

让工程师拥有一台“超级”计算机——字节跳动客户端编译加速方案
source link: https://xie.infoq.cn/article/34a0f997d44993e3a5583fcfd
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

我们有一个梦想,让每一名研发工程师拥有一台“超级”计算机。
作者:字节跳动终端技术——孙雄
大型工程的效率瓶颈
近年来,基于 Devops 流水线的研发流程,逐渐成为软件研发的行业标准。流水线的运行效率,决定了团队的研发效能。对大型项目来说,编译构建往往是流水线中耗时占比的大头。有些工程的编译时长超过 30 分钟,甚至达到几个小时。这样的性能,是非常糟糕的。
字节 iOS 大型项目的构建时长,大多控制在 5 分钟以内。这主要得益于内部的编译加速解决方案,它集分布式编译和分布式缓存为一体,本文将详细介绍它的工作原理。不过在这之前,我们先来分析一下大型项目的编译瓶颈和解决思路。
先说结论,机器性能不足和重复作业,是影响工程编译效率的两个最大因素,对此,可以采取分布式编译+编译缓存的方式,提升整体的性能。
分布式编译
工程的编译,往往可以拆解为可并行的编译子任务。以 C 系列语言(C, C++, ObjC)为例,项目中往往存在上千甚至上万的源代码文件(以 .c , .cc 或 .m 作为扩展名的文件),每个编译子任务将源代码文件编译为目标文件(以 .o 作为扩展名的文件),再整体链接成最终的可执行文件。
这些编译子任务可以并行执行,如下图所示:
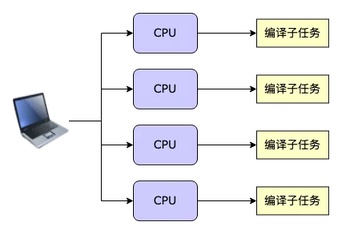
CPU 的数量,决定了编译的并行度上限。个人电脑(PC)的 CPU 核心数通常在 4~12 之间,专用服务器可以达到 24~96,但对于动辄上万文件的大型工程,CPU 的数量还是显得不足。这时候,利用分布式编译的技术,可以得到一台“超级计算机”。
大型工程全量编译,需要处理几千甚至几万个编译子任务。但大多数子任务,之前已经编译过,如果我们能通过某种方式,直接获取编译产物,就可以大大节省时间。
建立一个中央仓库,存储编译子任务的产物,这些产物可以通过“任务摘要”来索引。这样每次遇到一个新任务,我们首先向中央仓库查询摘要,如果查询成功,直接下载编译产物,就省去了重复编译的动作。
上面提到的分布式编译和编译缓存,是提升大型项目编译效率的两大法宝,本文主要介绍字节跳动的分布式编译解决方案。
“超级”计算机
借助云计算,我们可以以组装的方式,得到一台“超级”计算机,如下图所示:
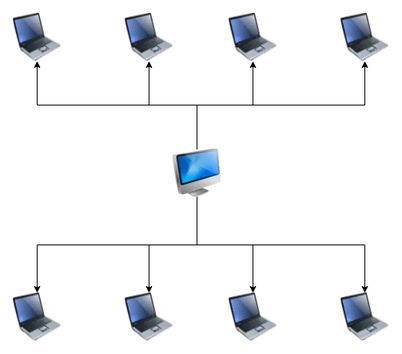
这台“超级”计算机,由一台中心节点和若干台工作节点组成。中心节点负责生成和调度编译子任务,依照它们的执行顺序,将任务发送给空闲的工作节点来执行。这样整个系统的并行处理能力,取决于所有工作节点的 CPU 之和,性能比单机高出数倍,甚至数十倍。
像这样把任务分发给工作节点的方案,又称为分布式编译。分布式编译并不是新鲜的概念,2008 年开源的 distcc 工具就提供了分布式编译的解决方案。Google 在 2017 年提出的 Remote Execution API,又从协议的角度规范了分布式编译和编译缓存的实现方式。
我们先看一下分布式编译的核心思路。
核心思路很简单,本地计算出编译命令需要读的文件,把文件列表和编译命令,发给远端机器,执行编译命令。编译结束后,再请求拉取编译产物。
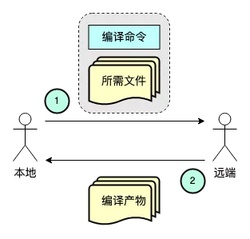
其中,如何找到所需文件是关键。
背景知识——预处理
在介绍我们的做法之前,需要先补充一些编译原理相关的背景知识。
待编译的源文件,可以通过#include xx.h和 #import xx.h的方式,声明对某头文件的依赖。
编译器处理编译命令的第一阶段叫做“预处理”,该阶段的一个重要工作是头文件展开。假设入口文件main.m 中有一行为#import Car.h,编译器会遍历所有搜索路径,找到Car.h文件,并读取该文件内容,替换掉main.m中的#import Car.h行。其中搜索路径由编译命令中的 -I, -isystem 等参数给出
接下来,如果 Car.h 文件中有 #import 语句,编译器会重复上述动作,找到依赖的文件,读取内容,进行替换,直到把所有的 #import 语句全部展开。
因此,假设我们模拟预处理的过程,找到所有依赖的头文件,就可以将该任务发送到远端执行。
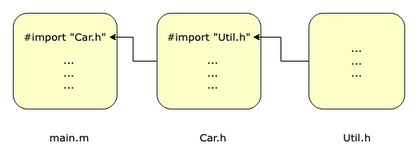
由上述编译原理可知,依赖分析是实现分布式的前提。不仅如此,依赖分析也是性能的决定因素。
由于依赖分析只能在本地进行,计算资源是有限的。依赖分析的性能,决定了任务分发是否流畅,如果依赖分析过慢,会导致大量工作节点限制,任务分发出现瓶颈。
可以把依赖分析,理解为分布式编译的重要引擎。
依赖分析的实现并不复杂,编译器本身就提供了相关参数,以clang为例。-M 可以获取完整的编译依赖,而 -MM 则可以得到用户定义的依赖,相关参数解析如下:
-M,--dependenciesLike -MD, but also implies -E and writes to stdout by default
-MD,--write-dependenciesWrite a depfile containing user and system headers
-MM,--user-dependenciesLike -MMD, but also implies -E and writes to stdout by default
-MMD,--write-user-dependenciesWrite a depfile containing user headers
开源框架recc 直接使用了编译器能力。
这种方法的好处是开发简单,并且足够安全,但性能存在瓶颈。我们早期以头条项目测试的时候,通过编译器获取依赖,平均耗时在 200 毫秒左右。而单个文件的编译时长,大多在 500 毫秒~3000 毫秒的区间内。依赖分析耗时占比太高,导致任务分发效率不够理想。
依赖分析时间过长,一方面由于编译器命令由独立进程执行,不同的编译任务之间无法复用缓存。另一方面,编译器的 -M 参数隐含了参数 -E,后者代表“预处理”,预处理阶段除了依赖分析,还做了不少其它工作,这部分工作我们可以优化掉。
Google 的 goma 采用了自研的依赖分析模块,并且在 Chromium 和 Android 这两个大型项目上取得了非常好的结果。它在实现依赖分析的时候,借助常驻进程的架构优势,运用了大量缓存,索引等技巧,提高了中间数据的复用率。
在使用 goma加速内部 iOS 的项目的过程中,我们发现当编译任务依赖的 Framework 过多,或者依赖的 hmap 文件过大的情况下,性能会受到较大影响,于是,我们针对大型 iOS 项目的特点,在goma基础上进行了优化,最终可以以平均 50ms 的速度,完成编译任务依赖解析。
接下来,让我们一起看看goma在设计时运用了哪些技巧,以及我们针对 iOS 项目做了哪些优化。由于篇幅有限,本文只介绍比较有代表性的部分。
快速依赖分析
goma 采用了依赖缓存和依赖分析结合的方案,如果之前在工作目录下进行过编译,下次使用时,可以直接使用依赖缓存,只有在缓存不命中的情况下,才进行依赖分析。
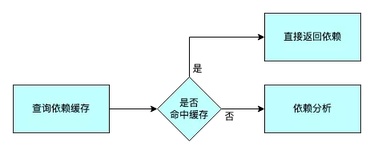
依赖缓存的核心原理是:检查相同编译参数对应的,上一次的依赖,如果依赖的文件都没变,即复用依赖关系。
其流程如下图所示:
有人可能会有疑问,为什么可以检查上一次的依赖?
如果这次引入了列表外的新文件,岂不是无法判断文件是否改变吗。
其实不然,引入新文件的前提是加入了新的#import 指令,它必然导致旧依赖列表中的某个文件发生改变,因此这种做法是相对安全的。

命中依赖缓存的话,可以在 5 毫秒以内得到编译命令的依赖文件列表,这是一个很理想的性能。
不过在实践中经常发现,即使文件修改了,依赖关系也大多是不变的,例如修改变量的值或增加一个类成员。如果我们能抓住这个特性,就可以大大增加缓存命中率。
忽略无关行
有些代码修改影响依赖,有些则不会,如果我们只考虑影响依赖的改动,就可以排除掉大量干扰因素。下面是两个例子,展示了有效改动和无效改动的区别。
有效改动(导致依赖分析缓存失效)

无效改动 (不影响依赖分析缓存)

除了前文提及的#include 和 #import ,还有如下语句可能造成缓存失效:#if, #else, #define, #ifdef, #ifndef, #include_next。
它们的共性是以# 开头,在预处理阶段会被编译器解析。这些指令统称为Directive,因此,我们只需缓存文件的Directive列表,当文件内容发生改变时,重新获取Direcitive列表,并和之前缓存的内容对比,如果列表不变,就可以认为该文件的改动不影响依赖关系。
深度优先分析
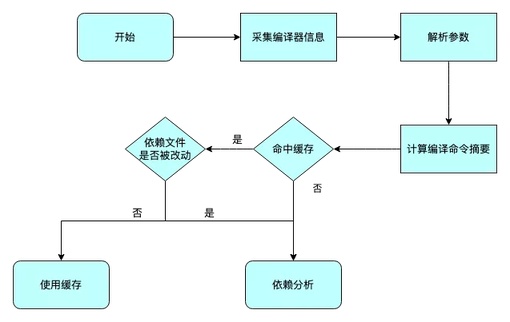
如果没命中依赖缓存或者关闭了该功能,就会进入依赖分析的阶段。
依赖分析采用深度优先搜索的算法,找到代码中所有的 #include 和 #import 对应的文件。需要注意的是,#if和#else这样的条件宏,也需要在预处理阶段解析。
深度优先采用文件栈 + 行指针的方式实现,如图所示:
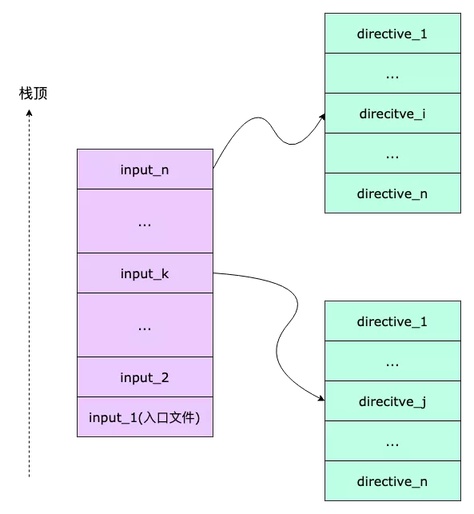
图中紫色部分是一个文件栈,栈中每一个元素都存放了文件相关的信息。每一个文件都对应一个Directive(预处理指令)列表,并维护一个指针,指向当前的Directive。
流程开始阶段,入口文件进栈,随后遍历入口文件的所有Directive,当读到 #include 或 #import 相关的 Directive 时,搜索依赖文件,并入栈。
此时,虽然入口文件还没有解析完,但按照规则应该优先解析新入栈的文件,所以需要通过指针维护入口文件当前读到的行号,以保证下次回到入口文件时,可以继续向下解析。
依赖分析的过程中,存在大量重复的操作,可以通过很多小技巧来优化这个过程。本文将介绍两个比较典型的小技巧。
依赖分析中最常见的操作在一堆备选目录中,找到对应名称的文件。
假设我们需要找到#import <A/A.h>语句中提到的A.h文件。命令行中有 10 个-I参数,分别指向 10 个不同的目录-Ifoo, -Ibar, ...,最朴素的方法是依次遍历这 10 个目录,拼接路径,尝试找到A.h文件。
这种方法当然可行,但是效率较低。对于大型项目,仅一条编译命令就可能涉及超过 5000 条#import语句,和超过 50 个头文件搜索路径。这意味着至少 5000*50=25 万次文件系统查找,时间开销非常大。
建立倒排索引,可以大大加快这个过程。其思路是预先遍历待搜索目录(directory),找到目录下的文件和子目录(统称entry),然后建立entry指向directory的倒排索引, 如下图所示:
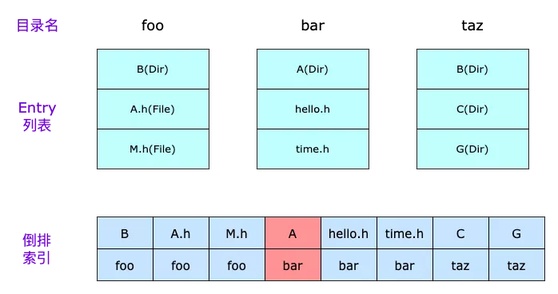
回到上面的问题,当我们搜索#import <A/A.h>时,首先需要找到foo, bar, taz三个目录里,哪个含有A子目录,根据倒排索引,可以快速定位到bar目录,而不需要从头开始遍历。
值得注意的是,objc 工程普遍采用 HeaderMap 技术(即 Xcode 自动生成的.hmap文件),提升编译时查找头文件的效率。HeaderMap 本质上也是一种索引表,它建立了 Directive -> Path 的直接映射关系。我们在建倒排索引的时候,需要解析.hmap中的内容,并合并到倒排索引中。
跨任务缓存(针对 iOS 项目的优化)
不同的编译任务,可能存在相同的依赖文件。例如foo.m和bar.m可能都依赖了common.h文件,编译foo.m的时候已经找到了common.h, 编译bar.m的时候,是否不需要再找一次了呢?
很遗憾,大多数情况需要重新查找,因为不同命令的查找条件往往不一样。影响查找条件的参数有很多,例如-I,-isystem 影响头文件搜索路径,-F 影响 Framework 搜索路径。
不过,iOS 项目往往可以复用之前的查找结果。
iOS 项目通常采用 Xcode + CocoaPods 的研发模式,针对同一个 Pod 内源文件的编译命令,头文件搜索路径基本是一致的。利用这个特性,我们提供了跨任务的缓存加速方案。
我们对搜索路径列表整体做了一层 hash,当两个命令的搜索路径相同时,对同名 Directive 的搜索结果一定相同。方案如下所示:
1. 在对单条命令进行依赖解析之前,先提取搜索路径的特征值。

2. 寻找头文件时,先查询缓存,如果查不到,在找到头文件后,将结果缓存。
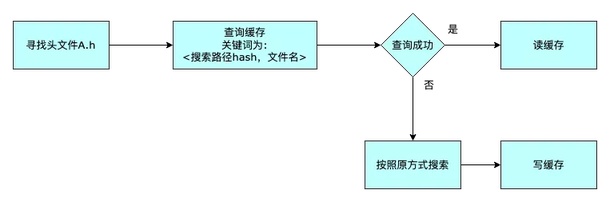
举一个具体的例子:
编译任务 1:
clang -c foo.m -IFoo -IBar -FCar编译任务 2:
clang -c bar.m -IFoo -IBar -FCar
foo.m和bar.m均包含行:#import common.h
假设编译任务 1 先执行,我们的做法应该是:
1. 提取搜索目录列表为:-IFoo -IBar -FCar
2. 使用 SHA-256 算法计算摘要,对应的搜索摘要为:598cf1e...(仅展示前 8 位)
3. 进行依赖分析,读到foo.m依赖common.h的部分,遍历搜索目录,找到common.h的位置,假设在目录Bar下面。
4. 写缓存,缓存用哈希表实现,key 为<598cf1e..., common.h>,value 为Bar
5. 执行编译任务 2,再次遇到寻找common.h的请求。
6. 直接从缓存中查到common.h在Bar目录下
索引缓存(针对 iOS 项目的优化)
建索引可以减少遍历目录寻找头文件的次数,是非常有效的优化方案。但是当头文件搜索目录过多,或者 hmap 过大时,建索引本身也需要几十毫秒的时间,对于性能要求十分严苛的依赖解析来说,这个时间还是略长。
所以我们想到,对索引本身是否可以做缓存呢?
按照跨任务缓存的思路,索引本身也是可以缓存的,只要两个任务的头文件搜索路径,以及 hmap 中的索引内容都一直,它们就可以共用一套索引。
具体的方案和跨任务缓存类似,本文就不详细展开了。通过对索引的缓存,我们将依赖分析的速度又提升了 20 毫秒左右。
分布式编译和编译缓存是提升大型项目编译效率的两大法宝。本文主要介绍了字节跳动的分布式编译解决方案。
该方案核心部分采用了开源框架 goma 的代码,并在此基础上,针对 iOS 项目的特性,做了一定的优化。
分布式编译的核心思想是空间换时间,引入额外的机器,提升单次编译的 CPU 数量。分布式编译的效果,取决于中心节点分发任务的速度,任务的分发又取决于依赖的解析效率。
传统方案利用编译器的预处理来解析依赖,方法可行,但由于每次解析都要单独 fork 进程,数据难以复用,存在性能瓶颈。我们采用了开源框架 goma 的代码,并在此基础上,针对 iOS 项目的特性,做了一定的优化。
本文介绍了依赖解析的四种技巧,分别从消除噪音,索引,缓存三个角度进行了优化。编译优化的道路,任重而道远。感谢 goma 团队,提供了许多优秀的设计思路和技巧,我们也会在此方向持续研究,尽可能的把思路分享给大家。
# 关于字节终端技术团队
字节跳动终端技术团队(Client Infrastructure)是大前端基础技术的全球化研发团队(分别在北京、上海、杭州、深圳、广州、新加坡和美国山景城设有研发团队),负责整个字节跳动的大前端基础设施建设,提升公司全产品线的性能、稳定性和工程效率;支持的产品包括但不限于抖音、今日头条、西瓜视频、飞书、番茄小说等,在移动端、Web、Desktop 等各终端都有深入研究。
就是现在!客户端/前端/服务端/端智能算法/测试开发 面向全球范围招聘!一起来用技术改变世界,感兴趣请联系 [email protected]。邮件主题:简历-姓名-求职意向-期望城市-电话。
MARS- TALK 04 期来啦!
2 月 24 日晚 MARS TALK 直播间,我们邀请了火山引擎 APMPlus 和美篇的研发工程师,在线为大家分享「APMPlus 基于 Hprof 文件的 Java OOM 归因方案」及「美篇基于 MARS-APMPlus 性能监控工具的优化实践」等技术干货。现在报名加入活动群 还有机会获得最新版 VR 一体机——Pico Neo3 哦!
⏰ 直播时间:2 月 24 日(周四) 20:00-21:30
💡 活动形式:线上直播
🙋 报名方式:扫码进群报名

作为开年首期 MARS TALK,本次我们为大家准备了丰厚的奖品。除了 Pico Neo3 之外,还有罗技 M720 蓝牙鼠标、筋膜枪及字节周边礼品等你来拿。千万不要错过哟!

👇 点击阅读原文,了解 APMPlus
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK