

面向B端算法实时业务支撑的工程实践
source link: https://www.51cto.com/article/700987.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

在营销场景下,算法同学会对广告主提供个性化的营销工具,帮助广告主更好的精细化营销,在可控成本内实现更好的ROI提升。我们在这一段时间支持了多个实时业务场景,比如出价策略的实时化预估、关键词批量服务同步、实时特征等场景,了解到业务侧同学来说,针对ODPS场景来说大部分可以灵活使用,但对于Blink使用还有不足,我们这里针对场景积累了一些经验,希望对大家有一些帮助。
二、 技术选型
为什么要选择Blink?大部分离线场景如果对于时效性没有要求,或者数据源是Batch模式的,非Streaming的(比如TT、SLS、SWIFT、顺序)等,这个场景的话选择ODPS就比较不错;总体来说,数据源是实时的(如TT/SLS/SWIFT)、需要顺序读取ODPS、对时效性要求高的场景,选择Blink是比较好的。
Blink目前也是支持Batch模式和Steaming模式。Batch模式是指有固定的起始时间和结束时间, 相比ODPS而来,他最大的优势是提前申请资源,可是独占的,这样可以保障时效性;Streaming模式就是传统意义上的实时消费,可实现毫秒级的处理。
从开发模式上看,主要分为Data Stream模式,类似于ODPS MR;第二种是SQL模式;从易用性角度看,SQL无疑是使用成本最低的;但对于复杂场景,Data Stream的掌控能力也是最好的,可灵活定义各类cache和数据结构,以及同时支持多类场景。
Datastream Batch
有固定起始时间和结束时间
提前申请资源
Datastream Streaming
更细粒度地控制实时计算作业
实时性较强,自定义source和sink
BlinkSQL Streaming
简单场景快速上手
使用成本低
批量作业开发
吞吐量较大
三 、主要场景
1. 实时replay出价策略评估
Replay系统是一套集线上竞价日志搜集、结构化、后续处理的模拟系统。该系统记录了直通车线上引擎在召回之后的竞价信息,主要涵盖了线上的召回、出价、打分等队列信息。结合排序以及扣费公式,可以利用该日志实现对线上竞价环境的模拟。简单来说,就是可以评估bidword上如果当时采用其他的出价,会带来什么样的结果。通过replay系统,算法团队和广告主可以在线上AB测试之前,利用离线流量预估用户策略修改之后带来的效果,这样可以尽可能地减少策略的修改带给线上的影响,让结果变得更加可控。同时在进行负向策略测试的过程中,可以尽可能地减少对大盘的收益影响。
算法团队希望基于在线精排召回日志实现业务侧多种出价策略评估,回放1天内采样日志(10亿数据),在出价策略上评估,并支持ad的实时下线,避免下线ad对出价策略有影响,并且预期希望10亿数据量在1-2个小时内跑完。
- 1千万物料数据如何加载;
- 高qps(100万)下线ad的实时同步;
- 业务侧解耦,整个实时job链路如何实现和业务解耦
物料数据加载:直接在blink启动时加载所有数据,避免高qps情况下,对igraph访问造成压力;另外采用广播模式,仅一次加载,每个节点都可以使用,避免多次加载odps数据;
下线的ad信息采用分桶的方式存入到IGraph中,并周期性cache方式全量读取全量下线ad,将查询的200W+qps控制在1w左右,并使用RateLimit限流组件控制访问并发,把IGraph并发控制限制在40万左右,实现整体流量平滑;
整体实时工程框架,预留UDF接口,让业务侧仅实现SDK即可,其他工程性能、并发、限流、埋点等逻辑内部实现即可,支持工程框架和算法策略Replay解耦。
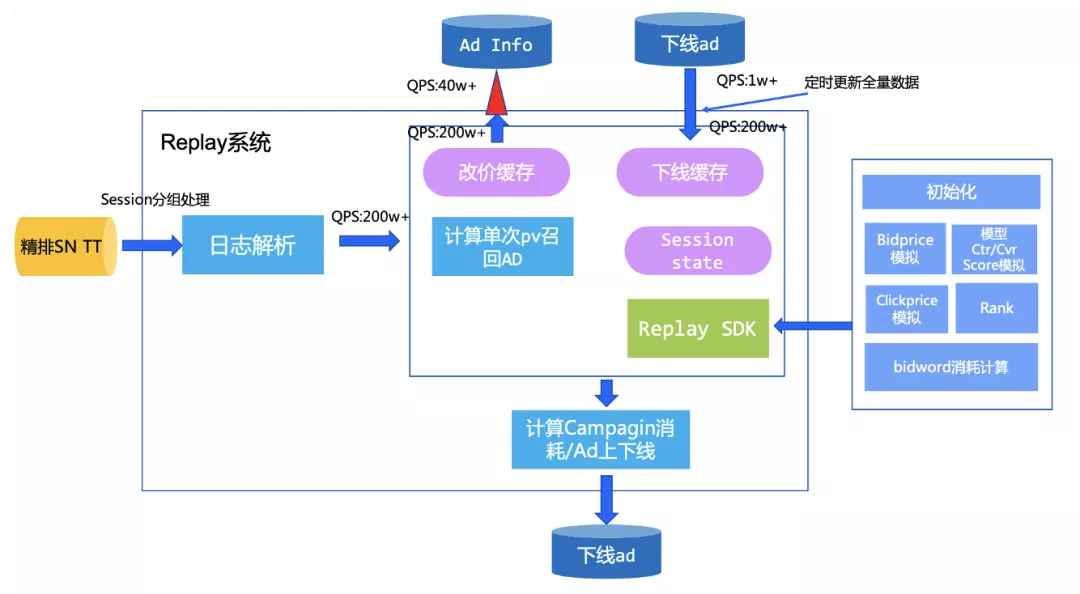
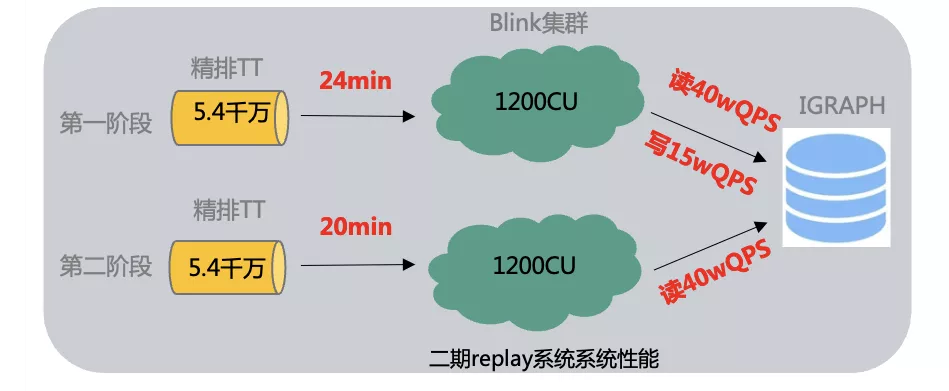
基于此业务需求,我们基于blink streaming Batch模式的灵活能力,实现了对tt数据固定开始和结束时间的数据处理。沉淀了读写tt组件 ,ODPS组件,iGraph组件和埋点组件 ,这些沉淀的组件很好地支持了后续相似业务的作业开发,同时组件作为之后作业产品化提供了基础能力。
2. 实时特征
随着B端算法发展,模型升级带来的增量红利越来越少,需要考虑从客户实时信息方面进一步捕捉用户意图,更全面、更实时的挖掘潜在需求,从B端视角进一步提升增长空间,基于线上用户行为日志产出用户行为实时特征,算法团队使用实时数据改进线上模型。
基于此需求我们产出一条用户实时特征产出链路,通过解析上游A+数据源获取用户实时特征,实时特征主要包含以下几种:
- 获取用户近50条特征数据值,并产出到igraph中。
- 输出具有某种特征的用户id,并按照分钟时间聚合
- 输出某种特征近1小时的和、均值或者数目
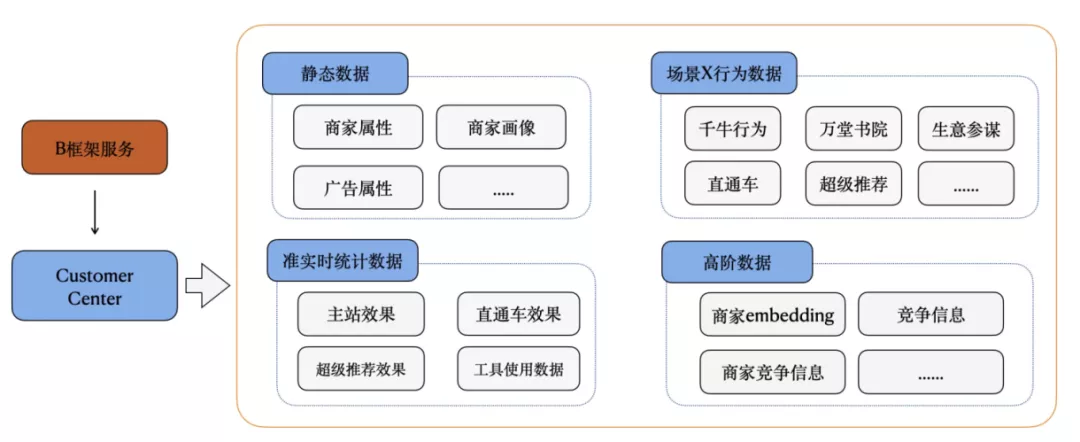
- 实时特征数据开发数量非常多,对于每个特征数据都需要开发实时数据链路、维护,开发成本、运维成本较高,重复造轮子;
- 特征数据开发要求开发者了解:
- 数据源头,会基于事实数据源进行ETL处理;
- 计算引擎,flink sql维护了一套自己的计算语义,需要学习了解并根据场景熟练使用;
- 存储引擎,实时数据开发好需要落地才能服务,故需要关系存储引擎选型,例如igraph、hbase、hologres等;
- 查询优化方法,不同存储引擎都有自己的查询客户端、使用及优化方法,故要学习不同引擎使用方法。
从产品设计角度,设计一套实时平台能力,让开发实时特征跟在odps开发离线表一样简单。产品优势是让用户只需要懂SQL就可以开发实时特征:
- 不需要了解实时数据源
- 不需要了解底层存储引擎
- 只用sql就可以查询实时特征数据,不需要学习不同引擎查询方法
整个实时开发产品联动极光平台、dolphin引擎、blink引擎和存储引擎,把整个流程串联打通,给用户提供端到端的开发体验,无需感知跟自己工作无关的技术细节。
相关平台介绍:
Dolphin智能加速分析引擎:Dolphin智能加速分析引擎源自阿里妈妈数据营销平台达摩盘(DMP)场景,在通用OLAP MPP计算框架的基础上,针对营销场景的典型计算(标签圈人,洞察分析)等,进行了大量存储、索引和计算算子级别的性能优化,实现了在计算性能,存储成本,稳定性等各个方面的大幅度的提升。Dolphin本身定位是加速引擎,数据存储和计算算子依赖于底层的odps, hologres等引擎。通过插件形式,在hologres中,完成了算子集成和底层数据存储和索引的优化,实现了特定计算场景计算性能和支撑业务规模的数量级的提升。目前Dolphin的核心计算能力主要包括:基数计算内核,近似计算内核,向量计算内核,SQL结果物化及跨DB访问等。Dolphin同时实现了一套SQL转译和优化能力,自动将原始用户输入SQL,转化成底层优化的存储格式和计算算子。用户使用,不需要关心底层数据存储和计算模式,只需要按照原始数据表拼写SQL,极大的提升了用户使用的便利性。
极光消费者运营平台:极光是面向营销加速场景的一站式研发平台,通过平台产品化的方式,可以让特色引擎能力更好赋能用户。极光支持的特色场景包含超大规模标签交并差(百亿级标签圈选毫秒级产出)、人群洞察(上千亿规模秒级查询)、秒级效果归因(事件分析、归因分析)、实时和百万级人群定向等能力。极光在营销数据引擎的基础上提供了一站式的运维管控、数据治理以及自助接入等能力,让用户使用更加便捷;极光沉淀了搜推广常用的数据引擎模板,包含基数计算模板、报表模板、归因模板、人群洞察模板、向量计算模板、近似计算模板、实时投放模板等,基于成熟的业务模板,让用户可以零成本、无代码的使用。
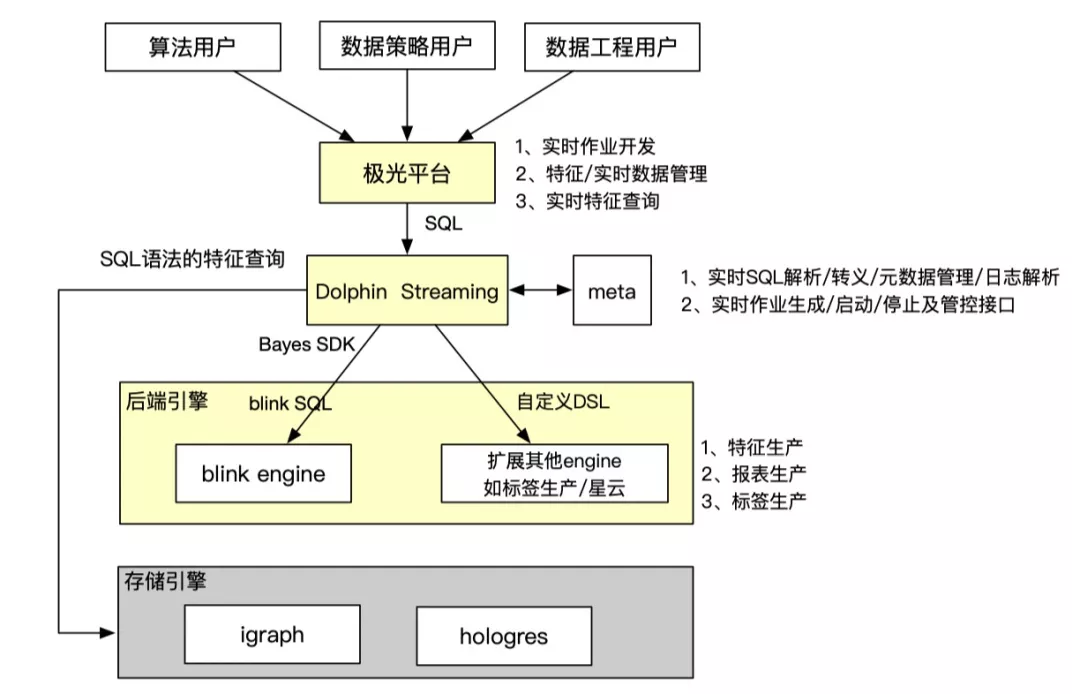
根据目前的业务需求,封装了实时数据源和存储数据源使用举例:
--- 注册输入表
create table if not exists source_table_name(
user_id String comment '',
click String comment '',
item_id String comment '',
behavior_time String comment ''
) with (
bizType='tt',
topic='topic',
pk='user_id',
timeColumn='behavior_time'
);
---- 创建输出表
create table if not exists output_table_name (
user_id STRING
click STRING
) with (
bizType='feature',
pk='user_id'
);
实现实时特征算子:
concat_id:
- 含义:从输入表输入的记录中,选取1个字段,按照timestamps倒序排成序列,可以配置参数按照id和timestamp去重,支持用户取top k个数据
使用举例:
-- 用户最近点击的50个商品id
insert into table ${output_table_name}
select nickname,
concat_id(true, item_id, behavior_time, 50) as rt_click_item_seq
from ${source_table}
group by user_id;
-- 1分钟内最近有特征行为用户id列表
insert into table ${output_table_name}
select window_start(behavior_time) as time_id,
concat_id(true, user_id) as user_id_list
from ${source_table}
group by window_time(behavior_time, '1 MINUTE');
sum、avg、count:
- 含义:从输入表输入的记录中,选取1个字段,对指定的时间范围进行求和、求平均值或计数
-- 每小时的点击数和曝光数
insert into table ${output_table_name}
select
user_id,
window_start(behavior_time) as time_id,
sum(pv) as pv,
sum(click) as click
from ${source_table}
group by user_id,window_time(behavior_time, '1 HOUR');
基于B端算法的实时特征需求,沉淀了一套基于blink sql + udf实现的实时特征产出系统,对用户输入的sql进行转义,在Bayes平台生成bink SQL Streaming任务,产出实时特征数据存入iGraph当中,沉淀了blink 写入igraph组件,concat_id算子、聚合算子等基础能力,为后续Dolphin streaming 实时特征产出系统打下了基础,支持后续多种特征算子扩展方式,快速支持此类用户需求。
3. 关键词批量同步
每天有很多商家通过不同渠道加入直通车;而在对新客承接方面存在比较大的空间。另一方面,对于系统的存量客户的低活部分也有较大的优化空间。系统买词作为新客承接、低活促活的一个重要抓手,希望通过对直通车新客和低活客户进行更高频率的关键词更新(天级->小时级),帮助目标客户的广告尝试更多关键词,存优汰劣,达到促活的目标。
基于此需求,我们在现有天级别离线链路的基础上补充小时级的消息更新链路,用来支持标准计划下各词包、以及智能计划的系统词更新,每小时消息更新量在千万量级,使用Blink将全量ODPS请求参数调用faas的函数服务,将每条请求的结果写入到ODPS的输出表中。更新频率在两个小时,更新时间:早8点到晚22点,单次增删规模:增500W/删500W。
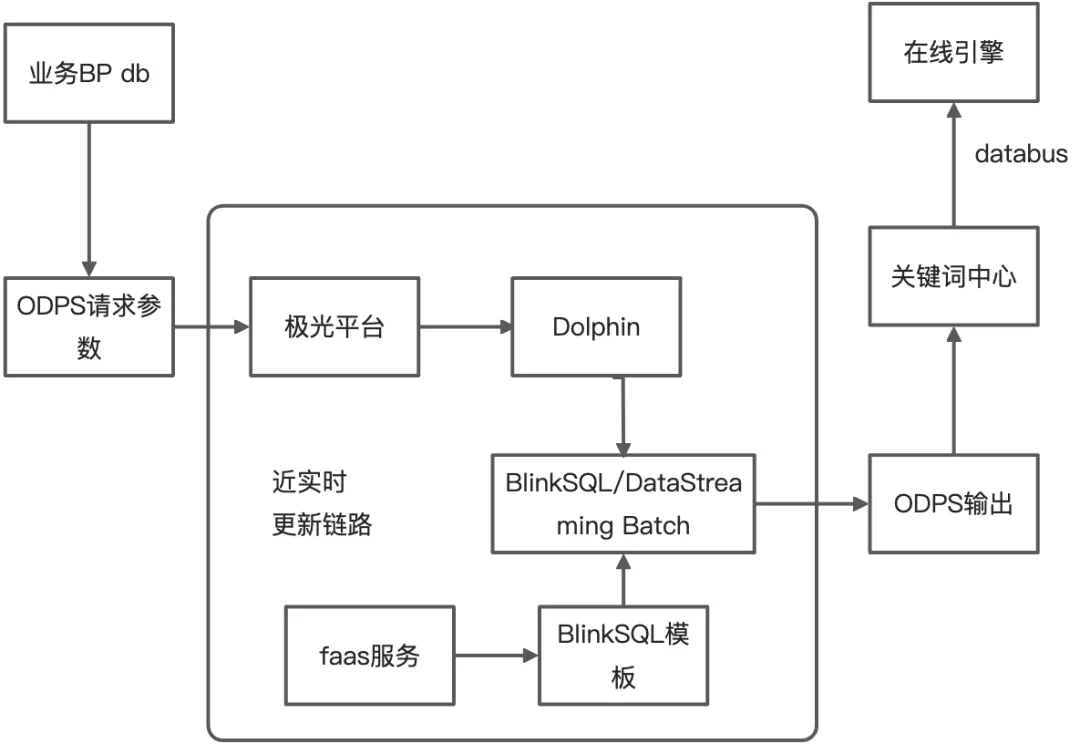
- blink批处理作业需要进行小时级调度
- faas函数调用需要限流
- 使用Blink UDF实现对request请求调用HSF的函数服务功能
- blink UDF使用RateLimiter进行限流,访问函数服务的QPS可以严格被节点并行度进行控制
- 在Dataworks平台配置shell脚本,进行Bayes平台批计算任务调度
基于此需求,使用blink sql batch模式实现了近实时的此类更新链路,打通了此类批处理作业的调度模式,为后续批作业产品化打下了基础。
四、 未来展望
基于B端算法的业务,Dolphin引擎目前已经设计开发了Dolphin streaming链路,用户在极光平台开发实时特征变得跟在odps开发离线表一样简单,用户无需了解实时数据源、底层存储引擎,只需要用sql就可以查询实时特征数据。但是B端算法业务中还有类似于本文中提到的批处理业务,这些业务需要开发blink batch sql、blink streaming batch模式、ODPS UDF和java code任务,并且提供调度脚本,最后将项目进行封装提交给算法团队进行使用。未来我们希望用户能够在极光平台自助开发批量计算业务,降低算法同学开发成本,提供一个可扩展、低成本的批计算引擎能力,支持业务快速迭代,赋能业务落地快速拿到结果。
- 对flink比较感兴趣或者是初步接触flink的同学可以参考以下内容进行一个初步学习:
- Flink官方博客:https://flink.apache.org/blog/
- Flink Architecture:https://flink.apache.org/flink-architecture.html
- Flink技术专栏:https://blog.csdn.net/yanghua_kobe/category_6170573.html
- Flink源码分析:https://medium.com/@wangwei09310931/flink-%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90-streamexecutionenvironment-4c1cd9695680
- Flink基本组件和逻辑计划:http://chenyuzhao.me/2016/12/03/Flink%E5%9F%BA%E6%9C%AC%E7%BB%84%E4%BB%B6%E5%92%8C%E9%80%BB%E8%BE%91%E8%AE%A1%E5%88%92/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK