

Apache SeaTunnel 进 ASF 孵化,众多数据源如何集成在一个平台?
source link: https://www.oschina.net/question/4489239_2324982
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Apache SeaTunnel 进 ASF 孵化,众多数据源如何集成在一个平台?
中国开源正在崛起,2021 年进入 Apache 孵化器的 5 个项目全部来自中国,深信开源未来十年看中国!在这里也呼唤有志于立足中国,贡献全球的伙伴加入到开源贡献大潮流里来,让自己贡献的代码能运行在数以百万计的电脑上,让自己的青春留下开源的印记!开源有你更精彩!
“If not you,who? if not now, when?”
—— 代立冬
近日, Apache SeaTunnel 成功进入 Apache 孵化器,成为 Apache 基金会中第一个诞生自中国的数据集成平台项目。
Apache SeaTunnel 是一个易用、高性能且支持实时流式和离线批处理的海量数据集成平台,是架构于 Apache Spark/Flink 之上的支持海量数据的实时同步与转换项目,于 2017 年开始研发,并在同年开源,曾用名 Waterdrop。
随着互联网流量爆发式增长,越来越多的公司业务需要支撑海量数据存储,对高并发、高可用、高可扩展性等特性提出了更高的要求,这促使各种类型的数据库快速发展,至今常见数据库已经达到 200 多个。
与之相伴的便是,各种数据库之间的同步与转换需求激增,数据集成便成了大数据领域的一个亟需优秀解决方案的方向。
Apache SeaTunnel 的导师数量也印证了业界对于数据集成平台的期盼。Apache 基金会中,一个项目通常拥有 3 名导师,而 Apache SeaTunnel 吸引了不少导师报名希望能参与指导 Apache SeaTunnel 的孵化,最终项目敲定了 7 名导师。
目前 Apache SeaTunnel 已经在腾讯云、B 站、360、滴滴、移动、去哪儿等近百家公司在生产上使用 Apache SeaTunnel 做海量数据的同步与集成平台,其中 B 站每日稳定同步数据超过 1000 亿条。为了进一步了解 Apache SeaTunnel 项目情况,OSCHINA 邀请到 Apache SeaTunnel 的导师之一——代立冬做客“开源访谈”,为大家详细介绍 Apache SeaTunnel 所做的事情与孵化情况。
伙伴们好,我是代立冬,白鲸开源联合创始人、Apache DolphinScheduler PMC Chair & Apache Apache SeaTunnel PPMC & Apache 孵化器导师、Apache Local Community Beijing 成员,作为 Apache 孵化器导师,也在帮助孵化微众主导的 Linkis 项目,帮助百度主导的 HugeGraph 加入孵化,推崇开源文化,多年来一直推广 Apache 成功之道,致力于让开源文化更好的在中国开发者群体传播。

Apache SeaTunnel 项目地址:
https://www.oschina.net/p/seatunnel
Proposal:
https://cwiki.apache.org/confluence/display/INCUBATOR/SeaTunnelProposal
何为 Apache SeaTunnel 数据集成平台?
数据集成平台要围绕解决海量数据同步这一目标进行,核心理念是保持海量数据能快速同步的同时还能保持数据的一致性,具体到 Apache SeaTunnel 来说,Apache SeaTunnel 具有以下核心特性:
1、高扩展性:模块化和插件化,支持热插拔, 带来更好的扩展性;
2、插件丰富:内置丰富插件,支持各种数据产品的传输和集成;
3、成熟稳定:经历大规模生产环境使用和海量数据的检验;
4、支持通过 SQL 进行数据处理和聚合;
5、简单易用:特有的架构设计,使得开发配置简单,无使用成本。
Apache SeaTunnel 社区在过去几年里,已经迭代升级了 38 个版本,现在也在努力为发布第一个 Apache 版本而努力,Apache 对发版要求极高,尤其是 license 梳理方面工作量非常大。
Apache SeaTunnel 发展上整体上有 2 个大版本,1.x 版本是基于 Spark 构建的,现在在打造的 2.x 是既支持 Spark 又支持 Flink。在架构设计上,Apache SeaTunnel 参考了 Presto 的 SPI 化思想,有很好的插件化体系设计。
在技术选型时,Apache SeaTunnel 主要考虑技术成熟度和社区活跃性。Spark、Flink 都是非常优秀并且流行的大数据计算框架,所以 1.x 版本选了 Spark,2.x 版本将架构设计的更具扩展性,用户可以选择 Spark 或 Flink 集群来做 Apache SeaTunnel 的计算层,当然架构扩展性的考虑也是为以后支持更多引擎准备,说不定已经有某个更先进的计算引擎在路上,也说不定 Apache SeaTunnel 社区自己会实现一个为数据同步量身打造的引擎。
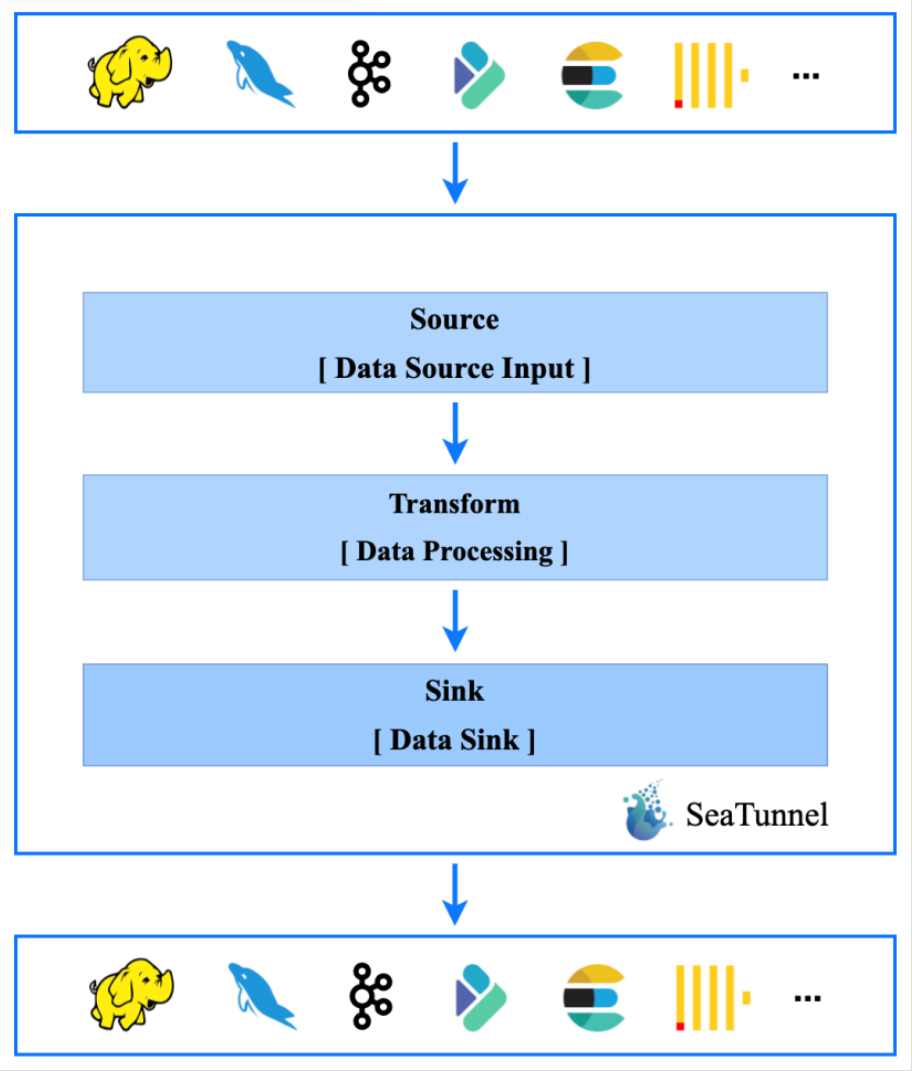
想做完整的集成平台,只有开源才可以
Q:为什么创建同年就快速选择了开源?
代立冬:
每个程序员心里都有一颗 “Show you my code” 的开源心,当年也为了减少大家上手 Spark 的难度,大家知道 Spark 是 Scala 写的,有一定的上手门槛,Apache SeaTunnel 提供了非常简单易用的配置化方式来实现用户不需写 Scala 就能使用上 Spark 。当然因为数据集成项目需要支持众多数据源(库),整体上大概有 200 多种,这是多么庞大的工程量,想要做到又快又好的完成一个完整的集成平台,只有开源集结成百上千的贡献者才可以做得到。
Q:Apache SeaTunnel 目前能支持多少种数据库?有计划把 200 多种全囊括进来吗?
代立冬:
目前能支持的数据源有 20 多种,像 S3、InfluxDB、Kafka、Clickhouse、Doris、HBase、Hudi、Kudu、MongoDB、Neo4j、Phoenix、Redis、Tidb、Alluxio、ElasticSearch、Hdfs、Hive、MySQL、File、Stdout 等,会尽力的去支撑更多的数据源的,最终支撑多少个这个要看社区贡献者意愿。
Q:在聚集了一众大数据领域优秀开源项目的 ASF 中,Apache SeaTunnel 为何还能俘获 7 位 Mentors 的“芳心”?
代立冬:
还是因为数据集成平台是大数据领域的一个尚未有很好解决方案的痛点,大家都很关注吧。
Q:投票进孵化器时,Mentors “竞争上岗”过程中有没有什么趣事可以分享一下?7 位 Mentors 现在如何分工?
代立冬:
其实也没有到竞争上岗的地步哈,就是在投票中,有不少对项目感兴趣的孵化器导师想要指导 Apache SeaTunnel 发展在投票邮件列表里留了言,最后 Apache 孵化器负责人 Justin 发邮件提醒导师不能过多,然后在邮件列表中就出现了有导师戏言:“Apache 项目真是旱的旱死,涝的涝死”。 Mentor 们其实也没有啥明确分工,重要的是提各种建议和解决方案,定期看看项目发展情况是否符合 Apache Way 是 mentor 们最关注的事情!
Q:Apache SeaTunnel 不仅基于 Spark、Flink,也支持 Doris、 ElasticSearch 集成,可以说和大数据领域的许多开源项目都有深度合作,那么您怎么看待这种同一领域下的开源项目间的合作?益处是什么?又是否会影响到项目本身的商业化?
代立冬:
首先数据集成平台天然和各大数据社区是协同发展、非常友好的合作伙伴,Apache SeaTunnel 设计有很好的插件体系,除了列的几个社区外,我们也在支持 Clickhouse、Kudu、Hudi、Druid、Redis、Tidb、Hive、Kafka、MongoDB、Mysql 及 文件 和 Socket 等,也欢迎更多的社区来交流合作。
各个社区强强联合比单个社区更有力量,因为数据同步与转换是痛点和刚需,各个社区不仅自己需要数据同步,也需要支持别的数据源同步到自己的平台或者自己平台的数据需要导出到别的平台去,尤其是不同的数据库,我们做了的话,大家就可以集中精力做自己数据库更核心的建设。
对项目本身的商业化基本没有影响的,大家选择一个数据(库)引擎的核心考虑还是这个引擎是否解决了我的痛点问题,对引擎来说,数据导入和导出不是核心能力,比如 OLAP 引擎来说,最核心的痛点是解决尽量多场景下的又快又稳,这也是 Clickhouse 当年成为一匹黑马的重要原因,他的追求是 ”fast,faster,fucking fast“,快就是他最显著的特点,也是大家选择它的最重要原因,当然也不排除以后会有更快的引擎。
作为引擎方,解决最核心的几个问题远比怎么做数据导来导去要重要的多的多,我认为做商业专注于解决最核心的 2、3 个问题足矣,在最核心的问题上自己是不是最佳方案才是最值得花精力、下功夫去打磨的。
Q:和其他数据集成平台相比,Apache SeaTunnel 有什么优势?
代立冬:
我认为能持续发展的数据集成平台很少,这也是我们为什么选择开源和加入 Apache 孵化器的重要原因。
大数据发展了这么多年,有 200 多种数据源,很多数据源已经有十多年的发展历史,每个数据源的各个版本还不一定兼容,数据集成平台要支持这么多数据源注定是一个苦活,在架构上肯定要有非常好的可扩展性设计来支持每个插件的多个版本,当然选择 Apache SeaTunnel 也意味着更简单的使用,因为 Apache SeaTunnel 通过配置的方式屏蔽了底层的复杂性,早年大家选择 Apache SeaTunnel 的一个重要原因也是他不用学习 Scala 就可以玩 Spark。
总结下就是选择开源基本是数据集成平台能长期健康发展的必然选择!
Q:Apache SeaTunnel 已经在众多大型互联网公司中使用,可以分享下开源项目的推广经验吗?
代立冬:
开源项目首先需要有一个好的定位,最好是专而精,比如 Apache SeaTunnel 就是解决数据集成问题的,当然像 Apache SeaTunnel 已经有一定的用户基础了,有些开源项目如果是从 0 起步的,那首先需要找到几个愿意尝试的种子用户,“汤匙喂食”式的想尽办法让这些种子用户用上给出反馈,然后改进,然后再反馈到改进,迭代 2、3 轮,项目的 MVP 算是闭环了,然后就可以通过 Meetup 或者跟一些发展好的开源社区进行联合 Meetup, 扩大自己项目的受众面,找到更多的用户;其次就是找到贡献者,只有用户,这项目是不能可持续发展的,找到用户和贡献者的方式可以是写文章也可以发视频等多种方式;最后做开源是要有一颗坚持的心,很多开源项目需要开源 2、3 年的时候才显示巨大的发展势能,所以一定要坚持,耐得住寂寞。
Q:总结来看,什么样的场景下或是技术栈中,比较适合使用 Apache SeaTunnel ?
代立冬:
所有需要用到数据同步或转换的场景都是 Apache SeaTunnel 的适用范围,比如 Hive 数据同步到 Clickhouse 等等各种数据源之间的同步。这是一个刚需场景,做数据的应该都避不开。
Q:Apache SeaTunnel 接下来在社区和项目上分别有什么计划?有商业化方面的规划吗?
代立冬:
Apache SeaTunnel 正在研发进入 Apache 后的第一个大版本,比如要支持 Flink 的最新版本,要支持更多的数据源 Connector 并提高数据一致性和可靠性及可观测性,具体请参见 Roadmap:https://github.com/orgs/apache/projects/28
Q:Apache SeaTunnel 属于大数据的一部分,您对于大数据技术趋势怎么看?
代立冬:
我观察下以下几个趋势:
1、大数据在朝着云原生的趋势发展,先前大家的任务是跑在 Yarn 上,未来会有更多的任务跑在 K8s 、跑在云上,未来的数据架构将要面向云原生架构设计,比如要考虑云提供的自动伸缩能力等。
2、随着数据存储的复杂性和灾备性考量,跨云、多云也将是趋势。
3、DataOps 也是呈现出来的一个大数据趋势,像 DolphinScheduler 和 Apache SeaTunnel 就属于 DataOps 领域,包含整个数据处理全链路的处理与治理。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK