A Note on Distributions and Approximation
March 11, 2012
A helpful analogy for the quantum computing debate?
Roman Smolensky was a complexity theorist—unfortunately “was” is the correct word here. He passed away in 1995, way too young, at the age of 35. His STOC 1987 paper “Algebraic methods in the theory of lower bounds for Boolean circuit complexity” is a classic, and one can only imagine what he might have done had he lived longer.
Today I, Ken, wish to explain a well known result of Smolensky’s about low-level complexity theory. Then I draw an analogy we hope may help in understanding mathematical issues underlying our current debate over scalable quantum computers.
Dick raises a principle of mathematics that is not well known, or not as well known as it should be: when it is hard to work with sets, replace them by distributions. Even though distributions are a more general notion, they have some nicer properties. Properties of distributions over qubits and their errors are at the heart of the debate, so we feel noting some properties of distributions on ordinary bits or vectors over a finite field, and raising some questions, may be a helpful stepping stone.
Smolensky considered bounded (or sub-logarithmic) depth circuits of unbounded fan-in 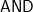 and
and  gates (with
gates (with 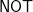 gates at inputs), or equivalently circuits of
gates at inputs), or equivalently circuits of  or
or  gates, together with unbounded fan-in gates telling whether the number of incoming 1’s is a multiple of a prime
gates, together with unbounded fan-in gates telling whether the number of incoming 1’s is a multiple of a prime  . He proved that they cannot compute the mod-
. He proved that they cannot compute the mod- function unless is a power of , and indeed cannot even approximate it in a sense whose dependence on distributions we wish to bring out. Let us first turn to Smolensky’s work, in the particular case of parity, i.e.,
function unless is a power of , and indeed cannot even approximate it in a sense whose dependence on distributions we wish to bring out. Let us first turn to Smolensky’s work, in the particular case of parity, i.e.,  and is an odd prime.
and is an odd prime.
Approximating NANDs
As Smolensky’s paper acknowledges, the following lemma on approximating by low-degree polynomials was also proved by Alexander Razborov for 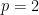 , and by David Mix Barrington for all :
, and by David Mix Barrington for all :
Lemma 1 For any distribution  on
on  , and
, and  , there exists a polynomial
, there exists a polynomial  of degree at most
of degree at most  over
over  such that
such that
![\displaystyle \Pr_{y \leftarrow D}[h(y) \neq \mathsf{NAND}(y)] \leq \frac{1}{p^k}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CPr_%7By+%5Cleftarrow+D%7D%5Bh%28y%29+%5Cneq+%5Cmathsf%7BNAND%7D%28y%29%5D+%5Cleq+%5Cfrac%7B1%7D%7Bp%5Ek%7D.+&bg=e8e8e8&fg=000000&s=0&c=20201002)
Proof: Consider polynomials of the form  where
where

with coefficients  .
.
If  makes
makes  false, then since
false, then since  stands for true,
stands for true,  , and so
, and so  which stands for false.
which stands for false.
Otherwise, some 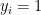 , and thus
, and thus  has an additive term that is simply
has an additive term that is simply  by itself. Whatever the value of the rest of , there is exactly a
by itself. Whatever the value of the rest of , there is exactly a  probability that a uniformly random choice of coefficients including will produce an such that
probability that a uniformly random choice of coefficients including will produce an such that  . Raising that to the power
. Raising that to the power 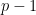 produces
produces  , and so
, and so  which stands for true.
which stands for true.
Furthermore, using  -many sets of
-many sets of  -many coefficients
-many coefficients  to define
to define 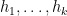 in the manner of , we define
in the manner of , we define

Then when  , all
, all  so
so  which stands for false, while for all other
which stands for false, while for all other  , the chance of making some
, the chance of making some  nonzero, so that the whole product is zeroed out and
nonzero, so that the whole product is zeroed out and  , is
, is  .
.
Thus for all  , the probability over the that the resulting
, the probability over the that the resulting  agrees with on that is
agrees with on that is  . Picture the ‘s as rows of a big table and the choices for all as columns. Each row has density of agreements. It follows that regardless of the distribution
. Picture the ‘s as rows of a big table and the choices for all as columns. Each row has density of agreements. It follows that regardless of the distribution  on the rows, some column has density at least of agreements when is chosen according to .
on the rows, some column has density at least of agreements when is chosen according to . 
The reason for caring about arbitrary distributions on is that the 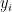 will be outputs from gates higher in the circuit, and those values might be correlated. Lecture notes by Alexis Maciel and David Mix Barrington (which I am using in a course) in fact represent the as functions
will be outputs from gates higher in the circuit, and those values might be correlated. Lecture notes by Alexis Maciel and David Mix Barrington (which I am using in a course) in fact represent the as functions  of a single variable
of a single variable  . Here is ultimately interpreted as the inputs
. Here is ultimately interpreted as the inputs  to the circuit
to the circuit  , but it could be arbitrary.
, but it could be arbitrary.
Lower Bound for Parity
The point of the lemma is that if the circuit has small depth  , then composing the polynomials
, then composing the polynomials 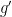 obtained for each gate
obtained for each gate  yields a polynomial
yields a polynomial 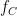 of degree at most
of degree at most  that agrees with on all but an
that agrees with on all but an  proportion of inputs , where
proportion of inputs , where  is the number of gates in . When
is the number of gates in . When  , there is some slack to choose non-constant but growing slowly enough with
, there is some slack to choose non-constant but growing slowly enough with  (for some fixed
(for some fixed  used as below) to make:
used as below) to make:

where is the size of the circuit. This allows to be as big as  , and this becomes the circuit size lower bound obtained by Smolensky’s argument.
, and this becomes the circuit size lower bound obtained by Smolensky’s argument.
Note that regardless of the distribution on the inputs, there always exists a setting of the  -many coefficients
-many coefficients  over all the gates that achieves the bound on the error probability over that distribution of inputs. In particular, this works for the uniform distribution over the inputs
over all the gates that achieves the bound on the error probability over that distribution of inputs. In particular, this works for the uniform distribution over the inputs  , but does not require it. Thus can be approximated by some polynomials
, but does not require it. Thus can be approximated by some polynomials  of low degree
of low degree  .
.
This sets the stage for Smolensky’s famous “trick” which we give in the case of parity. Over the domain  , parity is just the product
, parity is just the product  of all the variables, and
of all the variables, and  . Thus parity is a polynomial
. Thus parity is a polynomial  that is “complete” in the following sense defined in his paper:
that is “complete” in the following sense defined in his paper:
For every function  there are polynomials
there are polynomials  both of degree at most
both of degree at most  such that
such that

The genius of this is that if agrees with on some subset 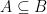 and has low degree
and has low degree  , then we can bound the size of
, then we can bound the size of  . Namely, every function
. Namely, every function  when restricted further to can be written as a polynomial of degree at most
when restricted further to can be written as a polynomial of degree at most  . There are
. There are  such functions, but only
such functions, but only  ways to assign the coefficients of terms of degree
ways to assign the coefficients of terms of degree  for all
for all  . Taking logs base we get
. Taking logs base we get

To understand the right-hand inequality intuitively, note that the standard deviation of coinflips is  , so having be only an
, so having be only an 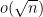 deviation above
deviation above  makes the overall density of only vanishingly above one-half. Thus and can agree on barely over half the inputs in
makes the overall density of only vanishingly above one-half. Thus and can agree on barely over half the inputs in 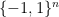 , making —that is, parity—inapproximable by any small-depth, sub-exponential size circuits . A tour-de-force.
, making —that is, parity—inapproximable by any small-depth, sub-exponential size circuits . A tour-de-force.
Note that the agreement set is implicitly talking about correlation with the uniform distribution on  . We would be interested in treatments that consider non-independent distributions on , and note the presentation of Smolensky’s theorem by Emanuele Viola in this paper in that regard.
. We would be interested in treatments that consider non-independent distributions on , and note the presentation of Smolensky’s theorem by Emanuele Viola in this paper in that regard.
The Analogy
The analogy is that the proof technique—for the Lemma—does not require the distribution over the inputs to be uniform. Indeed they can be joint functions of some “hidden variable” , and be in that sense “entangled.” More concretely, they can be arbitrarily strongly correlated. The proof technique copes with this lack of entropy in by creating its own entropy in the ability to fit the coefficients when taking a low-degree polynomial that succeeds with high probability. Although the theorem is usually presented assuming uniform distribution over the inputs , this is not actually needed for the Lemma.
The analogy with our quantum debate is made by asking, do fault-tolerance schemes work more like the Lemma, or do they really need independence? At the risk of straining what we are trying to say, we can draw out the analogy even further:
 “Model of Noise”: A class of distributions on the inputs to the circuit , or on any gate of .
“Model of Noise”: A class of distributions on the inputs to the circuit , or on any gate of .
“Correlated/Entangled Errors”: is the image distribution under mappings  ,
,  ,
, 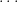 ,
,  of a distribution
of a distribution  on a set , where may have lower entropy/fewer degrees of freedom. Note that gates lower down in the circuit may have a greater degree of correlation resulting from the computation by gates above them.
on a set , where may have lower entropy/fewer degrees of freedom. Note that gates lower down in the circuit may have a greater degree of correlation resulting from the computation by gates above them.
“Reasonable Noise Model”: The distribution is not too complex, such as being  -samplable, or is natural in some other sense. For instance, could be induced from some distribution
-samplable, or is natural in some other sense. For instance, could be induced from some distribution 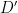 on co-ordinates
on co-ordinates  by some operation on the
by some operation on the 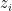 co-ordinates, such as projection or “tracing out.”
co-ordinates, such as projection or “tracing out.”
“Feasible States”: The coefficients that achieve the desired approximations are easy to compute, for instance -uniform.
The main lack in this analogy is that the complexity-class side has no notion of “noise” per se or “errors” or “correction.” But we offer it nevertheless because we see some similarity in the mathematical issues. We also would like to ask whether the feasible-construction issues have been addressed as-such by complexity theorists.
We have a further reason for thinking along lines of distributions, a.k.a. measures, in a related context. A survey paper by Akshay Venkatesh of Stanford about work on the Littlewood conjecture has some interesting examples and declares straight out:
Measures are often easier to work with than sets.
In particular, on pages 12–13 he gives an example of a statement about sets that is “wishful thinking” for sets, but which he can “salvage” in terms of distributions. We intend to elaborate on this point soon.
Open Problems
What is the complexity of constructing the polynomials that approximate a gate, or a circuit of gates, in terms of the complexity of the distribution on their inputs? Under what conditions are the resulting polynomials computable jointly in uniform polynomial time? When are they succinct?
Why does Smolensky’s argument fail to give a super-polynomial size lower bound for constant-depth circuits with  gates that compute parity? Can we give a better, deeper answer than, “because
gates that compute parity? Can we give a better, deeper answer than, “because  is not a field”?
is not a field”?
[fixed formula for g-prime]


