

使用缓存(Cache)的几种方式,回顾一下
source link: https://www.51cto.com/article/705369.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

缓存的作用其实很明确,如下两方面:
- 提升数据的获取速度
通常用在获取数据速度要求比较高的场景,比如一些和设备通信的软件,对时间的要求比较高,如果每次都从数据库读数据会导致消耗多余的时间。
- 减轻后台应用或数据库服务器的负载
对于高并发场景的系统,如果每次请求都打到数据库,数据库服务器负载会变大,到达一定瓶颈之后可能让系统体验变差或不可用。
1. 浏览器缓存
1.1 简述
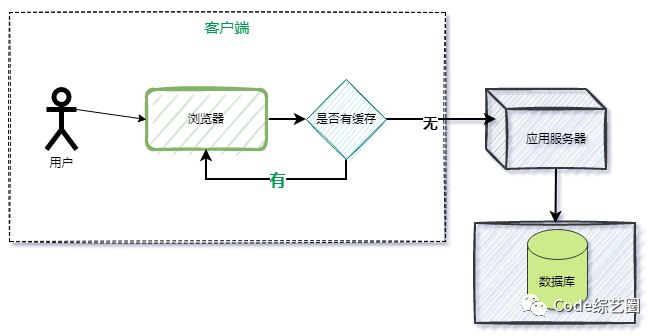
通过控制响应头信息,告诉浏览器让其将对应的数据缓存到本地,在指定时间范围内,可直接从本地缓存中取即可,但浏览器方可以不选择走缓存。
1.2 案例演示
本文中还是使用WebAPI项目进行演示,只是通过不同的API来区分不同案例。
创建好项目中,在默认的WeatherForecastController中添加一个Action方法,如下:
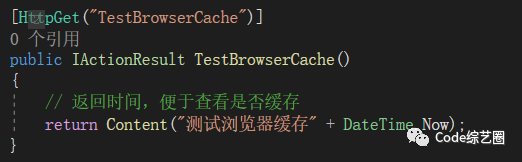
这个时候还没有做缓存处理,所以只要访问都会调用接口获取最新的数据。
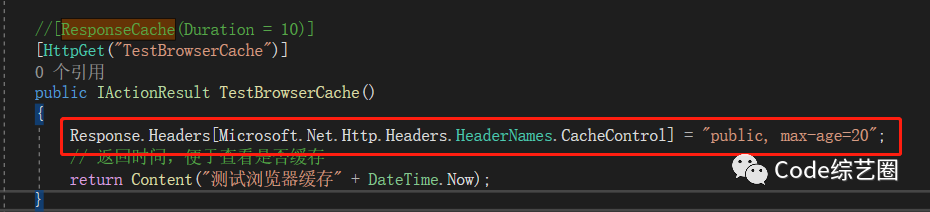
在接口方法上只需添加ResponseCache特性就可以实现浏览器缓存,如下:
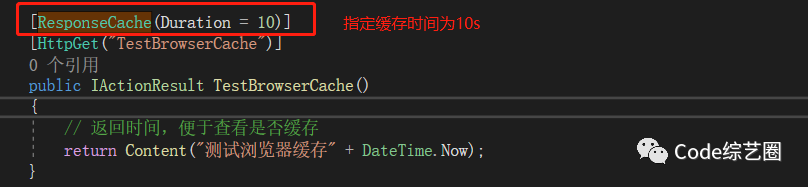
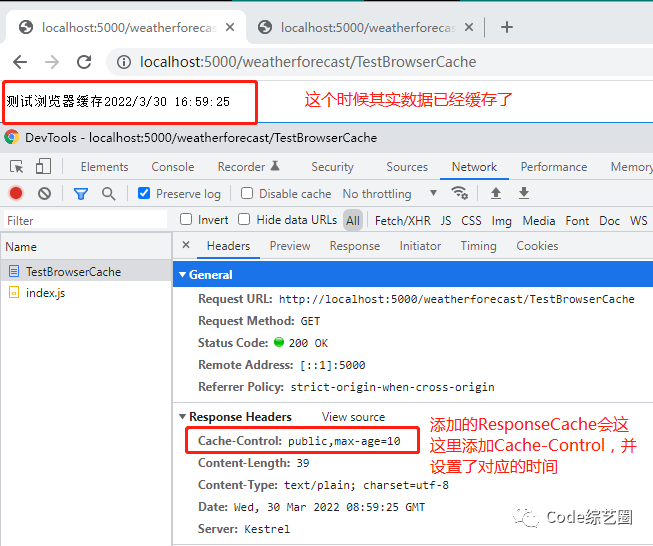
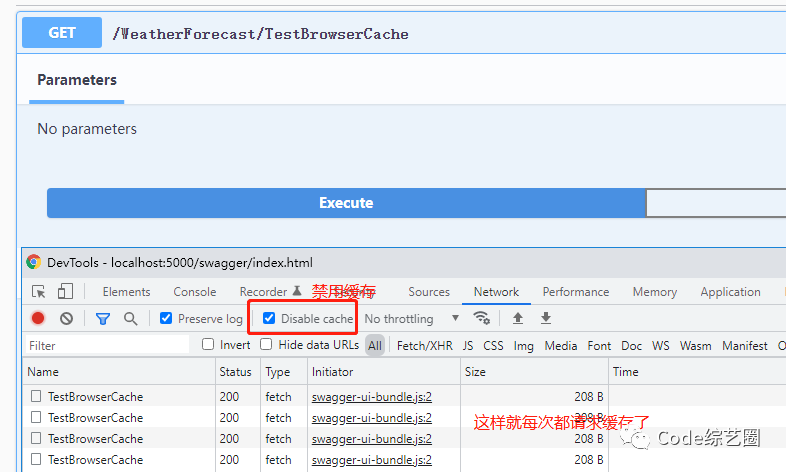
这样就可以实现客户端缓存了,可能会有小伙伴会点击浏览器的刷新和F5进行测试,这个时候并没有看到缓存效果,其实这个时候浏览器是以新的请求发出的,并不会去缓存里取,但其实请求获取到的数据已经存缓存了。
那怎么去测试呢?每次都 打开多个浏览器标签或用Swagger的形式,如下:
第一次访问:
每次都打开新标签,再访问接口:
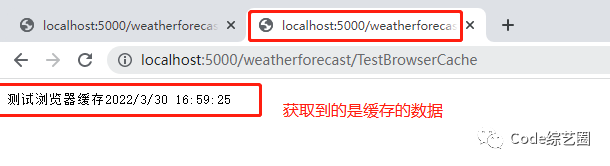
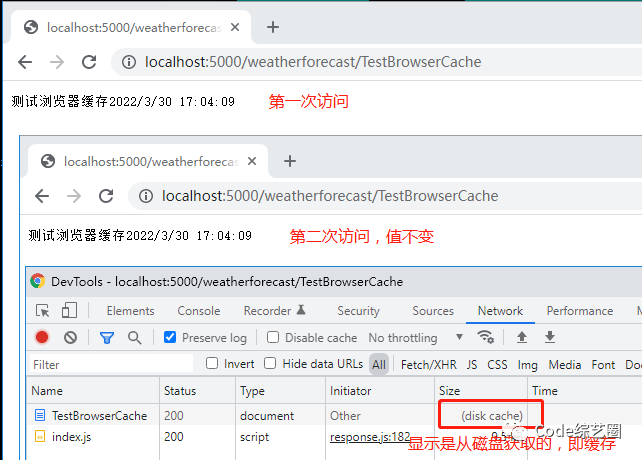
除了根据数据没变来判定是缓存数据外,还可以通过请求确定是否从本地缓存中取数据,如下:
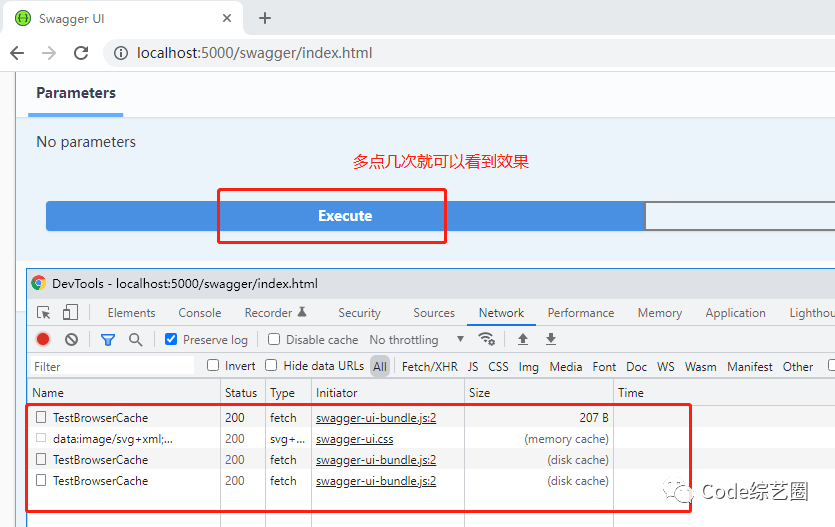
Swagger演示,关于如何集成Swagger,之前有专门分享过(跟我一起学.NetCore之Swagger让前后端不再烦恼及界面自定义):
浏览器缓存的原理其实就是在响应头中增加Cache-Control(ResponseCache的方式是通过Action过滤器的形式设置的响应头),告诉浏览器进行数据缓存,在指定时间范围内可以从缓存中取,我们也可以自己手动设置响应头信息来达到同样的效果,如下:
尽管数据已经缓存,浏览器也可以选择不从缓存取,如下:
2. 服务器缓存
2.1 简述
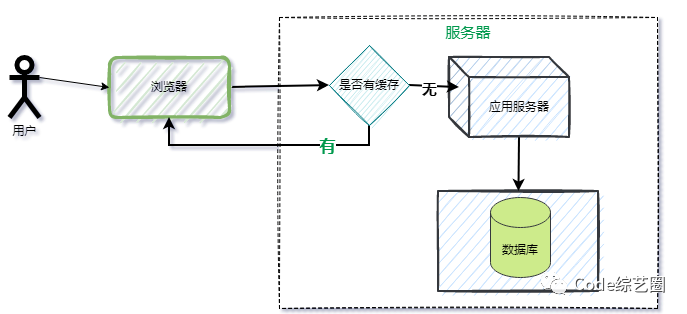
浏览器缓存只是将数据保存在单台电脑的不同位置,如果打开不同的浏览器或不同的电脑访问时,还是起不到缓存的效果,所以搞个服务器缓存肯定是个不错的选择。
即将数据缓存到站点服务器中,当请求过来时,如果命中缓存,直接获取返回即可,不调用对应的后台API。
2.2 案例
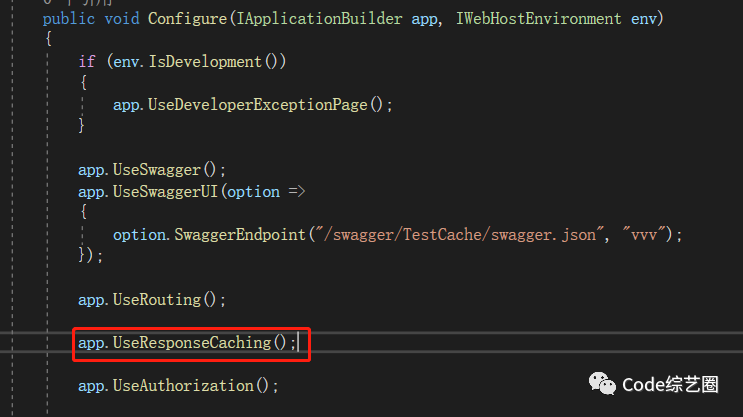
其实这只是在原来浏览器缓存的基础上增加了一个中间件的处理,如下:
代码如下:
运行效果:
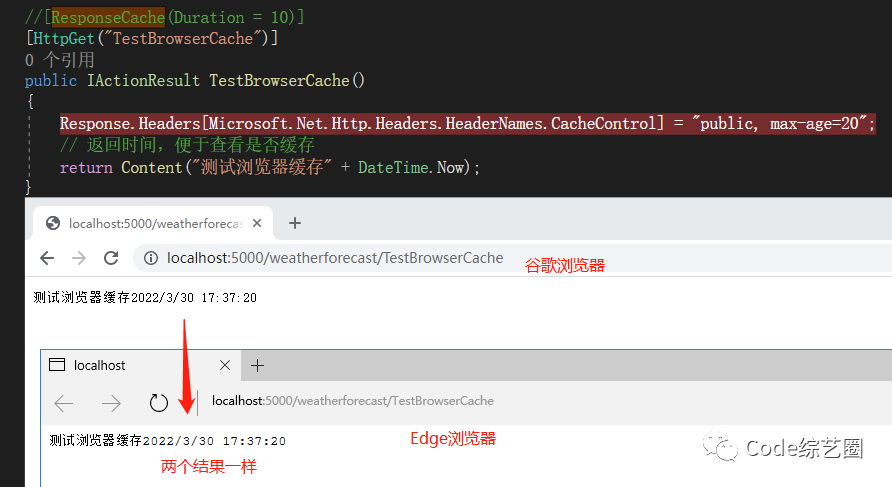
由于不同的浏览器保存的数据位置不一样,如果仅仅是本地缓存,那么两个浏览器的数据会返回不一样;另外第一个浏览器访问之后,其他浏览器在时间范围内获得结果是一样的,也不会调用后台接口。
这种服务器端的缓存在有些情况是不生效的,如:请求Method不是Get或Head的不缓存,返回状态码不是200的不缓存,请求头包含Authorization的不缓存等,所以基本很少用这种方式进行缓存操作。
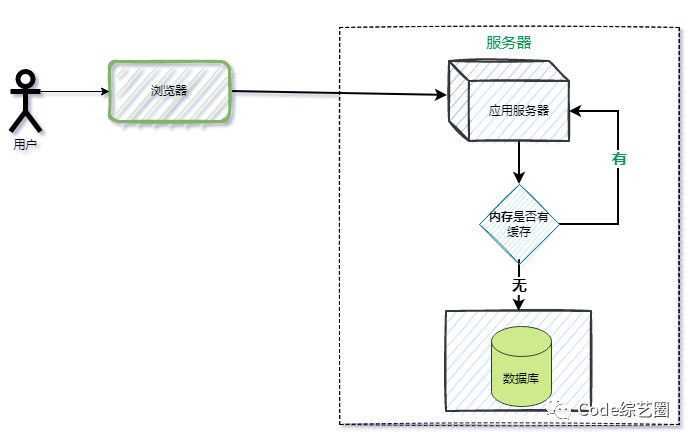
3. 应用内存缓存
3.1 简述
对于上面说到的浏览器缓存和服务器缓存,如果是友好的用户访问,没问题,能起到一定的效果;但如果有人要使坏,不设置对应的请求头访问API(禁用缓存),最终还是会给应用服务器和数据库服务器带来压力。所以需要一种能主动控制的缓存方式,后端程序就是下手的对象,在后端程序中写缓存逻辑,这样缓存策略就由我们自己控制了。
虽然每次请求都会进入应用程序,但会先从缓存中进行获取数据,如果命中缓存,就不再进行数据库访问,直接将缓存数据返回。
3.2 案例
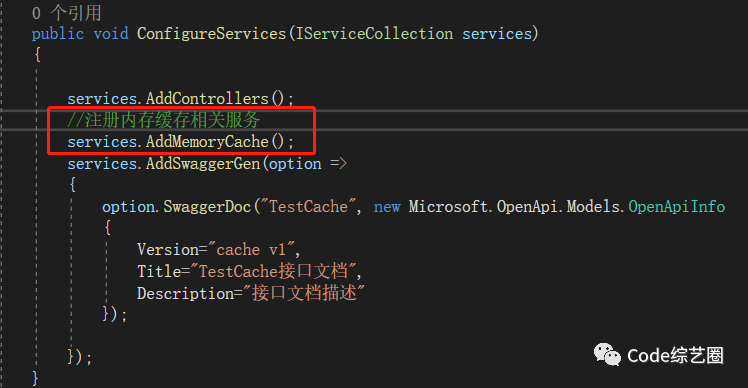
其实框架中针对内存缓存这块已经做好了封装,只需注册相关的服务就可以用了,如下:
注册完成之后,只需要注入就可以使用了,这里增加一个Action方法进行演示:
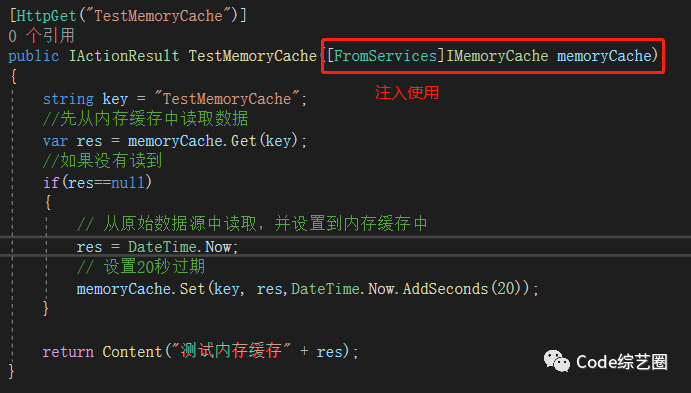
效果就不截图了,在20秒内,单程序部署情况下,不管怎么访问都会是一样的结果。
4. 分布式缓存
4.1 简述
内存缓存虽然能解决浏览器和服务器缓存的缺点,但只对单体部署程序比较适用,对于需要分布式部署的程序来说,程序内存之间的缓存数据不能共享,缓存的效果肯定就没那么尽人意,所以分布式缓存就出来了,采用对应的中间件,如Memcache、Redis等,而Redis成为了缓存的首选。
请求的逻辑和内存缓存差不多一样,只是分布式缓存会采用第三方中间件进行数据存储,保证分布式部署的程序共用一套缓存。
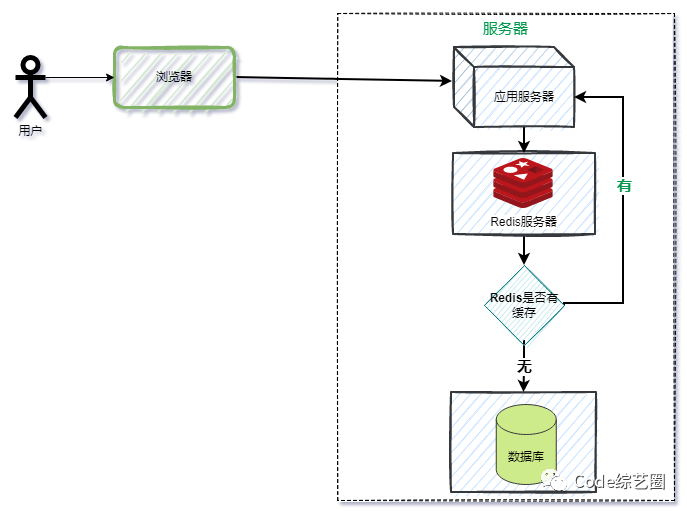
4.2 案例
这里还是用最火的Redis做演示,所以需要提前安装Redis。
框架也提供了统一操作分布式缓存的接口IDistributedCache,用法和上面的内存缓存基本一样。
这里用的是Redis,所以需要安装对应的Nuget包Microsoft.Extensions.Caching.StackExchangeRed,然后注册相关服务就可以用了,如下:
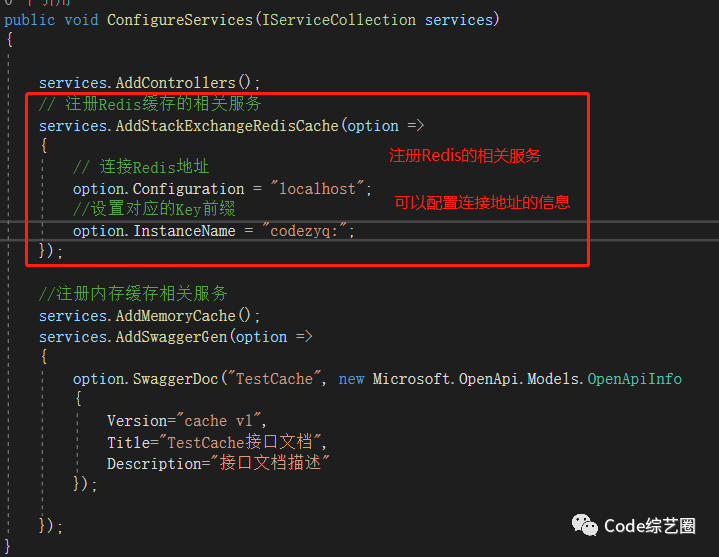
注册完成之后,只需要注入就可以使用了,这里也增加一个Action方法进行演示:
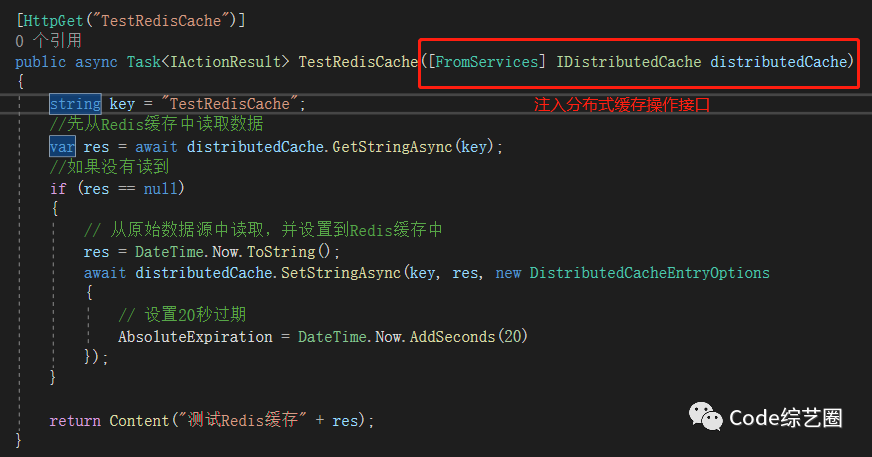
访问对应的接口,在设置的时间范围内从Redis中读取到的数据一致,过期之后就会清空,程序又会设置新的值,如下:
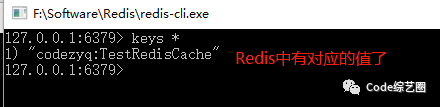
关于缓存的几种用法就先暂时说这么多,也有小伙伴根据业务场景自己实现的。
实例的源码:https://gitee.com/CodeZoe/dot-net-core-study-demo/tree/main/CacheDemo
缓存之所以现在这么火,其主要目的还是提升数据访问效率,缓解应用和数据库的压力,但同时也会带来一些问题,比如缓存穿透、缓存击穿、缓存雪崩及缓存数据与数据库不一致等问题,后续我们会逐个说说。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK