

从0到1剖析并编码实现短链系统
source link: https://developer.51cto.com/article/701051.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


短链很常见,在互联网营销场景以及移动端信息传播等场景下起着重要的作用。同时,也是经常被来拿考察选手系统设计水平的一个场景。
对于服务端研发,关于前端访问时的长短转换,其实只要知道有30X重定向基本也就可以了。
相较于重定向,我更关注的,是短链生成方式选型、存储选型、系统性能应对等方面的方案和设计。
Part one 短链系统分析
短链系统的最根本能力:
是可以根据长链计算得到短链,以方便外部访问:
- 判断对应短链已存在,则直接返回
- 判断对应短链不存在,则生成短链,并存储 长链->短链 的映射关系
也可以根据短链映射到长链,寻找真实服务地址提供服务:
- 根据短链->长链 查询存储,获取对应的长链
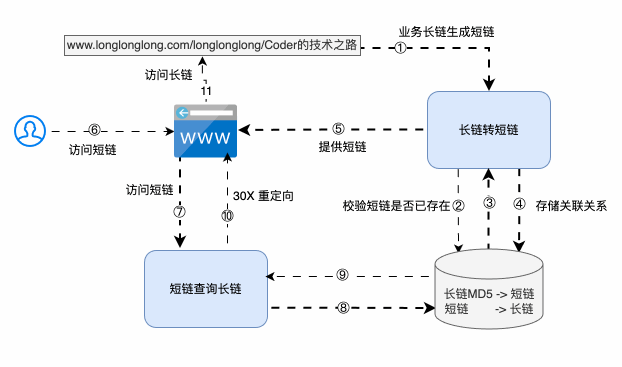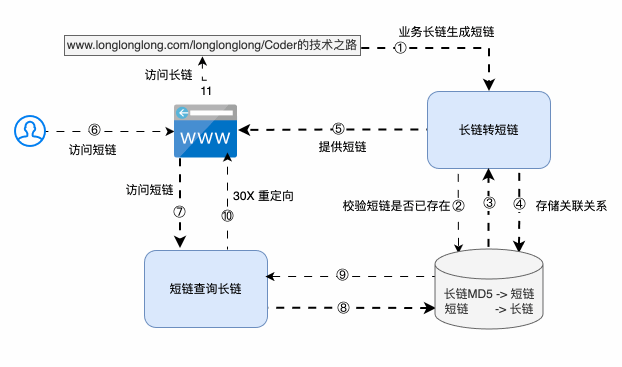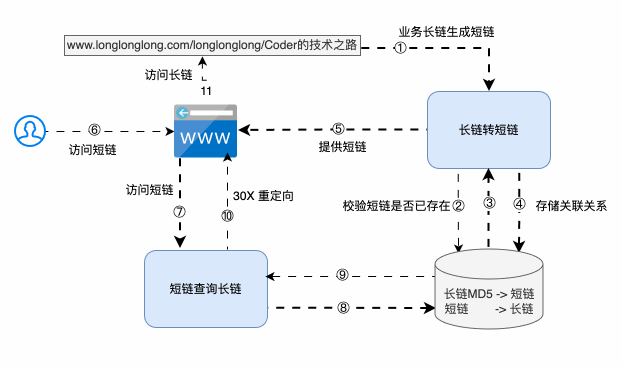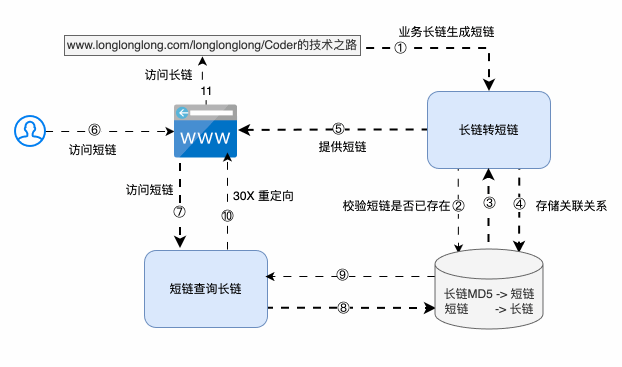
条条大路通罗马,系统方案有很多,但采取哪种最合适,还需要和存储策略以及访问性能联合起来一起看~
Part two 实现方案分析
Hash是最容易想到的实现策略之一,那么,Hash方式有哪些优缺点,我们又该怎么改进呢?
Hash策略关键点解析
首先,如果用hash方式来生成短链,那么短链是没法通过hash码反解出长链的,因此,必须存储短链和长链的关联关系;
其次,长链的长度一般又很长,不便于索引的构建,需要再生成一个长链的固定唯一短串来辅助存储和查询。( 如32位MD5压缩,加密算法一般不利于压缩,而压缩算法一般不可逆);
再次,hash难免会有冲突,需要对原始长链尾部拼接一个或多个固定串来消除冲突,因此,在访问长链时同样需要裁剪固定串。
Hash策略的存储设计
如果用mysql进行结构化存储比较简单:
id | 短链 | 长链MD5 | 长链 | 时间戳
并且需要给 短链 和 长链MD5 构建索引,供查询时使用。
- 优点是结构化查询、结构清晰,可以设置索引提升效率;
- 缺点是高并发下性能需要额外关注,保存的数据要过期,理论上得进行额外处理;
如果用redis等非结构化kv存储,则需要存储多个关系用于查询:
长链MD5 -> 短链 |
短链 -> 长链MD5 |
长链MD5 -> 长链
- 优点是查询性能高,可以抗量,且自带过期机制;
- 缺点是需要维护多个KV关系,稍显繁琐。
改进-- 自增ID+高位进制法
如果说长链的MD5标识的生成和存储是不可缺少的,那么,可优化的点,就只能从短链 -> 长链MD5的转化这里来下手了。
有没有办法既可以省掉短链 -> 长链MD5的存储呢?
如果我们让唯一标识和短链之间可以通过计算相互编码解码,是不是就可以了!?既省了一部分存储,而且也省掉了查询存储的时间耗时,本地简单计算总归要比查询外部存储要快的多。
经常使用进制转换,可以知道,进制越高所占位数越少。
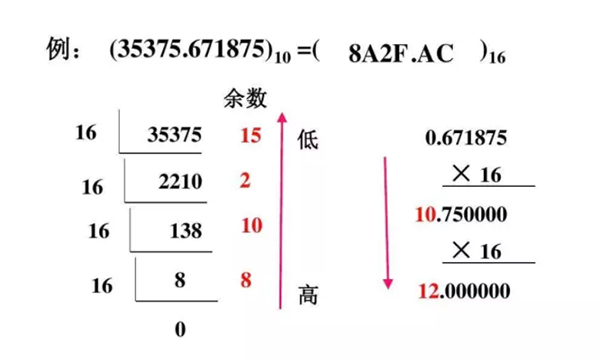
16进制转换示例
这个时候,用MD5应该就不太合适了,不好参与计算,因此,我们改用纯数字的分布式ID来代替MD5串(一般公司应该都有现成的分布式ID生成服务吧)。
利用进制转换虽然可以很方便编码成短链,但有时候,我们不希望出现 短链被轻松解码,导致服务端可被遍历,因此,需要考虑对进制转换进行加密处理。
编码实现带加密的进制转换
首先,需要选择高位进制:我们启用 0-9 a-z A-Z 全部的数字和字母,一共62位,即支持62进制转换
private static final String DIGITAL_STRING = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
//byte数组
private static final byte[] DIGITAL;
static {
DIGITAL = DIGITAL_STRING.getBytes(StandardCharsets.US_ASCII);
}从10进制向62进制转换的编码实现:
public static String encode(long 分布式id) {
//内部复制
long value = id;
//创建短链所需长度的空间,这里可以限制短链长度为最多12位,最少6位
ByteBuffer buf = ByteBuffer.allocate(12);
//最多执行12次转换
for (int i = 0; i < 12; i++) {
//分布式ID对62取模
int mod = (int) (value % 62);
//加密, 再取模
int pos = (mod + (OFFSET << i)) % 62;
//根据模值从数组中获取对应的值,加入结果集中
buf.put(DIGITAL[pos]);
//求余数,用余数继续参加后续模操作,直到余数为0 或 短链长度达到要求
value = value / 62;
if (value==0 && i >= 6) {
break;
}
}
//从ByteBuffer中获取结果集合
byte[] result=new byte[buf.position()];
buf.rewind();
buf.get(result);
//反转顺序
ArrayUtils.reverse(result);
return new String(result);}重点关注(mod + (OFFSET << i)) % 62 这个操作,其目的是在模值上加上一个偏移量(偏移大小和所处位置有关,非固定偏移) ,用来防止被直接解码。
//将短链串解码为分布式ID
public static long decode(String code) {
long value = 0;
byte[] buf = code.getBytes();
int length = buf.length;
//循环次数为短链字符串长度
for (int i = 0; i < length; i++) {
byte digital = buf[i];
//当前字符对应的下标
int index = Arrays.binarySearch(DIGITAL, digital);
//当前下标需要减掉加密时增加的部分(同样和所处位置有关)
index = index - (OFFSET << (length - i - 1));
//因为减掉的有可能是一个非常大的值,再把index对62取余,如果任然小于0 ,就加上62(62进制内负变正)
index = index % 62;
if (index < 0) {
index = index + 62;
}
//10进制复原原值
value = value * 62 + index;
}
return value;
}Part three 总结
每一种技术方案,都是通过不断论证和尝试才可以最终决定的。我们在学习一个技术架构时,最好可以从它的发展历程,每个瓶颈点的解决来进行整体把握,会对我们处理问题时候的入手角度和思考方式的锻炼起到很好的作用。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK