

重温机器学习概念:偏差(Bias)、方差(Variance)、欠拟合(Underfitting)、过拟合(Overf...
source link: https://weisenhui.top/posts/52125.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

最近放寒假了,除了看论文,我还打算抽空复习一些机器学习的基础知识。今天主要复习了机器学习中偏差、方差、欠拟合、过拟合这几个概念,能不能讲清楚偏差方差,经常被用来考察面试者的理论基础,我之前对有些地方是一知半解的,比如那个射靶图是什么意思,如今查阅了一些资料后终于恍然大悟,另外我对于如何根据训练集loss和测试集loss调整模型有了更清晰和系统的认识。
本文主要围绕下面两张图进行讲解
)
偏差和方差的定义
在机器学习中,我们经常用过拟合、欠拟合来定性地描述模型是否很好地解决了特定的问题。实际上,我们还可以用偏差和方差来定量地描述模型的性能。
在监督学习中,模型的泛化误差来源于两个方面:偏差和方差
偏差和方差的定义:
- 偏差(Bias):由所有采样得到的大小为m的训练数据集训练出的所有模型的输出的平均值和真实模型输出之间的距离。
- 方差(Variance):由所有采样得到的大小为m的训练数据集训练出的所有模型的输出的方差。
假设我们现在要预测一只神奇宝贝进化后的cp值(战力点数),只有Niantic这个游戏公司知道实际的cp值(因为他有对应的函数ˆf)
我们能做的是:从一堆训练数据中,找到一个函数$f^,用f^来估计\hat f$。
这就好比你现在在打靶,ˆf是靶的中心点,你收集到一堆训练数据,得到你觉得最好的函数f∗,它落在靶上的某处,它跟ˆf有一段距离,这个距离可能来自Bias,也可能来自Variance。
现在我们想估计靶的中心ˆf(理想情况的函数)。当你收集一堆训练数据,得到一个函数f∗,这就相当于你往靶上打了一枪。
ˆf和f∗的距离取决于两件事:
- 偏差(Bias):你瞄准的位置是否错了,即你的estimator是否是无偏的
- 问题:如何判断你的estimator是否有偏呢?
- 回答:收集很多堆训练数据,得到很多的$f^,那么你就可以计算出E[f^]=\bar f$。ˉf与ˆf之间的距离就是Bias。它表示你瞄的时候有没有瞄准。
- 如果偏差大,说明你开始就没瞄准靶心,你以为正中心在蓝色的点,而实际上靶心在红色的点。偏差小意味着你瞄准的位置是对的。
- 方差(Variance):当你瞄准某个位置ˉf后,把子弹射出去,位置还是会有偏移的(枪会有波动),所以每次找到的$f^$是不一样的。所有$f^与\bar f$的距离平方的期望就是Variance 。
- $\operatorname{Var}(f^)=E(f^-E(f^))^{2}=E(f^-\bar f)^{2}$
- 方差高意味着你的枪性能很差,每次射出去是分散在瞄准位置的周围的。
上面提到要收集很多堆训练数据,但通常我们手里不是只有一个训练集吗?我们要怎么找到那么多堆训练集呢?
你可以想象有很多的平行宇宙,每个宇宙里都可以收集到一堆训练集,比如每个宇宙里都去抓10只Pokemons作为训练集,来得到一个$f^。显然不同宇宙中,抓到的Pokemons是不一样的,所以得到的f^$也是不一样的。
方差(复杂模型学得的f∗受数据集影响大)
假设我们有100个平行宇宙,收集到100个不同的f∗。
对于简单的模型(函数空间:y=b+w⋅xcp),它得到的100个$f是比较集中的,而复杂的模型得到的100个f$散布就比较广,即枪不太稳)。
这里你可能就会有个疑问了,为什么复杂模型得到的100个$f$的散布就比较广呢?主要是因为简单模型比较不会受你训练集的影响。复杂模型学得的$f^$受数据集影响大,由于训练样本只有m个,数据集太少了,你稍微哪个样本,复杂模型为了拟合好这个训练集,形状变化就会很大,导致射出去的f∗分散得比较开,所以方差比较大,也就是说,方差通常是由于模型的复杂度相对于训练样本数m过高导致的。
对于一个复杂的模型,当我们稍微改变训练集时,学得的函数f∗差距将非常大。
偏差(简单模型的函数空间比较小)
上面我们在讲枪的性能稳不稳(方差),现在我们再来看看枪一开始瞄的准不准(偏差)。
偏差(Bias)的大小取决于这100个$f^的平均值\bar f(E[f^*]=\bar f)与理想函数f^$的距离
从下图,我们可以发现,当你的模型越复杂,虽然得到的5000个f∗是比较分散的,但是你把他们平均起来得到的ˉf,却与ˆf是比较接近的,也就是偏差小。而模型越简单,得到的偏差反而大。
这是你可能又有疑问了,为什么简单模型的偏差大,复杂模型的偏差小呢?这就要从函数空间的角度来解释了。
简单模型的函数空间比较小,你的目标ˆf根本就不在这个空间里,所以会有很大的偏差,而由于这个空间比较小,所以方差是比较小的。
复杂模型的函数空间比较大,目标ˆf在这个空间里,只不过他没有办法找到这个ˆf在哪里,因为数据集太少了,你稍微哪个样本,复杂模型为了拟合好训练集,形状变化就会很大,导致射出去的f∗分散得比较开,所以方差比较大,而他们是分散在这个ˆf周围的,你平均一下的话,得到的ˉf是很接近ˆf的,所以偏差比较小。
欠拟合和过拟合
接下来,我们再来聊一聊在模型评估和调整的过程中,经常遇到的“欠拟合”和“过拟合”现象。
在实际项目中,采用多种方法、从多个角度降低“过拟合”和“欠拟合”的风险是算法工程师应当具备的领域知识。
欠拟合时,训练集loss大,测试集loss大
过拟合时,训练集loss小,测试集loss大
如果你的泛化误差(test loss)主要是因为方差(Variance)偏大,这个现象就是过拟合(overfitting)。
- 过拟合的主要原因是数据集比较少,复杂模型受数据集改动的影响比较大(比如多了个噪音点,模型为了拟合好它,就大变样了,也就是枪的波动比较大。而模型把噪音数据的特征也学习到了模型中,导致模型泛化能力下降)
如果你的泛化误差(test loss)主要是因为偏差(Bias)偏大,这个现象就是欠拟合(underfitting)。
- 欠拟合是因为你的模型过于简单,函数空间太小,ˆf不在这个空间里面,那你瞄的位置都不是靶心,肯定偏差大。
现在我们简单总结下面三对概念之间的关系:
- train loss和test loss
- 偏差和方差(定量)
- 欠拟合和过拟合(定性)
如果你的train loss大,说明你偏差(Bias)偏大(定量),这个现象叫做欠拟合现象(定性)
如果你的train loss小,但test loss大,说明你方差(Variance)偏大(定量),这个现象叫做过拟合现象(定性)
图解Trade-off
识别“欠拟合”和“过拟合”现象的方法
如果你的train loss大,说明你偏差(Bias)偏大(定量),这个现象叫做欠拟合(underfitting)现象
如果你的train loss小,但test loss大,说明你方差(Variance)偏大(定量),这个现象叫做过拟合(overfitting)现象
攻略图:机器学习任务 General Guide
在你做机器学习任务时,可以用以下General Guide来针对性地进行模型调整,不断改进机器学习模型。
具体来说,对于一个机器学习任务,80%的人会盯着testing data的loss,这是错的。我们首先会看training data的loss怎么样。
我们首先要根据training data的loss大小确定
- 你的模型弹性是否足够(函数空间是否包含了最优模型)
- 你的Optimization是否没有问题(你的梯度下降做的怎么样,是否应该用Adam替代SGD,参数是否调好了)
- 你的使用的特征是否足够(是否挖掘出了好的特征或与标签强相关的特征)。
当你确定training data的loss是小的时候,才能去看testing data的loss
顺便说一下,我们说一个training data的loss大的时候,到底多大算大,如果loss=10000,那显然很大,但loss=10,loss=2,loss=1,算大吗?数值等于多少才算大呢?
其实,不同任务,不同数据集的最优loss是不一样的,可能对于MNIST数据集而言,loss=0.2就算大了,而对于CIFAR10数据集而言,loss=2才算大。
正确的做法:我们先选择一个尽量简单的模型去做当前的机器学习任务,通常得到的training data loss数值会很大,然后一点点增加模型的复杂度(如加深网络),你会发现你训练得到的loss数值慢慢再变小,而当你模型复杂度增加到一定程度后训练得到的loss数值开始变大了,说明你应该停止改变模型了。
因此上面提及的training data loss大其实是一个相对的概念。
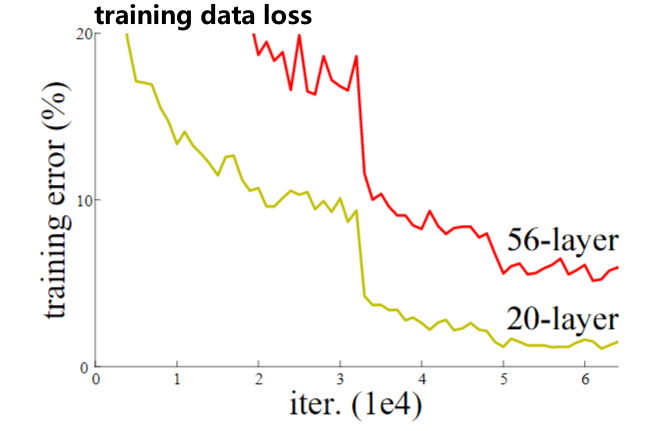
我想很多人都看过引用量10万的论文ResNet,在论文的第一页,He Kaiming用一个20层网络与56层网络的例子说明了有的时候你把模型变复杂后,testing data的loss不降反升,主要原因不是模型复杂后,出现了过拟合现象,而是你训练时的Optimization没有做好!
多数人看到下面这个图,会认为56层网络的测试集loss比20层网络的测试集大,所以56层网络这个模型过拟合了。根据我前面讲的,这样的判断显然是非常不合理的!
我们应该先去看下training data的loss情况!
根据实验结果,我们发现将模型变复杂后(20层→ 56层),training data上的loss反而变大了。根据General Guide,我们知道出现这个现象的原因只能是你的Optimization没有做好,你的网络根本训不动,梯度下降不给力啊。
{kind=link}
为了解决Optimization的问题,我们可以调参或者用更好的优化方法(如Adam),而Kaiming则提出了一种更高效的Optimization的方式,在网络层之间添加高速通道的方式,从而很好地解决了这个问题。
从以上例子,你应该清楚了吧,训练模型的时候,要先看training data的loss,然后才是testing data的loss
A. 降低过拟合(Overfitting)风险的方法
方差(Variance)偏大(即过拟合现象)的解决方法
(1)增加你的训练资料
使用更多的训练数据是解决过拟合问题最有效的手段,因为更多的样本能让模型学习到更多更有效的特征,减少噪音数据的影响
- 从网络上收集更多的资料
- 数据增强(如CV领域,可以对图片进行翻转或缩放;使用生成式对抗网络来合成大量的训练样本)
(2)限制你模型的复杂度(constrained model)
假设我们开了外挂,知道一个回归任务的模型是一个二次函数,只是我们不知道里面具体参数是多少。那你是怎么有这外挂呢?这取决于你对于问题的理解程度。最好的情况是你选择的模型跟数据背后产生的过程是一样的,那你就有机会得到很好的结果。
很遗憾,我们没有这样的外挂,所以在你选择的函式相对于当前少量的训练集过于复杂时,我们得适当降低模型的复杂度,避免模型拟合过多的采样到的噪音数据。
降低模型复杂度的方法:
- 神经网络调参:网络的层数、神经元的个数、epoch,dropout,embedding_dim,学习率,batchsize,seed等
- 决策树模型可以降低树的深度、进行剪枝等
- Less parameters, sharing parametersCNN
- Less features(剔除掉一些差的特征,特征不是越多越好)
- Early stopping(早停)
- Regularization(正则化,给模型参数一定的正则约束)
- 集成学习(把多个模型集成在一起,来降低单个模型的过拟合风险,如Bagging可以减少方差,即模型融合,预测结果加权平均)
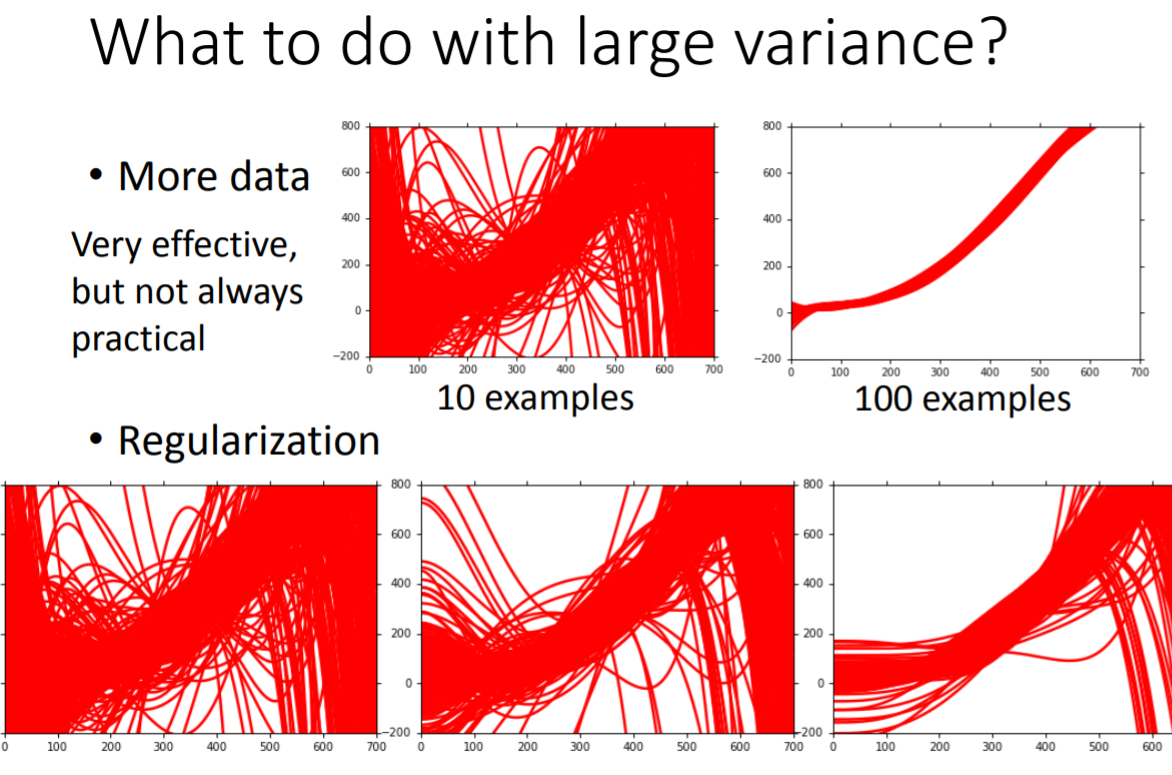
需要注意的是,当你想通过正则化限制模型复杂度的时候,你是可以降低方差的,从而缓解过拟合现象,但是你也不能过分地限制模型复杂度(正则化参数λ不能太大),因为这是会增大偏差的。换言之,给模型太多的限制后,它的弹性就太差了,函数空间变小了,图解
{kind=link}
B. 降低欠拟合(Underfitting)风险的方法
偏差(Bias)偏大(即欠拟合现象)的解决方法
(1)增加更多好的特征(kaggle竞赛里的特征工程,挖掘更多好的特征)
当特征不足或者现有特征与样本标签的相关性不强的时候,模型容易出现欠拟合的现象,也就是训练集上准确率不高,测试集上准确率也不高的情况。
其实你如果打过一些kaggle或天池的竞赛,你就会发现题目给你的特征就那么几个,比如4个数值特征,3个ID特征。你如果只用这几个特征去训练模型,大概率是欠拟合的,例如你的训练集的准确率只有70%,验证集的准确率只有66%,榜单上准确率只有64%,而排名靠前的大佬挖掘了很多“上下文特征”,“组合特征”,“统计特征”等新的特征,特征数由7变到了120个,即便是同样的模型,他们往往能够取得更好的效果,他们训练集准确率有82%,验证集准确率有80%,榜单上的准确率有77%。
除了人工挖掘特征,有很多模型也能帮助我们完成特征工程,如因子分解机、GBDT、Deep-crossing等都可以成为丰富特征的方法
某种意义上,提取更多好的特征能够降低training data loss的原因是我们在人工想办法帮助Optimization这个优化过程。
(2)重新设计模型,增加模型复杂度(换模型)
神经网络调参:网络的层数、神经元的个数、epoch,dropout,embedding_dim,学习率,batchsize,seed等
- 增加网络的层数
- 调Embedding的参数
- 增加神经元的个数
- 调dropout的大小
- 减少正则化系数
例如,对于一个推荐系统相关的比赛,你一开始可能是用最经典的多层MLP,发现训练集和测试集上的准确率都不高,那你可以换其他复杂的模型试试,比如DeepFM、Deep Cross、LightGBM、MMOE等,或许你的准确率就可以上去了。(不过以我的经验,换模型的效益远远不如提取几个好的特征)
不断增加模型复杂度(换模型)
训练集和测试集分布不一致的问题
根据General Guide,当你遇到训练集loss小,测试集loss大的时候,除了可能的过拟合(Overfitting),还有一种可能是训练集和测试集的分布不一样。
虽然我们在做机器学习任务时,通常假设训练集和测试集的分布一样,比如在做MNIST的时候是随机划分出80%为训练集,20%为测试集,但是在某些情况还是会遇到训练集和测试集不一样的情况,比如你的训练资料是2020年的数据,而测试资料是2021年的数据,那么mismatch的问题就很严重了,因为这两种数据背后产生的分布是不一样。
Q:如何判断是否出现了训练集和测试集分布不一致的问题?
A:这主要取决于你对数据产生的理解。
Mismatch的解决方法:迁移学习 Domain Adaptation
附:打靶图解释
在网上很多人讲偏差和方差都会拿下面这么个图,但是很少有人解释清楚这个图是怎么产生的以及上面这些点都是什么意思。
解释:这个图是以一次射击的例子来描述偏差和方差的区别和联系。
假设一次射击就是一个机器学习模型对一个样本进行预测。射中靶心位置代表预测准确,偏离靶心越远代表预测误差越大。
具体做法:我们通过n次采样得到n个大小为m的训练样本集合,训练处n个模型,对同一个样本做预测,相当于我们做了n次射击。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK