

Linux进程调度技术的前世今生之“前世”
source link: https://www.heapdump.cn/article/2705044
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Linux进程调度技术的前世今生之“前世”
随着内核版本的演进,其源代码的膨胀速度也在递增,这让Linux的学习曲线变得越来越陡峭了。这对初识内核的同学而言当然不是什么好事情,满腔热情很容易被当头浇灭。我有一个循序渐进的方法,那就是先不要看最新的内核,首先找到一个古老版本的内核(一般都会比较简单),将其吃透,然后一点点的迭代,理解每个版本变更背后的缘由和目的,最终推进到最新内核版本。
本文就是从2.4时代的任务调度器开始,详细描述其实现并慢慢向前递进。当然,为了更好的理解Linux调度器设计和实现,我们在第二章给出了一些通用的概念。之后,我们会在第四章讲述O(1)调度器如何改进并提升调度器性能。真正有划时代意义的是CFS调度器,在2.6.23版本的内核中并入主线。它的设计思想是那么的眩目,即便是目前最新的内核中,完全公平的设计思想仍然没有太大变化,这些我们会在第六章描述。第五章是关于公平调度思想的引入,通过这一章可以了解Con Kolivas的RSDL调度器,它是开启公平调度的先锋,通过这一章的铺垫,我们可以更顺畅的理解CFS。最后一章是对全文的总结。
二、任务调度器概述
为了不引起混乱,我们一开始先澄清几个概念。进程调度器是传统的说法,但是实际上进程是资源管理的单位,线程才是调度的单位,但是线程调度器的说法让我觉得很不舒服,因此最终采用进程调度器或者任务调度器的说法。为了节省字,本文有些地方也直接简称调度器,此外,除非特别说明,本文中的“进程”指的是task struct代表的那个实体,毕竟这是一篇讲调度器的文档。
任务调度器是操作系统一个很重要的部件,它的主要功能就是把系统中的task调度到各个CPU上去执行满足如下的性能需求:
1、对于time-sharing的进程,调度器必须是公平的
2、快速的进程响应时间
3、系统的throughput要高
4、功耗要小
当然,不同的任务有不同的需求,因此我们需要对任务进行分类:一种是普通进程,另外一种是实时进程。对于实时进程,毫无疑问快速响应的需求是最重要的,而对于普通进程,我们需要兼顾前三点的需求。相信你也发现了,这些需求是互相冲突的,对于这些time-sharing的普通进程如何平衡设计呢?这里需要进一步将普通进程细分为交互式进程(interactive processs)和批处理进程(batch process)。交互式进程需要和用户进行交流,因此对调度延迟比较敏感,而批处理进程属于那种在后台默默干活的,因此它更注重throughput的需求。当然,无论如何,分享时间片的普通进程还是需要兼顾公平,不能有人大鱼大肉,有人连汤都喝不上。功耗的需求其实一直以来都没有特别被调度器重视,当然在linux大量在手持设备上应用之后,调度器不得不面对这个问题了,当然限于篇幅,本文就不展开了。
为了达到这些设计目标,调度器必须要考虑某些调度因素,比如说“优先级”、“时间片”等。很多RTOS的调度器都是priority-based的,官大一级压死人,调度器总是选择优先级最高的那个进程执行。而在Linux内核中,优先级就是实时进程调度的主要考虑因素。而对于普通进程,如何细分时间片则是调度器的核心思考点。过大的时间片会严重损伤系统的响应延迟,让用户明显能够感知到延迟,卡顿,从而影响用户体验。较小的时间片虽然有助于减少调度延迟,但是频繁的切换对系统的throughput会造成严重的影响。因为这时候大部分的CPU时间用于进程切换,而忘记了它本来的功能其实就是推动任务的执行。
由于Linux是一个通用操作系统,它的目标是星辰大海,既能运行在嵌入式平台上,又能在服务器领域中获得很好的性能表现,此外在桌面应用场景中,也不能让用户有较差的用户体验。因此,Linux任务调度器的设计是一个极具挑战性的工作,需要在各种有冲突的需求中维持平衡。还好,经过几十年内核黑客孜孜不倦的努力,Linux内核正在向着最终目标迈进。
三、2.4时代的O(n)调度器
网上有很多的linux内核考古队,挖掘非常古老内核的设计和实现。虽然我对进程调度器历史感兴趣,但是我只对“近代史”感兴趣,因此,让我们从2.4时代开始吧,具体的内核版本我选择的是2.4.18版本,该版本的调度器相关软件结构可以参考下面的图片:
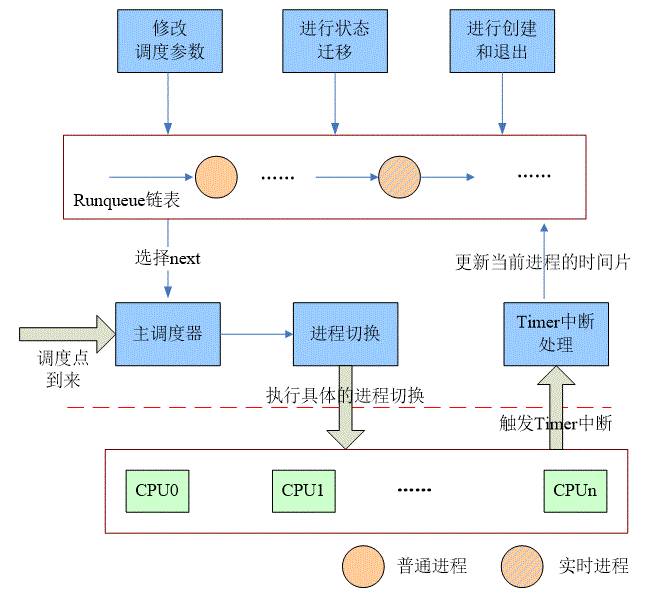
本章所有的描述都是基于上面的软件结构图。
1、进程描述符
struct task_struct {
volatile long need_resched;
long counter;
long nice;
unsigned long policy;
int processor;
unsigned long cpus_runnable, cpus_allowed;
struct list_head run_list;
unsigned long rt_priority;
......
};
对于2.4内核,进程切换有两种,一种是当进程由于需要等待某种资源而无法继续执行下去,这时候只能是主动将自己挂起(调用schedule函数),引发一次任务调度过程。另外一种是进程欢快执行,但是由于各种调度事件的发生(例如时间片用完)而被迫让出CPU,被其他进程抢占。这时候的调度并不是立刻发送,而是延迟执行,具体的方法是设定当前进程的need_resched等于1,然后静静的等待最近一个调度点的来临,当调度点到来的时候,内核会调用schedule函数,抢占当前task的执行。
nice成员就是普通进程的静态优先级,通过NICE_TO_TICKS宏可以将一个进程的静态优先级映射成缺省时间片,保存在counter成员中。因此在一次调度周期开始的时候,counter其实就是该进程分配的CPU时间额度(对于睡眠的进程还有些奖励,后面会描述),以tick为单位,并且在每个tick到来的时候减一,直到耗尽其时间片,然后等待下一个调度周期从头再来。
Policy是调度策略,2.4内核主要支持三种调度策略,SCHED_OTHER是普通进程,SCHED_RR和SCHED_FIFO是实时进程。SCHED_RR和SCHED_FIFO的调度策略在rt_priority不同的时候,都是谁的优先级高谁先执行,唯一的不同是相同优先级的处理:SCHED_RR采用时间片轮转,而SCHED_FIFO采用的策略是先到先得,先占有CPU的进程会持续执行,直到退出或者阻塞的时候才会让出CPU。也只有这时候,其他同优先级的实时进程才有机会执行。如果进程是实时进程,那么rt_priority表示该进程的静态优先级。这个成员对普通进程是无效的,可以设定为0。除了上面描述的三种调度策略,policy成员也可以设定SCHED_YIELD的标记,当然它和调度策略无关,主要处理sched_yield系统调用的。
Processor、cpus_runnable和cpus_allowed这三个成员都是和CPU相关。Processor说明了该进程正在执行(或者上次执行)的逻辑CPU号;cpus_allowed是该task允许在那些CPU上执行的掩码;cpus_runnable是为了计算一个指定的进程是否适合调度到指定的CPU上去执行而引入的,如果该进程没有被任何CPU执行,那么所有的bit被设定为1,如果进程正在被某个CPU执行,那么正在执行的CPUbit设定为1,其他设定为0。具体如何使用cpus_runnable可以参考can_schedule函数。
run_list成员是链接入各种链表的节点,下一小节会描述内核如何组织task,这里不再赘述。
2、如何组织task
Linux2.4版本的进程调度器使用了非常简陋的方法来管理可运行状态的进程。调度器模块定义了一个runqueue_head的链表头变量,无论进程是普通进程还是实时进程,只要进程状态变成可运行状态的时候,它会被挂入这个全局runqueue链表中。随着系统的运行,runqueue链表中的进程会不断的插入或者移除。例如当fork进程的时候,新鲜出炉的子进程会挂入这个runqueue。当阻塞或者退出的时候,进程会从这个runqueue中删除。但是无论如何变迁,调度器始终只是关注这个全局runqueue链表中的task,并把最适合的那个任务丢到CPU上去执行。由于整个系统中的所有CPU共享一个runqueue,为了解决同步问题,调度器模块定义了一个自旋锁来保护对这个全局runqueue的并发访问。
除了这个runqueue队列,系统还有一个囊括所有task(不管其进程状态为何)的链表,链表头定义为init_task,在一个调度周期结束后,重新为task赋初始时间片值的时候会用到该链表。此外,进入sleep状态的进程分别挂入了不同的等待队列中。当然,由于这些进程链表和调度关系不是那么密切,因此上图中并没有标识出来。
3、动态优先级和静态优先级
所谓静态优先级就是task固有的优先级,不会随着进程的行为而改变。对于实时进程,静态优先级就是rt_priority,而对于普通进程,静态优先级就是(20 – nice)。然而实际上调度器在进行调度的时候,并没有采用静态优先级,而是比对动态优先级来决定谁更有资格获得CPU资源,当然动态优先级的计算是基于静态优先级的。
在计算动态优先级(goodness函数)的时候,我们可以分成两种情况:实时进程和普通进程。对于实时进程而言,动态优先级等于静态优先级加上一个固定的偏移:
weight = 1000 + p->rt_priority;
之所以这么做是为了将实时进程和普通进程区别开,这样的操作也保证了实时进程会完全优先于普通进程的调度。而对于普通进程,动态优先级的计算稍微有些复杂,我们可以摘录部分代码如下:
weight = p->counter;
if (!weight)
goto out;
weight += 20 - p->nice;
对于普通进程,计算动态优先级的策略如下:
(1)如果该进程的时间片已经耗尽,那么动态优先级是0,这也意味着在本次调度周期中该进程已经再也没有机会获取CPU资源了。
(2)如果该进程的时间片还有剩余,那么其动态优先级等于该进程剩余的时间片和静态优先级之和。之所以用(20-nice value)表示静态优先级,主要是为了让静态优先级变成单调上升。之所以要考虑剩余时间片是为了奖励睡眠的进程,因为睡眠的进程剩余的时间片较多,因此动态优先级也就会高一些,更容易被调度器调度执行。
调度器是根据动态优先级来进行调度,谁大就先执行谁。我们可以用普通进程作为例子:如果进程静态优先级高(即nice value小),剩余时间片多,那么必定是优先执行。如果静态优先级高,但是所剩时间片无几,那么可能会让位给其他剩余时间片较多,优先级适中的任务。静态优先级低的任务毫无疑问是受到双重打击,因为本来它的缺省时间片就不多,而且优先级也很低。不过,无论静态优先级如何高,只要时间片用完,那么低优先级的任务总是能够有机会执行,不至于饿死。
在计算普通进程的动态优先级的时候,除了考虑进程剩余时间片信息和静态优先级,调度器也会酌情考虑cache和TLB的性能问题。例如,例如A和B进程优先级相同,剩余的时间片都是3个tick,但是A进程上一次就是运行在本CPU上,如果选择A,可能会有更好的cache和TLB的命中率,从而提高性能。在这种情况下,调度器会提升A进程的动态优先级。此外,如果备选进程和当前进程共享同一个地址空间,那么在计算调度指数的时候也会做小小的倾斜。这里有两种可能的情况:一种是备选进程和当前进程和当前进程在一个线程组中(即是进程中的两个线程),另外一种情况是备选进程是内核线程,这时候,它往往会借用上一个进程地址空间。不论是哪一种情况,在进程切换的时候,由于不需要进行进程地址空间的切换,因此也会有性能的优势。
4、调度时机
对于2.4内核,产生调度的时机主要包括:
(1)进程主动发起调度。
(2)在timer中断处理中发现当前进程耗尽其时间片
(3)进程唤醒的时候(例如唤醒一个RT进程)。更详细的信息可以参考下一个小节。
(4)父进程在fork的时候,其时间片会均分到父子进程,但是如果只剩下一个tick,这个tick会分配给子进程,而父进程的时间片则被清零,这时候,进程遭遇的场景等同与在timer中断处理中发现当前进程耗尽其时间片。如果父进程在fork的时候,其时间片较大,父子进程的时间片都不为0,这时候的场景类似于唤醒进程。因为这两个场景都是向runqueue中添加了一个task node,从而引发的调度。
(5)进程切换的时候。当在系统中的某个CPU上发生了进程切换,例如A任务切换到了B任务,这时候是否A任务就失去了执行的机会了呢?当然也未必,因为虽然竞争本CPU失败,但是也许其他的CPU上运行的task动态优先级还不如A呢,异或正好其他CPU有进入idle状态,正等待着新进程入驻。
(6)用户进程主动让出CPU的时候
(7)用户进程修改调度参数的时候
上面的种种场景,除了进程主动调度之外,其他的场景都不是立刻调度schedule函数,而是设定need_resched标记,然后等待调度点的到来。由于2.4内核不是preemptivekernel,因此调度点总是在返回用户空间的时候才会到来。当调度点到来的时候,进程调度就会在该CPU上启动。抢占的场景太多,我们选择进程唤醒的场景来详细描述,其他场景大家自行分析吧。
5、进程唤醒的处理
当进程被唤醒的时候(try_to_wake_up),该task会被加入到那个全局runqueue中,但是是否启动调度还需要进行一系列的判断。为了能清楚的描述这个场景,我们定义执行唤醒的那个进程是waker,而被唤醒的进程是wakee。Wakeup有两种,一种是sync wakeup,另外一种是non-sync wakeup。所谓sync wakeup就是waker在唤醒wakee的时候就已经知道自己很快就进入sleep状态,而在调用try_to_wake_up的时候最好不要进行抢占,因为waker很快就主动发起调度了。此外,一般而言,waker和wakee会有一定的亲和性(例如它们通过share memory进行通信),在SMP场景下,waker和wakee调度在一个CPU上执行的时候往往可以获取较佳的性能。而如果在try_to_wake_up的时候就进行调度,这时候wakee往往会调度到系统中其他空闲的CPU上去。这时候,通过sync wakeup,我们往往可以避免不必要的CPU bouncing。对于non-sync wakeup而言,waker和wakee没有上面描述的同步关系,waker在唤醒wakee之后,它们之间是独立运作,因此在唤醒的时候就可以尝试去触发一次调度。
当然,也不是说sync wakeup就一定不调度,假设waker在CPU A上唤醒wakee,而根据wakee进程的cpus_allowed成员发现它根本不能在CPU A上调度执行,那么管他sync不sync,这时候都需要去尝试调度(调用reschedule_idle函数),反正waker和wakee命中注定是天各一方(在不同的CPU上执行)。
我们首先看看UP上的情况。这时候waker和wakee在同一个CPU上运行(当然系统中也只有一个CPU,哈哈),这时候谁能抢占CPU资源完全取决于waker和wakee的动态优先级,如果wakee的动态优先级大于waker,那么就标记waker的need_resched标志,并在调度点到来的时候调用schedule函数进行调度。
SMP情况下,由于系统的CPU资源比较多,waker和wakee没有必要争个你死我活,wakee其实也可以选择去其他CPU执行,相关的算法大致如下
(1)优先调度wakee去系统其他空闲的CPU上执行,如果wakee上次运行的CPU恰好处于idle状态的时候,可以考虑优先将wakee调度到那个CPU上执行。如果不是,那么需要扫描系统中所有的CPU找到最合适的idle CPU。所谓最合适就是指最近才进入idle的那个CPU。
(2)如果所有的CPU都是busy的,那么需要遍历所有CPU上当前运行的task,比对它们的动态优先级,找到动态优先级最低的那个CPU。
(3)如果动态优先级最低的那个task的优先级仍然高于wakee,那么没有必要调度,runqueue中的wakee需要耐心等待下一次机会。如果wakee的动态优先级高于找到的那个动态优先级最低的task,那么标记其need_resched标志。如果不是抢占waker,那么我们还需要发送IPI去触发该CPU的调度。
当然,这是2.4内核调度器的设计选择,实际上这样的操作值得商榷。限于篇幅,本文就不再展开叙述,如果有机会写负载均衡的文章就可以好好的把这些关系梳理一下。
6、主调度器算法
主调度器(schedule函数)核心代码如下:
list_for_each(tmp, &runqueue_head) {
p = list_entry(tmp, struct task_struct, run_list);
int weight = goodness(p, this_cpu, prev->active_mm);
if (weight > c)
c = weight, next = p;
}
list_for_each用来遍历runqueue_head链表上的所有的进程,临时变量p就是本次需要检查的进程描述符。如何判断哪一个进程是最适合调度执行的进程呢?我们需要计算进程的动态优先级(对应上面程序中的变量weight),它是通过goodness函数实现的。动态优先级最大的那个进程就是当前最适合调度到CPU执行的进程。一旦选中,调度器会启动进程切换,运行该进程以替换之前的那个进程。
根据代码可知:即便链表第一个节点就是最合的下一个要调度执行的进程,调度器算法仍然会遍历全局runqueue链表,一一比对。由此我们可以判断2.4内核中的调度器的算法复杂度是O(n)。一旦选中了下一个要执行的进程,进程切换模块就会在该CPU上执行具体的进程切换。
对于SCHED_RR的实时进程,优先级相等的情况下还需要有一个时间片轮转的概念。因此,在遍历链表之前我们就先处理该进程的时间片处理:
if (unlikely(prev->policy == SCHED_RR))
if (!prev->counter) {
prev->counter = NICE_TO_TICKS(prev->nice);
move_last_runqueue(prev);
}
如果时间片(对应上面程序中的prev->counter)用完,SCHED_RR的实时进程会被移到runqueue链表的尾部。通过这样的处理,优先级相等的SCHED_RR在遍历runqueue链表的时候会命中链表中的第一个task,从而实现时间片轮转的概念。这里有一个比较奇葩的事情就是SCHED_RR的时间片是根据其nice value设定,而实际上nice value应该只适用于普通进程的。
7、时间片处理
普通进程的时间片处理思路是这样:
(1)每个进程根据其静态优先级可以固定分配一个缺省的时间片,静态优先级越大,分配的时间片就越大。
(2)一旦Runqueue中的进程被调度执行,那么其时间片就会在tick到来的时候递减,如果进程时间片耗尽,那么该进程将失去分配CPU资源的资格。
(3)Runqueue中的进程的时间片全部被用完之后,我们称一个调度周期结束,这时候需要为runqueue中的进程重新设定其缺省时间片,这样,一个新的调度周期又开始了。
如何确定每个进程的缺省时间片呢?由于时间片是按照tick来分配的,那么最小的时间片也是1个tick,也就是说最低优先级(nice value等于19)的缺省时间片就是1个tick。对于中间优先级(nice value等于0)的时间片,我们将其设定为50ms左右,具体的算法大家可以自行参考NICE_TO_TICKS的代码实现。不得不承认这个根据nice value计算缺省时间片的过程还是很丑陋的,不同的HZ设定,计算得到的缺省时间片是不一样的。也就是说系统的调度行为和HZ的设定有关,这叫有代码洁癖的同学如何能够接受。不论如何,我们还是给出实际的例子来感受一下:
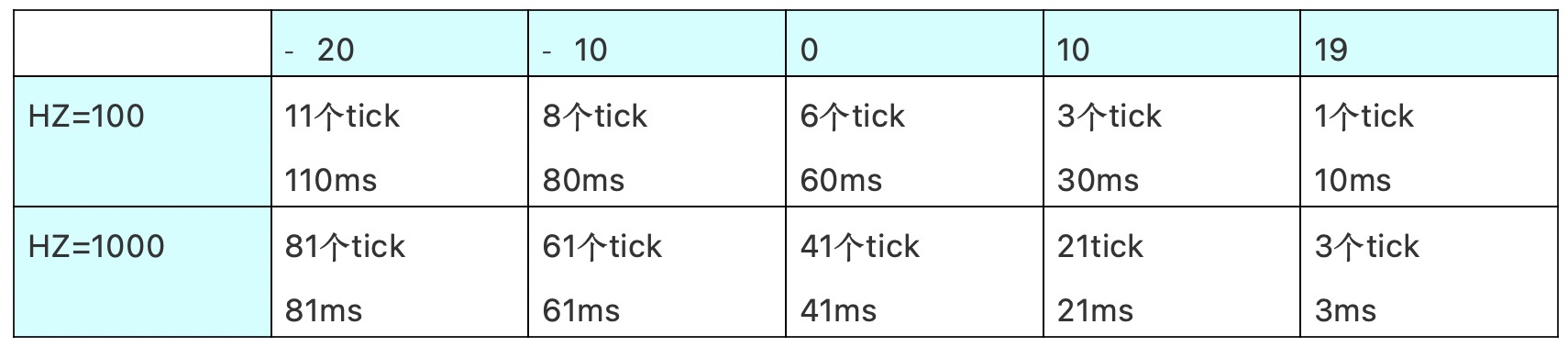
当runqueue中所有进程的时间片耗尽之后,这时候就会开启一次重新加载进程缺省时间片的过程,代码如下(在schedule函数中):
if (unlikely(!c)) {
struct task_struct *p;
for_each_task(p)
p->counter = (p->counter >> 1) + NICE_TO_TICKS(p->nice);
goto repeat_schedule;
}
这里c就是遍历runqueue链表之后找到的最大动态优先级,如果它等于0则说明:首先,系统中没有处于可运行状态的实时进程,其次,所有的处于可运行状态的普通进程都已经消耗完了它们的时间片,这时候是需要重新“充值”了。for_each_task这个宏是遍历所有系统中的进程描述符,不论是否是可运行状态的。对于挂入runqueue链表中的普通进程而言,其当前的时间片p->counter已经是等于0了,因此它获得的新的时间片就是NICE_TO_TICKS(p->nice),也就是根据nice value计算得到的缺省时间片。对于挂入等待队列中处于睡眠状态的进程而言,其时间片p->counter还有剩余,当然会累积到进程时间片配额中,这也算是对睡眠进程的一种奖励吧。为了防止经常睡眠的交互式进程获得过于庞大的时间片,这里并不是累积其全部存留时间片,而是打了个对折(p->counter >> 1)。
新的一个周期开始了,当前进程已经在CPU上奔跑了,消耗其时间片的代码位于timer中断处理中,如下:
if (--p->counter <= 0) {
p->counter = 0;
p->need_resched = 1;
}
每一个tick到来的时候,进程的时间片都会减一,当时间片是0的时候,调度器剥夺其执行的权力,从而从而引发一次调度,选择其他时间片不是0的进程运行,直到runqueue中的所有进程时间片耗尽,又会重新赋值,开始一个新的周期。调度器就这样周而复始,推动整个系统的运作。
四、2.6时代的O(1)调度器
1、Why O(1)调度器
如果简单是判断调度器好坏的唯一标准,那么无疑O(n)调度器是最优秀的调度器。虽然它非常的简单,容易理解,但是存在严重的扩展性问题和性能问题。下面让我们一起来控诉O(n)调度器的“七宗罪”,同时这也是Ingo Molnar发起O(1)调度器项目背后的原因。
(1)算法复杂度问题
让人最不爽的就是对runqueue队列的遍历,当系统中runnable进程不多的时候,遍历链表的开销还可以接受,但是随着系统中runnable状态的进程数目增多,那么调度器select next的运算量也随之呈线性的增长,这也是我们为什么叫它O(n)调度器的原因。
此外,调度周期结束后,调度器会为所有进程的时间片进行“充值“的动作。在大型系统中,同时存在的进程(包括睡眠的进程)可能会有数千个,为每一个进程计算其时间片的过程太耗费时间。
(2)SMP扩展性问题
2.4内核的O(n)调度器有非常差的SMP扩展性。我们知道,O(n)调度器是通过一个链表来管理系统中的所有的等待调度的进程,访问这个runqueue链表的场景很多:进行调度的时候,我们需要遍历runqueue,找到合适的next task;wakeup或者block进程的时候,我们需要从runqueue中增加节点或者删除节点……在访问runqueue这个链表的时候,我们都会首先会上自旋锁,同时disable本地CPU中断,然后访问链表执行相应的动作,完成之后释放锁,开中断。通过这样的内核同步机制,我们可以保证来自多个CPU对runqueue链表的并发访问。当系统中的CPU数目比较少的时候,自旋锁的开销还可以接受,但是在大型系统中,CPU数目非常多,这时候runqueue spin lock就成为系统的性能瓶颈。
(3)CPU空转问题
每当runqueue链表中的所有进程耗尽了其时间片,这时候就需要启动对系统中所有进程时间片重新计算的过程。这个计算过程异常丑陋,需要遍历系统中的所有进程(注意:是所有进程!),为进程描述符的counter成员赋一个新值。而这个操作足以把该CPU上的L1 cache全部干掉。当完成了时间片重新计算过程后,你几乎面对的就是一个全空的L1cache(当然不是全空,主要是cache中的数据没有任何意义,这时候L1 cache的命中率急剧下降)。除此之外,时间片重新计算过程会带来CPU资源的浪费,我们用下面的图片来描述:
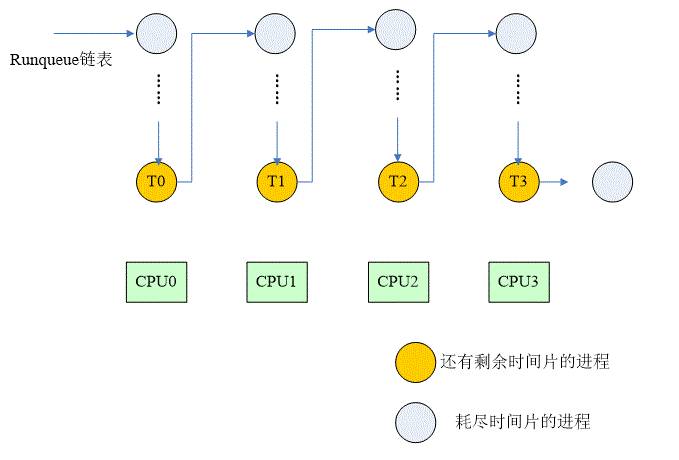
在runqueue队列中的全部进程时间片被耗尽之前,系统总会处于这样一个状态:最后的一组尚存时间片的进程分分别调度到各个CPU上去。我们以4个CPU为例,T0~T3分别运行在CPU0~CPU3上。随着系统的运行,CPU2上的T2首先耗尽了其时间片,但是这时候,其实CPU2上也是无法进行调度的,因为遍历runqueue链表,找不到适合的进程调度运行,因此它只能是处于idle状态。也许随后T0和T3也耗尽其时间片,从而导致CPU0和CPU3也进入了idle状态。现在只剩下最后一个进程T1仍然在CPU1上运行,而其他系统中的处理器处于idle状态,白白的浪费资源。唯一能改变这个状态的是T1耗尽其时间片,从而启动一个重新计算时间片的过程,这时候,正常的调度就可以恢复了。随着系统中CPU数目的加大,资源浪费会越来越严重。
(4)task bouncing issue
一般而言,一个进程最好是从一而终,假如它运行在系统中的某个CPU中,那么在其处于可运行状态的过程中,最好是一直保持在该CPU上运行。不过在O(n)调度器下,很多人都反映有进程在CPU之间跳来跳去的现象。其根本的原因也是和时间片算法相关。在一个新的周期开后,runqueue中的进程时间片都是满满的,在各个CPU上调度进程的时候,它可选择的比较多,再加上调度器倾向于调度上次运行在本CPU的进程,因此调度器有很大的机会把上次运行的进程调度到同一个处理器上。但是随着runqueue中的进程一个个的耗尽其时间片,cpu可选择的余地在不断的压缩,从而导致进程执行在一个和它亲和性不大的处理器(例如上次该进程运行在CPU0,但是这个将其调度到CPU1执行,但是实际上该进程和CPU0的亲和性更大些)。
(5)RT进程调度性能问题
实时调度的性能一般。通过上一节的介绍,我们知道,实时进程和普通进程挂在一个链表中。当调度实时进程的时候,我们需要遍历整个runqueue列表,扫描并计算所有进程的调度指数,从而选择出心仪的那个实时进程。按理说实时进程和普通进程位于不同的调度空间,两不相干,但是现在调度实时进程还需要扫描计算普通进程,这样糟糕的算法让那些关注实时性的工程师不能忍受。
当然,上面的这些还不是关键,最重要的是争个linux内核不是抢占式内核,在整个内核态都不能被抢占。对于一些比较耗时(可能几个毫秒)的系统调用或者中断处理,必须返回用户空间才启动调度是不可接受的。除了内核抢占性之外,优先级翻转问题也需要引起调度器的重视,否则即便一个rt进程变成runnable状态了,但是也只能眼睁睁的看着比它优先级低的进程运行,直到该rt进程等待的资源被释放。
(6)交互式普通进程的调度延迟问题
O(n)并不区分交互式进程和批处理进程,它只是奖励经常睡眠的那些进程。但是有些批处理进程也属于IO-bound进程,例如数据库服务进程,它本身是一个后台进程,对调度延迟不敏感,但是由于它需要和磁盘打交道,因此也会经常阻塞在disk IO上。对这样的后台进程进行动态优先级的升高其实是没有意义的,会增大其他交互式进程的调度延迟。另外一方面,用户交互式进程也可能是CPU-bound的,而这时候调度器不会正确的了解到该进程的调度需求并对其进行补偿。
(7)时间片粒度问题。
用户感知到的响应延迟是和系统负载相关,我们可以用runnable进程数目来粗略的描述系统的负载。当系统负载高的时候,runqueue中的进程数目会比较多,一次调度周期的时间就会比较长,例如在HZ=100的情况下,runqueue上有5个runnable进程,nice value是0,每个时间片配额是60ms,那么一个调度周期就是300ms。随着runnable进程增大,调度周期也变大。当一个进程耗尽其时间片之后,只能等待下一个调度周期到来。因此随着调度周期变大,系统响应也会变的较差。
虽然O(n)调度器存在不少的issue,但是社区的人还是基本认可这套算法的,因此在设计新的调度器的时候并不是完全推翻O(n)调度器的设计,而是针对O(n)调度器的问题进行改进。在本章中我们选择2.6.11版本的内核来描述O(1)调度器如何运作。鉴于O(1)调度器和O(n)调度器没有本质区别,因此我们只是描述它们之间不同的地方。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK