

Advances on Group Isomorphism
source link: https://rjlipton.wpcomstaging.com/2013/05/11/advances-on-group-isomorphism/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Advances on Group Isomorphism
Finally progress on this annoying problem
David Rosenbaum is right now the world expert on one of my favorite problems, group isomorphism. He is a third-year PhD student at the University of Washington in Seattle under Paul Beame, and has been visiting MIT this year to work with his other advisor, our familiar friend Aram Harrow. He presented a paper on this at SODA 2013, and recently posted a successor paper to the ArXiv. He grew up in the Portland area where he won prizes in scholastic chess tournaments.
Today I want to talk about his work, which not only advances our understanding of this problem, but also makes progress on other ones.
Group isomorphism is a great problem for many reasons. It is a special case of the graph isomorphism problem, which is another annoying problem. Very annoying. Of course a good idea when confronted with a immovable problem is to work on a special case. Add extra conditions. Perhaps the special case adds enough extra structure, giving you additional leverage, so the problem can be “moved.”
Group isomorphism is not a great problem because people are lining up to solve it. Nor are people lining up to solve graph isomorphism problem either, but that is another story. The new algorithms that David has found are all galactic as we coined the term here. Indeed they are way out there in space usage too. But galactic or not they are based on beautiful ideas that will have impact in other areas, in my opinion. This is why they are so important. Every advance in our understanding of how to create clever algorithms—for any problem—advances our general understanding of computation. And that is good.
Notes From Underground
You can skip this, since it is about how we work here at GLL. Our “staff” has various rules and procedures for the creation of a new piece. We have a complex process… Of course not. But I did consider writing about David’s work quite a while ago.
Something made me delay and delay and delay. Other pieces were written, others were put out, and a discussion of group isomorphism stayed on the stack. Other things have slowed us including “floodgates” on Ken’s side. Somehow I knew that David was onto something great. Initially he made progress on special groups, then on a larger class of groups, and finally on all finite groups. Even better he discovered a new algorithmic principle that may be of importance to other areas of computing. It is exciting and may be useful in both theory and in practice.
An aside: perhaps I should still wait some more. Could his next result be even stronger? Oh well, we will push forward and if he makes more progress we will discuss that another day. Just to prove my point here is a quote from my earlier draft that we never “approved” for release:
I wonder if he can extend to prove
for
for all groups. The reason is that 2-groups always seemed to be the roadblock to me for this improvement.
Now we can note that he can indeed. Let’s talk about group isomorphism and more.
Group Isomorphism
The group isomorphism problem is about multiplication tables. A finite group is described by giving the complete product table. If the group consists of the elements
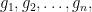
then the table is 
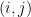



Long ago Bob Tarjan and Zeke Zalcstein and I made a simple observation: Group isomorphism could be done in time

This relies on the easy-to-prove fact that every group has at most 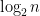
What is nice about this observation is it is a much better time bound than any known for graph isomorphism. But it also depends on group theory in a very weak way. It only uses Joseph Lagrange’s theorem: the order of a subgroup always divides the order of the group.
New Results
David made progress on group isomorphism by combining powerful insights from group theory with several from computing. Let’s first state some of his newest results, and then discuss at high level how he proves them.
Theorem 1 Group isomorphism can be solved in time
for solvable groups.

Solvable groups are special, but I always thought that they would be a hard class to handle. For starters their structure is immensely complex. Yet solvable groups do have many neat closure properties that have proved to be useful.
Note that the “extreme” opposite of solvable groups are simple groups. Thanks to the classification of simple groups, the isomorphism problem for them is trivially in polynomial time. The algorithm is based on the cool fact that every simple group has a generator set of at most size two. It is interesting to have a trivial algorithm whose correctness proof is immense, since the correctness depends on the classification theorem. Perhaps this is the worst ratio of algorithm size to correctness proof? Anyway it is a building block for the final result.
Theorem 2 Group isomorphism can be solved in time
for general groups.

Of course the “general groups” here are finite—group isomorphism as discussed here is always about finite groups. The improvement is the constant 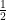

A New Game
As usual the best way to understand what David did is to look at his paper. However there is a new principle that he isolated that I would like to discuss here. This is the principle that I believe can be used elsewhere, and is a fundamental advance.
Consider the following game between Alice and Bob—who else? They each have access to a finite tree 






The issue in the game is whether Alice and Bob can follow a pre-determined strategy that identifies structural features in the tree. For instance, suppose they agree that after strating from the root they never choose a node with an odd number of children. Then the sets
David, not acting as a player in this game, has discovered a wide range of trees where there is an economical winning strategy for Alice and Bob. This strategy involves counting, and yields a much smaller value of 
One cautionary aspect of this game, however, is that even though it is defined on a tree, it lacks the space-saving properties of depth-first search. The entire sets involved seem to need to be maintained in memory at once. David in fact shows that his game strategy forms a spectrum with a common time-space tradeoff, with his best time at one end and the simple generator-enumeration algorithm at the other end.
Open Problems
The main open problem is to show—really show—that group isomorphism is in polynomial time. Or failing that, show that it can be done in time 
Another interesting open question is what can we say about his new principle? Can we use his search ideas on other problems? This seems like an accessible research line.
Like this:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK