期的行情数据存储。
import os
# 创建数据目录。
BASE = "."
[os.makedirs(f"{BASE}/data/{klt}", exist_ok=True) for klt in [101, 102, 103]]
此外,我还实现了 get_filename 函数,可快速获取行情数据文件的文件名。
def get_filename(code: str, klt: KLT) -> str:
"""获取行情数据文件名。
Args:
code (str): 股票代码
klt (KLT): 行情类型
Returns:
str: 行情数据文件名
"""
return f"{BASE}/data/{klt}/{code}.csv"
函数 get_quote_history 的返回值是 DataFrame 类型,其 to_csv 方法可实现数据保存至 CSV 文件的功能。
# 保存数据至 CSV 文件。
data.to_csv("data/101/000001.csv", index=False)
# 追加数据至 CSV 文件。
data.to_csv("data/101/000001.csv", header=False, index=False, mode="ab")
为减少存储成本,我将 股票名称 和 股票代码 两列信息移除。
data.drop(data.columns[[0, 1]], axis=1, inplace=True)
由于每日都有新行情的变更,这就涉及到了 全量下载 和 增量下载 的问题。
- 数据文件不存在:全量下载
- 数据文件存在:增量下载
全量下载与增量下载的区别,其实在于请求数据接口时的 beg 参数,这是行情数据的起始时间。观察 data/101/000001.csv 文件,可以观察到:文件最后一行是空行,倒数第二行是有效数据,有效数据的时间格式为 YYYY-MM-DD 。

有了这些信息,即可解析出每个行情数据文件的最新日期,并以此实现全量下载或增量下载。
def get_next_trade_date(code: str, klt: KLT) -> str:
"""获取下载数据时的起始交易日期。
Args:
code (str): 股票代码
klt (KLT): 行情类型
Returns:
str: 下载数据时的起始交易日期
"""
filename = get_filename(code, klt)
# 若不存在数据文件,则为全量数据下载。
if not os.path.exists(filename):
return "0"
with open(filename, "rb") as f:
# 读取最后一行有效数据,并解析出其交易日期。
f.seek(-2, os.SEEK_END)
while f.read(1) != b"\n":
f.seek(-2, os.SEEK_CUR)
last_data = f.readline().decode()
last_trade_date_str = last_data.split(",")[0]
last_trade_date = datetime.datetime.strptime(last_trade_date_str, "%Y-%m-%d")
# 直接将 last_trade_date + 1 视为下一个交易日期,因为数据下载接口实现了兼容。
next_trade_date = last_trade_date + datetime.timedelta(days=1)
return datetime.datetime.strftime(next_trade_date, "%Y%m%d")
通过 get_next_trade_date 函数,可计算出 beg 参数,进而下载对应时间范围内的行情数据。
def persist_stock(code: str, klt: KLT):
"""下载股票行情数据。
Args:
code (str): 股票代码
klt (KLT): 行情类型
"""
# 下载行情数据。
next_trade_date = get_next_trade_date(code, klt)
data = ef.stock.get_quote_history(code, beg=next_trade_date, klt=klt, fqt=1)
if (not isinstance(data, DataFrame)) or len(data) == 0:
return
# 丢弃无用数据,降低存储成本。
data.drop(data.columns[[0, 1]], axis=1, inplace=True)
# 保存数据。
filename = get_filename(code, klt)
if next_trade_date == "0":
# 保存全量数据。
data.to_csv(filename, index=False)
else:
# 保存增量数据。
data.to_csv(filename, header=False, index=False, mode="ab")
多线程下载
上述的 persist_stock 函数,只实现了单一股票的行情数据下载。而截至当前,A 股市场有 4683 只股票。这种情况下,就得使用多线程下载策略了。
首先,我们需要知道市场上的所有股票代码。在实现中,我使用了 TuShare 的 stock_basic 接口,因为 efinance 并没有提供该接口。
# 获取所有股票代码。
basic = pro.query(api_name="stock_basic", fields=["symbol"])
stocks = basic["symbol"]
通过使用 multiprocessing.dummy.Pool 的相关方法,我实现了一个大小为 8 的线程池,用于行情数据的下载。
# 创建进度指示器。
pbar = tqdm(total=len(stocks))
def do_work(code: str, klt: KLT):
persist_stock(code, klt)
pbar.update(1)
# 并行下载行情数据。
pool = Pool(8)
for stock in stocks:
pool.apply_async(func=do_work, args=(stock, klt))
pool.close()
pool.join()
此外,通过配合 tqdm ,我还实现了直观的下载进度展示功能。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK