

一次压缩引发堆外内存过高的教训
source link: https://my.oschina.net/PerfMa/blog/4590873
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本文来自: PerfMa技术社区
一、项目介绍
lz_rec_push_kafka_consume 该项目通过kafka与算法进行交互,通过push推荐平台(lz_rec_push_platform)预生成消息体。
二、问题背景
发现项目的k8s容器会出现重启现象,重启时间刚好是push扩量,每小时push数据量扩大5倍左右。 发生问题时,容器配置:CPU:4个,内存:堆内3G,堆外1G。
三、问题排查流程:望-闻-问-切
望:查看监控系统,观察重启发生时,容器实例的资源情况
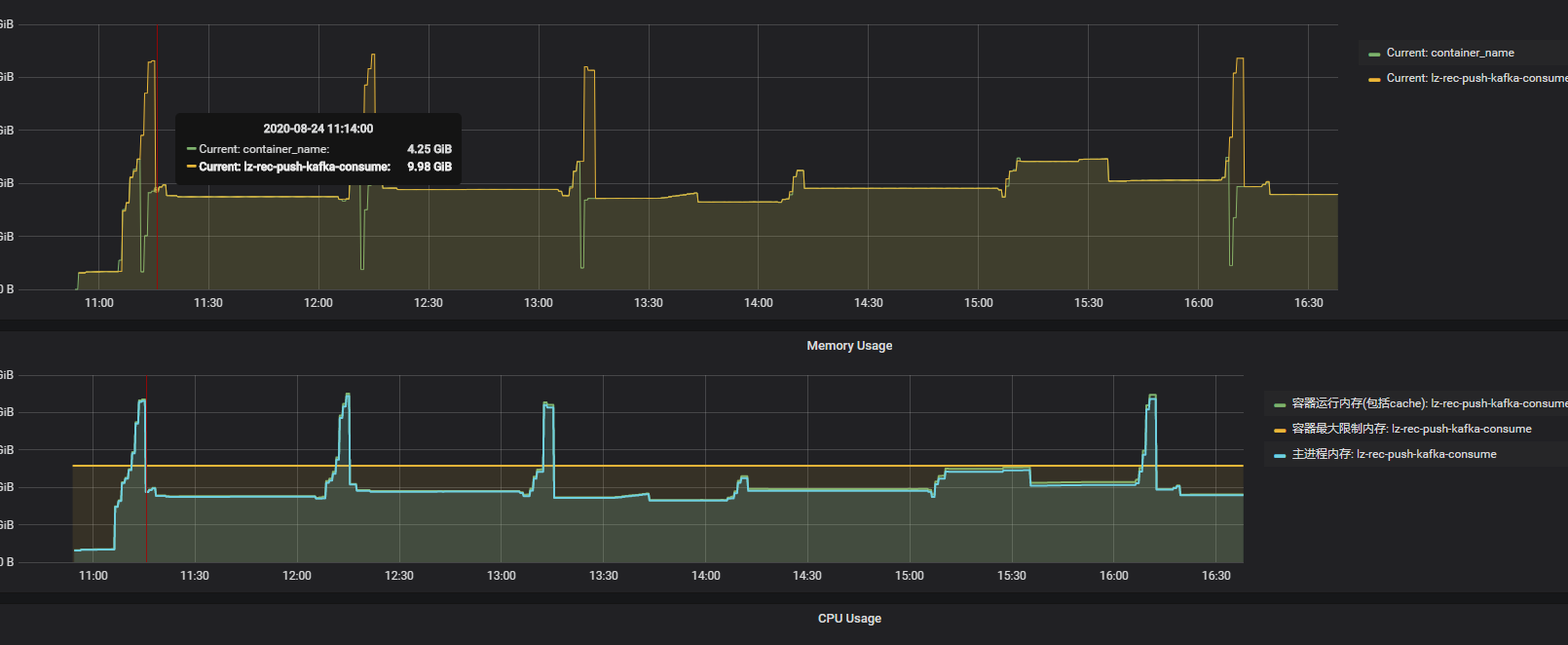

闻:检查项目的健康情况:线程、堆内内存使用、堆外内存使用。
-
通过jstack、jstat二连,查看项目线程情况及垃圾回收情况,无线程突增情况,无fullGC及频繁youngGC情况。
-
通过top命令发现res使用比jstat命令显示的堆大小大许多(忘了保留现场了),此时怀疑是堆外内存泄漏导致的。为了确定是堆外泄漏而非堆内,分析GC日志文件。
- 借助easygc对GC日志进行分析:无fullGC情况(图中四次fullGC为手动触发测试的:jmap -histo:live ),且每次youngGC能正常回收对象。
- 借助easygc对GC日志进行分析:无fullGC情况(图中四次fullGC为手动触发测试的:jmap -histo:live ),且每次youngGC能正常回收对象。
-
修改启动脚本,将-Xmx参数和-Xms参数置为4G,且增加dump堆参数(-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/logs/ ),如果堆内发生oom则能拿到我们心心念念的堆文件进行分析。 但是事与愿违,容器多次发生重启的时候,并没有发生项目堆内oom,也就是说,并没有dump下堆现场。此时更加确定,应该是堆外内存泄漏。
-
配置堆外参数:-XX:MaxDirectMemorySize 用于限制堆外内存的使用,但是实例的内存使用还是膨胀到11G。网上的小伙伴都说这个参数可以用来限制堆外内存使用,难道是我没用好。原本是想用这个参数来触发堆外内存不足的错误,好验证堆外内存泄漏这个方向。 既然这个方向走不通,那就扩大堆外看看是否堆外的泄漏能否回收,还是永久泄漏。
-
堆外内存泄漏一般由堆内对象引用(最常见由NIO引起,但是这次NIO表示不背锅),且堆内引用无法被回收引起的(我猜的)。通过第四点图,自然情况下的youngGC或者手动触发fullGC后,垃圾回收都能试堆回到正常水平。此处判断,泄漏的内存由可回收的引用所值向。 那么问题来了,该部分引用在垃圾回收前就已经大量堆积,导致堆外内存空间不足,触发k8s容器被kill。我猜的,接下来验证这个想法。
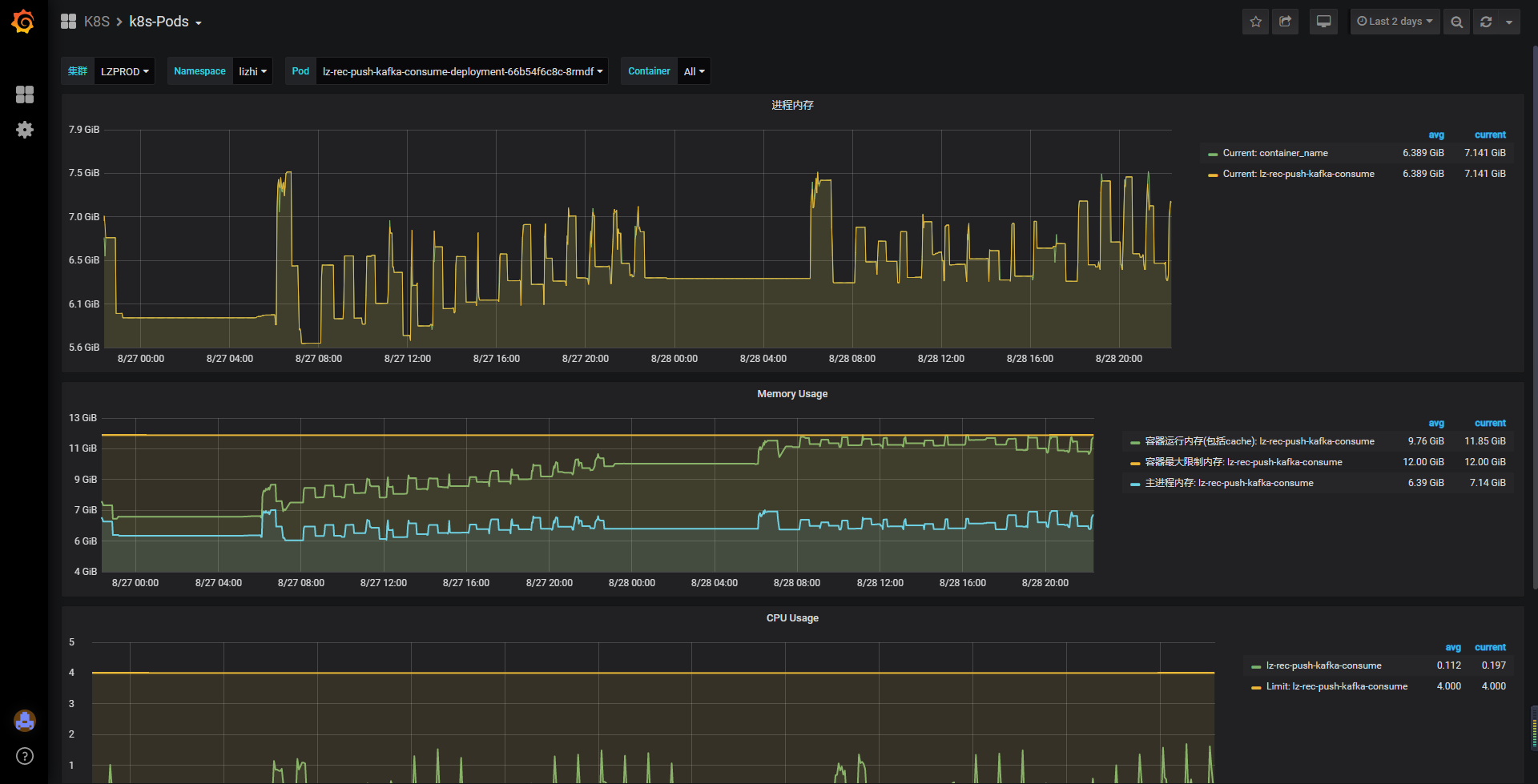
- 让运维大佬将k8s实例调整到12G,因为每次重启时,容器的内存占用几乎稳定在11g左右。(好吧其实是运维大佬看容器一直重启,主动要求扩容协助排查,赞一个)
- 将堆内内存限制在7G,堆内使用6G,留给堆外尽可能大的空间。
-
实例内存调整后,项目的三个实例在持续运行两天过程中,没有再出现重启情况,且每次“预生成数据”后内存能正常回收。由此确定,泄漏的堆外内存是可回收的,而非永久泄漏,且在堆内引用被回收后即可完成回收。
-
上图为k8s实例资源监控图,仅能体现容器资源情况,而非容器内项目的堆情况,该图只能证明堆外内存能正常回收,而不是永久泄漏。既然不再重启了,那么问题解决了,搞定走人?天真,一个节点12G,没必要的浪费,运维大佬会杀人祭天的。 通过jstat命令可观察,且GC日志可以得出,堆内存使用基本可稳定在4G以内,没必要浪费12G的空间。
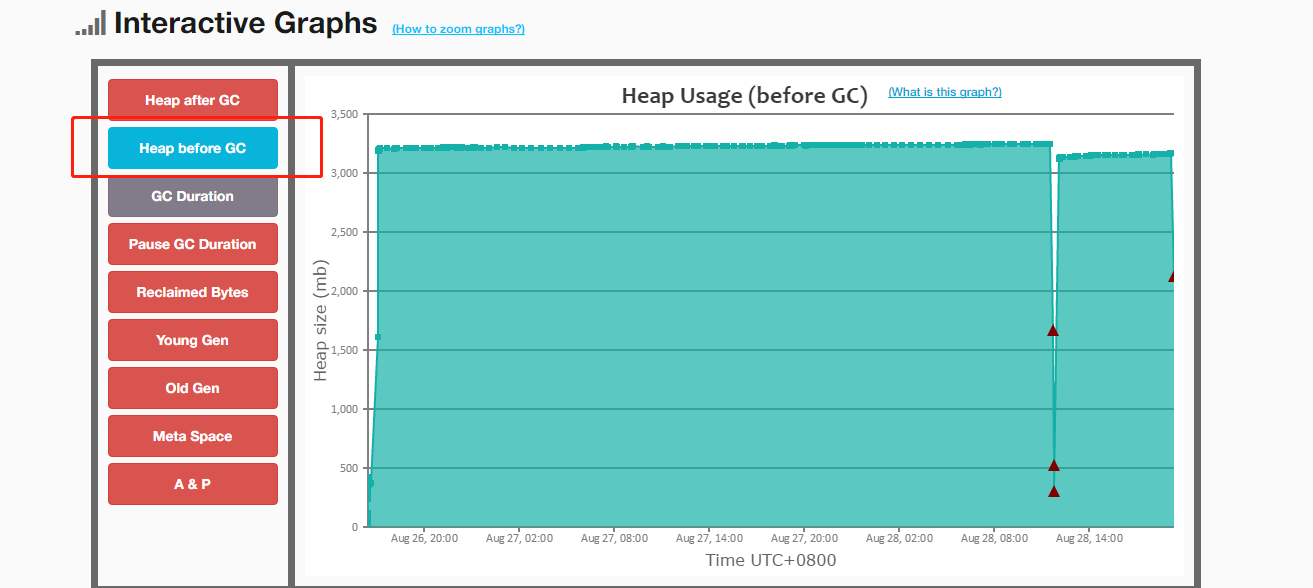
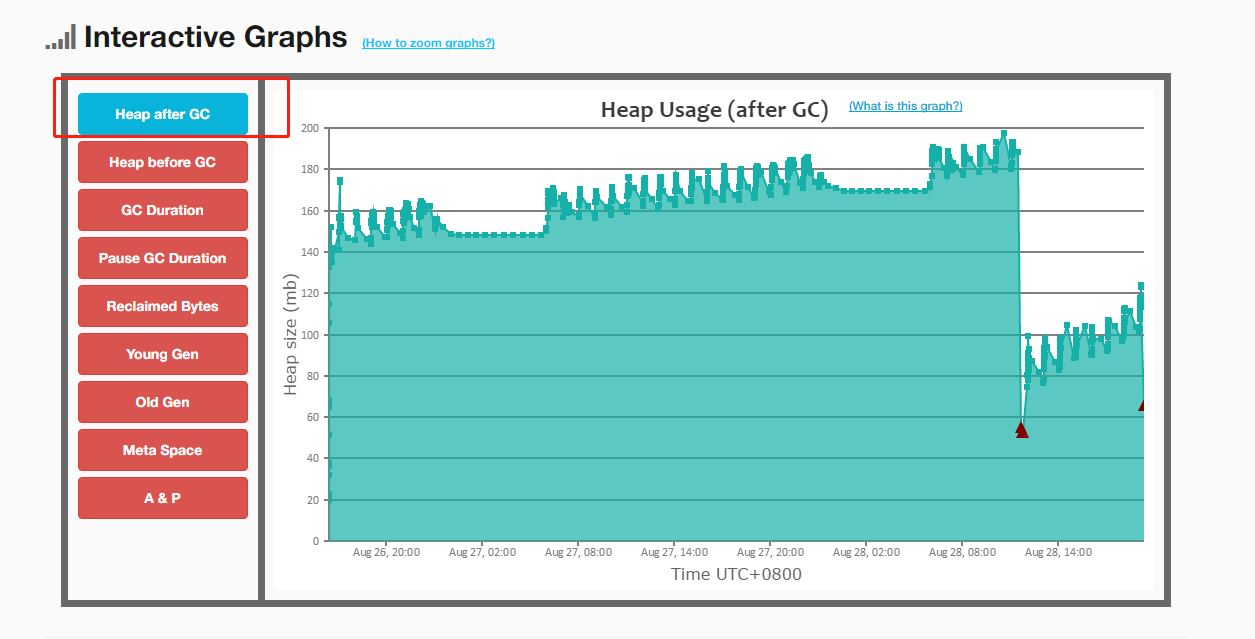

问:目前需要解决的问题是找出堆外内存泄漏的原因。
- 通过Google查找堆内存排查的文章:今咱们来聊聊JVM 堆外内存泄露的BUG是如何查找的 一次堆外内存泄露的排查过程
- 借用arthas观察,当Eden区膨胀到85%+的时候会进行一轮youngGC。所以盯着监控在Eden使用达到80%的时候将堆dump下来(jmap -dump:format=b,file=heap.hprof )。
切:通过对分析工具对堆文件进行分析:JProfiler(后面会用到)、MemoryAnalyzer
- 借助Memory Analyzer (MAT)工具将堆文件开。具体使用流程可自行百度,这里不细讲。
- 首先打开堆文件
- 进入后看到对分析结果中出现三个明显的错误,问题一跟问题二是由于引入了arthas导致的,直接跳过。
- 看到第三个问题是否眼前一亮,小时候我们学java的时候就知道java.lang.ref.Finalizer是干嘛的,有兴趣的可自行Google,也可看一下:JVM finalize实现原理与由此引发的血案
- 首先打开堆文件
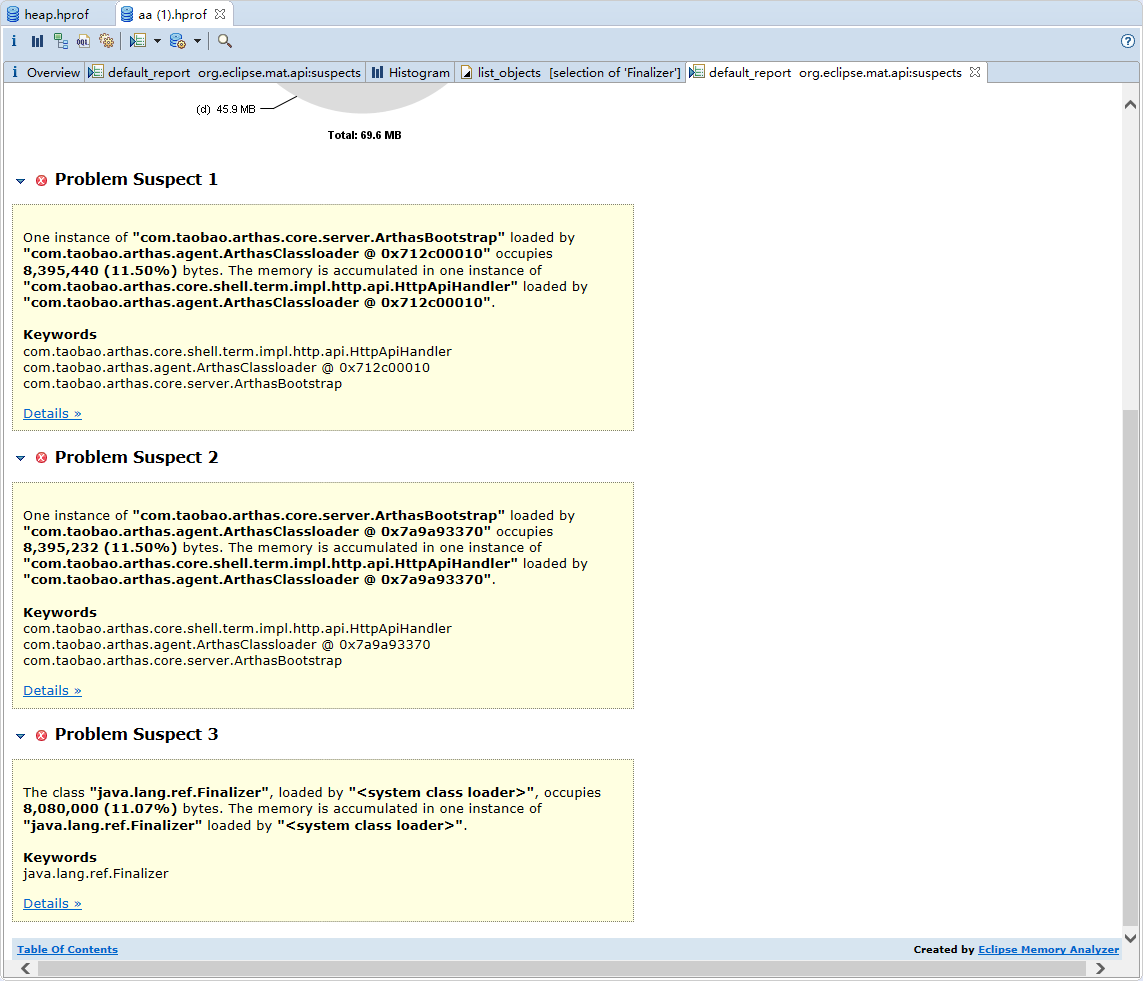
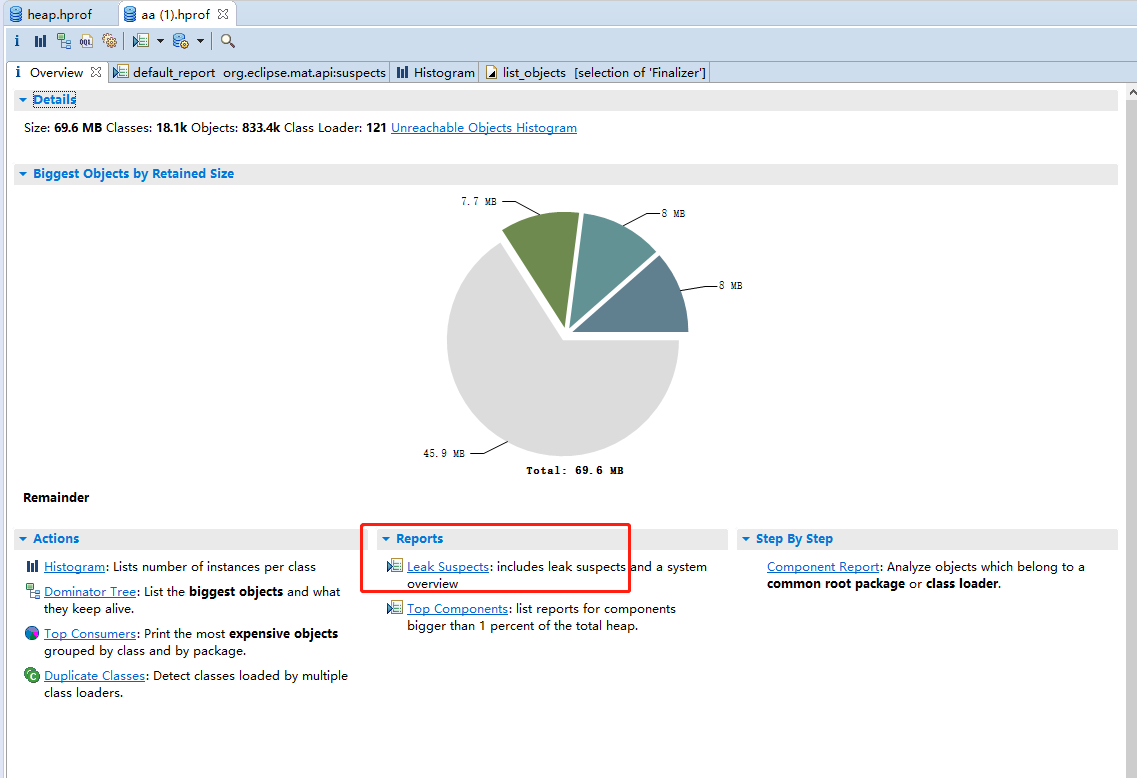
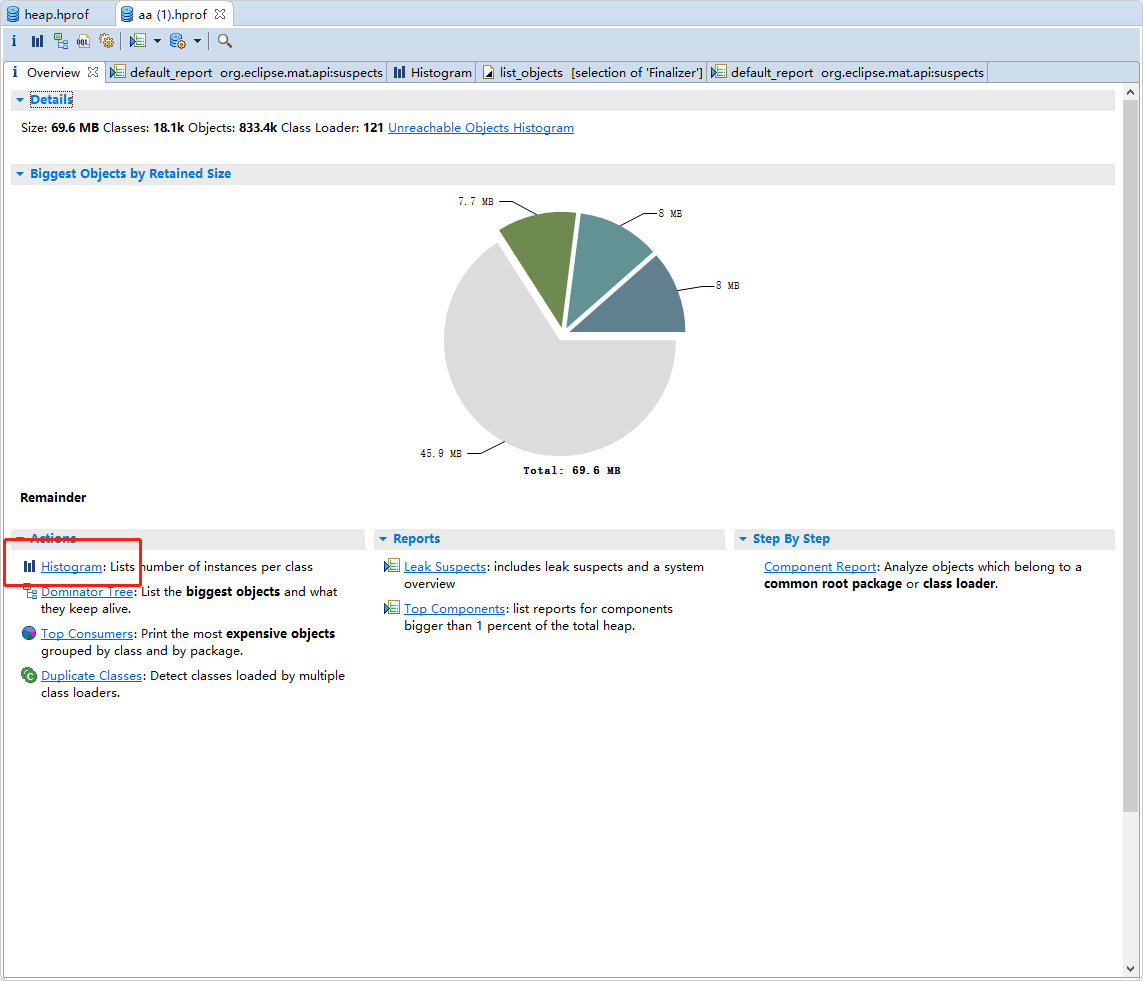
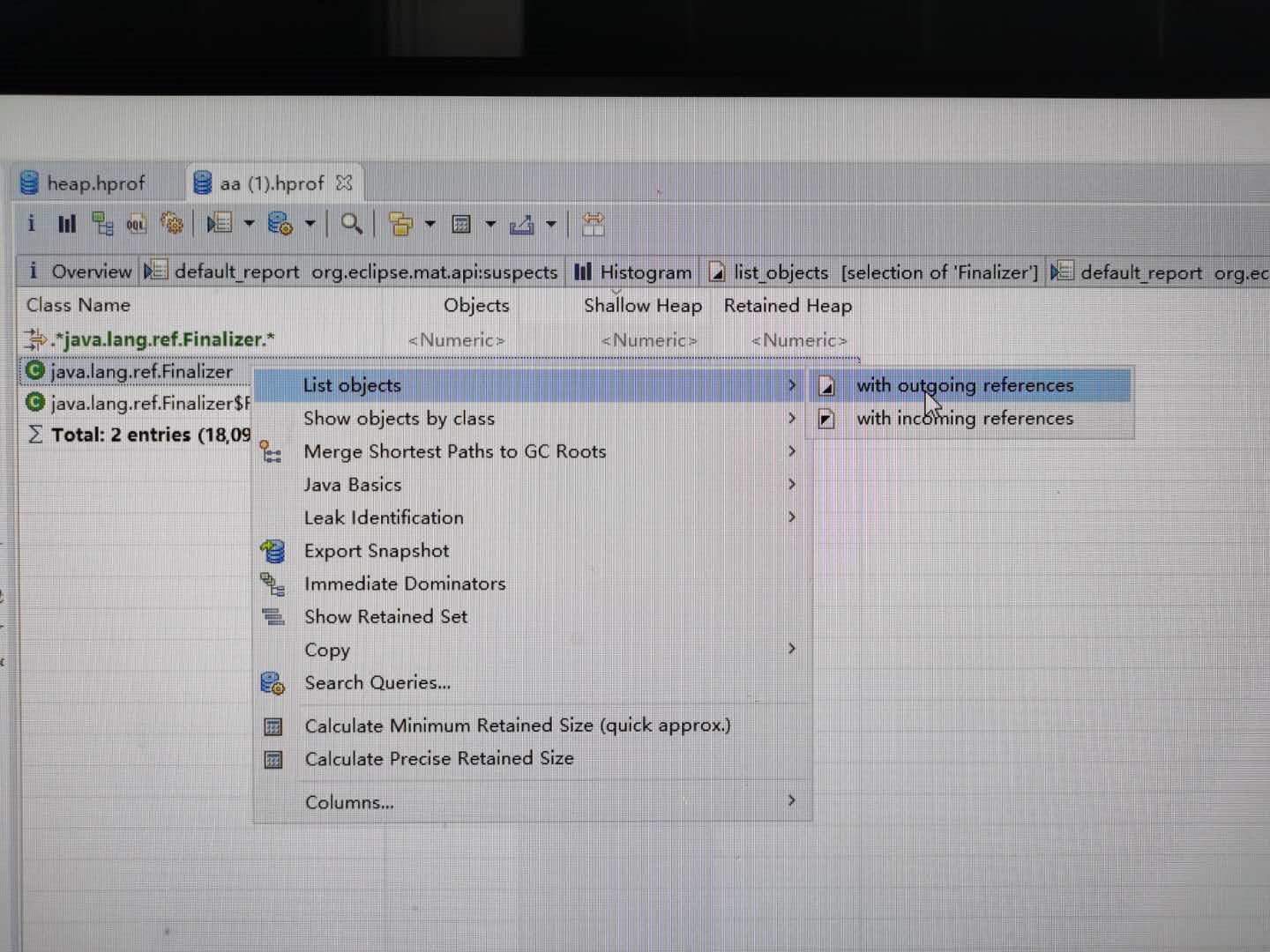
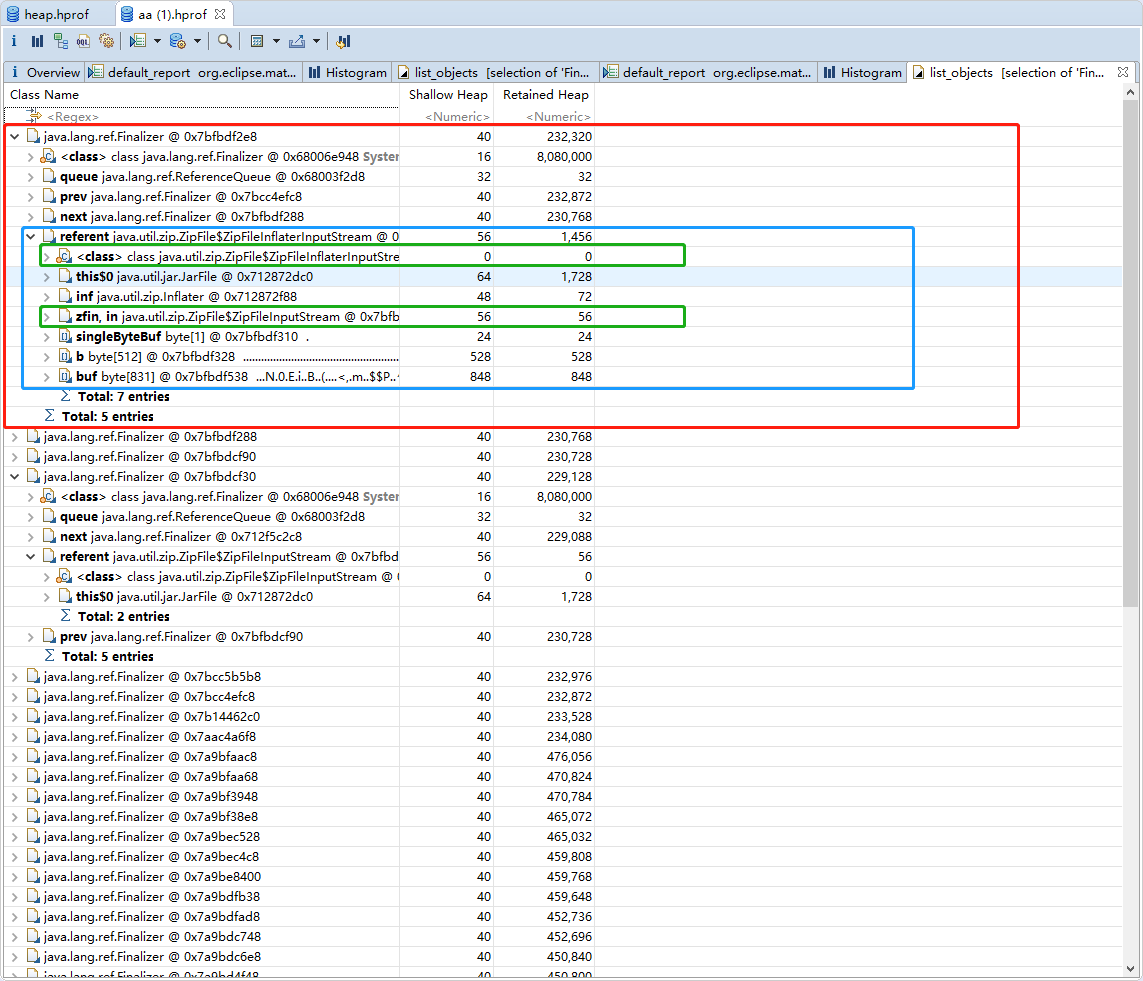
- java.lang.ref.Finalizer基本确定回收阶段出现问题,进入搜索待回收的对象。此时我们不是纠结有多少对象没有被回收,为什么没有回收。而是这些没有回收的对象是否由指向堆外内存。
- 点开实例查看所属类,此处看到这里出现3500+的未回收对象指向java.util.zip.ZipFile$ZipFileInflaterInputStream,赶紧Google发现还是有许多小伙伴碰到相同的问题,例如:Java压缩流GZIPStream导致的内存泄露 。
- 看到ZipFileInflaterInputStream马上想起该压缩在哪使用:push消息在预生成后存储redis,批量生成后将消息进行压缩再存储,采用的正是zip压缩,代码示例如下: 遗憾的是项目中使用的压缩工具为jdk自带的zip压缩,有兴趣的孩子可以了解一下基于Deflater 和 Inflater的zip压缩。 (具体使用方法直接参照这两个类上的示例注释,应该是最权威的使用方式了)以下是本人在项目中的使用:
- 点开实例查看所属类,此处看到这里出现3500+的未回收对象指向java.util.zip.ZipFile$ZipFileInflaterInputStream,赶紧Google发现还是有许多小伙伴碰到相同的问题,例如:Java压缩流GZIPStream导致的内存泄露 。
byte[] input = log.getBytes();
try (final ByteArrayOutputStream outputStream = new ByteArrayOutputStream(input.length)) {
final Deflater compressor = new Deflater();
compressor.setInput(input);
compressor.finish();
byte[] buffer = new byte[1024];
int offset = 0;
for (int length = compressor.deflate(buffer, offset, buffer.length); length > 0; length = compressor.deflate(buffer, offset, buffer.length)) {
outputStream.write(buffer, 0, length);
outputStream.flush();
}
//compressor.end();
return Base64Utils.encodeToString(outputStream.toByteArray());
}
}
public static String zipDecompress(final String str) throws Exception {
byte[] input = Base64Utils.decodeFromString(str);
try (final ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(input.length)) {
final Inflater decompressor = new Inflater();
decompressor.setInput(input);
byte[] buffer = new byte[1024];
for (int length = decompressor.inflate(buffer); length > 0 || !decompressor.finished(); length = decompressor.inflate(buffer)) {
byteArrayOutputStream.write(buffer, 0, length);
}
//decompressor.end();
return new String(byteArrayOutputStream.toByteArray());
}
}
- 奇怪的是,压缩与解压缩的预发都是采用try with resource的格式进行编写,讲道理是会进行流关闭的。网上部分小伙伴推荐使用snapy代替zip,但是我就不~~还是要搞清楚为什么此处没有在方法栈弹出之后马上做资源回收。
- 点击进入Deflater的deflate方法或者Inflater的inflate方法可以发现,二者都是调用了“native”方法,详细代码请参照源码。两个工具类均持有end()方法,其注释如下:
/**
* Closes the compressor and discards any unprocessed input.
* This method should be called when the compressor is no longer
* being used, but will also be called automatically by the
* finalize() method. Once this method is called, the behavior
* of the Deflater object is undefined.
*/
- 所以以上代码中将注释掉的两行end()方法的调用放开即可(这两行是锁定问题后加上的)。end()方法在调用后即可对堆外使用的内存进行释放,而不是等待jvm垃圾回收来临之后,将引用回收时再间接使堆外的缓冲区回收。继续翻看源码,不难发现Deflater和Inflater确实重写了finalize方法,而该方法的实现正是调用end方法,这就验证了我们上面的猜想。众所周知finalize方法会在对象被回收的时候被调用且只会被调用一次。所以在对象回收之前,被引用的堆外的空间是无法被回收的。
/**
* Closes the compressor and discards any unprocessed input.
* This method should be called when the compressor is no longer
* being used, but will also be called automatically by the
* finalize() method. Once this method is called, the behavior
* of the Deflater object is undefined.
*/
public void end() {
synchronized (zsRef) {
long addr = zsRef.address();
zsRef.clear();
if (addr != 0) {
end(addr);
buf = null;
}
}
}
/**
* Closes the compressor when garbage is collected.
*/
protected void finalize() {
end();
}
- 翻看redis的存储空间,好吧即使是高峰期的数据也不是很多,是我考虑太多了。
思考:项目发生重启是在kafka数据扩量后才出现的,那为何扩量前没有这个问题的出现呢?其实问题一直是存在的,只是数据量小的情况下,引用都在垃圾回收后能正常释放堆外内存。但是扩量后,瞬间的流量增高,产生大量的堆外内存使用引用。在下一次垃圾回收之前ReferenceQueue队列已经堆积了大量的引用,将容器内的堆外内存撑爆。
药:去除压缩解压缩动作
去除压缩与解压缩动作后,发版观察。项目的k8s实例资源监控处在合理范围。 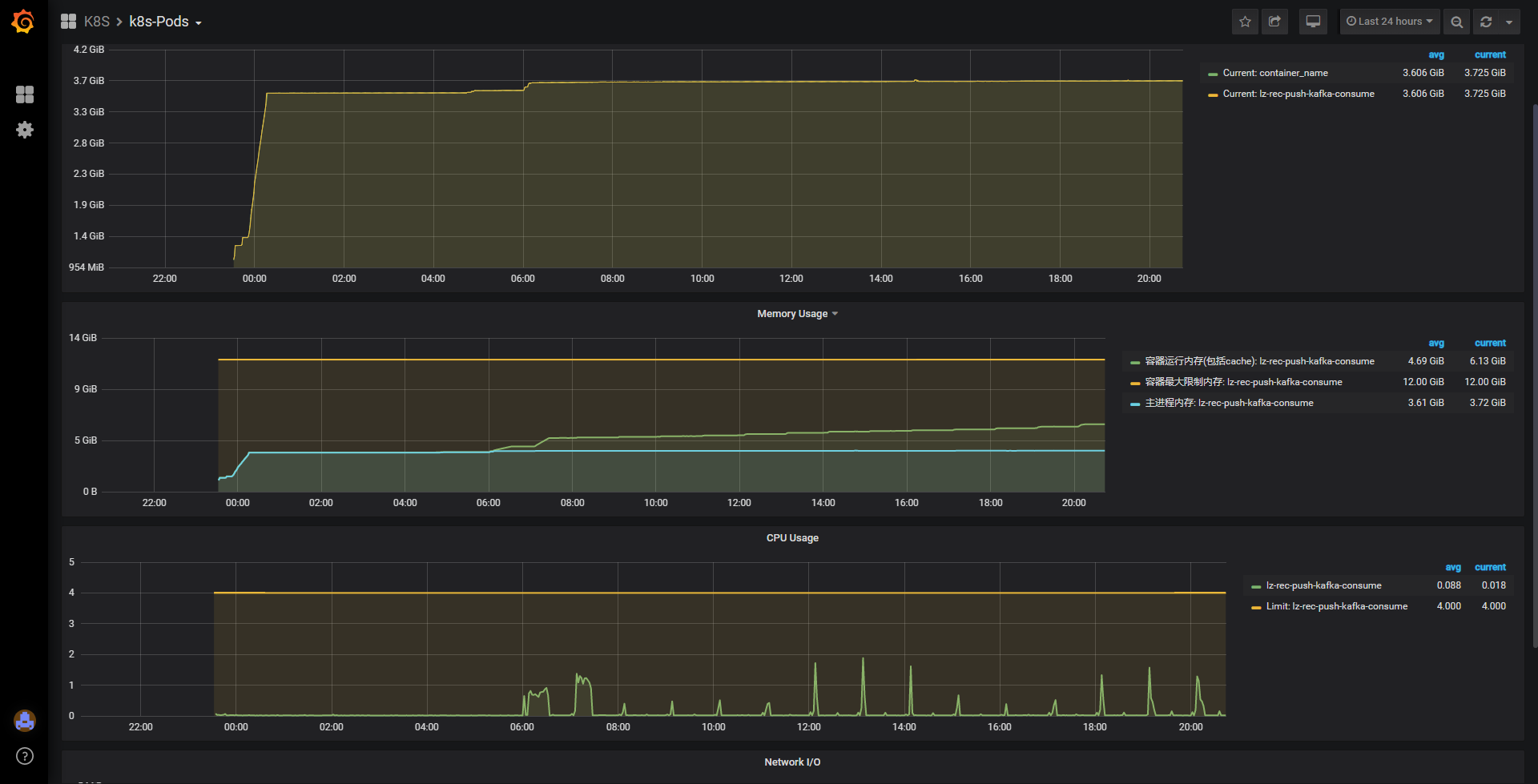
五、思考与复盘
问题:使用资源时,保持着资源使用后及时释放的习惯。该问题便是由压缩使用有误引起的,应该也算是低级错误了。
由于第一次排查堆外内存泄漏的问题,没有丰富的经验去锁定问题点达到快速排查,走了不着弯路。该文章略显啰嗦,但是主要目的还是想记录下排查问题的过程。第一次发博客,写作思路上有点紊乱,请多多包涵。如果有什么措辞不当的,还望指出。有什么好的建议也希望能指点一二。
一起来学习吧:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK