

根据文本描述从视频中抠图,Transformer:这种跨模态任务我最擅长
source link: https://www.51cto.com/article/703412.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
都说Transformer适合处理多模态任务。
这不,在视频目标分割领域,就有人用它同时处理文本和视帧,提出了一个结构更简单、处理速度更快(每秒76帧)的视频实例分割框架。
这个框架只需一串文本描述,就可以轻松将视频中的动态目标“抠”出来:
可以实现端到端训练的它,在基准测试中的多个指标上表现全部优于现有模型。
目前,相关论文已被CVPR 2022接收,研究人员来自以色列理工学院。

根据文本描述进行视频目标分割这一多模态任务(RVOS),需要结合文本推理、视频理解、实例分割和跟踪技术。
现有的方法通常依赖复杂的pipeline来解决,很难形成一个端到端的简便好用的模型。
随时CV和NLP领域的发展,研究人员意识到,视频和文本可以同时通过单个多模态Transformer模型进行有效处理。
为此,他们提出了这个叫做MTTR (Multimodal Tracking Transformer)的新架构,将RVOS任务建模为序列(sequence)预测问题。
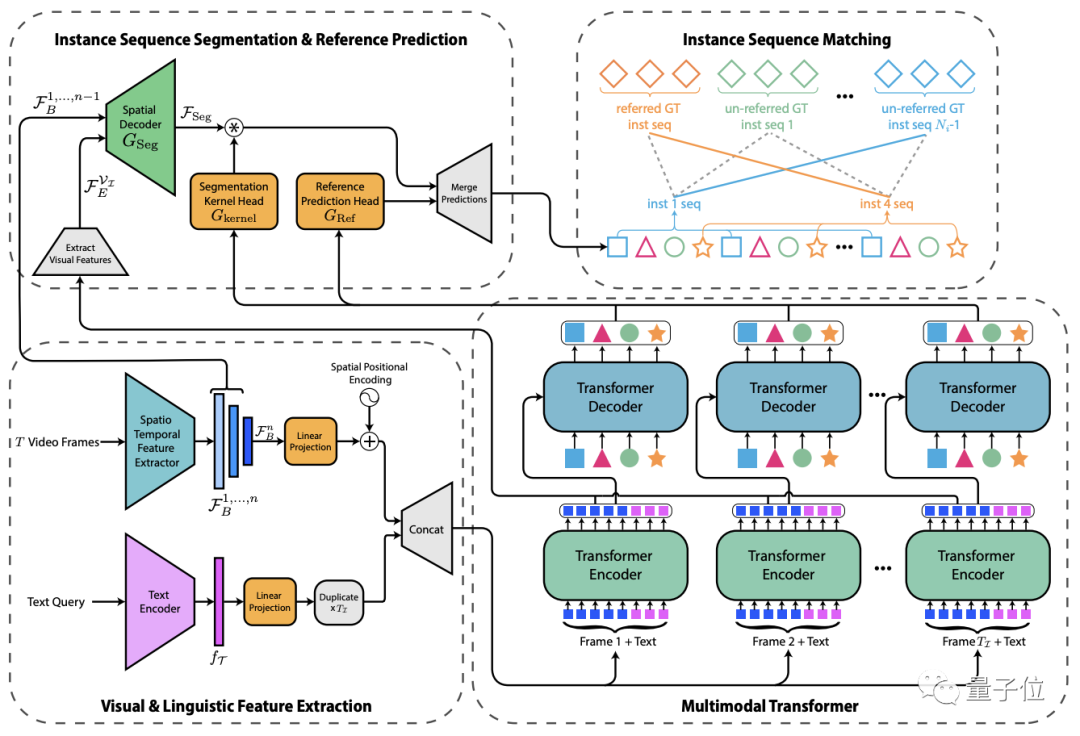
首先,输入的文本和视频帧被传递给特征编码器进行特征提取,然后将两者连接成多模态序列(每帧一个)。
接着,通过多模态Transformer对两者之间的特征关系进行编码,并将实例级(instance-level )特征解码为一组预测序列。
接下来,生成相应的mask和参考预测序列。
最后,将预测序列与基准(ground truth,在有监督学习中通常指代样本集中的标签)序列进行匹配,以供训练过程中的监督或用于在推理过程中生成最终预测。
具体来说,对于Transformer输出的每个实例序列,系统会生成一个对应的mask序列。
为了实现这一点,作者采用了类似FPN(特征金字塔网络)的空间解码器和动态生成的条件卷积核。
而通过一个新颖的文本参考分数函数,该函数基于mask和文本关联,就可以确定哪个查询序列与文本描述的对象具有最强的关联,然后返回其分割序列作为模型的预测。
精度优于所有现有模型
作者在三个相关数据集上对MTTR进行了性能测试:JHMDB-Sentences、 A2D-Sentences和Refer-YouTube-VOS。
前两个数据集的衡量指标包括IoU(交并比,1表示预测框与真实边框完全重合)、平均IoU和precision@K(预测正确的相关结果占所有结果的比例)。
结果如下:
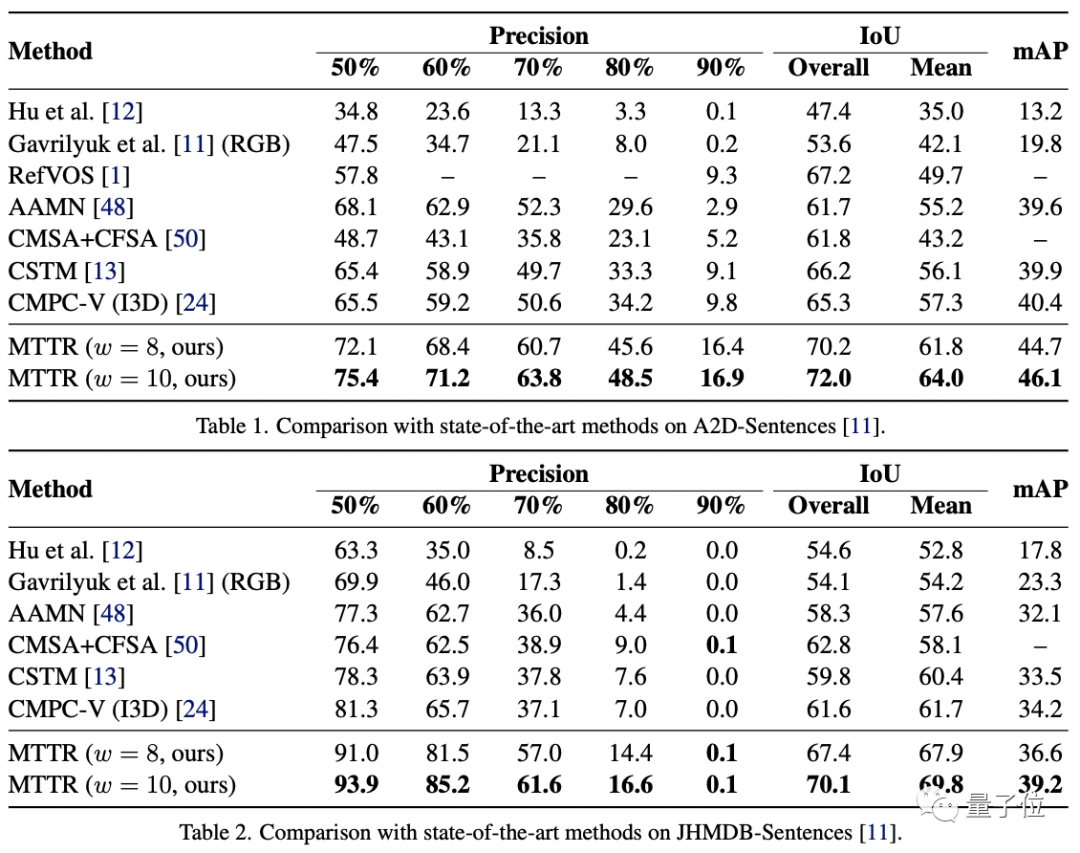
可以看到,MTTR在所有指标上都优于所有现有方法,与SOTA模型相比,还在第一个数据集上提高了4.3的mAP值(平均精度)。
顶配版MTTR则在平均和总体IoU指标上实现了5.7的mAP增益,可以在单个RTX 3090 GPU上实现每秒处理76帧图像。
MTTR在JHMDBs上的结果表明MTTR也具备良好的泛化能力。
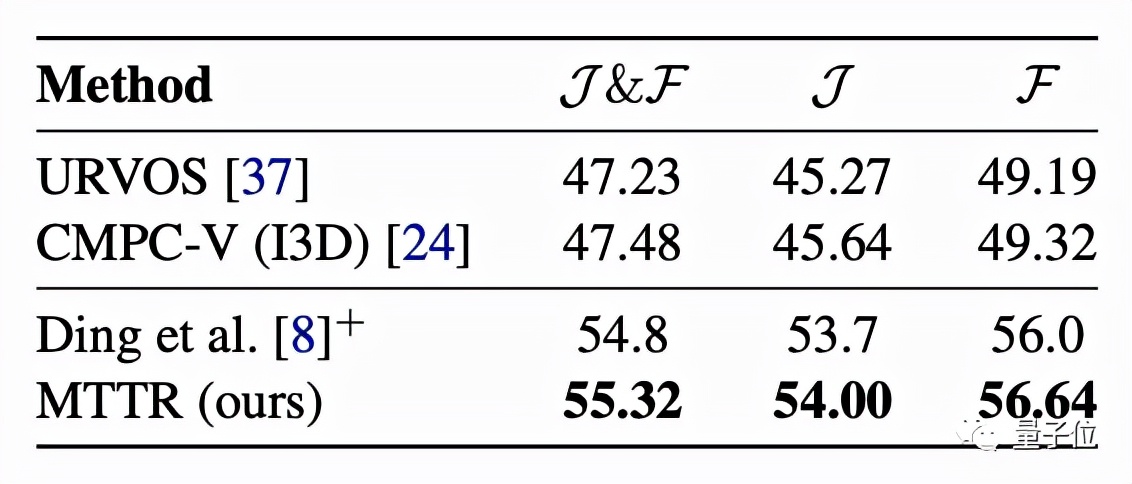
更具挑战性的Refer-YouTube-VOS数据集的主要评估指标为区域相似性(J)和轮廓精度(F)的平均值。
MTTR在这些指标上全部“险胜”。
一些可视化结果表明,即使在目标对象被类似实例包围、被遮挡或完全超出画面等情况下,MTTR都可以成功地跟踪和分割文本引用的对象。

最后,作者表示,希望更多人通过这项成果看到Transformer在多模态任务上的潜力。
最最后,作者也开放了两个试玩通道,感兴趣的同学可以戳文末链接~

△ Colab试玩效果
试玩地址:
https://huggingface.co/spaces/akhaliq/MTTR
https://colab.research.google.com/drive/12p0jpSx3pJNfZk-y_L44yeHZlhsKVra-?usp=sharing
论文地址:
https://arxiv.org/abs/2111.14821
代码已开源:
https://github.com/mttr2021/MTTR

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK