

机器学习中极大似然估计MLE和最大后验估计MAP
source link: https://weisenhui.top/posts/48308.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

机器学习必知必会
最大似然估计MLE、最大后验概率估计MAP这两个概念在机器学习和深度学习中经常碰到。现代机器学习的终极问题都会转化为解目标函数的优化问题,MLE和MAP是生成这个函数的很基本的思想,因此我们对二者的认知是非常重要的。
在统计中最大似然估计(Maximum likelihood estimation, 简称MLE)和最大后验概率估计(Maximum a posteriori estimation, 简称MAP)是很常用的两种参数估计方法(根据观测到的数据去推测模型和参数),但很多人并不理解这两种方法的思路,本文将详细介绍他们的区别。
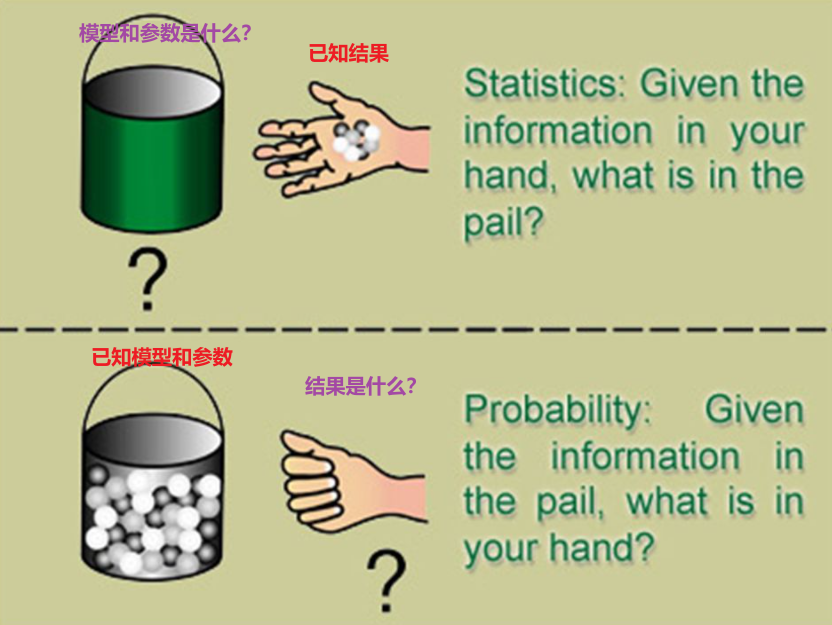
一、概率和统计的区别
我们在大学里通常会学到《概率论与数理统计》这门课,那概率(probabilty)和统计(statistics)看似两个相近的概念,其实研究的问题刚好相反。
Lary Wasserman 在 All of Statistics 的序言里有说过概率论和统计推断的区别:
The basic problem that we study in probability is:
Given a data generating process, what are the properities of the outcomes?
The basic problem of statistical inference is the inverse of probability:
Given the outcomes, what can we say about the process that generated the data?
{kind=link}
- 概率是已知模型和参数,推数据(例如均值,方差,协方差等)
- 统计是已知数据,推模型和参数(例如高斯分布、指数分布等)
显然,本文解释的MLE和MAP都是统计领域的问题。它们都是根据观测到的数据去推测模型和参数的方法。
二、概率函数和似然函数的区别 P(x|θ)
对于函数P(x|θ),输入x表示某一个具体的数据,θ表示模型的参数
- 如果θ是已经确定的,x是变量,那这个函数就叫做概率函数(probability function),它描述已知模型的情况下,不同的样本点x出现的概率是多少。
- 如果x是已经确定的,θ是变量,那这个函数就叫做似然函数(likelihood function),它描述对于不同的模型参数θ,出现x这个样本点的概率是多少。
这种形式我们之前也见过,比如f(x,y)=xy,如果x是已经确定的,如x=3,那么f(3,y)=3y是指数函数,而如果y是已经确定的,如y=2,那么f(x,2)=x2是幂函数。同一个数学形式,从不同变量角度考虑,可以有不同的名字。
三、频率学派:极大似然估计 argmaxθP(x∣θ)
关于极大似然估计的详细原理,可以看我的另一篇博客:【极大似然估计MLE】透彻理解机器学习中MLE的原理
假设有一个造币厂生产某种硬币,现在我们拿到了一枚这种硬币,想试试这硬币是不是均匀的?
这是一个统计问题,解决统计问题需要什么? 数据!
所以我们拿这枚硬币抛了10次,得到的数据x=反正正正正反正正正反
假设正面朝上的概率是θ,通过极大似然估计我们可以求出最有可能出现数据x的模型参数θ=0.7,然后我们就认为这枚硬币不是均匀的,正面朝上的概率是0.7,这就是极大似然估计做的事情。
但有些会说,硬币一般都是均匀的啊,就算你实验发现结果是”反正正正正反正正正反”,我也不信θ=0.7
这里就设计到贝叶斯学派的思想了,要考虑先验概率(即不同模型出现的概率也是不同的),为此,引入了最大后验概率。
四、贝叶斯学派:最大后验估计 argmaxθP(x∣θ)P(θ)
最大似然函数是在观测数据x已知的情况下,直接选择能使P(x|θ)最大的模型(参数为θ),而贝叶斯学派认为,每个模型(参数θ)出现的概率是不一样的。在贝叶斯学派眼里,参数θ也是随机变量, 它自身也有分布,。比如以抛硬币为例,根据常识(先验知识),模型(θ=0.5)出现的概率显然是最大的,因此我们还需要考虑先验概率,在现实世界中,不同模型出现的概率,有些模型即便P(x|θ)很大,但可能它存在于现实世界的概率是0.001,综合考虑P(x|θ)P(θ)就会很小。
因此最大后验概率估计是想让P(x|θ)P(θ)最大。而极大似然估计时默认认为某个模型出现的概率是一样的,P(θ)是常数,即极大似然估计只需要让P(x|θ)最大。
最大后验概率估计可以看作是正则化的最大似然估计,当然机器学习或深度学习中的正则项通常是加法,而在最大后验概率估计中采用的是乘法,P(θ)是正则项
抛硬币实例
下面以抛硬币为例,来理解最大后验概率估计
投硬币时,我们认为(”先验地知道”)θ取0.5的概率很大,取其他值的概率小一些。我们用一个高斯分布(当然你也可以认为先验分布是个Beta分布)来具体描述我们掌握的这个先验知识,例如假设P(θ)为均值0.5,方差0.1的高斯函数,分布函数为1√2πσe−(θ−μ)22σ2=110√2πe−50(θ−0.5)2,如下图
每个模型(参数θ)存在于现实世界的可能性不同,模型(θ=0.5出现的可能性最大)
似然函数 P(x|θ)=θ7(1−θ)3,图像如下:
则 P(x|θ)P(θ)的函数如下图:
之前通过极大似然估计,我们得到θ=0.7时,P(x|θ)取到最大值,现在我们使用最大后验概率估计,θ=0.558时,P(x|θ)P(θ)取到最大值。
那如何让贝叶斯学派的人相信极大似然估计的结果θ=0.7呢?你得多做点实验。
如果做了1000次实验,其中700次都是正面朝上,此时的似然函数P(x|θ)=θ700(1−θ)300,图像如下:
假设先验知识P(θ)仍为均值0.5,方差0.1的高斯函数
则 P(x|θ)P(θ)的函数如下图:
现在我们使用最大后验概率估计,θ=0.696时,P(x|θ)P(θ)取到最大值。这样就算是考虑了先验概率的贝叶斯学派的人,也不得不承认得把θ估计在0.7附近了。
所以说随着试验次数的增加,我们的先验假设的作用被逐渐淡化,数据中体现的信息将会在估计中占据主导作用,因此当数据量足够大时,会发现两种估计方法会得到相近的结论。
顺便说一下为什么最大后验概率估计中有“后验概率”这个词,其实也很好理解,后验概率的定义是P(θ|X),其中X是已经确定的,θ是变量,利用贝叶斯公式p(θ∣X)=p(X∣θ)⋅p(θ)p(X),在贝叶斯学派里面,P(X)=∑θP(X|θ)P(θ)是综合考虑所有不同模型后得到的结果,显然P(X)是固定的(你也可以理解为归一化项),选择不同的模型(参数θ)会影响p(θ∣X),但不会影响P(X)。
因此之前我们是argmaxθP(X∣θ)P(θ),它和argmaxθP(θ∣X)是等价的
argmaxθP(θ∣X)=argmaxθP(X∣θ)P(θ)P(X)∝argmaxθP(X∣θ)P(θ)=argmaxθ[logP(X∣θ)+logP(θ)]
五、 最大似然估计与最大后验估计的区别
频率学派和贝叶斯学派的争论
抽象一点来讲,频率学派和贝叶斯学派对世界的认知有本质不同:
频率学派认为世界是确定的,有一个本体,这个本体的真值是不变的,即参数θ是一个客观存在的固定值,我们的目标就是要找到这个真值或真值所在的范围。(世界上只有一个模型)
贝叶斯学派认为世界是不确定的,人们对世界先有一个预判,而后通过观测数据对这个预判做调整,我们的目标是要找到最优的描述这个世界的概率分布。。换言之,模型参数θ是一个随机变量,服从一个概率分布(世界上有多个模型,每个模型出现的概率不同),我们首先根据主观的经验假定θ的概率分布式P(θ)(先验分布,例如高斯分布、指数分布,往往并不准确),然后根据观察到的新信息(数据集X)其进行修正。
MLE和MAP的异同
在统计中最大似然估计(Maximum likelihood estimation, 简称MLE)和最大后验概率估计(Maximum a posteriori estimation, 简称MAP)是很常用的两种参数估计方法,他们都是根据观测到的数据x去推测模型和参数
- 极大似然估计MLE是求让P(x|θ)最大的模型(它认为不同模型出现的概率相同,即P(θ)是一个常数或者说它认为世界上只有一个模型)
- 最大后验概率估计MAP是求让P(x|θ)P(θ)最大的模型(它认为不同模型出现的概率不同)
随着数据量的增加,参数分布会越来越向数据靠拢,先验的影响力会越来越小
如果先验是uniform distribution,则贝叶斯方法等价于频率方法。因为直观上来讲,先验是uniform distribution本质上表示对事物没有任何预判
- 高中数学有一个著名的概率问题,“一枚硬币连续投了五次都是正面,那么第六次投还是正面的概率是多少?”机智的高中生会想,这骗得了我?这是独立重复实验,概率还是0.5!(因为这个高中生有先验知识,根据常识硬币正面朝上的概率=0.5最常见)
- 可如果一枚硬币连续投了一百次都是正面呢?一亿次都是正面呢?是否还要坚信出现正面的概率是0.5?这个硬币会不会被人动了手脚,就只有正面呢?(说明在具体实验中,先验知识可能并不准确)
- 当大量的事实摆在我们面前,随着数据越来越多,人应该越来越相信这个硬币有问题,越来越不相信硬币的概率是0.5,这才是最自然而然的感觉,这才是动态的看待问题,而不是机械僵化的看待问题,而这种直觉背后就是贝叶斯思想。(先验的影响越来越小)
最大后验估计与L1 L2正则之间的关系
参考:https://zhuanlan.zhihu.com/p/342268982
MAP的奥妙之处在于我们可以通过先验的方式给模型灌输一些信息,比如模型的参数θ可能服从高斯分布,这样我们可以假定先验就是高斯分布
P(θ)=1√2πσe−(θ−μ)22σ2,其中μ和σ2是先确定好的
在极大似然估计的基础上加了高斯的先验,这等同于我们在已有的代价函数上加了L2正则。
当我们把先验分布换成拉普拉斯分布时,会是什么情况呢?
知乎:拉普拉斯分布
f(x∣μ,b)=12be−|x−μ|b,其中μ和b是先确定好的
简单总结:
- 假设参数的先验概率服从高斯分布,相当于原来损失函数加入了L2正则
- 假设参数的先验概率服从拉普拉斯分布,相当于原来损失函数加入了L1正则
顺便说一下,我们经常说L1正则化比L2正则化易得稀疏解,其实从最大后验概率的角度也能解释这个现象。
回答:采用拉普拉斯分布先验的最大后验估计=极大似然估计+L1正则化项。观察高斯分布和拉普拉斯分布的概率密度函数图像可知,拉普拉斯分布更为稀疏,也即取到0的概率更大,所以其生成的参数ω更为稀疏。
参考:https://sm1les.com/2019/01/07/l1-and-l2-regularization/
六、进阶知识
贝叶斯公式理解(图解)
之前我们都是从模型(参数)与数据的角度来理解θ和X,下面从另一种角度理解贝叶斯公式:
贝叶斯公式:p(θ∣X)=p(X∣θ)⋅p(θ)p(X),即 posterior= likelihood ⋅ prior evidence
X(已经确定)是某件已经发生的事情,θ(变量)是某个原因。有了前面的知识铺垫,应该很容易明白为什么上面P(X|θ)是似然函数而不是概率函数了吧
举个例子:
- X表示老板生气了
- θ是表示某种原因
- 可能的原因1:员工迟到
- 可能的原因2:昨晚和老婆吵架了
- 可能的原因3:员工泄漏资料
从这个角度去理解贝叶斯公式:P(θ∣X)表示已知老板生气了,问是因为某种原因的概率有多大
$P员工迟到|老板生气 =\frac{P老板生气|员工迟到P员工迟到}{P老板生气}= \frac{P老板生气|员工迟到P员工迟到}{P老板生气|员工迟到P员工迟到 + P老板生气|原因2P原因2 + P老板生气|原因3*P原因3}$
第一个等号是贝叶斯公式,第二个等号用了全概率公式
贝叶斯估计
贝叶斯估计是最大后验估计的进一步扩展,感兴趣的同学可以看这两篇博客:贝叶斯估计、最大似然估计、最大后验概率估计,最大似然估计MLE、最大后验概率估计MAP及贝叶斯估计
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK