

How to Create Application Systems In Moments - DZone Database
source link: https://dzone.com/articles/how-to-create-application-systems-in-moments
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

How To Create Application Systems In Moments
Previously, creating application systems was time-consuming and complex. Today, you can create customizable, model-driven systems - with a single command. Let's see how.
Join the DZone community and get the full member experience.
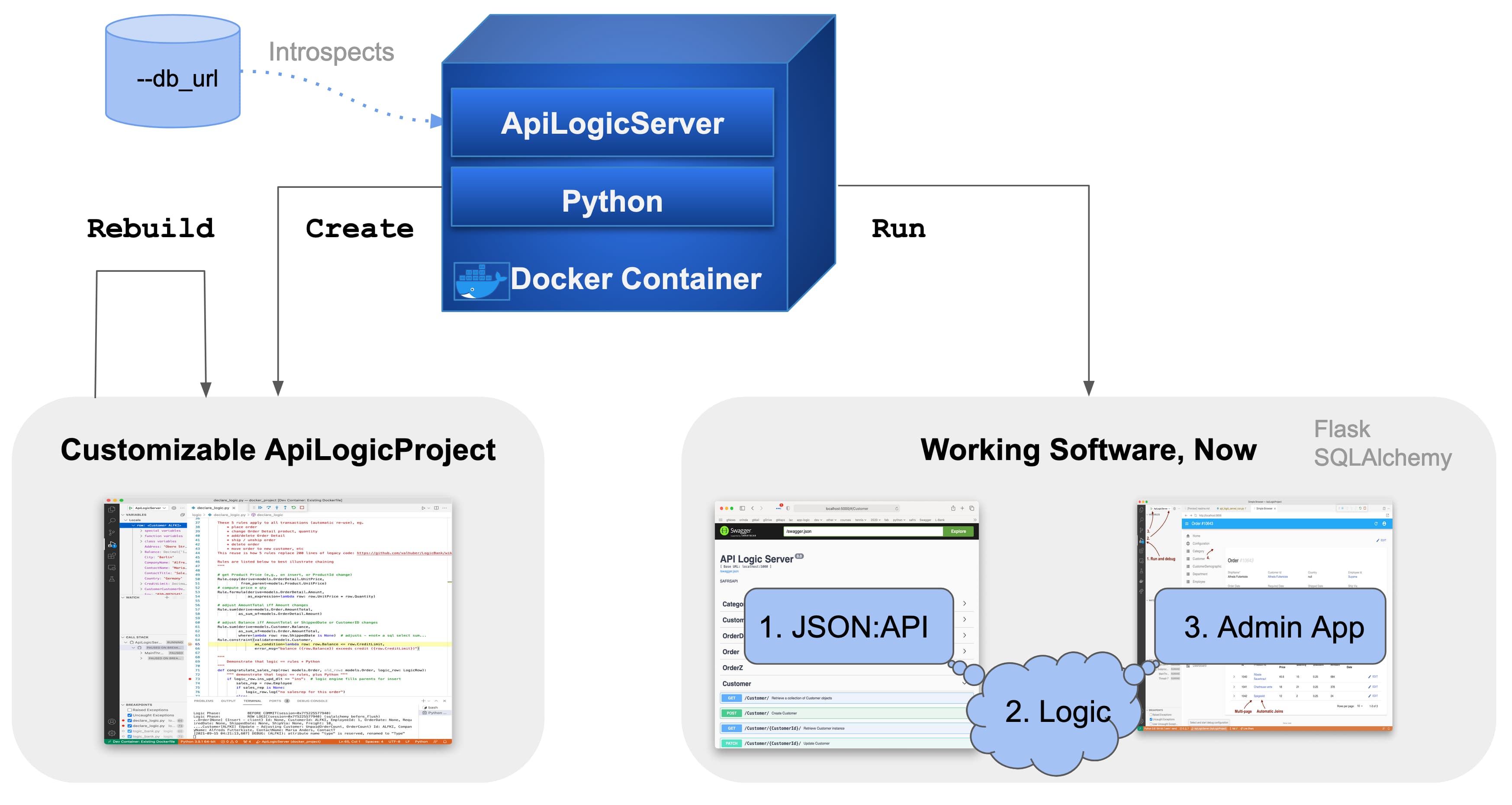
Join For FreePreviously, creating database-oriented transactional application systems was time-consuming and complex. New open-source technology now enables you to create customizable, model-driven systems with a single command:
ApiLogicServer create --project_name=/localhost/ApiLogicProject --db_url=This creates a working system, in moments, directly from your database:
- a React-based admin app, for back-office data maintenance and end-user collaboration.
- an API, with Swagger, for custom app dev.
- and logic, with unique spreadsheet-like rules that are remarkably more concise than code.
In this “How to” tutorial, we will explore:
- The creation process
- Architecture
- The created system
- Customization
- Technology considerations
Creation Process
The create command above creates an executable project by introspecting your database, designated by the --db_url argument. The blank value above uses the pre-supplied database (Northwind - Customers, Orders, etc.). To use your own database, specify an SQLAlchemy URI (database type, server, schema, credentials, etc).
You can open the created project in your IDE to customize and debug. The project elements are files, so you can manage projects with your existing tools for source control, code management, etc.
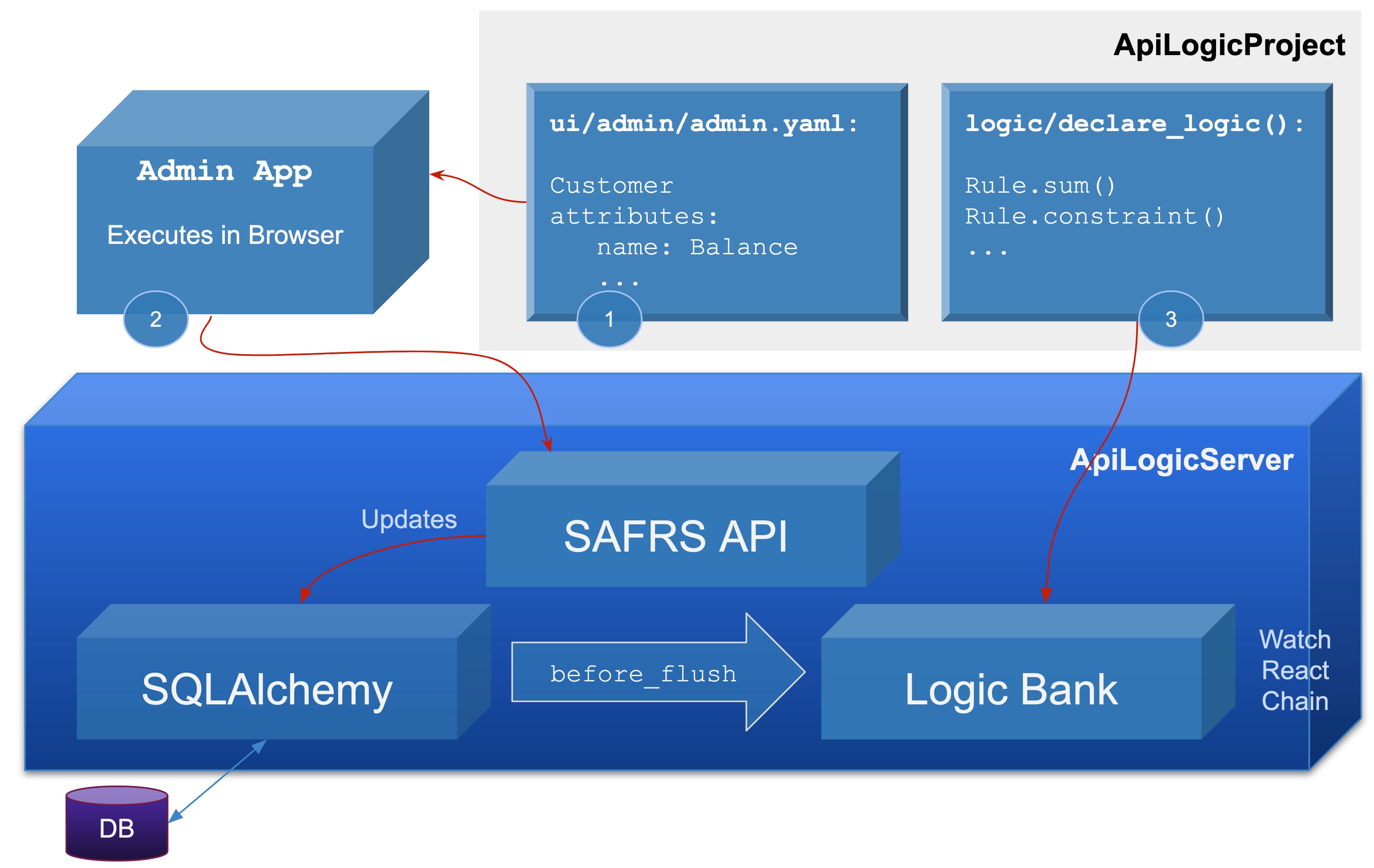
Architecture
The system is installed via pip install, or (as pictured above) a docker container. It executes as a standard multi-tier application:
- The admin app is implemented not as enormous amounts of complex JavaScript and HTML, but rather a model - a description of what the app should do, not how to do it. In this case, the model is represented as an easy-to-edit YAML file located in your
ApiLogicProject. - The admin app executes in the Browser using react-admin. It uses the automatically created JSON:API to read and write data.
- The API uses SQLAlchemy to read/write data. The business logic to maintain database integrity is declared in
declare_logic.py. This logic expresses multi-table derivations and constraints, and actions such as sending email or messages. This is also a model file consisting of rules and Python, which we'll see below. It is used by the Logic Bank rule engine, which listens for SQLAlchemybefore_flushevents.
Created System
Let's examine the system built from the create command.
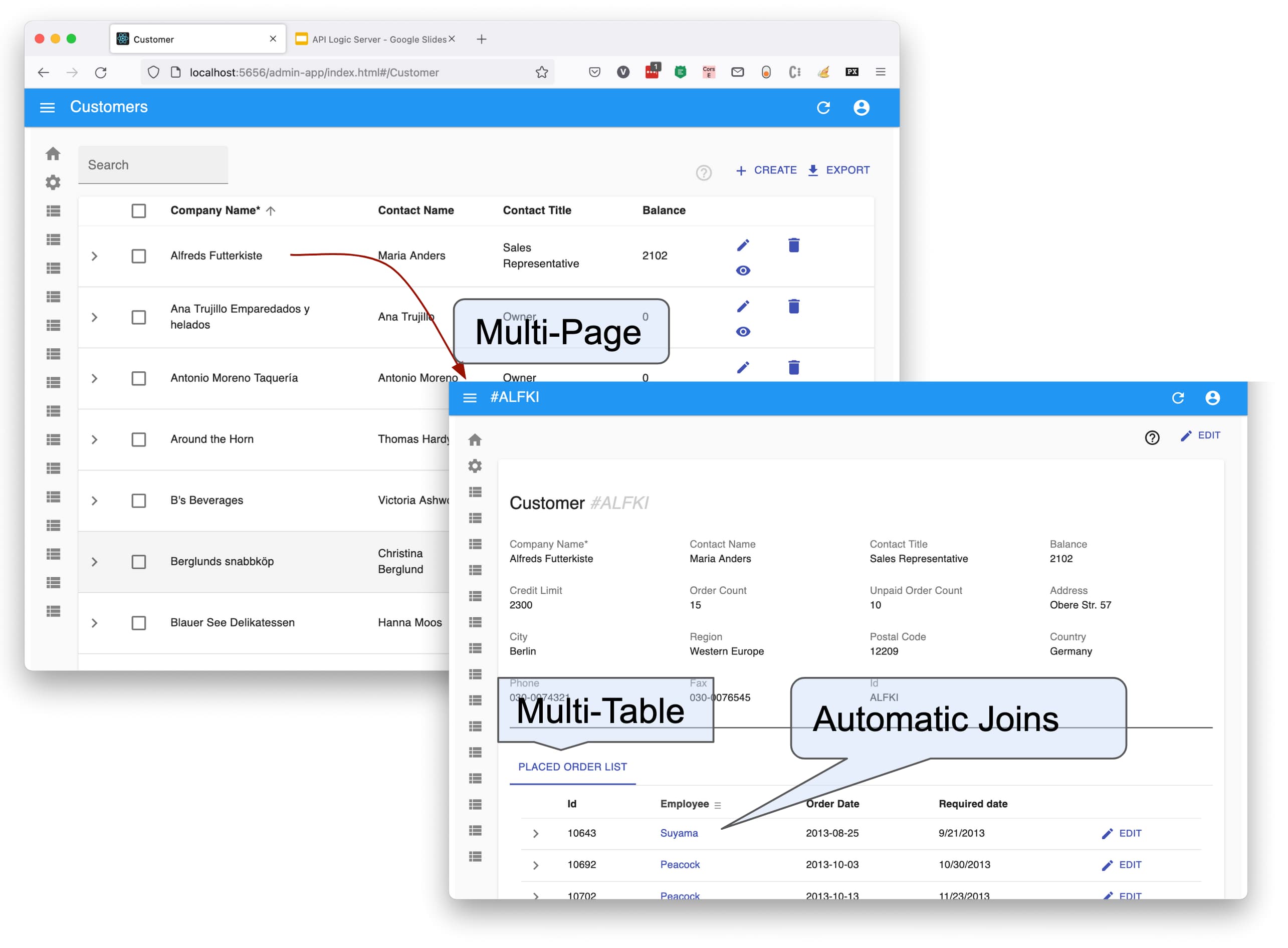
React Admin Application - Multi-Page, Multi-Table
As shown in the diagram below, two pages are created for each table: a list page and a show page. So, in our Northwind example, our create command produces a 30-page application.
Lists are a key aspect of any application; they support multi-field search, sort by clicking column headers, and pagination for good large-result performance. The diagram below illustrates support for multi-page applications: clicking the customer zooms into its show page.
Pages are multi-table, automatically including related data, such as the Placed Orders. Similarly, you can click an Order to see its details, including a list of its Order Details. You can thus "walk the database relationships" in the admin app.
Observe the Employee (Sales Rep) for the Order. It is an automatic join. Each Order has a foreign key of EmployeeId, a number that makes no sense for users. So the system has automatically joined the Employee Name. Popup dialogs are also provided to see the full set of related data.
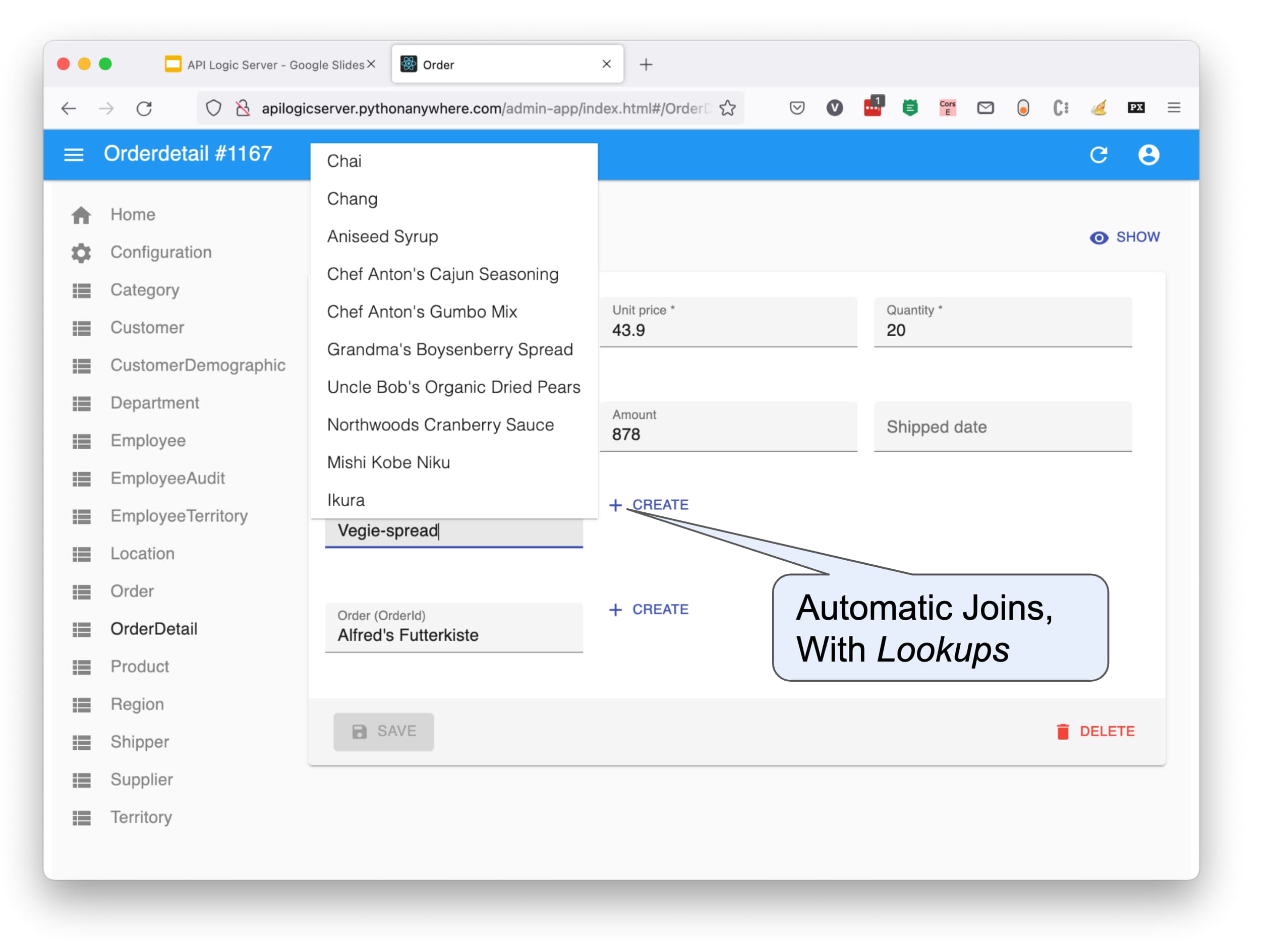
Update Support - Lookups, Logic
The update includes important support for Lookups, to fill in foreign keys by name, not Id. In the screenshot below, OrderDetails relate to their Product by ProductId Not only does the system provide the automatic join, but also a lookup to filter/select a Product (Chai, Chang, etc.); the system fills in the foreign key.
The save button fires logic to recalculate the Order AmountTotal. This logic was via a few rules - not code - which we'll see shortly.
 Key Take-away: not a page-by-page "low code" screen painter, but the single
Key Take-away: not a page-by-page "low code" screen painter, but the single create command builds a complete, multi-page/multi-table application.
API - With Swagger
The system also automatically creates an API, which is used by the app, and for custom apps and application integration. The API supports filtering, pagination, and related data access.
We can examine the API via automatically created Swagger. An endpoint for every table, with verbs for retrieval and update.
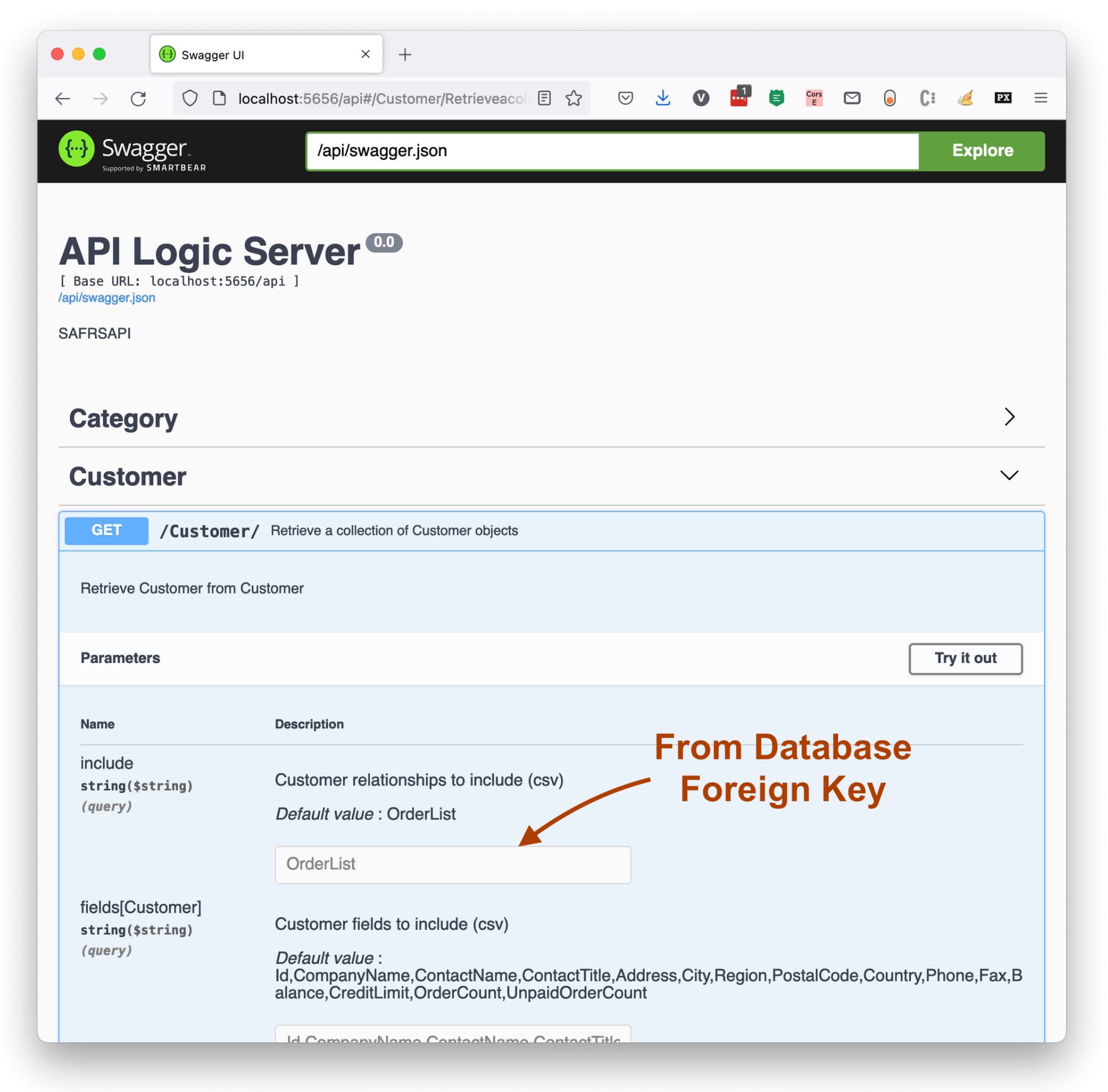 Key Take-away: it's not so hard to create a single "hello world" endpoint, or even return some SQL data. It's quite another matter for the
Key Take-away: it's not so hard to create a single "hello world" endpoint, or even return some SQL data. It's quite another matter for the create command to build endpoints for every table, with filtering, sorting, pagination, and related data access.
Customization - Python and Your IDE
Everything shown so far was automatically built from the create command. A great start, but it's critical to be able to customize the system, utilizing standard languages and tools.
The create command builds an ApiLogicProject that you can customize in your IDE, such as PyCharm or VS Code. Shown below in VS Code, the project is built-to-customize: the model, the API, the logic, and the application. Pre-built configurations enable the use of Docker or pip install, and the use of IDE tools like the code editor and debugger.
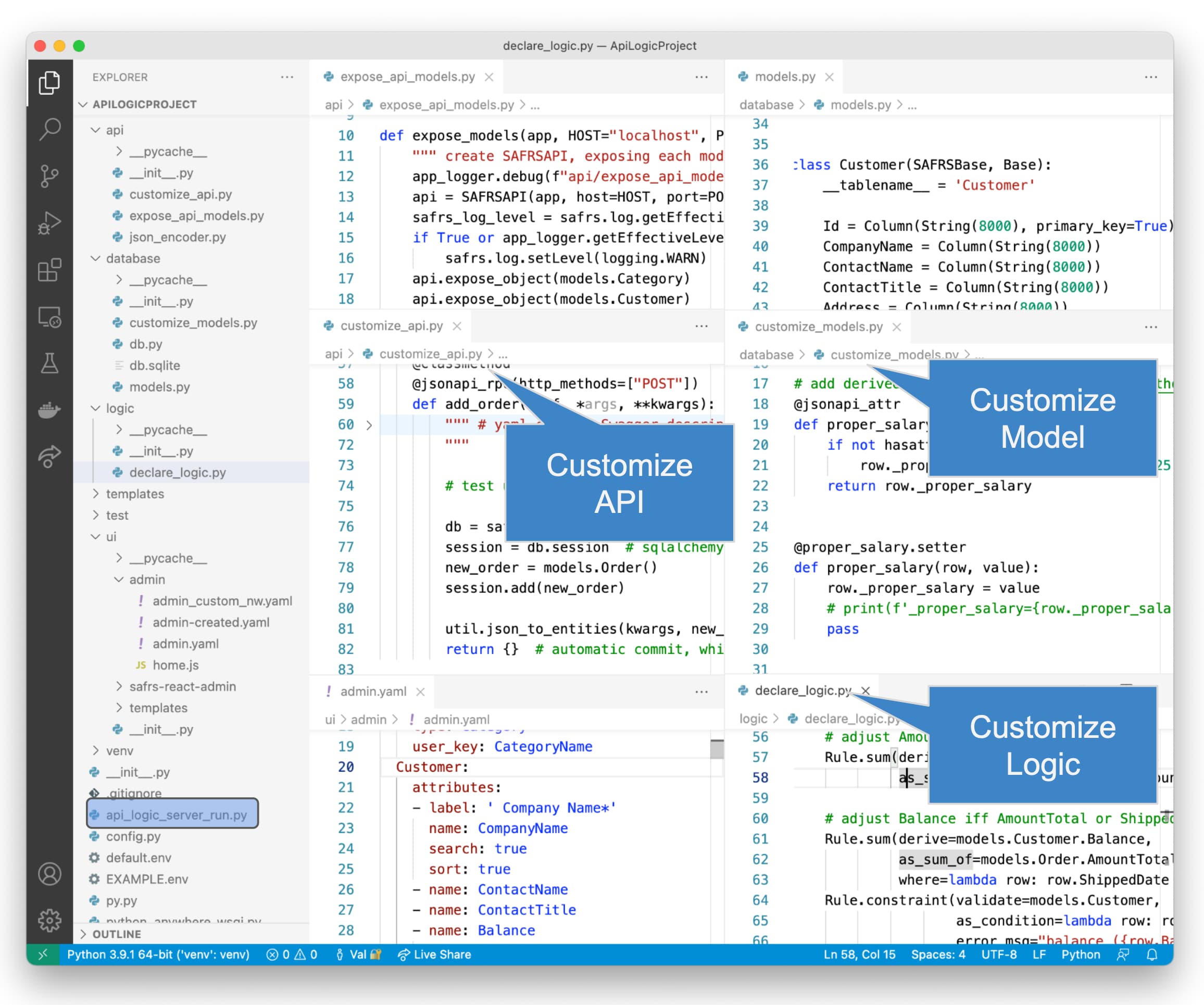
The sections below take a brief look at customizations for the model, the app, the API, and the logic.
Customize Application - Column Order and Labels
As noted above, the admin app is implemented not as enormous amounts of complex JavaScript and HTML, but rather a model - a description of what the app should do, not how to do it. In this case, the model is represented as an easy-to-edit YAML file located in your ApiLogicProject.
The lower left pane above shows the YAML file. It's trivial to reorder the columns, specify labels, and make other basic changes.
This instant application is suitable for instant collaboration, and for back-office data maintenance. For customer-facing custom applications, use your tools of choice in conjunction with the API for data retrieval and update.
Customize API - Add End-Points
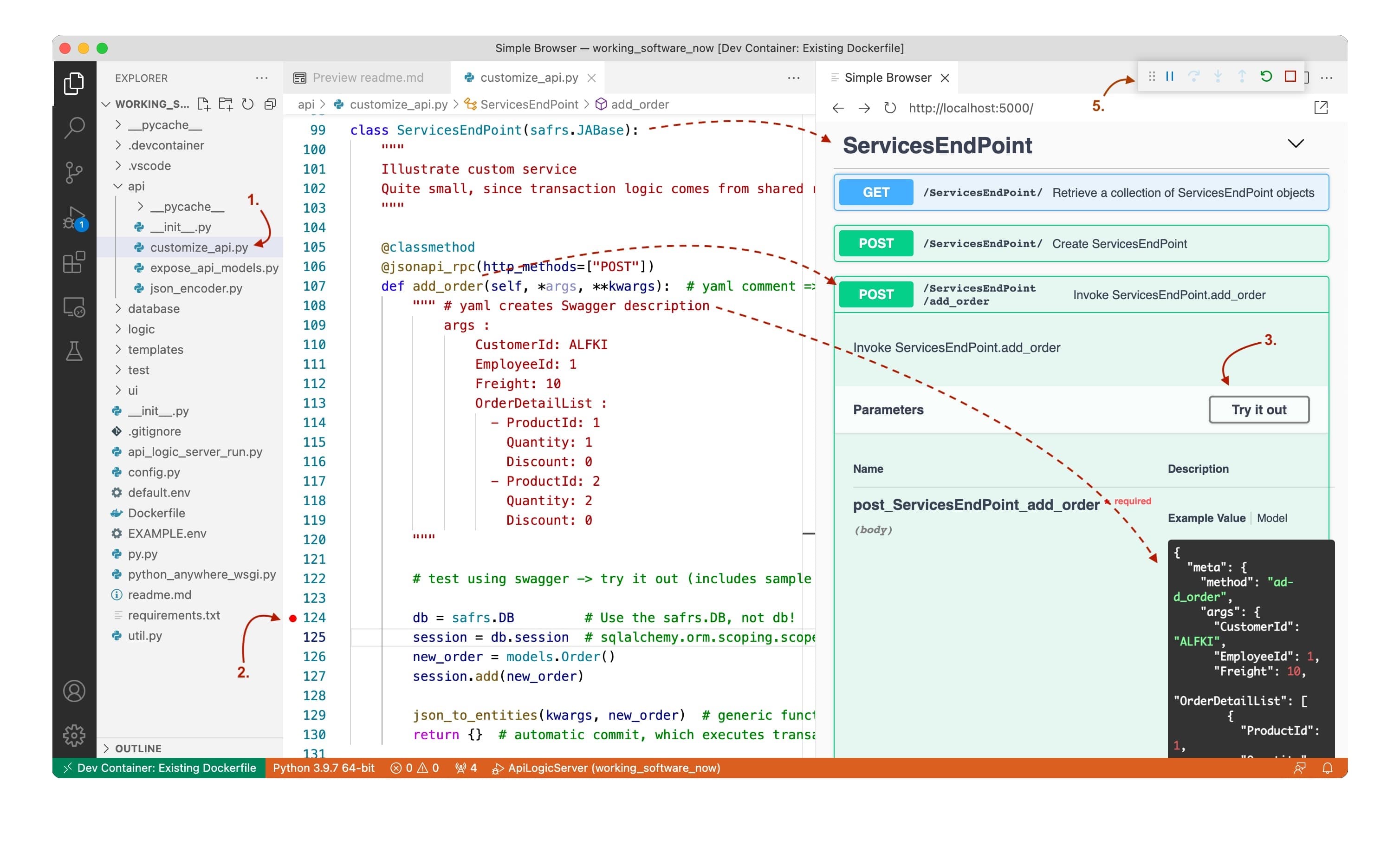
We can also customize the API. This code below (lines 124-130) defines a new endpoint, addOrder.
It's short since all the derivation and constraint logic is declared in rules as we'll see in a moment.
You can use your IDE to debug your customizations. Modern IDEs enable you to inspect variables, set watches, execute step-by-step, etc. In the diagram below:
- We use the Swagger (right pane) for our custom endpoint to submit an order consisting of an Order and a set of Order Details
- We set a breakpoint in our custom endpoint, line 124.
Declare Logic
For the transactional systems targeted by ApiLogicServer, it is common that the backend logic is nearly half the app: multi-table derivations and constraints, and actions such as sending mail or messages.
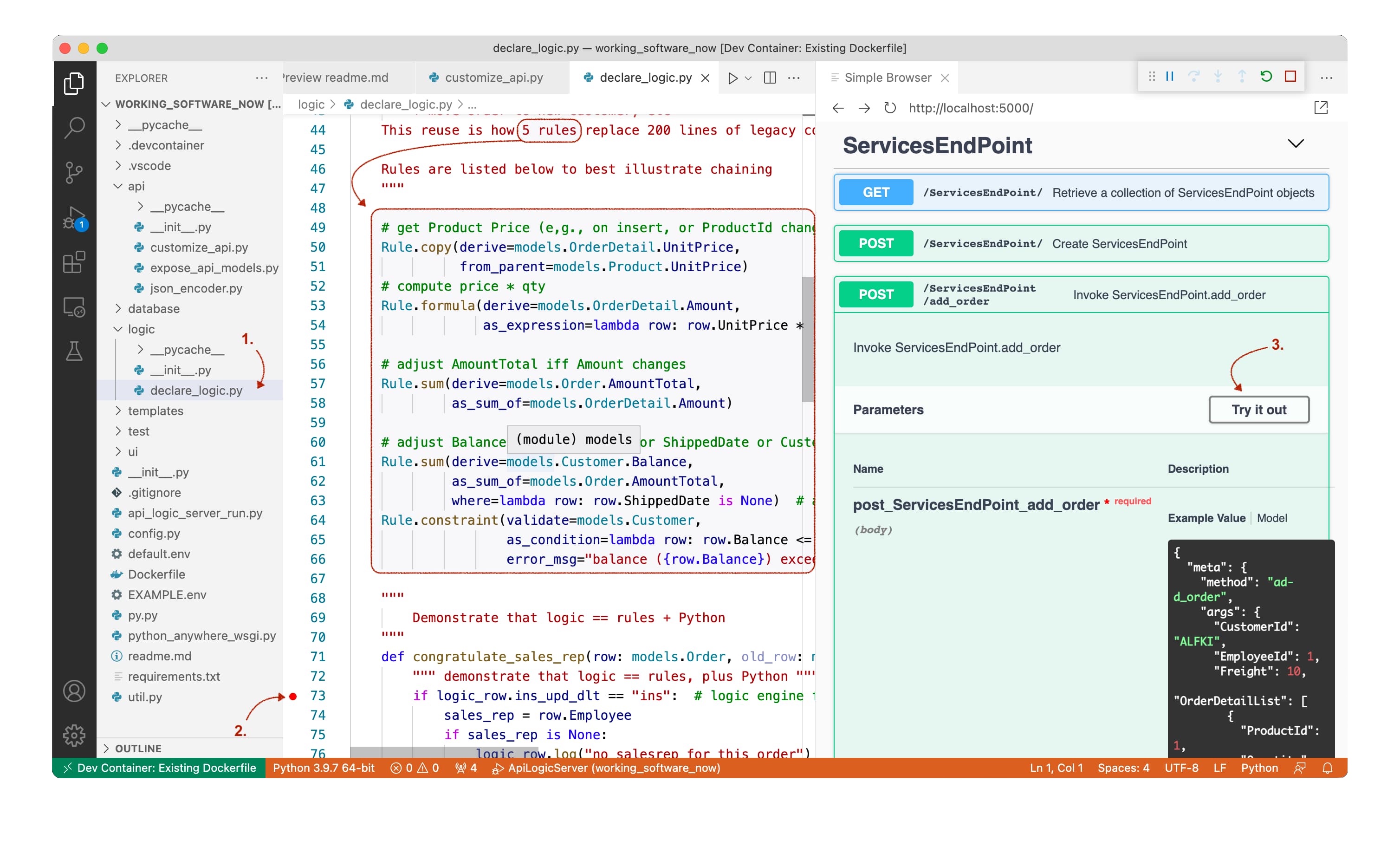
The problem is that a simple "cocktail napkin" specification of 5 lines explodes into 200 lines of code as shown below:

Instead of writing all the code, you can use ApiLogicServer to declare spreadsheet-like rules for multi-table derivations and constraints. These 5 rules shown below (lines 49-66) represent the same logic as 200 lines of Python - an executable representation of the cocktail napkin spec above.
Experience has shown that rules address 95% of backend logic. This is profound: you are reducing the back-end half of your system by 40:1 (200 lines of code / 5 rules).
The ApiLogicServer rules engine loads these rules when the server starts. It listens for SQLAlchemy update events, and automatically your logic as API updates are issued. Execution includes automation of ordering and optimization. This automation is repeated as your alter logic during iteration/maintenance, so you continue to derive value over the life of the project.
Extend rules with Python events, for actions like sending mail or messages. This is how you address the 5% of logic not addressed by rules. See the event handler below, partially shown on lines 71-76. Again, we can set a breakpoint (line 73), and retry our transaction. We can inspect our rows, and
step through our events.
 Key Take-away: back-end logic is a key element for transactional systems. It is often ignored by No/Low-Code approaches, or addressed with "your code goes here". ApiLogicServer not only creates projects in moments but enables you to customize them, using declarative rules that dramatically increase business agility.
Key Take-away: back-end logic is a key element for transactional systems. It is often ignored by No/Low-Code approaches, or addressed with "your code goes here". ApiLogicServer not only creates projects in moments but enables you to customize them, using declarative rules that dramatically increase business agility.
Acknowledgments
Much of the work here is through the efforts of Thomas Pollet. In particular, it's his work behind the API and the admin app. I also appreciate the help of long-time friend Max Tardiveau, who guided me through some rocky Docker moments.
Technology Considerations
This section summarizes the key aspects of the technology and addresses some questions we are sometimes asked.
Key Aspects: Automation, Model-Driven
Perhaps the most striking thing about ApiLogicServer is automation: the create command builds a complete admin app and API, in moments.
But it's also important to consider what is built from the create command. Not just a project you can customize and debug in your IDE... the created artifacts are models that declare "what, not how". These models are far simpler to understand, modify and maintain than enormous amounts of generated code.
Learning Curve?
Learning a new technology is overhead that must be weighed against the gain. Let's look at the gains and the elements that must be learned.
For transactional systems, the gain is considerable -- the create command represents weeks or months of saved effort. Let's examine the overhead.
The create command requires no particular background in Python, just basic development and database skills. That leaves 2 things to learn: Python (if you don't already know it), and rules.
Python is required for customization. Importantly, this is not "from scratch" coding -- the create command builds your project structure and a working system. So you're always adding code to a working base - much simpler than a cold start. And the amount of Python you need for basic customizations is easily mastered in a day or so, particularly given the examples.
Rules are certainly new. There are 10 rules, so learning them is pretty quick. The real trick is learning to "think spreadsheet" - instead of code, declaring multiple rules to address a requirement. These examples should help nail down the key patterns. Experience suggests 2 days should be sufficient to ramp up on rules.
Proven Technology?
There's a great deal of innovation here - automated construction of apps and APIs, and rules. It's a natural question whether it stands up to serious applications.
As it turns out, this is in fact a proven technology. It began with the Wang PACE system, installed at over 6500 sites. The technology evolution continued at Versata, with over 700 sites, a multi-billion dollar IPO, and backed by the founders of Microsoft, SAP, Informix, and Ingres. Customers paid around $50k per computer for these products.
Why Not Rete?
Some have asked why there is a rules engine instead of a Rete engine. Rete has proven to be a poor choice for transaction processing due to poor multi-table performance. In particular, chained aggregates result in many high-cost SQL commands.
For example, consider substituting a different Product for an Order Detail - the system must recompute the balance and ensure it does not exceed the credit limit. A Rete engine would add up all the Orders, and all their Order Details, to compute the new Balance.
The transaction logic engine in ApiLogicServer was designed specifically to address this problem, with automatic pruning and optimization. The key is integrating logic into the persistence mechanism (SQLAlchemy), which enables the system to compare old/new values on an update, use prune rules for unchanged data, and use deltas to replace chained aggregates with a single adjustment update. This has been shown to reduce transaction times from minutes to sub-second.
The example here presumes the use of stored aggregates. It is a design choice whether aggregates are stored or virtual; altering the schema will automatically re-optimize the transaction logic. This enables you to change your design, late in the project, without having to recode all the related logic.
Summary
So there you have it. In a few moments, you can create a complete system, ready for Agile collaboration and near-instant iteration. You can customize and debug the app, API, and logic in your IDE, and manage it with your existing source control systems.
We saw how the system is mainly models - executable descriptions of what we want, not the detailed code to build it. Much simpler to get started, customize and maintain. And it runs in an isolated container, for clean development and deployment.
To explore it further:
- Open Source: the GitHub site contains install instructions, samples, documentation, and tutorials
- Explore the app: you can explore this application and API, running on PythonAnywhere
- Video: watch how this application was built on YouTube
Thanks for reading!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK