NeurIPS 2021 | CyGen:基于概率论理论的生成式建模新模式
编者按:在概率论中,两随机变量的一个联合分布可由一个变量的边缘分布和对应条件分布确定,也可对称地由另一变量的边缘分布和另一方向的条件分布确定,但无法由这两个边缘分布确定。因此,可否仅由这两个条件分布来确定联合分布,成为了科研人员感兴趣的研究方向。针对上述问题,微软亚洲研究院的研究员在 NeurIPS 2021 上发表的论文给出了全面而准确的回答,并基于此理论提出了一个全新的生成式建模模式 CyGen。其仅需两个可形成闭环的条件分布模型,而无需指定先验分布,从而从根本上解决了流形错配和后验坍缩问题,使得其在实验中可以完美表达数据分布,并能将不同特性数据点的表示区分开来。熟悉概率论的读者想必不会对条件概率公式感到陌生,即 p(x,z)=p(z)p(x│z)=p(x)p(z│x)。它意味着定义两随机变量 (x,z) 的一个联合分布 p(x,z) 可通过定义边缘分布 p(z) 和条件分布 p(x│z) 完成,也可对称地通过定义另一边缘分布 p(x) 和另一方向的条件分布 p(z│x) 完成。但是,用两个边缘分布 p(z) 和 p(x) 却无法定义联合分布,因为它们没有提供x和z相关性的信息。因此,用两个条件分布 p(x│z) 和 p(z│x) 能否确定 (x,z) 的一个联合分布,成为了研究员们十分感兴趣的研究方向。微软亚洲研究院的研究员们在 NeurIPS 2021 发表的论文“On the Generative Utility of Cyclic Conditionals”中,从最基本而通用的测度论角度分析了此问题,并且发现
答案可以是肯定的,但需要一定条件。研究员提出了一个
全新的生成式建模模式:只需建模两个条件分布,即似然模型(likelihood model,或称生成器 generator 或解码器 decoder)p(x│z),和推断模型(inference model,或称编码器 encoder) q(z│x),而不像已有模式还需指定或建模先验分布(prior distribution)p(z)。此新模式可以称之为“成环式生成式建模”,简记为 CyGen(Cyclic conditional Generative modeling),源自它仅需的模块——p(x│z)和q(z│x)——的方向(即从 z 采 x 和从 x 采 z)形成了闭环。
CyGen 避免了各已有生成模型因需要先验而带来的流形错配(manifold mismatch)和后验坍缩(posterior collapse)问题,从而能以更高精度拟合并生成数据,且能抽取到更有用的数据表示。
论文地址:https://arxiv.org/pdf/2106.15962代码地址:https://github.com/changliu00/cygen
两条件分布能否确定联合分布?此问题其实包含了两个子问题,只有都是肯定的答案,原问题才是肯定的答案。(1)
相容性(compatibility):对于任意给定的两条件分布 p(x│z) 和 q(z│x),它们是否可由同一个联合分布导出?换言之,是否存在一个联合分布 π(x,z) 使得 π(x│z)=p(x│z)且π(z│x)=q(z│x)?(2)
决定性(determinacy):对于两个相容的条件分布 p(x│z) 和 q(z│x),它们是否能唯一决定一个联合分布?换言之,能够导出二者的联合分布是否唯一?
绝对连续情况首先考虑两个条件分布都有密度函数(Radon-Nikodym 导数,统一描述连续和离散变量)的情况,测度论中称之为“绝对连续”(absolutely continuous)[1]。它包含了经典的变分自编码器(variational auto-encoder,VAE)[2]-[3]及最近兴起的基于扩散过程的生成模型(diffusion-based generative models)[4]–[6]。这是概率论中最常见的情况,有了密度函数就可以随意使用各种密度函数公式。由此可知,如果满足相容性,那么就存在联合分布 π(x,z) 使得两条件分布的比值 (p(x│z))/(q(z│x))=(π(x,z)/π(z))/(π(x,z)/π(x))=π(x) 1/π(z) 可分解为一个 x 的函数乘以一个 z 的函数。反过来,若比值满足这样的分解,就可以构造出这样的 π(x,z),从而说明两条件分布相容。这正是已有工作(如[7]–[9])的基础。但是,已有工作忽略了一件事:条件分布(如 p(⋅│z))仅在边缘分布(如 p(z))所定义的“几乎处处”的意义下是唯一的,特别是,若 z_0 在 p(z) 的支撑集(support)之外,那 p(⋅│z_0) 可以是一个任意的分布。这意味着任给的两条件分布就算不在整个空间 X×Z 上满足上述可分解性,但若它们可在一个恰当的子集上满足,仍有可能是相容的,因为若联合分布以此子集为支撑集,那么两条件分布在此子集之外的表现就可以是任意的。所以,已有工作的结论是充分但非必要的。近来也有工作[10]提出了充分必要的条件,但其描述仍然是存在性的,因而无法指导实际操作。所以微软亚洲研究院的研究员们找出了一个
既充分必要又可操作的相容性判据,大意是根据所给条件密度函数找出恰当子集并在其上判断可分解性。其严格叙述涉及一些数学细节,感兴趣的读者可阅读论文原文。关于
决定性,研究员们也给出了一个比以往结论(如[9])“更必要”的充分条件。大意是:在每一个“是方的”的两相容条件分布所决定的“恰当子集”上,联合分布是唯一的。特别地,若两条件分布都有全支撑集,那整个空间 X×Z 是唯一可能的“恰当子集”而且也“是方的”,因此若两者相容则它们即在整个空间上唯一确定了一个联合分布。所以
绝对连续情况下的条件分布有很好的决定性。
狄拉克分布情况另外一些流行的生成模型的似然模型(生成器)是一个从隐变量 z 到数据变量 x 的确定性映射,即 x=f(z),包括生成式对抗网络(generative adversarial net, GAN)[11]以及基于流的生成模型(flow-based generative model)[12], [13]。它所定义的条件分布将所有概率质量都集中在了 f(z) 这一点上,被称为狄拉克德尔塔分布(Dirac delta distribution):p(X│z)=δ_f(z) (X)=I[f(z)∈X],即若可测集 X 包含 f(z) 则为其赋测度1,否则赋0。注意在连续情况下这个分布没有密度函数,因而不能使用密度函数公式,而必须要从测度论的角度分析。研究员们对狄拉克分布情况也给出了一个既充分必要又可操作的相容性判据,大意是存在一个 x_0 使得另一条件分布只在其原像集上放置概率质量:q(f^(-1) ({x_0})|x_0)=1。可能反直觉的是只需一个这样的 x_0 即可满足相容性,这是因为 δ_((x_0, f^(-1) ({x_0})))已经是一个可导出两者的联合分布,而两者在此联合分布的支撑集 (x_0,f^(-1) ({x_0})) 之外的表现可以是任意的。不过,单点上的相容性对于实际使用并不足够,因而人们希望相容性能在一个集合上成立。若另一条件分布 q(Z│x) 也取狄拉克分布的形式,那最小化对偶学习中常用的环式一致性损失函数(cycle-consistency loss)[14]–[18]便对相容性是充分的。如果 f 还是可逆的,那它也是必要的,且相容的 q(Z│x) 的映射函数是 f 的逆。这也说明流模型天生就是相容的。至于决定性,刚才已提到,在 (x_0,f^(-1) ({x_0})) 上两相容条件分布可确定唯一的联合分布 δ_((x_0,f^(-1) ({x_0})))。但若这样的 x_0 不唯一,那这些 x_0 上的概率质量分配是无法确定的,因而无法在整个空间 X×Z 上定义联合分布。这也与直觉相符:狄拉克分布 δ_f(z) 及与其相容的 q(⋅|x) 只能确定 X×Z 中的一条曲线 x=f(z),但不能确定此曲线上的分布。因而
狄拉克分布情况下的条件分布缺乏决定性。
全新的生成式建模模式:CyGen生成式建模任务是指对数据变量 x 的分布 p(x) 进行建模。对于 x 维度很高的情况直接建模此分布不便灵活地表达各维度的相关性,因而当前流行的(深度)生成模型都会引入隐变量 z 并建模联合分布 p(x,z) 来给出p(x)=∫(p(x,z) dz),用此积分表达 x 各维度间复杂的相关性,同时这个隐变量 z 也可以作为数据的一个紧凑(低维)的有语义的表示(representation)。这些模型通过指定先验分布 p(z) 和似然模型 p_θ (x│z)(θ 为参数)来定义联合分布 p_θ (x,z)=p(z) p_θ (x│z)。同时,为提取数据表示,它们也会引入推断模型 q_ϕ (z│x)(ϕ 为参数)用来近似联合分布所定义的后验分布 p_θ (z│x)。变分自编码器(variational auto-encoder,VAE)[2], [3]、双向生成式对抗网络(bi-directional generative adversarial net,BiGAN)[19], [20],基于流的生成模型(flow-based generative model)[12], [13]以及基于扩散过程的生成模型(diffusion-based generative model)[4]–[6]都属于这种建模模式。然而,使用 p(z) 和 p_θ (x│z) 定义联合分布会带来一些问题。对于一般任务(如图像分布的建模)人们并不知道什么样的先验分布最合适,因而大多选用标准高斯分布。但它的支撑集是单连通的且似然模型通常是连续的(即保拓扑的),这意味着模型只能表达支撑集也是单连通的数据分布,而若真实数据分布有多联通分量,例如图1左上角所示的数据分布,这样的模型便无法很好地建模数据分布。例如 VAE 生成的数据分布是模糊的,而 BiGAN 生成的五瓣数据堆也仍然是连在一起的。这称为
流形错配(manifold mismatch)问题。另一方面,高斯先验也会让推断模型 q_ϕ (z│x) 都向原点集中,将具有不同特性的数据点的表示混在一起,使得这些表示不能充分体现各数据点 x 的特性,因而不够有用。图1第二行展示了 VAE 和 BiGAN 得到的数据表示会将不同类别数据的表示挤在一起甚至重叠。这称为
后验坍缩(posterior collapse)问题。也有方法试图使用人类专家设计的先验分布或者更加复杂的先验模型来解决这些问题,但这些方法要么只适用于个别具体任务,要么引入了额外的建模、训练和使用的代价。
图1:合成数据集(左上角图)上各类生成模型对于数据分布建模(第一行)和提取数据表示(第二行)的表现。从根本上解决问题的途径是解除生成式建模中需要指定先验分布的这个要求。这就引出了一开始的问题:能否仅用两个条件分布模型定义联合分布进而实现生成式建模。研究员们首先发现,简单粗暴地去掉先验分布是不行的。如图1所示,使用去噪自编码器(denoising auto-encoder,DAE)[21]–[23](它并非作为生成模型提出,但也只需两个条件分布模型)无法得到合理的结果。为此,研究员们提出了
“成环式生成式建模”CyGen(
Cyclic conditional
Generative modeling)这一生成式建模的全新模式。它仅需两个可形成闭环的条件分布模型 p_θ (x│z) 和 q_ϕ (z│x) 而无需指定先验分布,并且方法源自上面所建立的严格理论分析,保证了相容性和决定性,因而是一个合法的生成式模型。需要阐明的是,两条件分布模型满足相容性和决定性就唯一确定了联合分布,因此也隐式地定义了一个先验分布,只是 CyGen 无需特意为它建立模型显式表达。由于无需指定先验分布,CyGen 从根本上解决了流形错配和后验坍缩问题,图1的结果表明它确实能完美表达数据分布,并能将不同特性数据点的表示给区分开来。
满足相容性和决定性为构成合法的生成模型,两条件分布模型必须能定义一个联合分布,所以它们必须满足相容性和决定性。对于
决定性,从上面的理论分析可以得知,狄拉克形式的条件模型,例如 GAN 及基于流的生成模型中确定性的似然模型(生成器),无法给出决定性。因而使用绝对连续形式的条件模型,例如 VAE 中概率性的似然模型和推断模型,其良好的决定性也是理论分析的结论。研究员们使用绝对连续情况下的
相容性判据来实现相容性。由于一般的概率性条件分布模型结构都有全支撑集,因此判据中的“恰当子集”只可能是整个空间 X×Z,所以满足相容性只需满足两条件分布密度函数的比的可分解性条件。为此,需要引入如下相容性损失函数(compatibility loss):
其中 p^*(x) 为真实数据分布。直觉上说,若条件密度比可分解,那其对数就是一个 x 的函数加上一个 z 的函数,因而在对z的任一分量又对 x 的任一分量求完导数后得零。这也可以说明反过来也成立。理论分析中提到过环式一致性损失函数可实现狄拉克分布情况下的相容性,但却无法用于绝对连续的情况,故此损失函数可视为它的推广。
它更揭示了标准 VAE 的秘密:若两条件分布都选为高斯分布,那当二者相容、即相容性损失函数为零时,两者的均值函数都是仿射(线性函数加常数)的。这解释了标准VAE的隐空间非常线性这一已有观察[24]。同时也可得知,若希望学到非线性表示,直接使用深度神经网络是不够的。因此研究员们将其中一个条件分布模型取为比高斯分布更加灵活的分布,例如基于流的概率模型(如[25])。使用这个损失函数还面临一个关键问题:直接对它估计需要 O(d_X d_Z) 次求导操作(d_X 和 d_Z 分别为变量 x 和 z 的维度)。对于常见任务如图片生成,两个维度都极高,这个计算代价是不可接受的。为此,研究员们开发了此损失函数的一个随机但无偏且复杂度仅为 O(d_X+d_Z) 的估计器。详细信息可阅读论文原文。
拟合与生成数据作为一个生成模型,
两条件分布模型还必须提供相应的服务,即拟合与生成数据。当两个条件分布模型满足相容性和决定性时,则可用它们写出数据变量 x 的边缘分布 p_(θ,ϕ) (x),进而
可进行最大似然估计(maximum likelihood estimate):
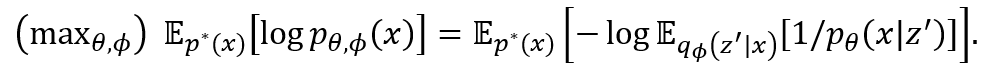
等式右边第二个期望可用 VAE 中常采用的 q_ϕ (z|x) 重参数化技术(reparameterization trick)用蒙特卡罗(Monte Carlo)方法估计[2],而估计其对数则可使用 logsumexp 技术保证数值稳定。相比之下,前文提到的 DAE 的目标函数 E_(p^* (x) q_ϕ (z^'│x)) [log p_θ (x│z^')]却是它的上界(注意这里需要最大化),因而无法保证拟合效果。特别是,它会让 q_ϕ (z│x) 变为集中在 p(x|z) 对 z 的最大值解上的狄拉克分布(即模式坍缩,mode-collapse),所以破坏了决定性。这解释了它在图1中的失败。CyGen 最终的优化目标是此最大似然目标与上述相容性目标之和。
至于
生成数据,由于两条件分布没有定义一个从头到尾的生成过程,祖先采样(ancestral sampling)无法使用,但仍然可用马尔可夫链蒙特卡罗(Markov chain Monte Carlo,MCMC)方法采样。它们只需目标分布的未归一化密度函数,而 CyGen 正好可以提供:p_(θ,ϕ) (x)∝(p_θ (x|z))/(q_ϕ (z|x))。研究员们选取了基于动力学系统的 MCMC 方法,例如随机梯度朗之万动力学系统方法(stochastic gradient Langevin dynamics,SGLD)[26],详细信息可阅读论文原文。
实验结果除了图1中合成数据集上的实验结果,研究员们也在真实图片数据集 MNIST 和 SVHN 上做了实验。为公平比较,所有方法都用了同样的条件分布模型结构。由于是概率性的(为满足 CyGen 的决定性),BiGAN 的训练过程十分不稳定,未能产生合理的结果,所以没有展示。图2中的结果表明,
CyGen 的生成效果十分清晰而多样,且用它提取的数据表示所训练的分类器取得了最高的准确率。这分别体现了 CyGen 避免流形错配及后验坍缩的好处。相比之下,DAE 由于没有决定性,生成质量不好,所以 VAE 的准确率是最低的,表明它有明显的后验坍缩问题。论文也给出了更多实验分析,表明引入相容性损失函数是必要的,使用 SGLD 生成数据的效果好于使用吉布斯采样,并且尽管舍弃了先验分布,人类知识仍可通过条件分布模型进入到生成式建模中。
图2:真实图片数据集MNIST和SVHN上各类生成模型的生成效果以及用它们提取的数据表示所训练的分类器的百分准确率(各图右下角)。
结语与展望本工作为“两条件分布是否可确定联合分布”这个问题建立了一个统一的理论框架,包括联合分布的存在性和唯一性——即两条件分布的相容性和决定性——的充分必要判据或充分条件,并基于此理论提出了一个仅需两条件分布模型而无需指定先验分布的生成式建模全新模式 CyGen,包括实现相容性和决定性以及拟合和生成数据的算法。实验展示了 CyGen 因解除对指定先验分布的需求而带来的更好的生成效果及更有用的数据表示等优势。CyGen 这种生成式建模模式会为很多应用领域带来便利,因为在大部分场景中很难知道一个先验分布,但却对条件分布有一定的知识,例如图片特征对图片平移旋转缩放的不变性。另一方面,本文中所建立的基础理论也能对机器学习其他领域(例如对偶学习和自监督学习)带来新的认识,进而启发新的分析和算法。[1] P. Billingsley, Probability and Measure. New Jersey: John Wiley & Sons, 2012.[2] D. P. Kingma and M. Welling, “Auto-encoding variational Bayes,” in Proceedings of the International Conference on Learning Representations, 2014.[3] D. J. Rezende, S. Mohamed, and D. Wierstra, “Stochastic Backpropagation and Approximate Inference in Deep Generative Models,” in International Conference on Machine Learning, 2014, pp. 1278–1286.[4] J. Sohl-Dickstein, E. A. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep Unsupervised Learning using Nonequilibrium Thermodynamics,” in International Conference on Machine Learning, 2015.[5] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” in Advances in Neural Information Processing Systems, 2020, vol. 256.[6] Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-Based Generative Modeling through Stochastic Differential Equations,” in Proceedings of the International Conference on Learning Representations, 2021, pp. 1–32.[7] B. C. Arnold and S. J. Press, “Compatible conditional distributions,” J. Am. Stat. Assoc., vol. 84, no. 405, pp. 152–156, 1989.[8] B. C. Arnold, E. Castillo, and J. María Sarabia, “Conditionally specified distributions: An introduction,” Stat. Sci., vol. 16, no. 3, pp. 249–265, 2001.[9] B. C. Arnold, E. Castillo, and J.-M. Sarabia, Conditionally Specified Distributions. 1992.[10] P. Berti, E. Dreassi, and P. Rigo, “Compatibility results for conditional distributions,” J. Multivar. Anal., vol. 125, pp. 190–203, 2014.[11] I. J. Goodfellow et al., “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems, pp. 1–9, 2014.[12] L. Dinh, D. Krueger, and Y. Bengio, “NICE: Non-linear Independent Components Estimation,” in workshop on the International Conference on Learning Representations, 2015.[13] D. P. Kingma and P. Dhariwal, “Glow: Generative Flow with Invertible 1x1 Convolutions,” in Advances in Neural Information Processing Systems, 2018.[14] T. Kim, M. Cha, H. Kim, J. K. Lee, and J. Kim, “Learning to Discover Cross-Domain Relations with Generative Adversarial Networks,” in International Conference on Machine Learning, 2017.[15] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks,” in IEEE International Conference on Computer Vision (ICCV), 2017.[16] Z. Yi, H. Zhang, P. Tan, and M. Gong, “DualGAN: Unsupervised Dual Learning for Image-to-Image Translation,” in IEEE International Conference on Computer Vision (ICCV), 2017.[17] Y. Xia, T. Qin, W. Chen, J. Bian, N. Yu, and T.-Y. Liu, “Dual Supervised Learning,” in International Conference on Machine Learning, 2017, no. 1.[18] Y. Xia et al., “Dual Learning for Machine Translation,” in Advances in Neural Information Processing Systems, 2016.[19] J. Donahue, P. Krähenbühl, and T. Darrell, “Adversarial Feature Learning,” in Proceedings of the International Conference on Learning Representations, 2017.[20] V. Dumoulin et al., “Adversarially Learned Inference,” in Proceedings of the International Conference on Learning Representations, 2017.[21] P. Vincent, H. Larochelle, Y. Bengio, and P.-A. Manzagol, “Extracting and Composing Robust Features with Denoising Autoencoders,” in International Conference on Machine Learning, 2008, vol. 311, pp. 1–10.[22] Y. Bengio, L. Yao, G. Alain, and P. Vincent, “Generalized denoising auto-encoders as generative models,” in Advances in Neural Information Processing Systems, 2013, pp. 1–9.[23] Y. Bengio, É. Thibodeau-Laufer, G. Alain, and J. Yosinski, “Deep generative stochastic networks trainable by backprop,” in International Conference on Machine Learning, 2014, vol. 2, pp. 1470–1485.[24] H. Shao, A. Kumar, and P. Thomas Fletcher, “The Riemannian geometry of deep generative models,” in IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, 2018.[25] R. Van Den Berg, L. Hasenclever, J. M. Tomczak, and M. Welling, “Sylvester normalizing flows for variational inference,” in 34th Conference on Uncertainty in Artificial Intelligence, 2018, vol. 1, pp. 393–402.[26] M. Welling and Y. W. Teh, “Bayesian Learning via Stochastic Gradient Langevin Dynamics,” in International Conference on Machine Learning, 2011.
你也许还想看:


