

买不起手办就用AI渲染一个!用网上随便搜的图就能合成,已有网友开炒游戏NFT
source link: https://www.qbitai.com/2022/02/32786.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

买不起手办就用AI渲染一个!用网上随便搜的图就能合成,已有网友开炒游戏NFT

已有网友开炒游戏NFT
萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
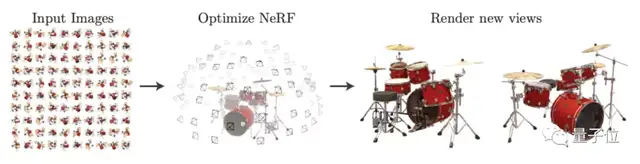
渲染一个精细到头发和皮肤褶皱的龙珠3D手办,有多复杂?

对于经典模型NeRF来说,至少需要同一个相机从特定距离拍摄的100张手办照片。
但现在,一个新AI模型只需要40张来源不限的网络图片,就能把整个手办渲染出来!

这些照片的拍摄角度、远近和亮暗都没有要求,还原出来的图片却能做到清晰无伪影:

甚至还能预估材质,并从任意角度重新打光:

这个AI模型名叫NeROIC,是南加州大学和Snap团队玩出来的新花样。

有网友见状狂喜:
不同角度的照片就能渲染3D模型,快进到只用照片来拍电影……

还有网友借机炒了波NFT(手动狗头)

所以,NeROIC究竟是如何仅凭任意2D输入,就获取到物体的3D形状和性质的呢?
基于NeRF改进,可预测材料光照
介绍这个模型之前,需要先简单回顾一下NeRF。
NeRF提出了一种名叫神经辐射场(neural radiance field)的方法,利用5D向量函数来表示连续场景,其中5个参数分别用来表示空间点的坐标位置(x,y,z)和视角方向(θ,φ)。
然而,NeRF却存在一些问题:
- 对输入图片的要求较高,必须是同一场景下拍摄的物体照片;
- 无法预测物体的材料属性,因此无法改变渲染的光照条件。
这次的NeROIC,就针对这两方面进行了优化:
- 输入图片的场景不限,可以是物体的任意背景照片,甚至是网络图片;
- 可以预测材料属性,在渲染时可以改变物体表面光照效果(可以打光)。
它主要由2个网络构成,包括深度提取网络(a)和渲染网络(c)。
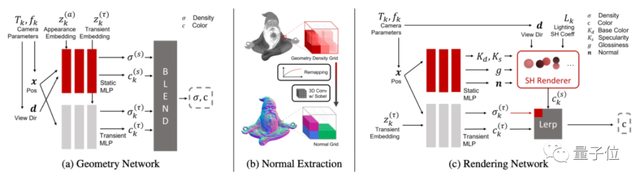
首先是深度提取网络,用于提取物体的各种参数。
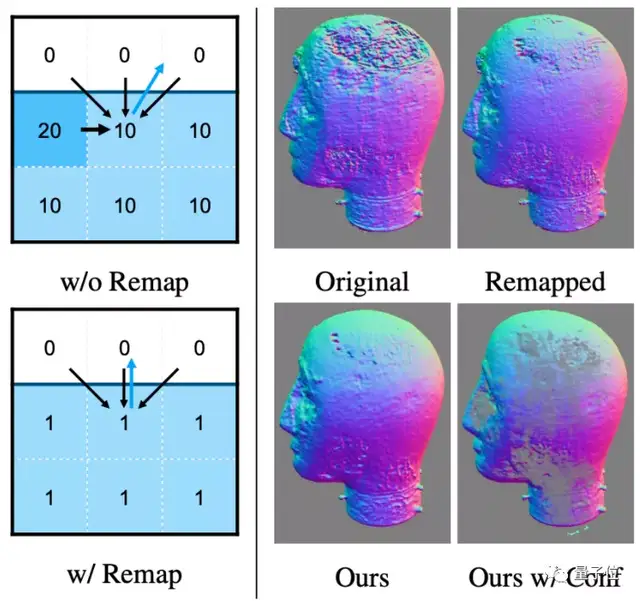
为了做到输入场景不限,需要先让AI学会从不同背景中抠图,但由于AI对相机的位置估计得不准确,抠出来的图片总是存在下面这样的伪影(图左):

因此,深度提取网络引入了相机参数,让AI学习如何估计相机的位置,也就是估算图片中的网友是从哪个角度拍摄、距离有多远,抠出来的图片接近真实效果(GT):

同时,设计了一种估计物体表面法线的新算法,在保留关键细节的同时,也消除了几何噪声的影响(法线即模型表面的纹路,随光线条件变化发生变化,从而影响光照渲染效果):
最后是渲染网络,用提取的参数来渲染出3D物体的效果。
具体来说,论文提出了一种将颜色预测、神经网络与参数模型结合的方法,用于计算颜色、预测最终法线等。
其中,NeROIC的实现框架用PyTorch搭建,训练时用了4张英伟达的Tesla V100显卡。
训练时,深度提取网络需要跑6~13小时,渲染网络则跑2~4小时。
用网络图片就能渲染3D模型
至于训练NeROIC采用的数据集,则主要有三部分:
来源于互联网(部分商品来源于网购平台,即亚马逊和淘宝)、NeRD、以及作者自己拍摄的(牛奶、电视、模型)图像,平均每个物体收集40张照片。
那么,这样的模型效果究竟如何呢?
论文先是将NeROIC与NeRF进行了对比。
从直观效果来看,无论是物体渲染细节还是清晰度,NeROIC都要比NeRF更好。
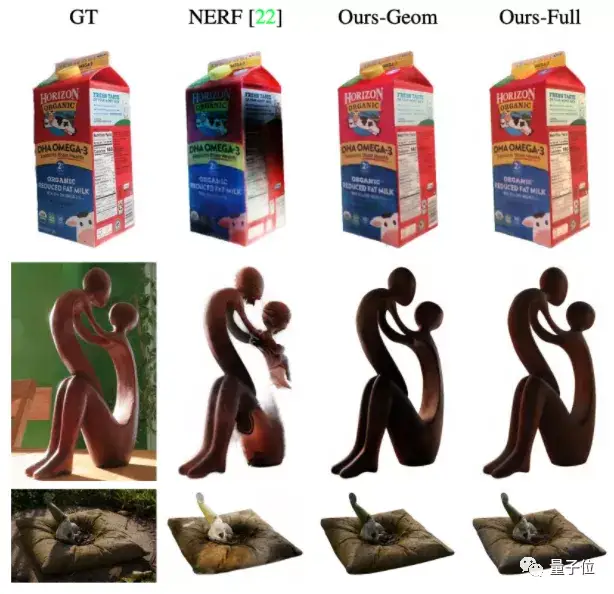
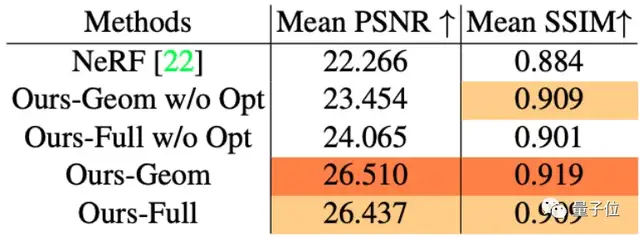
具体到峰值信噪比(PSNR)和结构相似性(SSIM)来看,深度提取网络的“抠图”技术都挺不错,相较NeRF做得更好:
同时,论文也在更多场景中测试了渲染模型的效果,事实证明不会出现伪影等情况:

还能产生新角度,而且重新打光的效果也不错,例如这是在室外场景:

室内场景的打光又是另一种效果:

作者们还尝试将照片数量减少到20张甚至10张,对NeRF和NeROIC进行训练。
结果显示,即使是数据集不足的情况下,NeROIC的效果依旧比NeRF更好。

不过也有网友表示,作者没给出玻璃或是半透明材质的渲染效果:

对AI来说,重建透明或半透明物体确实也确实是比较复杂的任务,可以等代码出来后尝试一下效果。
据作者表示,代码目前还在准备中。网友调侃:“可能中顶会、或者在演讲之后就会放出”。
一作清华校友

论文一作匡正非,目前在南加州大学(University of Southern California)读博,导师是计算机图形学领域知名华人教授黎颢。
他本科毕业于清华计算机系,曾经在胡事民教授的计图团队中担任助理研究员。
这篇文章是他在Snap公司实习期间做出来的,其余作者全部来自Snap团队。

以后或许只需要几张网友“卖家秀”,就真能在家搞VR云试用了。

论文地址:
https://arxiv.org/abs/2201.02533
项目地址:
https://formyfamily.github.io/NeROIC/
参考链接:
[1]https://zhengfeikuang.com/
[2]https://ningding97.github.io/fewnerd/
[3]https://twitter.com/ben_ferns/status/1486705623186112520
[4]https://twitter.com/ak92501/status/1480353151748386824
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK