

定时任务之时间轮
source link: https://www.biaodianfu.com/timingwheel.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

定时任务的基础知识
首先,我们先了解下什么是定时任务?定时器有非常多的使用场景,大家在平时工作中应该经常遇到,例如生成月统计报表、财务对账、会员积分结算、邮件推送等,都是定时器的使用场景。定时器一般有三种表现形式:按固定周期定时执行、延迟一定时间后执行、指定某个时刻执行。
定时器的本质是设计一种数据结构,能够存储和调度任务集合,而且 deadline 越近的任务拥有更高的优先级。那么定时器如何知道一个任务是否到期了呢?定时器需要通过轮询的方式来实现,每隔一个时间片去检查任务是否到期。
所以定时器的内部结构一般需要一个任务队列和一个异步轮询线程,并且能够提供三种基本操作:
- Schedule 新增任务至任务集合;
- Cancel 取消某个任务;
- Run 执行到期的任务。
JDK 原生提供了三种常用的定时器实现方式,分别为 Timer、DelayedQueue 和 ScheduledThreadPoolExecutor。下面我们逐一对它们进行介绍。
Timer
Timer 属于 JDK 比较早期版本的实现,它可以实现固定周期的任务,以及延迟任务。Timer 会起动一个异步线程去执行到期的任务,任务可以只被调度执行一次,也可以周期性反复执行多次。我们先来看下 Timer 是如何使用的,示例代码如下:
Timer timer = new Timer();
timer.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
// do something
}
}, 10000, 1000); // 10s 后调度一个周期为 1s 的定时任务
可以看出,任务是由 TimerTask 类实现,TimerTask 是实现了 Runnable 接口的抽象类,Timer 负责调度和执行 TimerTask。接下来我们看下 Timer 的内部构造。
public class Timer {
private final TaskQueue queue = new TaskQueue();
private final TimerThread thread = new TimerThread(queue);
public Timer(String name) {
thread.setName(name);
thread.start();
}
}
TaskQueue 是由数组结构实现的小根堆,deadline 最近的任务位于堆顶端,queue[1] 始终是最优先被执行的任务。所以使用小根堆的数据结构,Run 操作时间复杂度 O(1),新增 Schedule 和取消 Cancel 操作的时间复杂度都是 O(logn)。
Timer 内部启动了一个 TimerThread 异步线程,不论有多少任务被加入数组,始终都是由 TimerThread 负责处理。TimerThread 会定时轮询 TaskQueue 中的任务,如果堆顶的任务的 deadline 已到,那么执行任务;如果是周期性任务,执行完成后重新计算下一次任务的 deadline,并再次放入小根堆;如果是单次执行的任务,执行结束后会从 TaskQueue 中删除。
DelayedQueue
DelayedQueue 是 JDK 中一种可以延迟获取对象的阻塞队列,其内部是采用优先级队列 PriorityQueue 存储对象。DelayQueue 中的每个对象都必须实现 Delayed 接口,并重写 compareTo 和 getDelay 方法。DelayedQueue 的使用方法如下:
public class DelayQueueTest {
public static void main(String[] args) throws Exception {
BlockingQueue<SampleTask> delayQueue = new DelayQueue<>();
long now = System.currentTimeMillis();
delayQueue.put(new SampleTask(now + 1000));
delayQueue.put(new SampleTask(now + 2000));
delayQueue.put(new SampleTask(now + 3000));
for (int i = 0; i < 3; i++) {
System.out.println(new Date(delayQueue.take().getTime()));
}
}
static class SampleTask implements Delayed {
long time;
public SampleTask(long time) {
this.time = time;
}
public long getTime() {
return time;
}
@Override
public int compareTo(Delayed o) {
return Long.compare(this.getDelay(TimeUnit.MILLISECONDS), o.getDelay(TimeUnit.MILLISECONDS));
}
@Override
public long getDelay(TimeUnit unit) {
return unit.convert(time - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
}
}
}
DelayQueue 提供了 put() 和 take() 的阻塞方法,可以向队列中添加对象和取出对象。对象被添加到 DelayQueue 后,会根据 compareTo() 方法进行优先级排序。getDelay() 方法用于计算消息延迟的剩余时间,只有 getDelay <=0 时,该对象才能从 DelayQueue 中取出。
DelayQueue 在日常开发中最常用的场景就是实现重试机制。例如,接口调用失败或者请求超时后,可以将当前请求对象放入 DelayQueue,通过一个异步线程 take() 取出对象然后继续进行重试。如果还是请求失败,继续放回 DelayQueue。为了限制重试的频率,可以设置重试的最大次数以及采用指数退避算法设置对象的 deadline,如 2s、4s、8s、16s ……以此类推。
相比于 Timer,DelayQueue 只实现了任务管理的功能,需要与异步线程配合使用。DelayQueue 使用优先级队列实现任务的优先级排序,新增 Schedule 和取消 Cancel 操作的时间复杂度也是 O(logn)。
ScheduledThreadPoolExecutor
上文中介绍的 Timer 其实目前并不推荐用户使用,它是存在不少设计缺陷的。
- Timer 是单线程模式。如果某个 TimerTask 执行时间很久,会影响其他任务的调度。
- Timer 的任务调度是基于系统绝对时间的,如果系统时间不正确,可能会出现问题。
- TimerTask 如果执行出现异常,Timer 并不会捕获,会导致线程终止,其他任务永远不会执行。
为了解决 Timer 的设计缺陷,JDK 提供了功能更加丰富的 ScheduledThreadPoolExecutor。ScheduledThreadPoolExecutor 提供了周期执行任务和延迟执行任务的特性,下面通过一个例子先看下 ScheduledThreadPoolExecutor 如何使用。
public class ScheduledExecutorServiceTest {
public static void main(String[] args) {
ScheduledExecutorService executor = Executors.newScheduledThreadPool(5);
executor.scheduleAtFixedRate(() -> System.out.println("Hello World"), 1000, 2000, TimeUnit.MILLISECONDS); // 1s 延迟后开始执行任务,每 2s 重复执行一次
}
}
ScheduledThreadPoolExecutor 继承于 ThreadPoolExecutor,因此它具备线程池异步处理任务的能力。线程池主要负责管理创建和管理线程,并从自身的阻塞队列中不断获取任务执行。线程池有两个重要的角色,分别是任务和阻塞队列。ScheduledThreadPoolExecutor 在 ThreadPoolExecutor 的基础上,重新设计了任务 ScheduledFutureTask 和阻塞队列 DelayedWorkQueue。ScheduledFutureTask 继承于 FutureTask,并重写了 run() 方法,使其具备周期执行任务的能力。DelayedWorkQueue 内部是优先级队列,deadline 最近的任务在队列头部。对于周期执行的任务,在执行完会重新设置时间,并再次放入队列中。ScheduledThreadPoolExecutor 的实现原理可以用下图表示:
以上我们简单介绍了 JDK 三种实现定时器的方式。可以说它们的实现思路非常类似,都离不开任务、任务管理、任务调度三个角色。三种定时器新增和取消任务的时间复杂度都是 O(nlog(n)),面对海量任务插入和删除的场景,这三种定时器都会遇到比较严重的性能瓶颈。因此,对于性能要求较高的场景,我们一般都会采用时间轮算法。
时间轮原理
如果一个系统中存在着大量的调度任务,而大量的调度任务如果每一个都使用自己的调度器来管理任务的生命周期的话,浪费cpu的资源并且很低效。时间轮是一种高效来利用线程资源来进行批量化调度的一种调度模型。把大批量的调度任务全部都绑定到同一个的调度器上面,使用这一个调度器来进行所有任务的管理(manager),触发(trigger)以及运行(runnable)。能够高效的管理各种延时任务,周期任务,通知任务等等。
时间轮算法的核心是:轮询线程不再负责遍历所有任务,而是仅仅遍历时间刻度。时间轮算法好比指针不断在时钟上旋转、遍历,如果一个发现某一时刻上有任务(任务队列),那么就会将任务队列上的所有任务都执行一遍。
时间轮算法不再将任务队列作为数据结构,其数据结构如下图所示(我们以小时为单位):
显而易见,时间轮算法解决了遍历效率低的问题。时间轮算法中,轮询线程遍历到某一个时间刻度后,总是执行对应刻度上任务队列中的所有任务(通常是将任务扔给异步线程池来处理),而不再需要遍历检查所有任务的时间戳是否达到要求。
现在,即使有 10k 个任务,轮询线程也不必每轮遍历 10 k 个任务,而仅仅需要遍历 24 个时间刻度。
一个以小时为单位的时间轮算法就这么简单地实现了。不过,小时作为时间单位粒度太大,我们有时候会希望基于分钟作为时间刻度。最直接的方式是增加时间刻度,每一天有 24 * 60 = 1440。此时时间轮的数据结构如下:
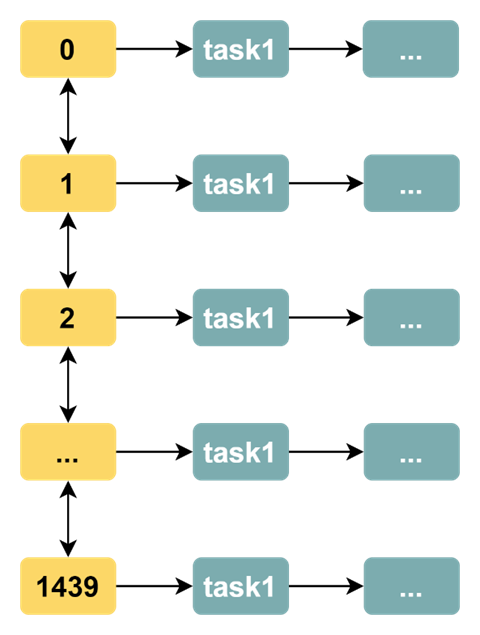
通过增加时间刻度,我们可以基于更精细的时间单位(分钟)来进行定时任务的执行。但是,这种实现方式有如下的缺陷:
- 轮询线程遍历效率低问题:当时间刻度增多,而任务数较少时,轮询线程的遍历效率会下降,例如如果只有 50 个时间刻度上有任务,但却需要遍历 1440 个时间刻度。这违背了我们提出时间轮算法的初衷:解决遍历轮询线程遍历效率低的问题;
- 浪费内存空间问题:在时间刻度密集,任务数少的情况下,大部分时间刻度所占用的内存空间是没有任何意义的。
如果要将时间精度设为秒,那么整个时间轮将需要 86400 个单位的时间刻度,此时时间轮算法的遍历线程将遇到更大的运行效率低的问题。
分层时间轮算法
分层的时间轮算法在生活中有对应的模型,那就是水表:

此时,我们有秒、分钟、小时级别的三个时间轮,每一个时间轮分别有 60、60、24 个刻度。
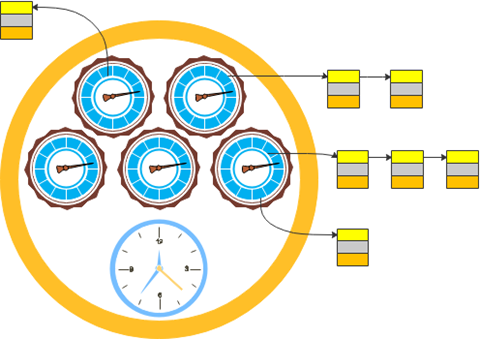
分层时间轮如下图所示:
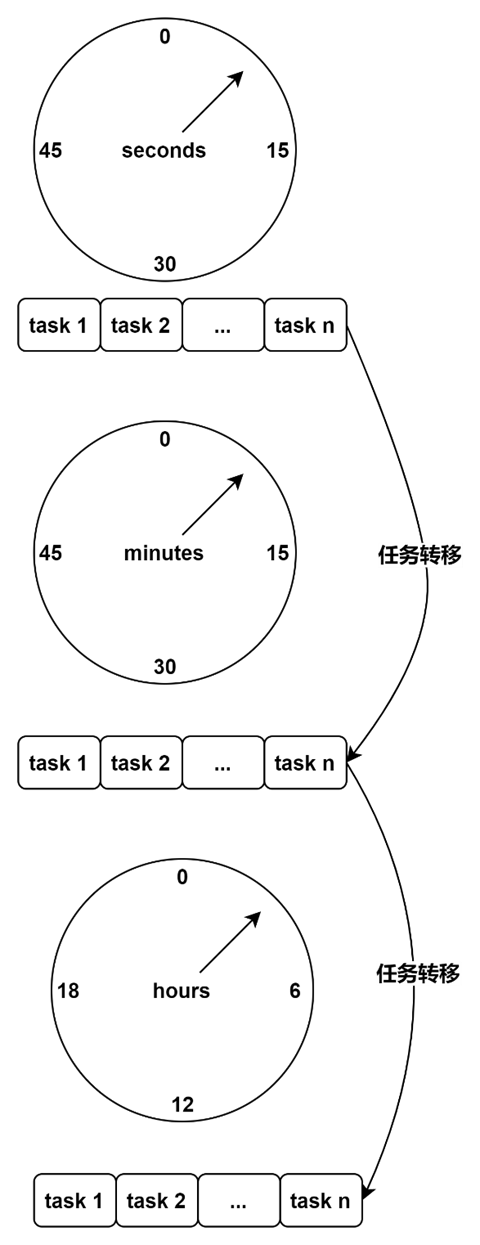
假设我们的任务需要在每天的 7:30:20 秒执行一次。任务首先添加于秒级别时钟轮的第 20 号刻度上,当其轮询线程访问到第 20 号刻度时,就将此任务转移到分钟级别时钟轮的第 30 号刻度上。当分钟级别的时钟轮线程访问到第 30 号刻度,就将此任务转移到小时级别时钟轮的第 7 号刻度上。当小时级别时钟轮线程访问到第 7 号刻度时,最终会将任务交给异步线程负责执行,然后将任务再次注册到秒级别的时间轮中。
分层时间轮中的任务从一个时间轮转移到另一个时间轮,这类似于水表中小单位的表转弯一圈会导致高单位的表前进一个单位一样。
由于时间轮在 Netty、Akka、Quartz、ZooKeeper 、Kafka等组件中都存在,所以这里不对具体实现和用法做详解的讲解。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK