

Multi-Cloud API Authorization Challenges
source link: https://dzone.com/articles/multi-cloud-authorization-challenges
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Multi-Cloud API Authorization Challenges
In this article, we will look at how declarative API authorization could help and the challenges API providers face with deploying and running these APIs.
Join the DZone community and get the full member experience.
Join For FreeAs more and more companies move to a multi-cloud strategy and increase usage of a cloud-native infrastructure, API providers are under a lot of pressure to deliver APIs at scale in multi-cloud environments. At the same time, APIs should follow each company’s security requirements and best practices, no matter the cloud platform. These reasons explain why many providers have such complex API authorization requirements.
Let's assume in a company that multiple teams from different lines of business are building and deploying APIs in the Azure cloud. Different teams use different technologies to build these APIs (e.g., Azure Functions, Node.js). A company might host applications that consume the APIs on the same network, such as a company's AWS account or external SaaS applications.
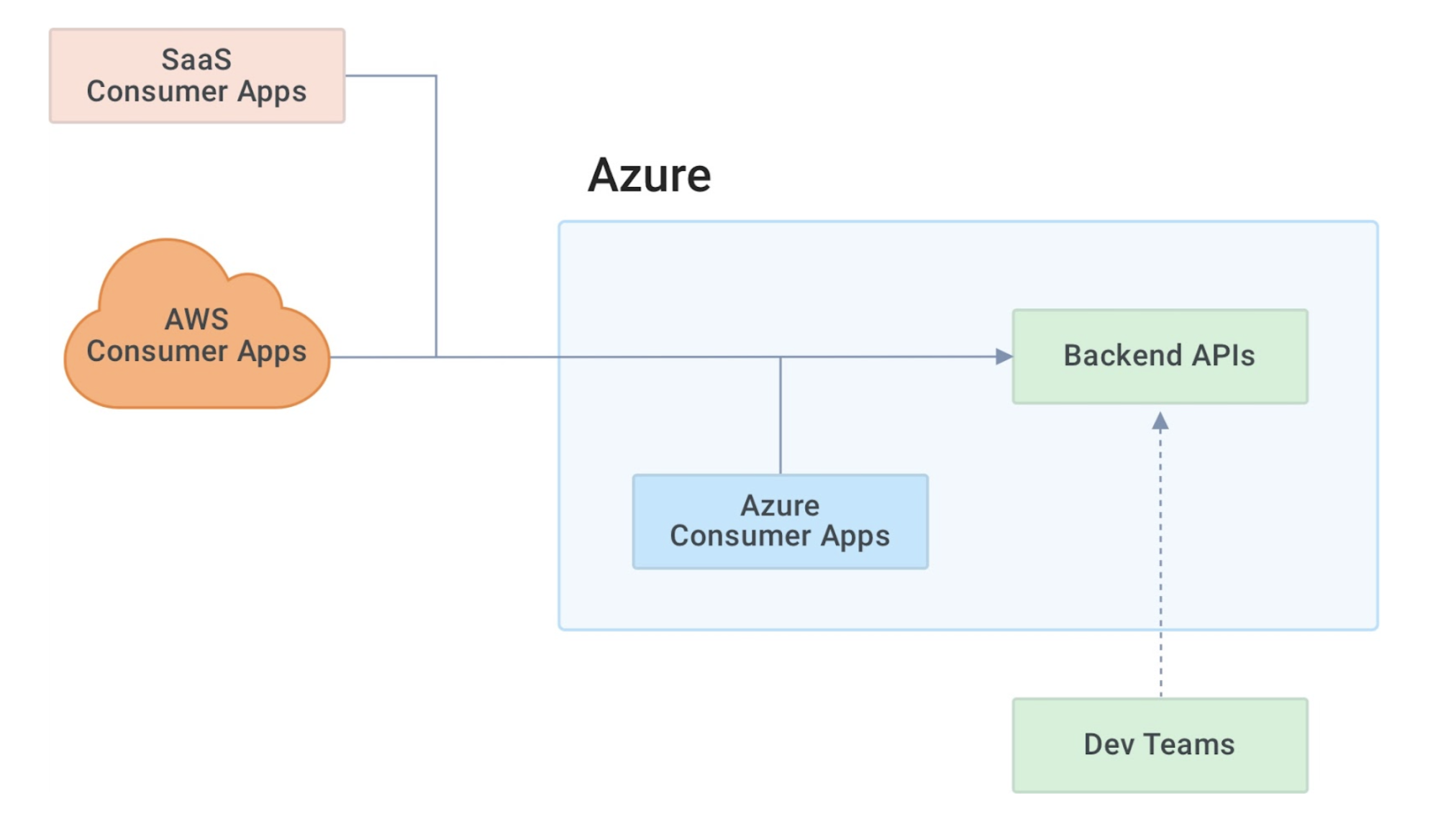
Now let’s take a closer look at the challenges API providers face when deploying and running these APIs.
Deployment Time
As mentioned earlier, multiple teams use different technologies to build and deploy APIs in a multi-cloud environment. We need a way to validate the APIs and make sure they follow best practices. Some companies leave this responsibility to individual teams and expect them to come up with these best practices. This approach normally leads to chaos. Teams either follow different standards and best practices or completely ignore them to speed up the delivery process. Another approach is a Center of Excellence (COE) to review all the APIs and ensure they follow best practices. This approach is not scalable; it might work for delivering a few APIs, but the COE team becomes a bottleneck when dealing with thousands of APIs because it takes a long time to review them.
Companies are looking to automate this as part of their CI/CD process and automatically validate the APIs. Let’s assume every API should be secured using API key authentication and authorization. This means we need a way to ensure developers have applied the right security policies on top of APIs before deploying them.
Run Time
Enforcing authorization can get complex in multi-cloud environments, and it can cause some serious challenges for the API providers. Let’s assume an API provider wants to control applications, users, and the IP ranges allowed to call their APIs—a typical use case.
One of the common approaches for storing authorization data is to store it in the IDP and use JWT tokens to pass it to the backend APIs. This approach is not a good fit for multi-cloud environments due to the distributed nature of these environments and the likelihood of using different authorization technologies. For example, users coming from AWS might use different IDP vs. Azure vs. SaaS users.
Replicating the user's authorization data across many IDPs and keeping them in sync is complex and inefficient. There might also be some restrictions on the data which API providers can store in each IDP. For example, in our case, the AWS IDP admin is questioning why they need to store authorization data for Azure APIs.
Solution: Declarative API Authorization
To solve this problem, we can use a declarative configuration with APIOps, Kong Gateway, and OPA. Before I dive into how these solutions work together, I’ll cover some basics.
APIOps
APIOps brings DevOps and GitOps principles to the API and microservices lifecycle to automate these stages as much as possible. You can achieve a big part of this automation using declarative configuration. If you have been using Kubernetes or DevOps, you are familiar with declarative configuration concepts. APIOps uses declarative configuration to automate most of the API lifecycle.
Open Policy Agent
OPA is an open-source policy engine that lets users define policy as code. OPA uses Rego language to define these policies.
You can use OPA to create policies as code and enforce them across different applications in your organization. You can create OPA policies that can answer questions such as:
- Can an application call the Customer API?
- Can user X call the Customer API?
- Is user A authorized to see user B’s data?
The declarative nature of OPA makes it a great fit for APIOps. You can create these policies, store them in your code repository and use them through different stages of the API lifecycle. For more information about OPA, please refer to the OPA website.
Kong Gateway and Open Policy Agent
You can integrate OPA with Kong Gateway. Let’s look at the interactions between the API consumer, Kong Gateway, OPA server, and a backend API.
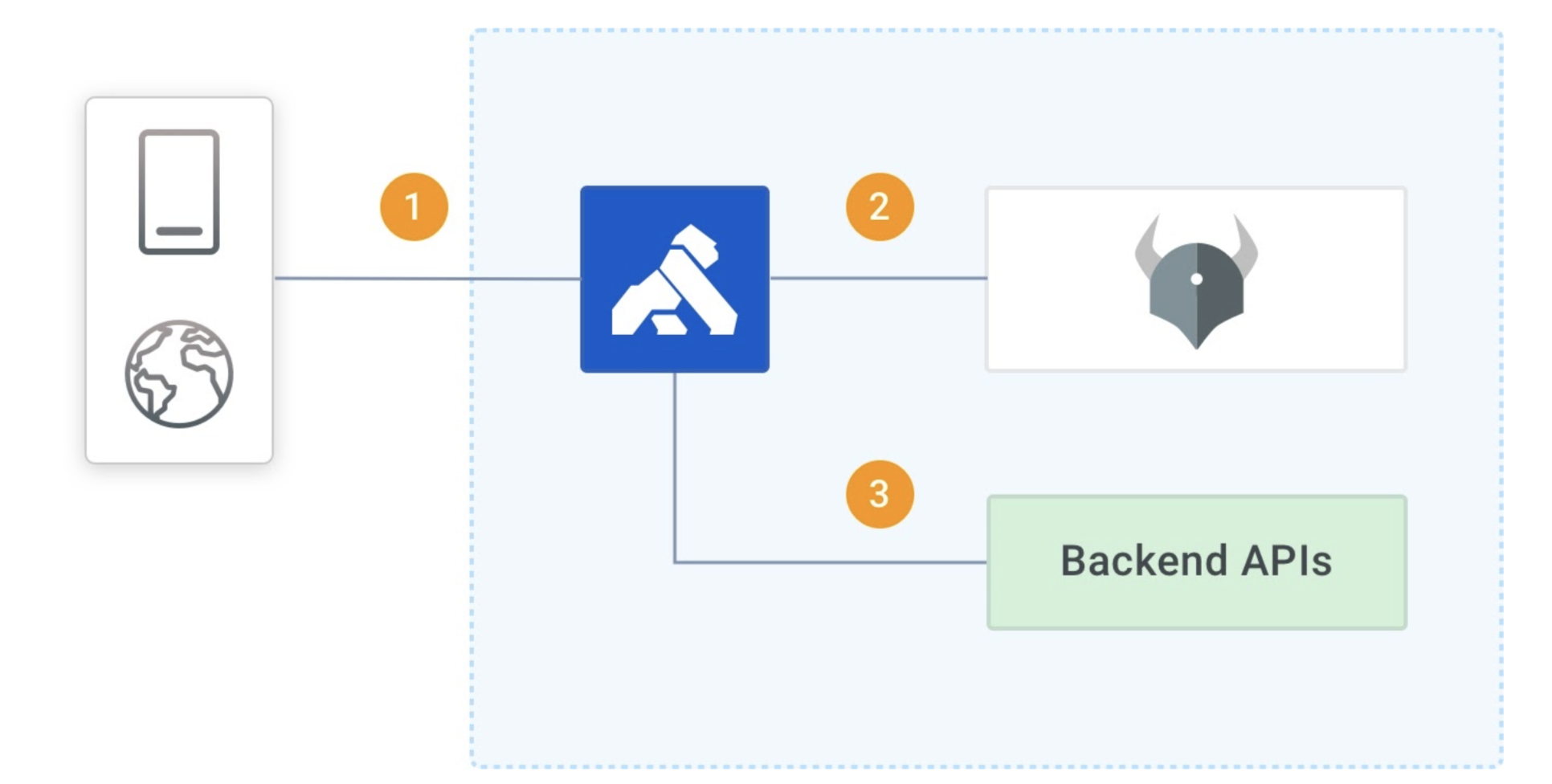
- API consumer sends a request to Kong Gateway.
- Kong Gateway uses the OPA plugin to call a policy in the OPA server and receive the response.
- Based on the response from the OPA server, Kong Gateway decides to forward the request to a backend API or send an error back.
An important part of OPA policy architecture is decoupling the data from the policy definition. In this scenario, there are two ways for the policy to access the information it needs to decide:
- Input: Input refers to the request that the consumer sent to Kong Gateway. We can also configure the OPA Plugin to send the gateway’s Service, Consumer, and Route objects as part of Input as well.
- Data: Arbitrary JSON data can be pushed into the policy using OPA’s API. You might ask why we need the data element. This is because Input is about the current consumer, and making a decision sometimes requires more information than just the current user context. For example, arbitrary data can be about the user's role and access level, which does not exist in the Input request.
There are other approaches for injecting external data into OPA policy. For more information, please refer to the OPA website.
CI/CD Tools and Open Policy Agent
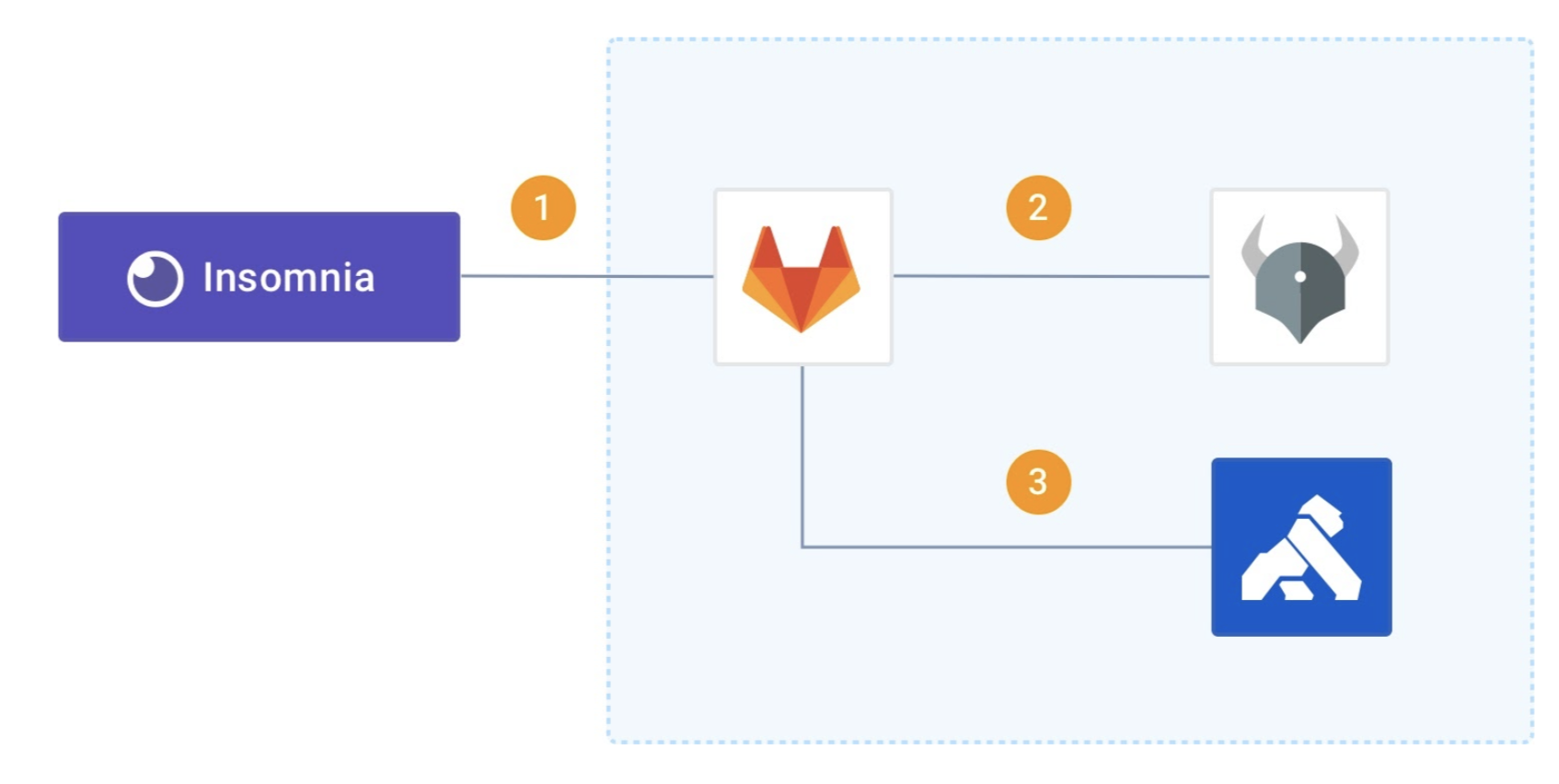
One of the great things about OPA is that it can integrate with most technologies as long as they generate and consume JSON. Most CI/CD tools these days have either out-of-the-box libraries or third-party add-ons to support JSON. During deployment, we can use OPA to validate the:
- Mandatory Kong plugins applied to the APIs (e.g., Authentication Plugins)
- Mandatory test cases have been included in the project.
- The user has permission to deploy the API to the target environment.
To implement the declarative authorization as part of the continuous deployment:
- The API developer uses Insomnia to design the API, define the Kong plugins and check the API specification into a code repository.
- As part of the continuous deployment, the CI/CD tool calls the OPA Policy. The OPA policy validates the API specification, Kong Plugins, test cases, and the developer’s authorization.
- If the result was successful, the CI/CD tool continues the process; otherwise, it stops.
How APIOps, Kong Gateway, and OPA Work Together
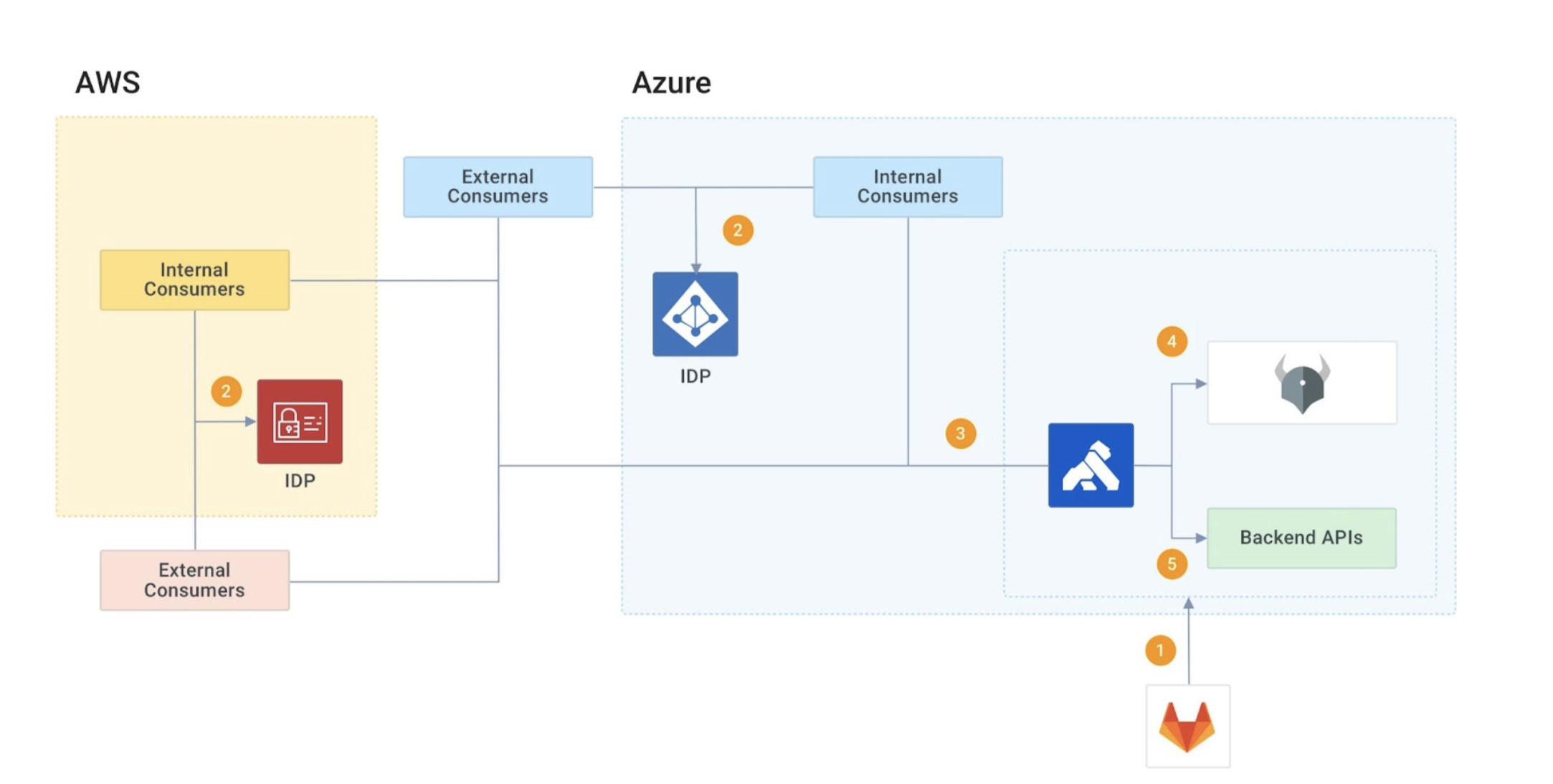
You can implement this solution by following these steps:
- Before deploying the API to Kong Gateway, the CI/CD tool calls OPA and verifies the mandatory plugins are in the API definition. If it passes the policy check, then it deploys the API using declarative configuration.
- Consumer applications use an IDP or any other method to create a JWT token. This token has the user’s unique ID. We assume that the user ID is unique across different clouds.
- Consumer applications send the request to Kong Gateway.
- Kong Gateway sends the request to the OPA server. The OPA server executes the policy and returns the result.
- Kong Gateway sends the request to the backend API if the result is successful; otherwise, it returns an error.
In the next sections, we discuss the implementation and walk you through the details. We are using GitHub Actions to automate the API deployment. You can adjust these scripts based on the CI/CD tool you are using.
How to Set Up GitHub Actions and OPA
The first part of the solution ensures developers have included the right policies on top of APIs. This means Key Authentication and OPA plugins should exist in the API specification.
API developers can use “x-kong-plugin-” prefix to add the required plugins to their APIs. The OAS spec for the Customer API looks like this:
openapi: "3.0.0"
info:
version: 1.0.1
title: customer api
license:
name: Kong
servers:
- url: ${UPSTREAM_SERVER_URL}$
description: Upstream server URL.
# Key Auth plugin enables authentication for this service
x-kong-plugin-key-auth:
enabled: true
config:
key_names:
- apikey
x-kong-plugin-opa:
enabled: true
config:
opa_host: ${OPA_HOST}$
opa_port: ${OPA_PORT}$
opa_path: /v1/data/userAuthz/allowUser
include_consumer_in_opa_input: true
include_route_in_opa_input: true
include_service_in_opa_input: true
We can simply create an OPA policy to look for these plugins in the API specification.
package apiCDAuthz
default allow = false
allow {
input["x-kong-plugin-key-auth"].enabled == true
input["x-kong-plugin-opa"].enabled == true
}As you can see, this policy looks for these two plugins in the OAS specification (e.g., input) and checks if they are enabled. It returns true if both policies exist and are enabled; otherwise, it returns false.
You can create this policy by calling OPA’s create policy API:
curl -XPUT http://<opa-server:port>/v1/policies/apiCDAuthz --data-binary @./opa/apiCDAuthz.regoThe next step is to send the OAS specification to the OPA policy and check the result. In this example, we wrote our OpenAPI Specification in YAML, and OPA can only process JSON. The first thing we need to do is to export the customer specification and transform it to JSON, as shown in this GitHub Action workflow:
# Export customer yaml
- name: Export customer yaml
run: inso export spec customer-opa --output customer.yaml
# Transform OAS to JSON
- uses: fabasoad/yaml-json-xml-converter-action@main
id: yaml2json
with:
path: 'customer.yaml'
from: 'yaml'
to: 'json'
- name: Prepare OPA input
run: |
cat <<EOF > ./v1-data-input.json
{
"input": ${{ steps.yaml2json.outputs.data }}
}
EOFAnd then, we can call the OPA policy and validate the JSON data.
# Check deployment authorisation
- name: Call OPA to Check Deployment Authorisation
id: call-opa
run: |
result=$(curl ${{ secrets.OPA_HOST }}/v1/data/apiCDAuthz -d @./v1-data-input.json \
-H 'Content-Type: application/json' | jq '.result.allow')
echo "::set-output name=result::$result"
- name: Should I continue?
run: |
if ${{ steps.call-opa.outputs.result }}; then
echo "Call OPA Result: ${{ steps.call-opa.outputs.result }}"
else
echo "Call OPA Result: ${{ steps.call-opa.outputs.result }}"
exit 1
fi
If the result is false (i.e., the API spec does not conform to the configured best practice), the deployment process will automatically fail, and the system will notify the developer.
This is a very simple example to demonstrate the role which OPA can play in the deployment process. You can extend it to:
- Check the developer authorization
- Do advanced linting
- Check API best practices and naming conventions
- And so much more
How to Set Up Kong Gateway and OPA
As discussed earlier, API providers want to expose their APIs to:
- Internal consumers in Azure
- Internal consumers in AWS
- External consumers who use AWS IDP
- External consumers who use Azure IDP
At the same time, they want to control the applications, users, and the networks calling their APIs. For example, an API provider might only allow users to call GET customers using the CRM application hosted in the company's AWS account.
We are confident that the API developer has already configured the OPA plugin for this API at runtime. Otherwise, it would fail during the deployment. Below is the configuration for the OPA plugin:
x-kong-plugin-opa:
enabled: true
config:
opa_host: ${OPA_HOST}$
opa_port: ${OPA_PORT}$
opa_path: /v1/data/userAuthz/allowUser
include_consumer_in_opa_input: true
include_route_in_opa_input: true
include_service_in_opa_input: trueThe OPA plugin sends the request, consumer, service, and route information to the userAuthz policy in the OPA server. Adding service, consumer, and route information on top of the current request helps us implement a more granular access level. For example, the policy can restrict the users to only certain routes.
Now let’s take a look at the userAuthz policy:
package userAuthz
default allowUser = false
allowUser = response {
# Validate JWT token
v := input.request.http.headers.authorization
startswith(v, "Bearer ")
t := substring(v, count("Bearer "), -1)
io.jwt.verify_hs256(t, data.userAuthz.jwt_signiture)
[_, payload, _] := io.jwt.decode(t)
# Validate consumer app
kong_consumer := input.consumer.username
some j
data.userAuthz.apps[j] == kong_consumer
# Validate network
net.cidr_contains(data.userAuthz.networkcidr, input.client_ip)
# Validate user's access to api
role := data.userAuthz.users[payload.username].role
serviceName := input.service.name
access := data.userAuthz.role_service_access[role][serviceName].access
tier := data.userAuthz.role_service_access[role][serviceName].tier
some i
access[i] == input.request.http.method
response := {
"allow": true,
"headers": {
"x-user-tier": tier,
},
}
}This policy:
- Reads the JWT token from the request, validates and decodes it
- Validates that the client IP address is authorized to call this API
- Validates that the consumer app is on the list of approved applications
- Validates that the user is in the list of authorized users and can execute the HTTP method
As you can see, this policy uses data variables. This data is injected into this policy using the OPA API.
curl -XPUT http://<opa-server:port>/v1/data/userAuthz --data-binary @./opa/userAuthz.json If there is a change in data, we can simply update the JSON file and call the OPA API again.
{
"jwt_signiture": "46546B41BD5F462719C6D6118E673A2389",
"networkcidr": "178.10.0.0/24",
"apps": ["insomnia"],
"users": {
"[email protected]": {
"role": "admin"
}
},
"role_service_access": {
"admin": {
"customer_api": {
"access": ["GET"],
"tier": "Gold"
},
"employee_api": {
"access": ["GET","POST"],
"tier": "Silver"
}
}
}
}By using this policy and the data combined, the API provider only allows the requests with the following attributes to call GET customers API:
- JWT token which signed by hs256 and 46546B41BD5F462719C6D6118E673A2389 key
- The IP address within 178.10.0.0/24 CIDR
- User id [email protected]
Another beneficial feature of OPA policies is the ability to return useful information to Kong Gateway. This case returns the user's access tier (i.e., Gold) for each API. Kong Gateway can use this information to do things like tier-based rate limiting.
Conclusion
Using OPA and declarative policies is becoming very popular, especially in APIOps. That’s because they’re:
- Easy to integrate: It's very simple to integrate OPA with Kong Gateway, Kong Mesh, and CI/CD tools. It's also easy to integrate OPA with external data sources.
- Declarative: Being declarative makes OPA policies a natural fit for APIOps and automation. API providers can use OPA policies through different stages of the API lifecycle and be confident it will not impact the automation.
- Extremely powerful and flexible: OPA uses Rego language for defining policies. Rego provides powerful support for referencing nested documents and ensuring that queries are correct and unambiguous.
- Platform agnostic: OPA is platform agnostic. It can work with most technologies and platforms. We can use the same policies in different cloud providers and applications.
Building and managing APIs in a multi-cloud environment can be difficult, especially regarding security and authorization. Using policy-as-code with APIOps is a great way to build an automated and scalable solution. Try it out and see for yourself!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK