

图像搜索引擎
source link: https://developer.51cto.com/article/705440.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


译者 | 朱先忠
审校 | 梁策 孙淑娟
相似图像检索是任何图像相关的搜索,即“基于内容的图像检索系统”,简称 “CBIR”系统。
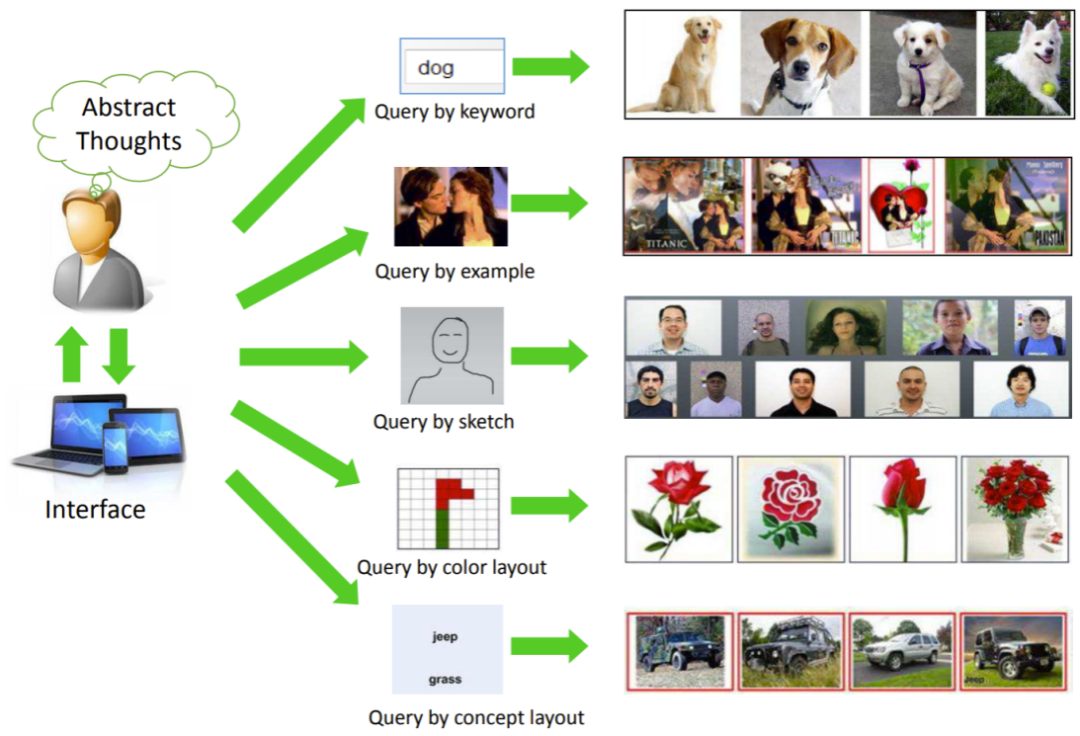
上述图像来自文章《基于内容的图像检索:前沿文献调查(2017年)》(https://arxiv.org/abs/1706.06064)
如今,图片搜索的应用日益广泛,尤其在电子商务服务(如AliExpress、Wildberries等)领域。“关键词搜索”(包括图像内容理解)早已在谷歌、Yandex等搜索引擎中站稳脚跟,但在市场和其他私人搜索引擎应用还较为有限。计算机视觉领域中连接文本与图像的对比语言图像预训练CLIP(https://openai.com/blog/clip/)问世后便引发轰动,因而也将加速其全球化进程。
我们的团队专门研究计算机视觉中的神经网络,因此在本文中我将专注介绍通过图像搜索的方法。
1、基本服务组件
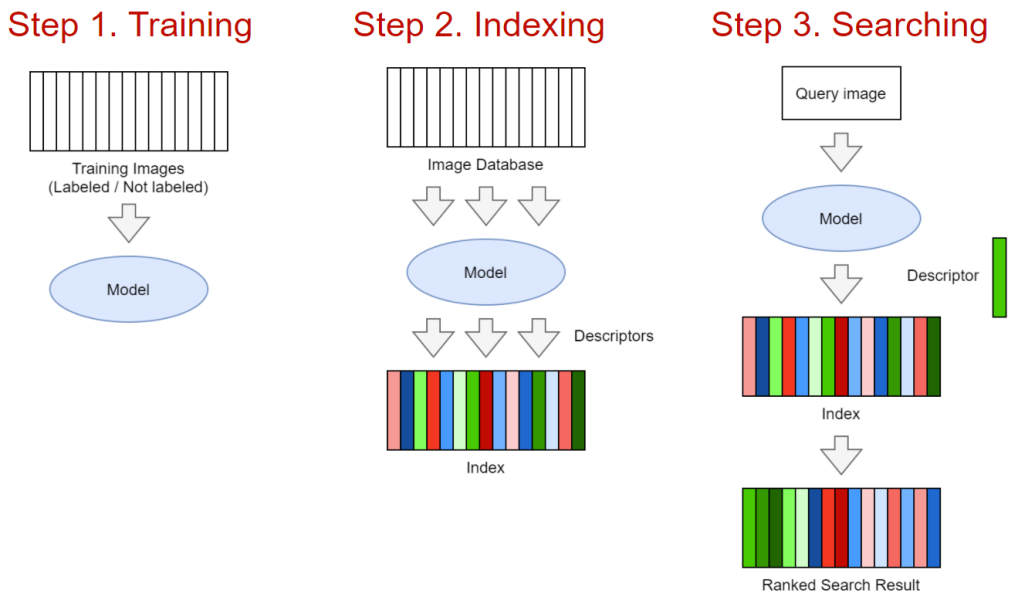
第一步:训练模型。模型部分可以基于经典计算机视觉或神经网络基础来建立。模型输入部分是一幅图像,输出部分则是一个D维描述符/嵌入层。在经典的实现方案中,可以采用SIFT(Scale-invariant feature transform, 尺度不变特征变换)描述符和BoW (bag-of-visual-words,视觉词袋)算法相组合的策略。但是在神经网络方案中,可以采用标准算法模型(如ResNet、EfficientNet等)结合复杂的池化层,再进一步结合出色的学习技术。如果数据够多或者经过良好训练,选择神经网络方案几乎总会得到比较满意的结果(有亲测实例),所以本文中我们将重点关注这一方案。
第二步:索引图像。这一步就是在所有图像上运行训练好的模型,并将嵌入内容写入一个特殊的索引,以便快速搜索。
第三步:搜索。使用用户上传的图像,运行模型,获得嵌入层,并将嵌入层与数据库中的其他嵌入层数据进行比较。最后的搜索结果按相关性排序。
2、神经网络与度量学习
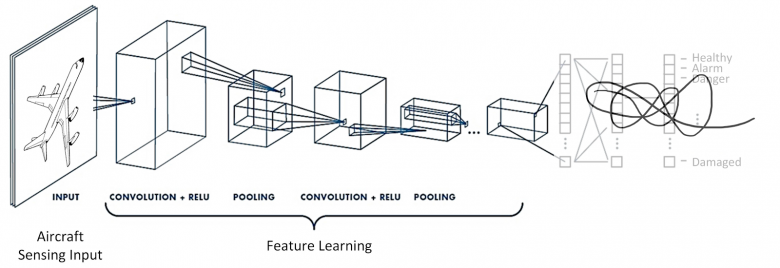
在寻找相似性的任务中,我们使用神经网络作为特征提取器(主干网络)。当然,主干网络的选择取决于数据的容量和复杂性——你可以根据自己的开发需求选择从ReNET18残差网络模型到Visual Transformer模型的所有可选方案。
图像检索模型的第一个特征当属神经网络输出部分的实现技术。在图像检索排行榜(https://kobiso.github.io/Computer-Vision-Leaderboard/cars.html)上,不同的图像检索算法都是为了构建出最理想的描述符——例如有使用并行池化层的组合全局描述符(Combined Global Descriptors)算法,还有为了在输出功能上实现更均匀激活分布的批处理删除块算法。
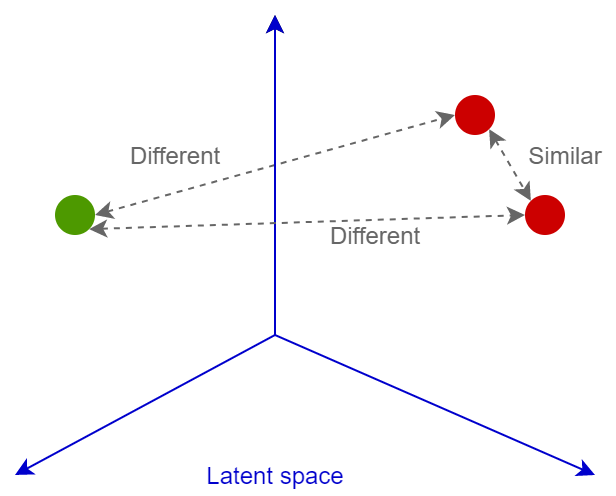
第二个主要特征是损失函数。目前人工智能领域已经有不少损失函数,比如仅在《深度图像检索调查》(https://arxiv.org/abs/2101.11282)一文中就提到了十几种推荐的损失函数算法。同时,也存在数量相当的分类函数。所有这些损失函数的主要目标都是为了训练神经网络以便将图像转换为线性可分离的空间向量,从而进一步通过余弦或欧几里德距离比较这些向量:相似的图像会拥有相近的嵌入层,不相似的图像则会拥有极为不同的嵌入层。接下来,让我们对这些内容作进一步介绍。
1、对比损失函数(Contrastive Loss)
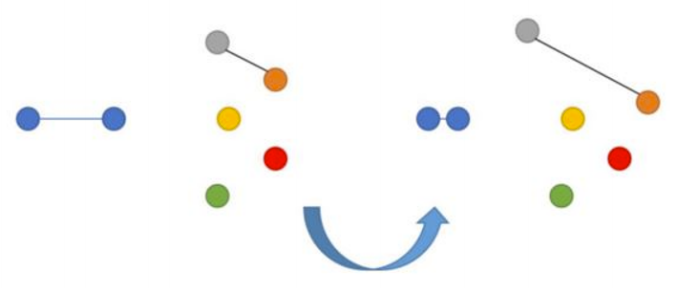
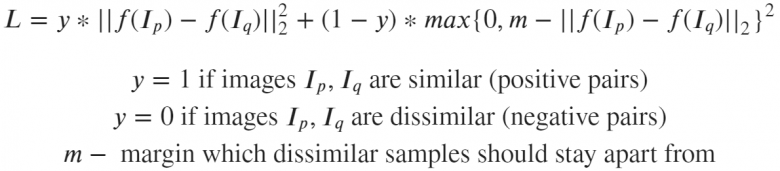
这种算法中存在一种双重损失的情况,往往发生在比较彼此之间的距离的对象身上。
如果图像p和q实际上是很相似的,那么神经网络会因图像p和q的嵌入层之间的距离而受到惩罚。类似地,因应用了嵌入层的接近性也会存在神经网络惩罚的情况,因为事实上嵌入层的图像实际上彼此是不同的。在后面这种情况下,我们可以设置一个边界值m(例如赋值为0.5),目的是为了克服我们想当然地认为神经网络已经处理了“分离”不相似图像任务的想法。
2、三元组损失函数(Triplet Loss)
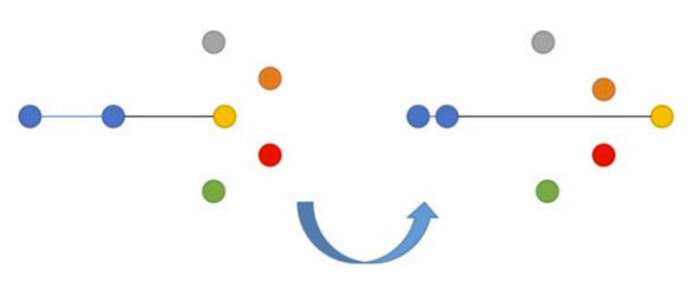

在这里,我们的目标是最小化锚点到正例的距离,而最大化锚点到负例的距离。三元组损失函数最早见于谷歌FaceNet模型关于人脸识别的文章中,长期以来一直是最先进的解决方案。
3、N元组损失函数(N-tupled)
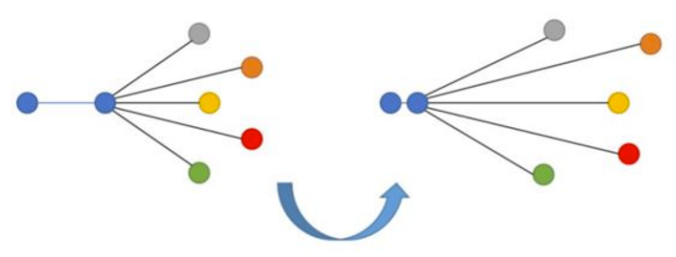

N元组损失函数是基于三元组损失函数进一步的研究成果,此函数也采用了锚点和正例概念,但使用的是多个而非单个负例技术。
4、加性角度间隔损失函数(Angular Additive Margin,也称ArcFace)
配对损失函数的问题在于选择正例、负例和锚点的组合方面——如果只是从数据集中均匀随机选取它们,那么就会出现“轻配对”的问题。出现这种简单的图像配对时,损失为0。事实证明,此情况下网络会很快收敛到一种状态,在这种状态下,批次中的大多数元素都极易处理,其损失将变成零——此时神经网络将停止学习。为了避免这个问题,此算法的开发人员开始提出复杂的配对挖掘技术——硬负例挖掘和硬正例挖掘。有关问题可参见(https://gombru.github.io/2019/04/03/ranking_loss/),该文章比较了多种损失函数。此外PML库(https://github.com/KevinMusgrave/pytorch-metric-learning)也实现了许多挖掘方法。值得注意的是,这个库中包含了许多在PyTorch框架上度量学习任务的有用信息。
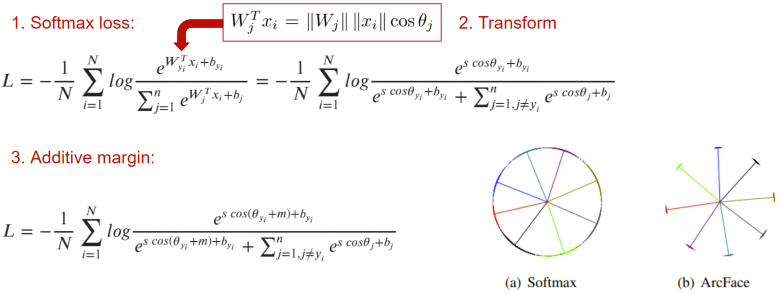
解决上述问题的另一种方案是使用分类损失函数。我们不妨回想三年前推出的面部识别算法ArcFace,它是当时最先进的,也导致了当时众所周知的“缺陷”特征的存在。
该算法的主要思想是在通常的交叉熵的基础上增加一个缩进m,该交叉熵将一类图像的嵌入层分布在该类图像的质心区域,以便它们都与其他类的嵌入层簇至少相隔一个角度m。
这看起来似乎是一个完美的损失函数解决方案,尤其是当针对MegaFace基准(https://paperswithcode.com/sota/face-verification-on-megaface)规模开发人工智能系统时。但需要记住,只有在存在分类标记的情况下,此算法才会起作用;否则,你将不得不面临配对损失函数问题。
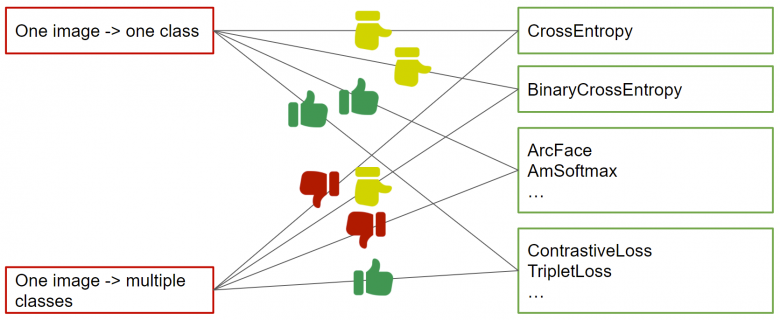
上图中直观地展示了使用单类标记和多类标记时,哪些损失函数最适合(可通过计算多标签向量样本之间的交集百分比,从多类标记中导出配对标记)。
现在,让我们回顾一下神经网络体系结构,不妨考虑在执行图像检索任务中使用一对池化层的情形。
1、R-MAC池化
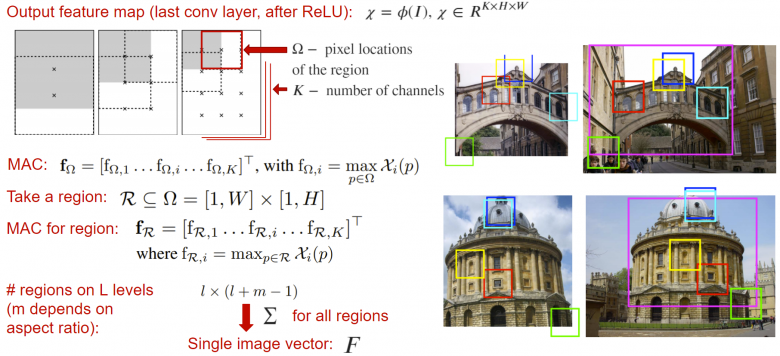
R-MAC(区域最大卷积激活)是一个池化层,它接受神经网络的输出映射(在全局池化层或分类层之前),并返回一个描述符向量,此向量为输出图中各个窗户中的激活量之和。在这里,窗户的激活量取为每个通道单独获取该窗户的最大值。
这个结果描述符的计算过程中考虑了图像在不同尺度下的局部特征,从而创建了一个内容丰富的特征描述。这个描述符本身可以是一个嵌入层,因此可以直接发送到损失函数。
2、GeM池化
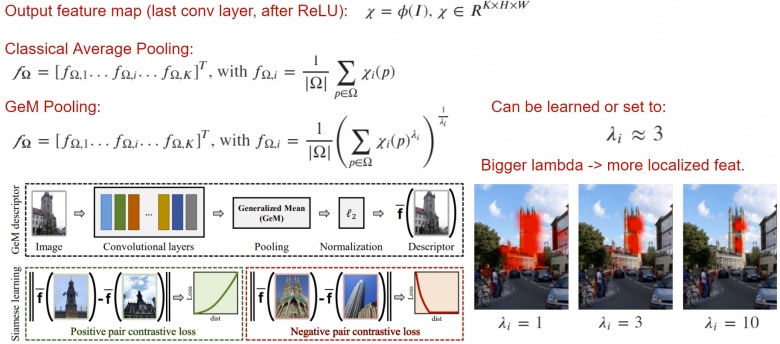
GeM(广义平均池化)是一种简单的池化算法,可以提高输出描述符的质量。底线是,经典的平均池化可以推广到lambda范数。通过增加lambda层,我们使神经网络关注图像的重要部分,这在某些任务中可能很重要。
高质量搜索相似图像的关键是排名,即显示给定查询的最相关样本。此过程的基本特征包括:建立描述符索引的速度、搜索的速度和占用的内存。
最简单的方法是保持嵌入层“对着正面”并对其进行强力搜索,例如使用余弦距离实现。但是,这种方法在有大量嵌入层时会出现问题——数量可能是数百万、数千万甚至更多。而且,搜索速度显著降低,占用的堆空间也会进一步增加。不过,还是存在积极的方面——使用现有的嵌入层即可实现完美的搜索质量。
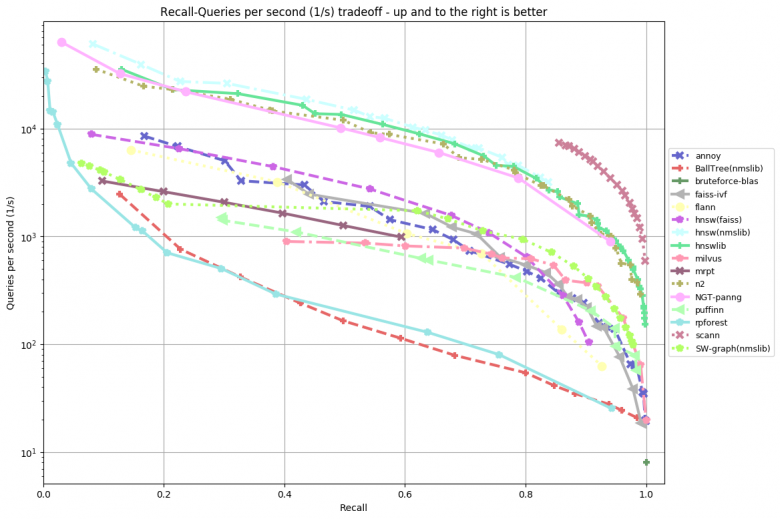
这几个问题可以以牺牲质量为代价来解决——以压缩(量化)而不是以原始形式存储嵌入层。而且还要改变搜索策略——不是使用暴力搜索,而是尝试进行最小比较次数以找到与给定查询最接近的所需比较次数。目前已经存在大量有效的搜索框架可以近似搜索最接近的内容。为实现这一目的,一个特殊的基准测试已经创建——根据这个基准你可以观测到每一种库在不同数据集上的表现。
其中,最受欢迎的库有:NMSLIB(非度量空间库)、Spotify的Have库、Facebook的Faiss库以及Google的Scann库等。此外,如果您想用REST API进行索引的话,可以考虑使用Jina应用程序(https://github.com/jina-ai/jina)。
2、重新排名
信息检索领域的研究人员早就了解到,在收到原始搜索结果后,可以通过某种方式对项目重新排序来改进有序的搜索结果。
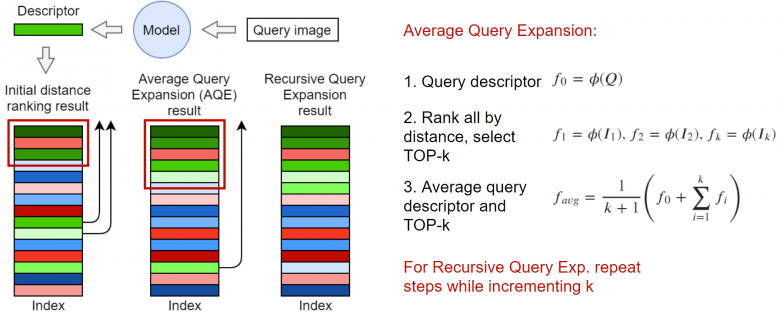
一种著名的算法是拓展查询(Query Expansion)。该算法的核心思想是使用最接近元素集合中的前top-K个元素生成新的嵌入层。在最简单的情况下,可以如上图所示取平均向量。其实,你还可以根据问题中的距离或与请求的余弦距离对嵌入层进行加权操作。在《基于注意力的查询扩展学习》(https://arxiv.org/abs/2007.08019)一文中有详细提到了一个框架,或者你也可以通过递归方式来使用拓展查询算法。
3、k近邻算法

上图是一个人物最近物体识别的应用程序截图。其中,图上部给出了查询及其10个最近邻数据,其中P1-P4为正例,NI-N6为负例。图底部中的每两列显示样本人物的10个最近邻居。蓝色和绿色框分别对应于样本人物和正例。我们可以观察到,样本人物和正例相互之间有10个最近的邻居。
k近邻算法主要围绕前top-k个元素展开,其中包括最接近请求本身的k个元素。
在这个集合的基础上,建立了对结果重新排序的过程,其中有一个过程在文章《基于k近邻算法的人物再识别信息重排序研究》 (https://arxiv.org/abs/1701.08398)中给出了描述。根据定义,k近邻算法(k-reciprocal)比k最近邻算法(k-nearest neighbors)更接近查询结果。因此,人们可以粗略地认为K近邻算法集合中的元素是正例,并且可以进一步改变加权规则用于类似于拓展查询这样的算法。
在该文中,一种机制已开发出来,它可以使用top-k中元素本身的k-近邻集合来重新计算距离。该文包含大量计算信息,暂时不在本文的讨论范围内,建议有兴趣的读者可以找来自行阅读。
相似图像搜索算法效果分析
接下来,我们来分析一下本文提出的相似图像搜索算法的质量问题。值得注意的是,实现这项搜索任务过程中存在许多细节,而初学者在第一次开发图像检索项目时很可能不会注意到这些问题。
本文将探讨在图像检索领域普遍使用的一些流行度量算法,比如precision@k、recall@k、R- precision、mAP和nDCG等。
【译者补充】一般来说,下述有关算法中的precision代表检索出来的条目有多少是准确的,recall则代表所有准确的条目有多少被检索出来。
(1)precision@R算法
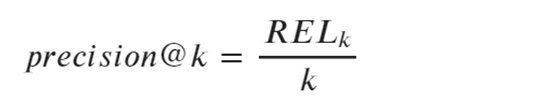
上述公式中,
参数RELk表示:top-k个结果中相关样本的数目;
参数k表示:需要考虑的顶部位置的固定样本数目。
优点:可以显示top-k中相关样本所占的百分比值。
- 对给定查询的相关样本数量非常敏感,这就导致无法对搜索质量进行客观评估,因为不同查询的相关样本数量不同。
- 只有当所有查询中的相关样本数量大于或者等于k时,才能达到值1。
(2)R-precision(精确率)算法
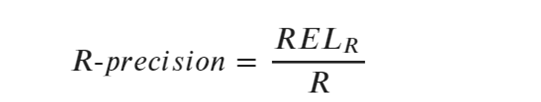
上述公式中,参数RELR表示:top-R个结果中相关样本的数目;
参数R表示:给定查询中所有相关样本项的数目。
与算法precision@k相同,参数k也被设置为相关查询样本的数目。
优点:不像precision@k中数字k的那样敏感,度量变得稳定。
缺点:必须事先知道与请求相关的样本的总数目(如果不把所有相关的数字都先标记出来,可能导致问题)。
(3)Recall@k(召回率)算法
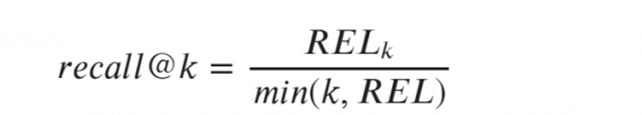
上述公式中,参数RELk表示:top-k个结果中相关样本的数目;
参数k表示:需要考虑的顶部位置中样本的固定数目;
参数REL表示:给定查询中所有相关样本项的数目。
这个算法能够显示top-k中发现的相关样本项的比例。
- 回答了在top-k中原则上是否相关的问题
- 稳定且平均超过请求
(4)mAP (均值平均精确率)算法
本算法能够显示出搜索结果顶部相关样本的密度。你可以将其视为搜索引擎用户收到的信息量,此时搜索引擎读取的页面数最少。因此,信息量与读取的页数之比越大,度量就越高。
- 对搜索质量进行客观稳定的评估
- 精确召回曲线的一位数表示,其本身携带有丰富的分析信息
- 必须知道与请求相关的总样本数量(如果不先把所有相关的样本都标记出来可能有问题)
【提示】可从https://nlp.stanford.edu/IR-book/html/htmledition/evaluation-of-ranked-retrieval-results-1.html一文了解到更多关于mAP算法输出的信息。
(4)nDCG(归一化累积增益)算法
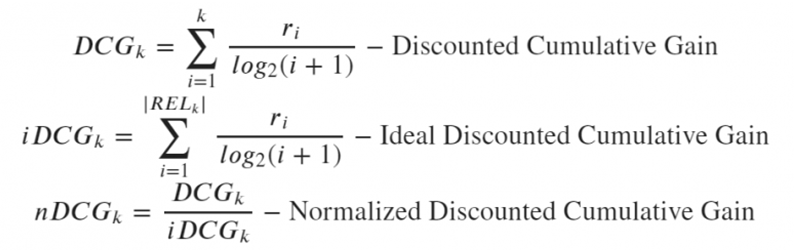
上述公式中,
参数RELk表示:位置k之前的相关样本项列表(按相关性排序);参数ri表示:
检索结果中第i项的四舍五入真值相关性得分。
这个度量算法显示了top-k中的元素在它们之间排序的正确程度。由于这是上面这些方法中唯一考虑元素顺序的度量算法,我们就不详述它的优缺点了。不过,有研究表明,当需要考虑顺序时,该度量算法相当稳定并且在大多数情况下适用。
2、算法整体估计
(1)宏观方面:为每个请求计算一个度量,并且对所有请求计算平均值。
- 优点:与此查询相关的不同数量的数据没有显著波动。
- 缺点:所有查询都被认为等同,尽管有些查询比其他查询相关性更强。
(2)微观方面:在所有查询中,标记相关和单独成功找到相关的数量进行求和,然后都参与到相应度量的计算中。
- 优点:对查询进行评估时,会考虑与每个查询相关的标记数量。
- 缺点:如果某个请求中有很多标记的相关度量,并且系统没有成功或者成功地将它们带到顶部,那么度量的计算结果可能变得非常低或者非常高。
3、系统验证
建议读者对本文算法采取以下两种验证方案:
(1)基于一组查询和选定的相关查询进行验证
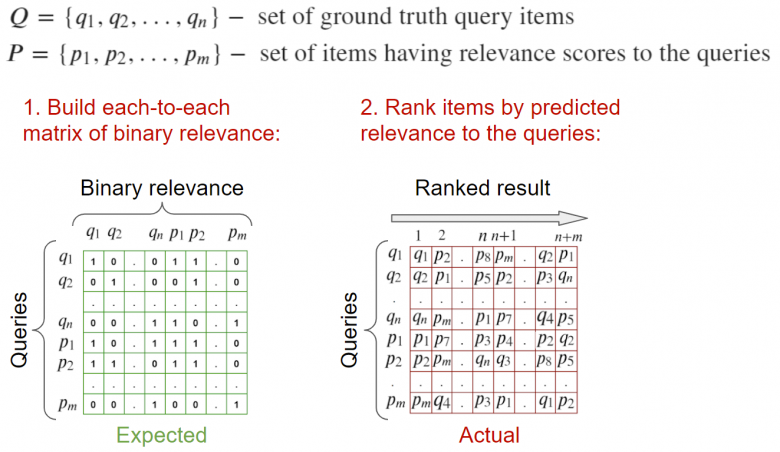
输入:图像请求和与之相关的图像,并且存在与此查询相关的列表形式的标记。为了计算度量,可以计算每个元素的相关性矩阵,并根据元素相关性的二进制信息来进行计算。
(2)全基验证
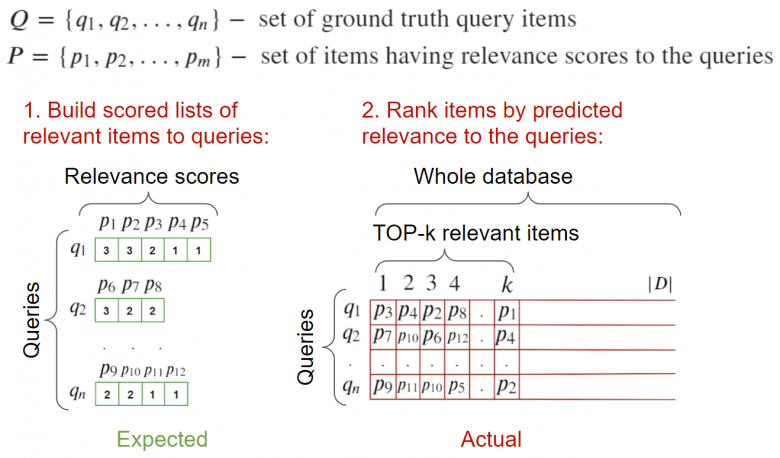
此算法的输入部分包括:图像请求以及与之相关的图像,还应有一个图像验证数据库——理想情况下,所有相关的查询都会在其中进行标记。此外,该数据库中不应该包含查询图像;否则,将不得不在搜索阶段清理该类图像,以便它们不会阻塞于top-1层上。此外还提供了一组负例作为验证基——我们的任务是找出与之相关的东西。
为了计算度量,你可以遍历所有请求,计算到所有元素(包括相关元素)的距离,然后将它们发送到度量计算函数。
已完成项目示例

在某家公司应不应该使用另一家品牌图案元素的问题上,公司间经常出现纠纷。在这种情况下,实力较弱的制造商试图寄生于一家成功的大品牌,用类似符号展示自家产品和服务。但是,消费者也会因此受到影响——你可能想从你信任的制造商那里购买奶酪,但却没有仔细阅读标签,于是错误地从假冒的制造商那里购买了伪劣产品。最近有个案例是苹果公司试图阻止Prepear公司的标志商标使用(https://www.pcmag.com/news/apple-is-attempting-to-block-a-pear-logo-trademark)。
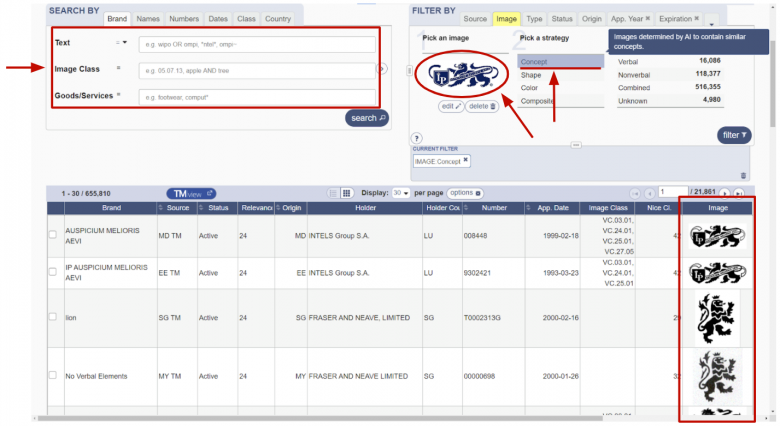
于是,有一些专业政府组织或私人公司来打击非法移植。他们持有注册商标的登记簿,通过该登记簿可以对即将引入的商标进行比对,最终决定批准还是拒绝商标注册申请。以上是使用WIPO(https://www3.wipo.int/branddb/en/)系统接口的一个典型示例,在这样的系统中,搜索相似的图像功能将为其提供极大便利,帮助有关专家更快地搜索到类似图像。
1、系统应用举例
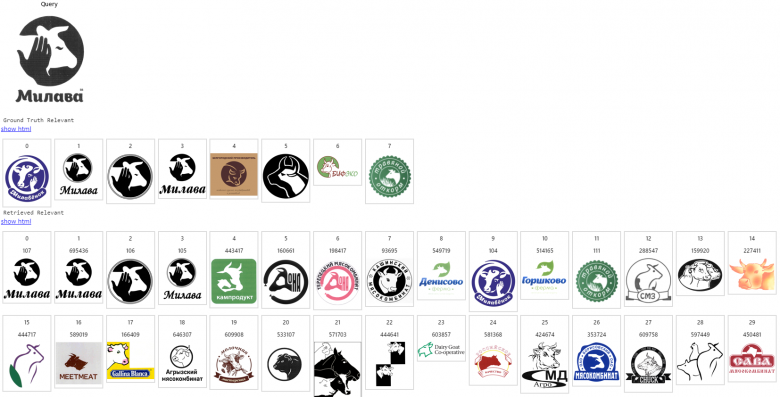
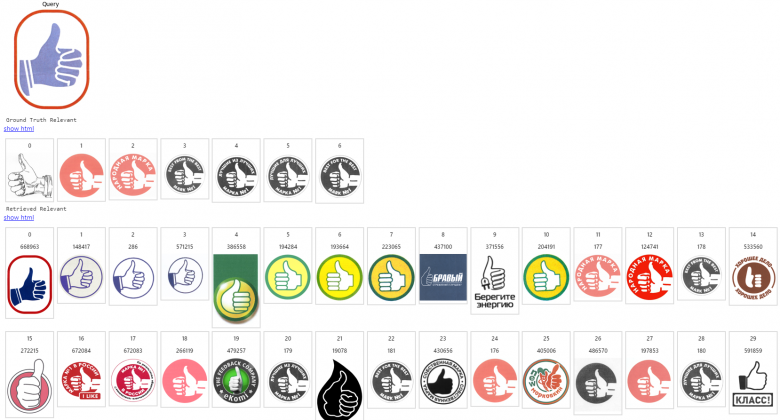
在我们开发的系统中,经索引的图像数据库中拥有数百万个商标。下面给出的第一张图片是一个查询结果展示,下一行(第二张图片)给出一个预期的相关图片列表,后面其余几行中的图片则是搜索引擎按照相关性降低的顺序给出的搜索结果。



朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。早期专注各种微软技术(编著成ASP.NET AJX、Cocos 2d-X相关三本技术图书),近十多年投身于开源世界(熟悉流行全栈Web开发技术),了解基于OneNet/AliOS+Arduino/ESP32/树莓派等物联网开发技术与 Scala+Hadoop+Spark+Flink等大数据开发技术。
原文链接:https://hackernoon.com/how-to-build-an-image-search-engine-to-find-similar-images

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK