

以太坊合并:运行主导性客户端?风险自担
source link: https://www.jinse.com/blockchain/1185835.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

以太坊合并:运行主导性客户端?风险自担
特别感谢 Vitalik Buterin, Hsiao-Wei Wang 和 Caspar Schwarz-Schilling 的反馈和评论。
摘要:出于安全性和可活性的考虑,以太坊选择了多客户端架构。为了鼓励质押者 (Stakers) 客户端设置的多样化,以太坊协议针对关联性故障 (correlated failures) 的惩罚是更高的。因此,对于运行一个市场份额占少数的客户端的质押者而言,如果该客户端出现 bug,那么该质押者通常只会损失适度的金额,而如果该质押者运行一个市场份额占主导性地位的客户端,那么在该客户端遭遇 bug 时该质押者将可能遭遇损失全部的质押金。因此,负责任的质押者应该审视当下的客户端分布格局,并选择运行一个不那么流行的客户端。
为何我们需要多个客户端?
有许多论点认为,单一客户端架构更加可取。开发多个客户端会带来巨大的开销,这就是为什么我们还没有看到任何其他区块链网络认真地追求提供多客户端的原因所在。
那么,为什么以太坊的目标是多客户端架构呢?客户端是非常复杂的代码,可能包含 bugs。其中最糟糕的是所谓的“共识 bugs”,即区块链核心状态转换逻辑 bugs。一个经常被引用的例子就是所谓的“无限货币供应” bug,出现这种 bug 的客户端将接受 (认可) 一笔铸造任意数量的 ETH 的交易。如果某人在某个客户端中发现了这种 bug,而且在此人抵达安全出口 (即通过混合器或交易所来使用这笔资金) 之前未被阻止,那么这将导致 ETH 的价值大幅缩水。
如果每个人都运行相同的客户端,停止这情况将需要人工干预,因为在这种情况下,区块链、所有智能合约和交易所将照常运行。攻击者甚至可能仅需要几分钟时间就能成功地发起一场攻击,并充分地将资金分散,使得只回滚该攻击者的交易变得无法实现。根据被铸造的 ETH 数量,以太坊社区将很可能协调将以太坊回滚至此次攻击发生之前的状态(这需要在确定和修复该 bug 之后进行)。
现在让我们看看当我们有多个客户端时会发生什么。有两种可能的情况:
包含该 bug 的客户端承载着少于 50% 的网络总质押金。该客户端将生产出一个这样的区块,该区块中包含了一笔利用该 bug 来铸造 ETH 的交易。让我们称这条链为 A 链。
然而,绝大多数运行另一个不存在该 bug 的客户端的质押者将忽略该区块,因为该区块是无效的 (对于该客户端而言,这笔铸造 ETH 的操作就是无效的)。因此,运行该客户端的质押者 (验证者) 将构建另一条链,我们称之为 B 链,这条链不包含这个无效的区块。
由于正确的客户端占主导地位,B 链将累积更多的证明 (attestations)。因此,即便那个有共识 bug 的客户端也会投票给 B 链;其结果是,B 链将会累积 100% 的投票,而 A 链将会消亡。区块链将继续前进,就好像该 bug 从未发生一样。
绝大多数质押者使用了这个有 bug 的客户端。在这种情况下,A 链将累积绝大多数投票。但由于 B 链仅拥有不到 50% 的证明,因此那个有 bug 的客户端永远也不会有理由从 A 链切换至 B 链。因此,我们将看到区块链分裂。如下图所示:
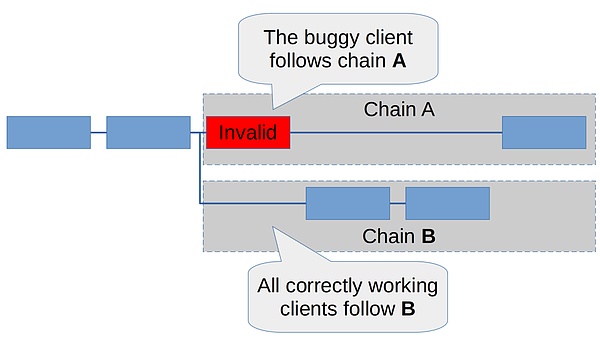
上述第一种情况是理想的情况。这种情况很可能会产生一个孤块 (orphaned block),大多数用户不会注意到该孤块。开发者可以调试客户端,修复该 bug,一切都很好。第二种情况显然并不理想,但相比于总共只有一个客户端 (即单一客户端架构) 而言,这仍然是一个更好的结果,大多数人将很快发现有了一条分叉链 (你可以通过运行几个客户端来自动监测到),交易所将很快暂停存款,DeFi 用户在链分裂被解决之前也可以谨慎行事。基本上来说,与单一客户端架构相比,这仍然给了我们一个大的闪烁的红灯警告,允许保护我们免受最坏的结果。
上述第二种情况中,如果这个有 bug 的客户端是由超过 2/3 的质押者运行,那么这种情况将更糟糕,因为该客户端将会敲定那条无效的链 (即 A 链)。对此我们将在下文更多地阐述。
有些人认为链分裂是如此灾难性,以至于这本身就是作为支持单一客户端架构的论据。但是请注意,链分裂只是由于客户端中的一个 bug 而发生的。就单一客户端架构而言,如果你想要修复这个 bug 并将区块链返回至之前的状态,那么你必须回滚至该 bug 发生之前的区块,而这与链分裂一样糟糕!所以,就多客户端架构而言,尽管链分裂听起来很糟糕,但在客户端出现严重 bug 的情况下,链分裂实际上是一个特性,而不是一个 bug。至少你能知道发生了严重的问题。
激励客户端多样性:反相关性惩罚
如果验证者的质押金被分配到多个客户端上,这显然对网络有利,最好的情况是每个客户端持有的质押金少于总质押金的 1/3。这将使得网络在面临任何单个客户端 bug 时都具有弹性。但质押者为什么要在意这一点呢?如果网络对于质押者没有任何激励机制,那么他们不太可能愿意承担切换至另一个少数派客户端产生的成本。
不幸的是,我们不能直接基于验证者选择运行哪个客户端来对其进行奖励。没有一种客观的方法来衡量这一点。
然而,当你运行的客户端发生了 bug 时,你不能幸免。这正是反相关性惩罚 (anti-correlation penalties) 起作用的地方:其中的理念是,如果你运行的验证者进行了恶意行为,那么你将受到的惩罚将会因为有更多其他验证者在大约同一时间犯了错误而变得更高。换句话说,你会因为关联性故障而受到惩罚。
在以太坊中,你 (验证者) 会因为两种行为而被罚没 (get slashed):
在同一个区块高度签名两个区块。
创建可被罚没的证明 (环绕投票或双重投票)。
当你 (验证者) 被罚没时,通常不会损失所有的资金。在撰写本文时 (信标链 Altair 分叉),默认的惩罚实际上是非常小的:你只会损失 0.5 ETH,也即大约是你质押的 32 ETH 的 1.5% (最终这会增加到 1 ETH,也即 3%)。
然而,这里有一个问题:有一个额外的惩罚,取决于你的验证者被罚没之前和之后的 4096 个 epochs (大约 18 天) 时间内的所有其他罚没事件。在此期间,你将受到与这些罚没总额成比例的罚没。这可能比最初的惩罚要大得多。目前 (信标链 Altair 分叉) 是这样设置的,如果在此期间 (你被罚没之前和之后的 18 天内) 有超过 50% 的全部质押金额被罚没了,那么你将损失你的全部资金。最终,这将被设置为如果 1/3 的质押者被罚没,那么你将损失你的所有质押金。之所以设置为 1/3,是因为这是导致一次共识失败的最少质押金数额。如下图所示:
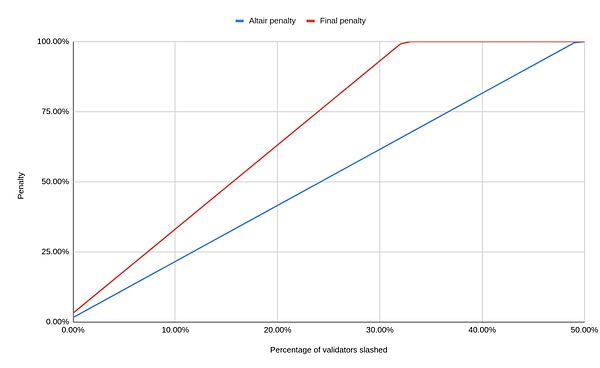
上图:蓝线表示当前 (信标链 Altair 升级之后) 的惩罚;红线表示最终将设置的惩罚。
另一个反相关性惩罚:Quadratic Inactivity Leak
验证者失效的另一种方式是离线。验证者离线也是会受到惩罚,但此机制非常不同。我们不将这种惩罚称为“罚没”(slashing),而且这种离线的惩罚通常是很轻微的:在正常操作下,离线的验证者会受到的惩罚金额,与他们在这段时间通过正确地验证本来可以获得的奖励相当。在撰写本文时,验证者的年收益率是 4.8%。如果你的验证者离线了几小时或几天 (例如由于暂时的互联网中断而离线),那么可能没什么可紧张的。
但是,如果当超过 1/3 的验证者离线时,情况将变得完全不同。此时,信标链将无法敲定区块,这威胁到了共识协议的一个基本属性,即活性 (liveness)。在这样的场景中,要恢复信标链的活性,就要使用所谓的“quadratic inactivity leak”机制。如果验证者在区块链停止敲定的同时还在继续离线,那么该验证者将受到的惩罚将随着时间呈二次方增长。最初这种惩罚是非常低的;在大约 4.5 天之后,离线的验证者将损失 1% 的质押金。然而,在大约 10 天之后,将损失 5% 的质押金,大约 21 天之后将损失 20% 的质押金 (这些是当前信标链 Altair 设置的值,这些值将在未来翻倍)。如下图所示:
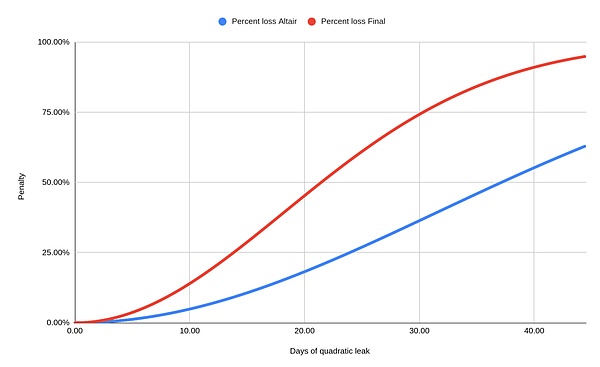
这种机制的设计是为了在发生一场灾难性事件导致大量验证者离线的情况下,使得区块链能够尽快恢复敲定区块。当离线的验证者损失越来越多他们的质押金时,他们将逐渐被踢出网络,从而在验证者总数中所占的份额越来越小,当这些离线的验证者质押金减少至小于网络总质押金的 1/3 时,剩余的在线验证者将重新占据区块链共识所需的 2/3 多数,从而允许他们敲定区块链。
然而,还有一种情况与此相关:在某些情况下,验证者无法再对有效链进行投票,因为他们不小心将自己锁在了一条无效链中。我们在下文中将对此进一步解释。
运行一个主导性客户端有多糟糕?
为了理解其中的危险之处,让我们来看一下三种类型的故障事件:
大规模罚没事件:由于某个 bug,运行主导性客户端 (即大多数验证者都选择使用的客户端) 的验证者将对可罚没事件进行签名。
大规模离线事件:由于某个 bug,运行主导性客户端的所有验证者都离线。
无效区块事件:由于某个 bug,运行主导性客户端的所有验证者都对一个无效区块进行证明。
还有其他类型的大规模故障和罚没可能会发生,但我将自己限制在这些与客户端 bug 相关的事件上 (这些是你在选择运行哪个客户端时应该考虑的问题)。
场景 1:双重签名
这可能是大多数验证者运营商最担心的情况:一个 bug 导致验证者客户端对可罚没事件进行了 签名。其中一个例子是两个证明 (attestations) 对同一个目标 epoch 进行投票,但使用了不同的有效负载 (这就是所谓的“双重签名”(Double Signing))。由于这是一个客户端 bug,因此不仅仅只有一个质押者需要担心,所有运行了这个特定客户端的质押者都需要担心了。当这种行为被发现时,罚没将会演变成一场血洗:所有相关的质押者都将损失 100% 的质押金。这是因为,我们此处考虑的是这些质押者运行的是一个主导性客户端 (即大多数质押者都选择使用的客户端);而如果相关的客户端承载的质押金只占网络总质押金的 10% (即该客户端并非主导性客户端),那么“只有“大约 20% 的相关质押金会被罚没 (这是信标链 Altair 升级以来的罚没力度;当最终的惩罚参数生效时,这个比例将会增加至 30%。)
这种情况所带来的损失显然是极端的,但我也认为这是极不可能的。满足成为可被罚没的证明的条件很简单,这就是为什么要构建验证者客户端 (validator clients, VCs) 来强制执行它们。验证者客户端是一个小型的、经过良好审计的软件,这种规模级别的漏洞是不太可能出现的。
到目前为止,我们已经看到了一些罚没情况,但据我所知,它们都是由于运营者操作不当造成的——几乎所有这些都是由于运营者在多个地点运行同一个验证者造成的。由于这些是非相关行为,罚没的数额很小。
场景 2:大规模离线事件
对于这个场景,我们假设主导性客户端存在一个 bug,当这个 bug 被触发时,会导致该客户端崩溃。一个非法区块已经被整合到区块链中,每当这个主导性客户端遇上该区块时,该客户端就会离线,使其无法参与任何进一步的共识。由于该主导性客户端现在离线了,此时 Inactivity Leaks 惩罚机制就启动了。
客户端开发者将争先恐后地让一切恢复正常。实际上,在几个小时内,最多几天内,他们将发布一个 bug 修复来消除该崩溃。在此期间,质押者也可以选择简单地切换至另一个客户端。只要有足够的质押者切换至另一个客户端,使得有超过 2/3 的验证者在线,那么这个 quadratic inactivity leak 惩罚机制就会停止。在修复这个有 bug 的客户端之前,这种情况并非不可能发生。
这种场景并非不可能发生 (导致客户端崩溃的 bugs 是最常见的 bug 类型),但由此导致被惩罚的总金额可能不到受影响的质押金的 1%。
场景 3:无效区块
对于这种场景,我们考虑这样一种情况,即主导性客户端存在一个 bug,该 bug 导致客户端生产了一个无效区块,并且接受该区块为有效区块——也即是说,当使用这个主导性客户端的验证者看到了这个无效区块时,他们将视其为有效区块,并证明 (投票给) 该区块。
我们将这条包含了这个无效区块的链称为 A 链。一旦这个无效区块被生产了,会发生两件事情:
所有其他正常运行的客户端将会忽视这个无效区块,并在最近的有效区块头之上构建一条单独的区块链,我们称之为 B 链。所有正常运行的客户端将投票给 B 链并继续构建这条链。如下图所示。
这个有 bug 的主导性客户端将会把 A 链和 B 链都视为有效链。因此,该客户端会投票给当下它认为是最“重”的任何一条链。
我们需要区分三种情况:
这个有 bug 的主导性客户端承载了少于 1/2 的总质押金。这种情况下,所有其他正常运行的客户端将会投票给 B 链并继续构建 B 链,最终使 B 链成为最重的那条链。此时,即便是这个有 bug 的客户端也将会切换至 B 链。除了会生产一个或几个孤块之外,没有什么糟糕的事情会发生。这是一个令人高兴的情况,也是为什么网络中有着主导性客户端之外的其他客户端是非常重要的。
这个有 bug 的主导性客户端承载了超过 1/2 但少于 2/3 的总质押金。这种情况下,我们将看到有两条链被构建—— A 链由这个有 bug 的客户端构建,B 链由其他客户端构建。这两条链都不具有 2/3 验证者的绝对优势,因此这两条链都无法敲定区块。当这种情况发生时,开发者们将争相理解为什么会有两条链。当他们发现 A 链中有一个无效区块时,他们可以继续修复有 bug 的主导性客户端。一旦 bug 修复完成,该客户端将把 A 链视为无效链,并开始构建 B 链,从而运行 B 链能够实现区块敲定。对于用户而言,这种区块是非常具有破坏性的。虽然弄清楚哪条链是有效链所需的这个时间预计是短暂的 (可能不到 1 小时),但区块链很可能在几个小时内 (甚至一天时间) 都无法敲定区块。但对于质押者来说,即便是那些在运行这个有 bug 的主导性客户端的质押者而言,他们受到的惩罚依然相对较小:他们会因为构建无效的 A 链而不是参与 B 链的共识而受到“inactivity leak”惩罚,但由于这持续的时间很可能不到一天时间,因此相应的惩罚可能不到 1% 的质押金。
这个有 bug 的主导性客户端承载了超过 2/3 的质押金。在这种情况下,这个有 bug 的主导性客户端将不仅仅会构建 A 链,实际上还会有足够的质押金来“敲定”A 链。需要注意的是,该客户端是唯一认为 A 链已被敲定的客户端,而所有其他正常运行的客户端则将 A 链视为无效链。但是,由于 Casper FFG 协议的运作方式,当一名验证者敲定了 A 链时,该验证者将无法再在不被罚没的情况下参与到另一条与 A 链相冲突的链中,除非这条链能够被敲定。因此,一旦 A 链已经被敲定,那么运行这个有 bug 的客户端的验证者就陷入了一个可怕的困境:他们已经投票给了 A 链,但 A 链是无效链;他们也无法构建 B 链,因为 B 链当下还无法实现敲定。甚至是对他们的客户端进行 bug 修复也无法帮助他们,因为他们已经发送了违规投票。当前将发生的情况是非常痛苦的:无法敲定区块的 B 链将启动 Inactivity Leak 惩罚机制,在接下来几周内,A 链上的验证者将损失他们的质押金,直到有足够多的质押金被销毁了,从而使得 B 链恢复敲定。假设 A 链上的质押者们一开始拥有网络中 70% 的质押金,那么他们将至少损失 79% 的质押金,因为这是他们的质押金数量要减少至代表网络中少于 1/3 的质押金所必须损失的数量。此时,B 链将恢复敲定,所有质押金都可以切换至 B 链。区块链将再次恢复健康状态,但在此之前的这种破坏性将持续数周,数百万 ETH 在此过程中被销毁。
显然,上述第三种情况就是一场灾难。这就是为什么我们非常希望不要让任何一个客户端拥有超过 2/3 总质押金。这样无效区块就永远不会被敲定,这种灾难就永远不会发生。
风险分析
那么我们应如何评估这些情况呢?一个典型的风险分析策略是评估事件发生的可能性 (我们使用数字 1 代表极不可能,数字 5 代表相当可能) 以及影响 (数字 1 代表非常低,数字 5 代表灾难性)。最重要的风险是那些在这两个指标上得分较高的风险,由影响和可能性的乘积表示。
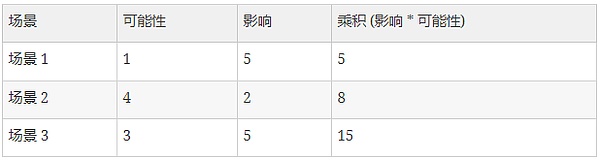
基于上表,到目前为止风险最高的是场景 3。当一个客户端拥有 2/3 质押金的绝对多数时,这是相当灾难性的情况,这也是一个相对可能出现的情况。为了强调这样的 bug 是多么容易发生,最近在 Kiln 测试网发生了一个类似的 bug:在这个案例中,Prysm 客户端确实在提出一个区块之后才发现它是错误的,并且并没有证明该区块。假如当时 Prysm 客户端将该区块视为有效区块,并且假如这是发生在以太坊主网 (而不是测试网) 上,那么我们将会面临场景 3 中的第三种情况——因为 Prysm 客户端目前在以太坊主网中拥有 2/3 的绝对多数。因此,如果目前你正在运行 Prysm 客户端,你可能会失去所有的资金,这是一个非常现实的风险,你应该考虑切换客户端。
虽然上述场景 1 可能是人们最担心的情况,但其风险评级相对较低。原因在于,我认为发生场景 1 这种情况的可能性非常低,因为我认为验证者客户端软件在所有客户端中都很好地被实现了,不太可能生产出可被罚没的证明或区块。
如果目前我在运行主导性客户端,并且对于切换客户端顾虑重重,那么我有什么选择呢?
切换客户端可能是一项重大的任务。它也伴随着一些风险。如果罚没数据库没有被正确地迁移至新设置,那会怎样呢?可能会有被罚没的风险,而这完全违背了我们切换客户端的目的。
对于那些担心这种问题的人,我还建议有另一个选择:可以让你的验证者设置保持原样 (无需取出密钥等等),仅仅切换信标节点。这是极低的风险,因为只要验证者客户端按预期工作,它就不会双重签名,因此也就不会被罚没。尤其是如果你运营着大型验证者业务,使得更改验证者客户端 (或远程签名者) 基础设施的成本非常昂贵,并且可能需要审计,那么这可能是一个很好的选择。如果新设置执行起来并没有像预期中的那样好,也能够轻松地切换回原来的客户端,或者可以尝试切换至另一个非主导性客户端。
这样做的好处是,在切换信标节点时,你几乎不用担心:这可能对你造成的最糟糕的事情是暂时离线。这是因为信标节点本身永远无法自己生成可被罚没的消息。如果你运行的是非主导性客户端,你不可能会面临上述场景 3 的情况,因为即便你投票给了一个无效区块,该区块也无法获得足够的投票来被敲定。
那执行客户端呢?
我在上文中撰写的内容适用于共识客户端,包括 Prysm、Lighthouse、Nimbus、Lodestar 和 Teku,截至撰写本文时,Prysm 可能拥有网络上 2/3 的绝对多数。
所有这些都以相同的方式应用于执行客户端。如果 Go-ethereum (此客户端很可能会在合并之后成为占主导性的执行客户端) 生产了一个无效区块,那么该区块可能会被敲定,因此将导致出现上文所述场景 3 的灾难性情况。
幸运的是,我们现在已经有其他 3 个执行客户端处于生产就绪中:Nethermind、Besu 以及 Erigon。如果你是一名质押者,我非常建议你运行这其中一个执行客户端。如果你运行的是一个非主导性客户端,其中的风险是相当低的!但如果你运行的是主导性客户端,那么你面临着损失所有资金的严重风险!
编者注:本译文有所删减,英文原文参见?
https://dankradfeist.de/ethereum/2022/03/24/run-the-majority-client-at-your-own-peril.html#A2-Why-can%E2%80%99t-the-buggy-client-switch-to-chain-B-once-it-has-finalized-chain-A
撰文:Dankrad Feist,以太坊基金会
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK