

(juc系列)forkjoin框架源码学习
source link: http://huyan.couplecoders.tech/java/2021/10/14/(juc%E7%B3%BB%E5%88%97)ForkJoin%E6%A1%86%E6%9E%B6%E6%BA%90%E7%A0%81%E5%AD%A6%E4%B9%A0/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

JUC系列提供的又一个线程池,采用分治思想,及工作窃取策略,能获得更高的并发性能.
通过将大任务,切割成小任务并发执行,由每一个任务等待所有子任务的返回. 大概可以理解为递归的思路.
比如要计算1~100的累加和.
那么任务: sum(1,100).
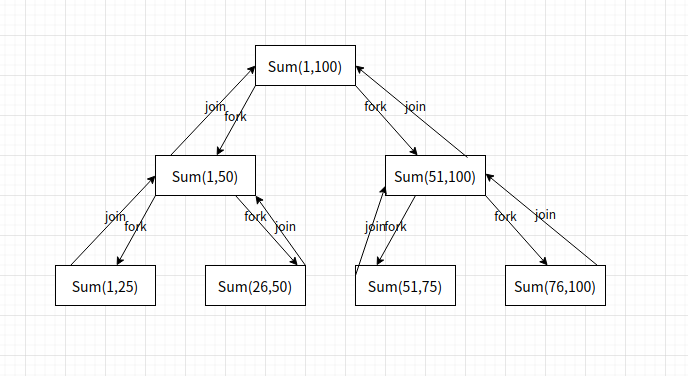
首先不断的切分,直到单个任务足够小,然后并发运行,之后再进行join收集操作.
工作窃取策略
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
每个线程有自己的工作队列,当自己的工作队列为空,随机从别的线程的工作队列尾部窃取一个任务进行执行.这样可以有效的提升并发度.
Fork/Join框架,主要分为三个部分:
- ForkJoinPool 线程池,管理线程
- ForkJoinTask 任务基类,定义一个任务
- ForkJoinWorkerThread 线程,实现任务执行等
这三个模块的关系是:
ForkJoinPool调用池中的ForkJoinWorkerThread,来执行ForkJoinTask.
下面就结合源码,逐一介绍这三个部分.
ForkJoinPool 线程池,负责调度
官方注释简介
这是官方注释的简单翻译版本.
用来运行ForkJoinTask的一个线程池. ForkJoinPool提供了提交非fork/join任务的客户端,以及管理和监控操作.
ForkJoinPool和其他线程池不同的是,它实现了工作窃取算法: 所有池中的线程都尝试去寻找并执行任务. 包括提交到线程池的任务或者被其他任务创建的任务.(如果一个任务都没有, 最终所有的线程阻塞).
这个算在大多数任务都会创建一些新的子任务,或者大量的小任务被提交时,有更好的效率.
尤其当asyncMode在构造函数中被设置为true时, ForkJoinPool也可以适配事件型的任务. 所有的工作线程初始化为守护线程.
静态的commonPool()是对大多数应用是可用且合适的. 公用的池用来执行那些没有被明确提交给特殊线程池的任务.
使用公用的线程池通常能够减少资源的使用.
需要分离的或者定制化的线程池的任务,ForkJoinPool用一个给定的并发等级来进行初始化. 默认情况下,这个数字等于可用的处理器的数量.
线程池尝试保持足够活跃的线程,通过动态的添加暂停或者唤醒内部的工作线程.
然而,没有什么调整是保证的, 在面对阻塞式IO或者其他没有被管理的同步操作时.
嵌套的ManagedBlocker接口允许扩展一些同步器. 默认的策略可以使用构造器来覆盖. 具体的文档在ThreadPoolExecutor里面.
为了执行和生命周期的管理,这个类提供了状态检查方法, getStealCount等用来帮助开发,调试和监控fork/join的应用程序.
另外,toString返回线程池状态,以进行一些非正式的监控.
在其他的ExecutorService中,有三种主要的执行策略,总结在下面的表中.
他们主要设计用于没有进行fork/join操作的客户端使用.
这些方法的主要形式接受 ForkJoinTask 的实例,但重载形式也允许混合执行普通的基于 Runnable 或 Callable 的活动。但是,已经在池中执行的任务通常应该使用表中列出的计算内形式,除非使用通常不加入的异步事件样式任务,在这种情况下,方法选择之间几乎没有区别
构造共用池的参数,可以被一下属性进行控制:
- parallelism 并发等级,一个不为负数的整数
- threadFactory 线程工厂,
- exceptionHandler 异常处理器
- maximumSpares 为了保持目标并发等级,最大允许的线程数量
注意,这个类限制最大的运行线程树为32767.尝试创建更多的线程将会抛出异常.
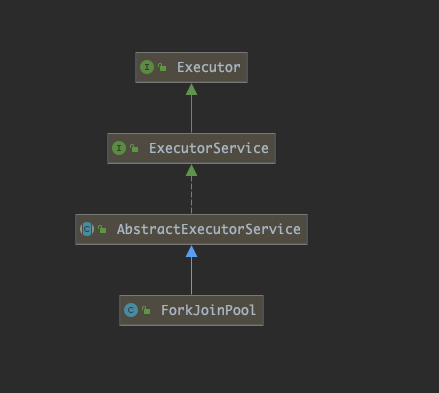
类继承结构图:
工作队列 WorkQueue
首先介绍一个内部类,是一个工作队列的实现.
它实现了双端的队列,用来对单个任务进行管理. 且一个工作队列被一个工作的线程持有.
volatile int source; // source queue id, or sentinel 源队列ID
int id; // pool index, mode, tag 池ID
int base; // index of next slot for poll // 下一个拿的index
int top; // index of next slot for push // 下一个放的index
volatile int phase; // versioned, negative: queued, 1: locked // 1是锁定. 负数是有队列
int stackPred; // pool stack (ctl) predecessor link //
int nsteals; // number of steals // 偷取任务数量
ForkJoinTask<?>[] array; // the queued tasks; power of 2 size // 队列中的任务
final ForkJoinPool pool; // the containing pool (may be null) // 池子
final ForkJoinWorkerThread owner; // owning thread or null if shared // 所属线程
核心属性: array保存了队列中的所有任务,同时提供队列头和尾两个指针,用于进行双端队列的出队和入队等.
push 入队任务
这是个内部的方法,仅被非共享的队列调用.
主要用于任务分解为子任务后,调用fork.此时,将任务放到当前线程已经持有的队列中.会调用这个方法.
final void push(ForkJoinTask<?> task) {
ForkJoinTask<?>[] a;
int s = top, d = s - base, cap, m;
ForkJoinPool p = pool;
// 已有队列
if ((a = array) != null && (cap = a.length) > 0) {
// CAS更新任务
QA.setRelease(a, (m = cap - 1) & s, task);
// 下标+1
top = s + 1;
// 数组满了,扩容
if (d == m)
growArray(false);
else if (QA.getAcquire(a, m & (s - 1)) == null && p != null) {
VarHandle.fullFence(); // was empty
// 新搞一个线程过来? TODO
p.signalWork(null);
}
}
}
通过CAS向数组中添加任务,成功后如果需要扩容任务数组.
poll 出队
final ForkJoinTask<?> poll() {
int b, k, cap; ForkJoinTask<?>[] a;
// 队列中有值,
while ((a = array) != null && (cap = a.length) > 0 &&
top - (b = base) > 0) {
// 从数组中获取一个任务
ForkJoinTask<?> t = (ForkJoinTask<?>)
QA.getAcquire(a, k = (cap - 1) & b);
if (base == b++) {
if (t == null)
Thread.yield(); // await index advance
// 置为空
else if (QA.compareAndSet(a, k, t, null)) {
BASE.setOpaque(this, b);
// 返回任务
return t;
}
}
}
return null;
}
从工作队列中取一个任务返回.
// 获取第一个任务
final ForkJoinTask<?> peek() {
int cap; ForkJoinTask<?>[] a;
return ((a = array) != null && (cap = a.length) > 0) ?
a[(cap - 1) & ((id & FIFO) != 0 ? base : top - 1)] : null;
}
// 权限
static final RuntimePermission modifyThreadPermission;
// common pool
static final ForkJoinPool common;
// 并发度
static final int COMMON_PARALLELISM;
// 偷取数量
volatile long stealCount; // collects worker nsteals
// 保持活跃的时间
final long keepAlive; // milliseconds before dropping if idle
// 下一个工作线程的下标
int indexSeed; // next worker index
// 最小最大线程
final int bounds; // min, max threads packed as shorts
// 并发度
volatile int mode; // parallelism, runstate, queue mode
// 工作队列
WorkQueue[] workQueues; // main registry
// 工作线程的前缀
final String workerNamePrefix; // for worker thread string; sync lock
// 线程工厂
final ForkJoinWorkerThreadFactory factory;
// 异常处理器
final UncaughtExceptionHandler ueh; // per-worker UEH
// 是否饱和的判断方法
final Predicate<? super ForkJoinPool> saturate;
// 核心的状态控制
@jdk.internal.vm.annotation.Contended("fjpctl") // segregate
volatile long ctl; // main pool control
ForkJoinPool的一些属性,核心属性:
- workQueues: 保存了当前的一些工作队列
- ctl 线程池的状态记录,由一个long. 按位进行编码,存储相关信息.
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false,
0, MAX_CAP, 1, null, DEFAULT_KEEPALIVE, TimeUnit.MILLISECONDS);
}
public ForkJoinPool(int parallelism) {
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false,
0, MAX_CAP, 1, null, DEFAULT_KEEPALIVE, TimeUnit.MILLISECONDS);
}
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode) {
this(parallelism, factory, handler, asyncMode,
0, MAX_CAP, 1, null, DEFAULT_KEEPALIVE, TimeUnit.MILLISECONDS);
}
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode,
int corePoolSize,
int maximumPoolSize,
int minimumRunnable,
Predicate<? super ForkJoinPool> saturate,
long keepAliveTime,
TimeUnit unit) {
// check, encode, pack parameters
// 并行度
if (parallelism <= 0 || parallelism > MAX_CAP ||
maximumPoolSize < parallelism || keepAliveTime <= 0L)
throw new IllegalArgumentException();
// 工厂
if (factory == null)
throw new NullPointerException();
// 活跃时间
long ms = Math.max(unit.toMillis(keepAliveTime), TIMEOUT_SLOP);
// 线程数量
int corep = Math.min(Math.max(corePoolSize, parallelism), MAX_CAP);
// ctl变量的值
long c = ((((long)(-corep) << TC_SHIFT) & TC_MASK) |
(((long)(-parallelism) << RC_SHIFT) & RC_MASK));
// mode
int m = parallelism | (asyncMode ? FIFO : 0);
int maxSpares = Math.min(maximumPoolSize, MAX_CAP) - parallelism;
int minAvail = Math.min(Math.max(minimumRunnable, 0), MAX_CAP);
// bounds
int b = ((minAvail - parallelism) & SMASK) | (maxSpares << SWIDTH);
int n = (parallelism > 1) ? parallelism - 1 : 1; // at least 2 slots
// 初始工作队列的数量
n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16;
n = (n + 1) << 1; // power of two, including space for submission queues
this.workQueues = new WorkQueue[n];
// 线程池前缀
this.workerNamePrefix = "ForkJoinPool-" + nextPoolId() + "-worker-";
// 赋值
this.factory = factory;
this.ueh = handler;
this.saturate = saturate;
this.keepAlive = ms;
this.bounds = b;
this.mode = m;
this.ctl = c;
checkPermission();
}
提供了4个构造方法,都是调用的最后一个。
计算了一堆参数.比如并行度,活跃时间,初始的工作队列数量,模式,ctl变量的初始值等等.
由ForkJoinPool进行任务管理,因此它负责接受外部提交的任务.
- invoke
- execute
- execute
- submit
- submit
- submit
- submit
- invokeAll
这些方法都是类似于execute方法,接受Runnable,Callable,ForkJoinTask三种任务,进行一定的封装,然后进行提交.
内部都是调用的externalSubmit方法.见下面的解析:
execute
public void execute(Runnable task) {
if (task == null)
throw new NullPointerException();
ForkJoinTask<?> job;
if (task instanceof ForkJoinTask<?>) // avoid re-wrap
job = (ForkJoinTask<?>) task;
else
job = new ForkJoinTask.RunnableExecuteAction(task);
// 核心的外部提交方法
externalSubmit(job);
}
ForkJoinTask.RunnableExecuteAction
是对ForkJoinTask进行简单实现,包装一个Runnable的简单内部类.
首先对提交的任务进行wrap.之后调用externalSubmit.
externalSubmit
private <T> ForkJoinTask<T> externalSubmit(ForkJoinTask<T> task) {
Thread t; ForkJoinWorkerThread w; WorkQueue q;
if (task == null)
throw new NullPointerException();
// 当前线程就是一个`ForkJoin`类型的线程,直接调用该线程的队列进行push, 说明是内部分裂开的任务,直接入队当前线程的队列
if (((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) &&
(w = (ForkJoinWorkerThread)t).pool == this &&
(q = w.workQueue) != null)
// 调用上方介绍过的`workQueue.push`方法
q.push(task);
else
// 调用externalPush进行提交任务
externalPush(task);
return task;
}
核心逻辑:
- 如果当前线程,就是一个
ForkJoin类型的线程,那么说明是内部分裂开的任务,直接入队当前线程的任务队列即可. - 否则调用
externalPush进行提交任务.见下方.
externalPush
final void externalPush(ForkJoinTask<?> task) {
int r; // initialize caller's probe
// 随机一个探针
if ((r = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit();
r = ThreadLocalRandom.getProbe();
}
for (;;) {
WorkQueue q;
int md = mode, n;
WorkQueue[] ws = workQueues;
if ((md & SHUTDOWN) != 0 || ws == null || (n = ws.length) <= 0)
throw new RejectedExecutionException();
// 该位置为空. 新建一个工作队列,加锁入队.
else if ((q = ws[(n - 1) & r & SQMASK]) == null) { // add queue
int qid = (r | QUIET) & ~(FIFO | OWNED);
Object lock = workerNamePrefix;
// 新建一个工作队列的操作
ForkJoinTask<?>[] qa =
new ForkJoinTask<?>[INITIAL_QUEUE_CAPACITY];
q = new WorkQueue(this, null);
q.array = qa;
q.id = qid;
q.source = QUIET;
if (lock != null) { // unless disabled, lock pool to install
synchronized (lock) {
// 放到对应位置上.
WorkQueue[] vs; int i, vn;
if ((vs = workQueues) != null && (vn = vs.length) > 0 &&
vs[i = qid & (vn - 1) & SQMASK] == null)
vs[i] = q; // else another thread already installed
}
}
}
// 如果工作队列的当前位置在忙,重新随机一个位置.
else if (!q.tryLockPhase()) // move if busy
r = ThreadLocalRandom.advanceProbe(r);
else {
// 该位置不为空,且不忙,就唤醒来干活了.
if (q.lockedPush(task))
signalWork(null);
return;
}
}
}
在已有的工作队列中,随机一个位置:
- 如果该位置为空,则为当前的任务新建一个工作队列.
- 如果该位置有工作队列,且正在忙,随机另外一个位置.
- 如果当前位置有工作队列,但是空闲,则唤醒让其工作.
ForkJoinTask 任务定义,负责计算逻辑,任务拆分等
官方注释简单翻译
使用ForkJoinPool执行的任务的一个基类. 一个ForkJoinTask是一个类似于线程的实体,但是比一个真正的线程更加轻量级.
在ForkJoinPool中,很多的任务和子任务,可能被少量的实际线程管理. 作为代价,有些使用受限制.
一个主要的ForkJoinTask在明确提交给ForkJoinPool时开始执行,或者当前任务没有参与到ForkJoin囧穿,则通过fork,invoke等相关的方法,在ForkJoinPool.commonPool()中执行.
一旦开始执行,它通常会依次执行其他子任务.就像类名一样,大多数程序使用ForkJoinTask只采用Fork,join方法,或者像invokeAll这种衍生品.
然而,这个类还提供了许多可以在高级用法中发挥作用的其他方法,以及允许支持新形式的 fork/join 处理的扩展机制。
ForkJoinTask是Future的轻量级形式. 他的高效来源于一组限制(仅部分静态强制执行).它主要应用在计算纯函数,或者对隔离对象进行操作的计算任务.
主要的协调机制是:
- fork 安排异步执行
- join 等待任务的计算结果
计算中应该尽量避免同步方法或者代码块, 同时尽量减少其他的阻塞同步,除了等待其他任务或者使用Phasers等可以与fork/join调度合作的同步器.
子任务也应该尽量避免阻塞IO. 并且理想情况下,应该访问完全独立于其他任务的变量.
通过不允许抛出IOException等已检查异常,这些限制被强制执行. 但是,计算仍然可能遇到未经检查的异常,这些异常会被抛出.
可以定义和使用会阻塞的ForkJoinTask.但是这样做要考虑以下三个因素:
- 如果其他任务应该阻塞在外部的同步器或者io. 将无法完成. 事件类型的异步任务将永远不会joined,他们通常属于这一类.
- 为了尽量减少资源消耗,任务应该尽量小. 理想情况下只执行阻塞操作.
- 除非
ForkJoinPool.ManagedBlocker被使用,或者已知可能阻塞的任务数量小于ForkJoinPool.getParallelism等级.池子不保证有足够的线程,以达到较好的性能表现.
等待完成并提取结果的主要方法是join, 但是有一些变体:
Future.get()方法支持可中断,可超时的等待。
invoke方法在语义上等效与fork方法
join()方法永远尝试在当前线程开始执行. 这些方法都是静默形式的,不会提取结果或者报告异常. 这些方法在有一系列的任务等待执行,并且你需要延迟处理结果时很有用.
invokeAll方法和最常见的并发调用一样: 派生一系列的任务然后等待全部.
在典型的使用场景中,fork-join对就像递归调用中,一个call和一个return一样. 像其他的递归调用一样,返回操作应该尽快被执行.
任务的执行状态,可能会通过几种级别来查询细节,
isDone返回true,如果任务完成的话(包括被取消)isCompletedNormally返回true,如果任务没有取消或者抛出异常,而是正常执行结束.isCancelled返回ture,如果任务被取消。包含任务抛出取消异常.isCompletedAbnormally返回true, 如果一个任务被取消或者抛出异常了.
ForkJoinTask类通常不直接被继承,而是
ForkJoinTask类通常不会直接子类化。子类化一个支持特殊的fork/join处理风格的抽象类,
- 通常情况下,对于大多数不返回结果的计算,我们使用RecursiveAction;
- 对于返回结果的计算,我们使用RecursiveTask;
- 对于完成的操作触发其他操作的计算,我们使用CountedCompleter。
通常,具体的ForkJoinTask子类声明包含其参数的字段,在构造函数中建立,然后定义一个计算方法,该方法以某种方式使用该基类提供的控制方法。
join方法和他的变体只适合在没有循环以来的情况下使用. 也就是说,并行计算可以使用有向无环图(DAG)来描述.
否则,循环依赖的任务之间互相等待,可能造成死锁. 然后,这个框架支持一些其他的方法和技术(Phasers,helpQuiesce,complete),
可以为那些不是dag的问题构造子类.
大多数的基础方法都是final,以防止覆盖本质上与底层轻量级任务调度框架相关联的实现.
创建新的fork/join风格的开发人员应该最低限度的实现protected方法. exec,setRawResutl,getRawResult等.
同时还引入一个可以在其子类中实现的抽象计算方法,可能依赖于该类提供的其他受保护的方法。
ForkJoinTasks应该执行相对较少的计算量。通常通过递归分解将大任务分解为更小的子任务。 一个非常粗略的经验法则是,一个任务应该执行超过100个和少于10000个基本计算步骤,并且应该避免无限循环。 如果任务太大,并行性就不能提高吞吐量。如果太小,那么内存和内部任务维护开销可能会压倒处理。
这个类为Runnable和Callable提供了适配的方法, 当混合执行ForkJoinTasks和其他类型的任务时,这些方法可能会很有用。当所有任务都是这种形式时,考虑使用asyncMode构造池。
ForkJoinTasks是可序列化的,这使得它们可以用于远程执行框架等扩展。 合理的做法是只在执行之前或之后序列化任务,而不是在执行期间。在执行过程中并不依赖于序列化。
类结构图:
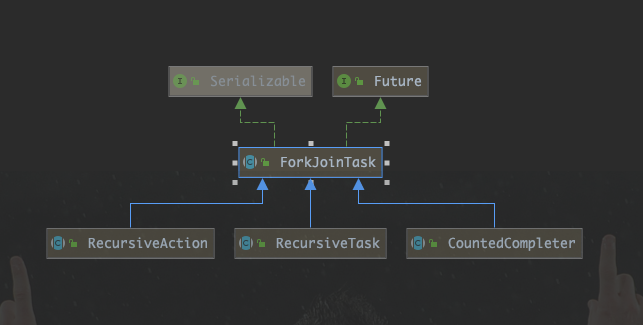
在模块结构中提过, ForkJoinTask负责任务的实际运行. 同时, 它实现了分治算法.
任务运行 doExec
final int doExec() {
int s; boolean completed;
// 当前任务状态正常
if ((s = status) >= 0) {
try {
// 调用抽象方法,进行任务的实际执行过程.
completed = exec();
} catch (Throwable rex) {
completed = false;
// 遇到异常了
s = setExceptionalCompletion(rex);
}
if (completed)
// 任务完成
s = setDone();
}
return s;
}
由于当前类,只是所有fork/join类型任务的基类,因此运行部分比较简单,判断任务状态正常后,调用exec()方法,进行计算逻辑的真正执行.
之后处理异常以及任务正常结束的情况即可.
exec()方法是预留给子类的接口, 方便子类嵌入具体的逻辑代码.
分治有两步,第一步,fork,也就是切分任务执行. 第二部,join,从子任务收集结果.
public final ForkJoinTask<V> fork() {
Thread t;
// 如果是工作线程的子任务切分,直接调用之前的`workQueue.push`将任务添加到当前线程的任务队列中去
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
// 如果是外部服务,直接调用fork,则调用之前的`externalPush`进行一个任务的提交
ForkJoinPool.common.externalPush(this);
return this;
}
public final V join() {
int s;
// 调用doJoin如果出错,报告异常.
if (((s = doJoin()) & ABNORMAL) != 0)
reportException(s);
// 拿到结果
return getRawResult();
}
其中getRawResult也是留给子类实现,返回当前任务的结果.
按照官方的设计, 我们很少会直接继承ForkJoinTask,而是继承它的几个给定的子类,去实现自己的逻辑.
官方介绍中,子类有三个.
RecursiveAction
一个递归的,没有返回结果的ForkJoinTask实现,定义了没有返回结果的行为,,应该返回一个Void.
public abstract class RecursiveAction extends ForkJoinTask<Void> {
private static final long serialVersionUID = 5232453952276485070L;
/**
* The main computation performed by this task.
*/
protected abstract void compute();
/**
* Always returns {@code null}.
*
* @return {@code null} always
*/
// 返回值永远是空
public final Void getRawResult() { return null; }
/**
* Requires null completion value.
*/
protected final void setRawResult(Void mustBeNull) { }
/**
* Implements execution conventions for RecursiveActions.
*/
protected final boolean exec() {
compute();
return true;
}
}
和上面的描述差不多,没有定义任何计算逻辑,但是定义了返回值是Void.且永远返回null. 这个类通常用来包装Runnable,因此Runnable真的没有返回值.
简单使用案例:
一个简单的,ForkJoin模式的排序.
static class SortTask extends RecursiveAction {
final long[] array; final int lo, hi;
SortTask(long[] array, int lo, int hi) {
this.array = array; this.lo = lo; this.hi = hi;
}
SortTask(long[] array) { this(array, 0, array.length); }
// 实现计算接口
protected void compute() {
// 排序范围不大,就排序
if (hi - lo < THRESHOLD)
sortSequentially(lo, hi);
else {
// 排序范围太大,就切分成两个任务,进行任务的提交
int mid = (lo + hi) >>> 1;
invokeAll(new SortTask(array, lo, mid),
new SortTask(array, mid, hi));
merge(lo, mid, hi);
}
}
// implementation details follow:
static final int THRESHOLD = 1000;
void sortSequentially(int lo, int hi) {
Arrays.sort(array, lo, hi);
}
// 合并结果集
void merge(int lo, int mid, int hi) {
long[] buf = Arrays.copyOfRange(array, lo, mid);
for (int i = 0, j = lo, k = mid; i < buf.length; j++)
array[j] = (k == hi || buf[i] < array[k]) ?
buf[i++] : array[k++];
}
}
这是一个将ForkJoin思路应用于排序的典型案例.
- 如果数据量很小,就直接排序
- 如果数据量较大,就分成两部分,各自提交任务排序
- 合并两个子部分的排序结果
一个更加简单的案例: 对数组中的每个元素递增1,也可以分治思想来做.
class IncrementTask extends RecursiveAction {
final long[] array; final int lo, hi;
IncrementTask(long[] array, int lo, int hi) {
this.array = array; this.lo = lo; this.hi = hi;
}
protected void compute() {
if (hi - lo < THRESHOLD) {
for (int i = lo; i < hi; ++i)
array[i]++;
}
else {
int mid = (lo + hi) >>> 1;
invokeAll(new IncrementTask(array, lo, mid),
new IncrementTask(array, mid, hi));
}
}
}
- 如果数组元素很少,就遍历递增.
- 如果数组元素较多,就切分成两部分,进行计算
- 不用收集结果了,因为是原址的递增
第三个小🌰: 对一个整数序列进行累加平方和.
double sumOfSquares(ForkJoinPool pool, double[] array) {
int n = array.length;
Applyer a = new Applyer(array, 0, n, null);
pool.invoke(a);
return a.result;
}
class Applyer extends RecursiveAction {
final double[] array;
final int lo, hi;
double result;
Applyer next; // keeps track of right-hand-side tasks
// 初始化
Applyer(double[] array, int lo, int hi, Applyer next) {
this.array = array; this.lo = lo; this.hi = hi;
this.next = next;
}
// 叶子节点
// 叶子节点不再继续分治,而是真的执行对应的计算
double atLeaf(int l, int h) {
double sum = 0;
for (int i = l; i < h; ++i) // perform leftmost base step
sum += array[i] * array[i];
return sum;
}
protected void compute() {
int l = lo;
int h = hi;
Applyer right = null;
// 根据getSurplusQueuedTaskCount结果,动态的调整是否继续分治下去
while (h - l > 1 && getSurplusQueuedTaskCount() <= 3) {
int mid = (l + h) >>> 1;
right = new Applyer(array, mid, h, right);
right.fork();
h = mid;
}
double sum = atLeaf(l, h);
while (right != null) {
// 如果右边的节点没有被偷, 继续计算
if (right.tryUnfork()) // directly calculate if not stolen
sum += right.atLeaf(right.lo, right.hi);
else {
right.join();
sum += right.result;
}
right = right.next;
}
result = sum;
}
}
这里使用的不是一分为2的分治思想,而是不断向右分治.
- 如果数组元素太多,且动态临界值符合条件,就不断的提交右边的任务
- 计算当前叶子节点
- 如果右边的任务没有被偷,也就是没有被别的工作线程执行,那么当前线程继续执行.
- 收集结果比较简单,累加即可.
通过特殊的分治方式,能够获得更好的性能.
RecursiveTask
一个递归的, 有结果返回的ForkJoinTask.主要用于封装Callable.
public abstract class RecursiveTask<V> extends ForkJoinTask<V> {
private static final long serialVersionUID = 5232453952276485270L;
/**
* The result of the computation.
*/
V result;
/**
* The main computation performed by this task.
* @return the result of the computation
*/
protected abstract V compute();
// 返回结果
public final V getRawResult() {
return result;
}
// 设置结果
protected final void setRawResult(V value) {
result = value;
}
/**
* Implements execution conventions for RecursiveTask.
*/
protected final boolean exec() {
result = compute();
return true;
}
}
由于支持返回值,因此是一个泛型类, 有个泛型参数V. 提供了设置结果和获取结果的方法.
示例: 计算斐波那契
class Fibonacci extends RecursiveTask<Integer> {
final int n;
Fibonacci(int n) { this.n = n; }
protected Integer compute() {
// 小于1,返回
if (n <= 1)
return n;
// 分别计算n-1和n-2.
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
// join返回
return f2.compute() + f1.join();
}
}
经典的斐波那契问题,采用递归算法,如果n<=1,返回结果,否则递归调用n-1和n-2. 然后调用join方法获取子任务的返回值.
需要注意,和RecursiveAction的不同, 在RecursiveAction的第三个示例中,虽然也有获取子任务的结果的操作,但是都是通过局部变量,
或者共享的数组来获取结果的,而不是像RecursiveTask,通过调用join来拿到子任务返回的值.
CountedCompleter
CountedCompleter 在任务完成执行后会触发执行一个自定义的钩子函数.
这个类执行子任务更加的厉害但是有点反直觉.pending个任务必须完成,以用来触发完成的钩子行为(onCompletion)定义.
pending count初始化为0,但是可以动态的修改,在tryComplete之前,如果代办的数量不为0, 将递减. 否则才执行完成的钩子行为.
代办的任务可以根据需要,由子类创建.
CountedCompleter必须实现compute方法,并且在返回之前调用一次tryComplete.这个类还可以重写onCompletion, 来重写一个新的完成行为,
onExceptionalCompletion, 可以重写一个新的异常完成行为.
一般情况下,CountedCompleter应该使用不需要返回值的版本, 他被定义为返回Void,然后一直返回null.如果需要返回值,需要自己去重写getRawResult.
代码比较长,这里就不贴了,如上面所述,对于
- compute
- onCompletion 两个方法,没有做出实现,需要子类去具体的进行实现.
- getRawResult
方法,返回的永远都是null. 如果需要有返回值的版本, 需要自己去定义且实现.
public static <E> void forEach(E[] array, Consumer<E> action) {
class Task extends CountedCompleter<Void> {
final int lo, hi;
Task(Task parent, int lo, int hi) {
super(parent); this.lo = lo; this.hi = hi;
}
public void compute() {
if (hi - lo >= 2) {
int mid = (lo + hi) >>> 1;
// must set pending count before fork
// 分解任务后, 需要先设置需要等待的子任务的数量
setPendingCount(2);
// 然后调用子任务的fork
new Task(this, mid, hi).fork(); // right child
new Task(this, lo, mid).fork(); // left child
}
else if (hi > lo)
// 执行操作
action.accept(array[lo]);
// 尝试完成整个任务.
tryComplete();
}
}
new Task(null, 0, array.length).invoke();
}
ForkJoinWorkerThread 负责执行ForkJoinTask
A thread managed by a ForkJoinPool, which executes ForkJoinTasks.
继承自Thread. 在ForkJoinPool中运行,执行ForkJoinTask.
final ForkJoinPool pool; // the pool this thread works in
final ForkJoinPool.WorkQueue workQueue; // work-stealing mechanics
protected ForkJoinWorkerThread(ForkJoinPool pool) {
// Use a placeholder until a useful name can be set in registerWorker
super("aForkJoinWorkerThread");
this.pool = pool;
this.workQueue = pool.registerWorker(this);
}
ForkJoinWorkerThread(ForkJoinPool pool, ClassLoader ccl) {
super("aForkJoinWorkerThread");
super.setContextClassLoader(ccl);
ThreadLocalRandom.setInheritedAccessControlContext(this, INNOCUOUS_ACC);
this.pool = pool;
this.workQueue = pool.registerWorker(this);
}
ForkJoinWorkerThread(ForkJoinPool pool,
ClassLoader ccl,
ThreadGroup threadGroup,
AccessControlContext acc) {
super(threadGroup, null, "aForkJoinWorkerThread");
super.setContextClassLoader(ccl);
ThreadLocalRandom.setInheritedAccessControlContext(this, acc);
ThreadLocalRandom.eraseThreadLocals(this); // clear before registering
this.pool = pool;
this.workQueue = pool.registerWorker(this);
}
除了进行权限等赋值之外:
- 记录当前线程在哪个线程池中工作.
- 向线程池中注册当前线程.拿到当前线程对应的工作队列.
注册的方法调用的是ForkJoinPool.registerWorker.
final WorkQueue registerWorker(ForkJoinWorkerThread wt) {
UncaughtExceptionHandler handler;
wt.setDaemon(true); // configure thread
if ((handler = ueh) != null)
wt.setUncaughtExceptionHandler(handler);
int tid = 0; // for thread name
int idbits = mode & FIFO;
String prefix = workerNamePrefix;
// 以当前线程创建一个工作队列,
WorkQueue w = new WorkQueue(this, wt);
if (prefix != null) {
synchronized (prefix) {
WorkQueue[] ws = workQueues; int n;
int s = indexSeed += SEED_INCREMENT;
idbits |= (s & ~(SMASK | FIFO | DORMANT));
if (ws != null && (n = ws.length) > 1) {
int m = n - 1;
tid = m & ((s << 1) | 1); // odd-numbered indices
// 找个空的位置
for (int probes = n >>> 1;;) { // find empty slot
WorkQueue q;
if ((q = ws[tid]) == null || q.phase == QUIET)
break;
else if (--probes == 0) {
tid = n | 1; // resize below
break;
}
else
tid = (tid + 2) & m;
}
w.phase = w.id = tid | idbits; // now publishable
if (tid < n)
// 创建的工作队列,放入到线程池的工作队列数组中去.
ws[tid] = w;
else { // expand array
// 重新创建工作队列的数组,
int an = n << 1;
WorkQueue[] as = new WorkQueue[an];
// 当前工作队列放进去
as[tid] = w;
int am = an - 1;
// 复制原有的所有任务过来
for (int j = 0; j < n; ++j) {
WorkQueue v; // copy external queue
if ((v = ws[j]) != null) // position may change
as[v.id & am & SQMASK] = v;
if (++j >= n)
break;
as[j] = ws[j]; // copy worker
}
workQueues = as;
}
}
}
wt.setName(prefix.concat(Integer.toString(tid)));
}
return w;
}
- 以当前线程,创建一个工作队列.
- 在线程池原有的工作队列数组中,找一个空位放下当前的工作队列.
- 如果没地方,就扩容一下原有的数组,复制老的所有工作队列过来,并且放入当前的工作队列.
run 线程运行
既然是一个线程的子类,那么启动也是调用run方法.
public void run() {
// 线程启动时,当前线程需要执行的任务必须为空.
if (workQueue.array == null) { // only run once
Throwable exception = null;
try {
// 调用启动前的hook
onStart();
// 启动当前工作线程
pool.runWorker(workQueue);
} catch (Throwable ex) {
exception = ex;
} finally {
try {
// 调用终止时的hook.
onTermination(exception);
} catch (Throwable ex) {
if (exception == null)
exception = ex;
} finally {
// 注销当前工作线程
pool.deregisterWorker(this, exception);
}
}
}
}
当工作线程被启动:
- 调用相关hook.
- 调用
ForkJoinPool.runWorker,启动当前工作队列.开始干活. - 结束前向线程注销自己这个工作队列.
一个工作线程,封装成一个工作队列,带有自己的任务列表,启动!
ForkJoinPool.runWorker 工作线程启动
final void runWorker(WorkQueue w) {
int r = (w.id ^ ThreadLocalRandom.nextSecondarySeed()) | FIFO; // rng
// 初始化任务数组
w.array = new ForkJoinTask<?>[INITIAL_QUEUE_CAPACITY]; // initialize
for (;;) {
int phase;
// 扫描到任务了.
if (scan(w, r)) { // scan until apparently empty
r ^= r << 13; r ^= r >>> 17; r ^= r << 5; // move (xorshift)
}
else if ((phase = w.phase) >= 0) { // enqueue, then rescan
long np = (w.phase = (phase + SS_SEQ) | UNSIGNALLED) & SP_MASK;
long c, nc;
do {
w.stackPred = (int)(c = ctl);
nc = ((c - RC_UNIT) & UC_MASK) | np;
} while (!CTL.weakCompareAndSet(this, c, nc));
}
else { // already queued
// 没任务了,休眠一阵时间
int pred = w.stackPred;
Thread.interrupted(); // clear before park
w.source = DORMANT; // enable signal
long c = ctl;
int md = mode, rc = (md & SMASK) + (int)(c >> RC_SHIFT);
if (md < 0) // terminating
break;
else if (rc <= 0 && (md & SHUTDOWN) != 0 &&
tryTerminate(false, false))
break; // quiescent shutdown
else if (w.phase < 0) {
if (rc <= 0 && pred != 0 && phase == (int)c) {
long nc = (UC_MASK & (c - TC_UNIT)) | (SP_MASK & pred);
long d = keepAlive + System.currentTimeMillis();
LockSupport.parkUntil(this, d);
if (ctl == c && // drop on timeout if all idle
d - System.currentTimeMillis() <= TIMEOUT_SLOP &&
CTL.compareAndSet(this, c, nc)) {
w.phase = QUIET;
break;
}
}
else {
LockSupport.park(this);
if (w.phase < 0) // one spurious wakeup check
LockSupport.park(this);
}
}
w.source = 0; // disable signal
}
}
}
一个工作线程启动后,首先进行自旋:
- 扫描任务,
- 没有任务,重新扫描
- 还是没有,就休眠一段时间.等待唤醒.
scan 扫描任务
private boolean scan(WorkQueue w, int r) {
WorkQueue[] ws; int n;
// 检查参数, 当前线程池必须有工作队列的数组,且要扫描的当前工作队列不为空
if ((ws = workQueues) != null && (n = ws.length) > 0 && w != null) {
for (int m = n - 1, j = r & m;;) {
WorkQueue q; int b;
if ((q = ws[j]) != null && q.top != (b = q.base)) {
int qid = q.id;
ForkJoinTask<?>[] a; int cap, k; ForkJoinTask<?> t;
if ((a = q.array) != null && (cap = a.length) > 0) {
t = (ForkJoinTask<?>)QA.getAcquire(a, k = (cap - 1) & b);
if (q.base == b++ && t != null &&
QA.compareAndSet(a, k, t, null)) {
q.base = b;
w.source = qid;
// 如果任务比较多,唤醒其他工作线程
if (a[(cap - 1) & b] != null)
signalWork(q); // help signal if more tasks
// 当前工作线程干活
w.topLevelExec(t, q, // random fairness bound
(r | (1 << TOP_BOUND_SHIFT)) & SMASK);
}
}
return true;
}
else if (--n > 0)
j = (j + 1) & m;
else
break;
}
}
return false;
}
扫描任务时,如果发现任务过多,就协助唤醒一些工作线程.然后让当前工作线程开始干活.
signalWork 唤醒其他工作线程
final void signalWork(WorkQueue q) {
for (;;) {
long c; int sp; WorkQueue[] ws; int i; WorkQueue v;
// 有足够多的工作线程,说明不需要唤醒了,退出
if ((c = ctl) >= 0L) // enough workers
break;
// 没有空闲线程
else if ((sp = (int)c) == 0) { // no idle workers
// 线程数很少,添加一个线程
if ((c & ADD_WORKER) != 0L) // too few workers
tryAddWorker(c);
break;
}
// 线程池终止了,退出
else if ((ws = workQueues) == null)
break; // unstarted/terminated
else if (ws.length <= (i = sp & SMASK))
break; // terminated
else if ((v = ws[i]) == null)
break; // terminating
else {
// 唤醒一个其他的线程
int np = sp & ~UNSIGNALLED;
int vp = v.phase;
long nc = (v.stackPred & SP_MASK) | (UC_MASK & (c + RC_UNIT));
Thread vt = v.owner;
if (sp == vp && CTL.compareAndSet(this, c, nc)) {
v.phase = np;
if (vt != null && v.source < 0)
LockSupport.unpark(vt);
break;
}
else if (q != null && q.isEmpty()) // no need to retry
break;
}
}
}
进行一些参数的判断:
- 如果当前工作线程够用,退出.
- 如果当前没有空闲的线程,新创建一个工作线程.
- 其他情况找一个工作线程,唤醒他.让他干活.
tryAddWorker
// 尝试添加一个工作线程
private void tryAddWorker(long c) {
do {
long nc = ((RC_MASK & (c + RC_UNIT)) |
(TC_MASK & (c + TC_UNIT)));
if (ctl == c && CTL.compareAndSet(this, c, nc)) {
// 创建线程
createWorker();
break;
}
} while (((c = ctl) & ADD_WORKER) != 0L && (int)c == 0);
}
// 创建工作线程
private boolean createWorker() {
ForkJoinWorkerThreadFactory fac = factory;
Throwable ex = null;
ForkJoinWorkerThread wt = null;
try {
// 创建一个线程并运行
if (fac != null && (wt = fac.newThread(this)) != null) {
// 默认的实现是下方的Thread.
wt.start();
return true;
}
} catch (Throwable rex) {
ex = rex;
}
// 注销一个工作线程
deregisterWorker(wt, ex);
return false;
}
topLevelExec 顶层的执行任务
final void topLevelExec(ForkJoinTask<?> t, WorkQueue q, int n) {
int nstolen = 1;
for (int j = 0;;) {
// 调用`doExec`执行一个`ForkJoinTask`.
if (t != null)
t.doExec();
if (j++ <= n)
t = nextLocalTask();
else {
j = 0;
t = null;
}
if (t == null) {
// 从q里面偷一个任务过来执行
if (q != null && (t = q.poll()) != null) {
++nstolen;
j = 0;
}
else if (j != 0)
break;
}
}
ForkJoinWorkerThread thread = owner;
nsteals += nstolen;
source = 0;
if (thread != null)
thread.afterTopLevelExec();
}
总结工作线程的一生
懒得画流程图,打字吧.
- 提交新任务时,会创建一个工作线程. 然后启动.
- 启动后扫描任务,扫描到任务就自己执行.扫描不到就自己休眠等待唤醒.
- 扫描过程中,如果发现任务太多,就唤醒2中处于休眠状态的其他工作线程一起干活.
- 唤醒过程中,发现没有空闲的线程,都很累,活还干不完,就新建一个线程,这个新的线程也从1开始执行.
ForkJoin框架的代码,是目前我看jdk代码看的最懵的一次,十分复杂. 本文主要从基本原理上阅读了相关代码, 对于其中ctl的属性按位编码,没有过于深究,需要了解的朋友们可以自行阅读及调试.
ForkJoin框架,提供了对线程池调度任务,更好的灵活性,更高的并行性及性能,但是也不是无敌的. 使用时尤其需要注意以下几点:
- 避免不必要的fork
fork是提交进入队列操作,如果一个任务会分割成两个任务,那么两个任务都fork,是有一次进队出队的浪费的. 应该
task -> task1 + task2
task1.fork();
task2.compute();
- 合理的任务粒度
这个和普通线程池一样, 任务过大,无法充分发挥并行性,任务过小,调度浪费的算力都赶上使用线程池增大的算力了.
实践出真知,代码开发的灵活一些,设置参数调试最优解吧~
- fork与join的顺序
在同一个工作线程中, 将大任务分割成两个子任务,分别提交,等待返回.和普通的多线程开发很相似,这时就要注意任务的提交和等待顺序,否则可能白忙活一场.比如:
task -> task1 + task2
task1.fork();
task1.join();
task2.fork();
task2.join();
这样的代码,本质上接近于串行执行了,性能肯定好不了.
- 避免重量级的任务划分和结果合并操作
从上面的例子可见,对于ForkJoinPool的使用,很多时候都是在处理集合List/Array中的数据等, 那么在划分任务和收集结果时,避免设计出大量的拷贝,二次计算操作.
从而尽量避免调度任务的开销,将算力花在真正的”计算逻辑”上.
源码作者的《A Java Fork/Join Framework》 Java全栈知识体系的一篇文章
给我很多启发,尤其是最后的注意事项部分.
最后,欢迎关注我的个人公众号【 呼延十 】,会不定期更新很多后端工程师的学习笔记。
也欢迎直接公众号私信或者邮箱联系我,一定知无不言,言无不尽。

以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
联系邮箱:[email protected]
更多学习笔记见个人博客或关注微信公众号 <呼延十 >——>呼延十
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK