

A primer on Windows PE files and doing API calls without knowledge of memory lay...
source link: https://codeinsecurity.wordpress.com/2021/08/18/a-primer-on-windows-pe-files-and-doing-api-calls-without-knowledge-of-memory-layout/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

A primer on Windows PE files and doing API calls without knowledge of memory layout
This blog post started as a ridiculously long comment on a GitHub issue. It’s long enough that it should be a blog post, as someone on Twitter pointed out to me, so now I’m replicating it here with some tweaks to make it read a bit better in continuous prose.
A caveat: I very quickly slapped this together and have not 100% validated everything. There might be some mistakes. Shout at me on Twitter if you find issues.
The issue at hand here is this: you’ve got an x86_64 Windows PE and you want to change its behaviour by executing a stub or some shellcode in the process when it runs. That stub or shellcode needs to make API calls, but you can’t guarantee that the PE you’re injecting into actually imports the APIs you want to use, and you don’t know anything about the memory layout ahead of time. So how do you make this work?
To make sure we’re all on the same page, I’m going to start with the PE format.
All screenshots here are from CFF Explorer, which is a PE editor tool. It’s kinda old but it gets the job done. I’m also just looking at a 64-bit executable since 32-bit structures are slightly different.
PEs files start with an old 16-bit DOS header. This header is almost entirely ignored on modern Windows, so the only fields that typically matter are e_magic (which must be ‘MZ’) and e_lfanew, which points to the offset of the NT header.

The e_lfanew field is always at 0x3C. It tells you the offset of the NT headers. Here’s a tree view of the overall structure just to keep the overall layout in your head.
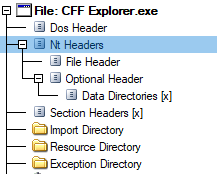
You can see that its offset is at 0x108, which is where e_lfanew said it was. You might notice that there’s a bit of a gap between the end of the PE header at 0x40 and the start of the NT header at 0x108.
What sits in that space is the DOS stub. You know the old “This program cannot be run in DOS mode”? That’s actually a 16-bit x86 DOS program, stored in the file immediately after the e_lfanew field, but before the NT header. If you try to run a modern Windows PE under DOS, it runs that program instead of the PE. Since the e_lfanew field is 32-bit, you can actually embed a complete 16-bit DOS program in there for cross-compatibility!
For fun, here’s the stub disassembled:

If you’re really eagle-eyed, you might have noticed that the DOS header plus the string it references still doesn’t make up the full size of the gap between 0x40 and 0x108. And you’d be right. This executable also happens to contain something called a RICH header, which is a kinda weird self-contained debug blob. Has its uses, but irrelevant here.
Anyway, back to the main topic. After the NT header signature comes the File Header and the Optional Header. These are sequential.
The File Header contains some important fields.
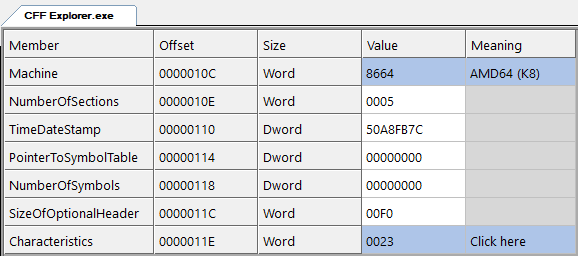
The first is the Machine field, which tells you what machine this was built for. 0x8664 means x86_64, and 0x14C means x86_32. There are a bunch more defined values but unless you’re planning on working with Itanium or ARM PEs I wouldn’t worry about it.
Next is the NumberOfSections field. This tells you how many sections there are in the section table. We’ll come to that later.
TimeDateStamp and the symbol table fields can be ignored. SizeOfOptionalHeader is the next of importance – it tells us how big the next structure is going to be. It should always be 0xF0 on a 64-bit executable.
Finally there’s Characteristics. This is a bitfield that specifies various flags. The flags in here should be irrelevant for your use-case, but flag 0x20 is “image can handle >2GB address space” which, if you ever do 32-bit stuff, will be important because it signifies PAE compatibility, i.e. the ability to have a virtual address space up to 3GB (or sometimes 4GB) in size per 32-bit process. If you’re just doing 64-bit, ignore this.
The optional header is where most of the magic happens. It’s different between 32-bit and 64-bit programs. I’ll focus only on 64-bit.

The first field here tells you which structure to use. 0x020B is PE64, 0x010B is PE32.
The SizeOfCode and SizeOfInitializedData fields are the sum of the sizes of the sections that have the “Contains code” and “Contains initialised data” flags respectively. You shouldn’t need to update these since if you inject a new section you don’t actually have to apply these flags to make it work. I’ll get into that later.
AddressOfEntryPoint is the RVA of the entry point. Notice that CFF has marked it as “.text” next to it, indicating that this RVA points to something in the .text section. This field is what you change to make the PE start executing your own stub.
BaseOfCode is the RVA of the code section. You shouldn’t need to touch this, but it basically just points to the virtual address of the .text section.
ImageBase is the “preferred” base address of the executable, i.e. if ASLR was disabled the image would be loaded at that virtual address assuming that nothing else was already loaded there. This is largely irrelevant these days, although it does have one weird implementation detail – in order to support full “high entropy” ASLR the specified image base must be in the upper side of the 64-bit virtual address space, i.e. 0x100000000 or higher. You can generally ignore this.
SectionAlignment is the alignment of the virtual address space for sections. This is usually set to 0x1000, i.e. one page. You are not allowed to specify section start addresses or sizes with smaller granularities than the alignment. So all sections’ virtual addresses must start at a multiple of 0x1000.
FileAlignment is the alignment of the section data in the file. Each section has a “Raw Address” and “Raw Size” field that specifies where its contents are in the PE file. This is how the loader takes code and data from the PE file and puts it in memory ready to be used. The FileAlignment field must be at least 0x200 on Win10, and it is usually 0x200 anyway. This means that the data for each section in the file must start at an offset that is a multiple of the file alignment, and its size must also be a multiple of the file alignment. Don’t worry if this is a bit confusing, you’ll see this more clearly later.
SizeOfImage is supposed to be the size of the image, but it’s calculated in a weird way. Basically take the highest virtual address of a section, add the virtual size, and round up to a multiple of SectionAlignment. Here it’s 0x2BF000 + 0xA7D7C = 0x366D7C, which gets you 0x367000. You’ll need to update this if you inject a new section.
SizeOfHeaders is the size of all image headers rounded up to FileAlignment. Almost always 0x400 in normal executables, but may be 0x200 in packed executables that omit some data directories and have only one section.
CheckSum is generally ignored. Technically if it is set it to a non-zero value it should be correct, but in practice it doesn’t matter. Good practice to zero it or set it correctly if you’re modifying a PE, but not strictly necessary.
Subsystem tells you which subsystem loads the PE. The two you’ll run into are 0x0002, which is Windows GUI, and 0x0003, which is Windows Console. You might also see 0x0001, which is Native, i.e. a kernel driver.
DllCharacteristics tells you a bunch of flags about the executable. 0x40 is dynamic base (ASLR supported), 0x80 is the force integrity flag (related to signing policies), 0x100 is NX compatible (DEP), the rest are irrelevant.
Finally you’ve got NumberOfRvaAndSizes. This tells you how many entries there are in the directory table. The directory table tells the loader where certain optional structures are in memory. The directory table covers things like imports, exports, exception tables, digital signatures, relocations, debug info, thread-local storage config, IATs, and .NET metadata for CLR executables.
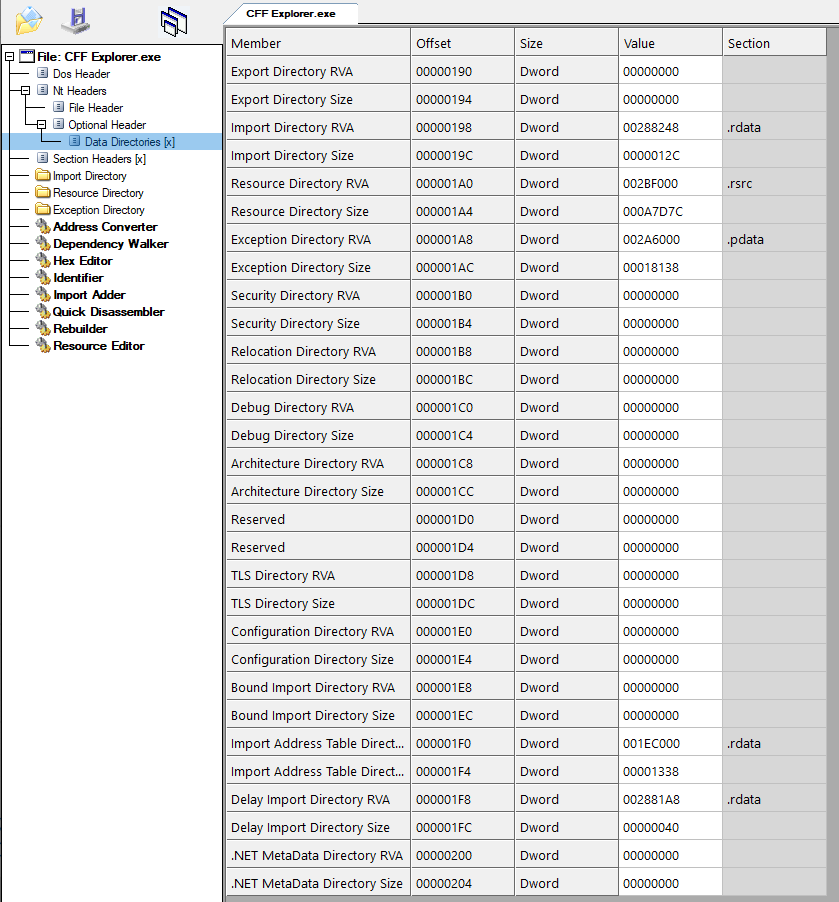
The data directories table is an array of up to 15 entries, each containing an RVA and size field. The NumberOfRvaAndSizes field is the number of valid entries in the table, plus one null entry on the end. So for a full table (the norm) it’s 16, or 0x10. Normally you won’t see any other value than 0x10 in a non-packed executable.
The meaning of each directory is hard-coded by its index, i.e. export = 0, import = 1, resource = 2, exception = 3, etc.
The RVA is the virtual address, relative to the image base, of the location of the data for that directory. These match up with sections, i.e. every directory points to some address in a section, rather than to an offset in the file.
The ones you care about at the Export Directory, Import Directory and the Import Address Table (IAT) Directory. I’ll describe these later since it makes more sense to look at sections first.
Immediately after the data directories you have the sections table.

Each entry in the table is called a section header and it has ten fields. A section lays out parts of program memory in virtual address space, telling the loader what page access flags to apply and what content to load.
The first field is the section name, which is an 8 byte string padded with nulls. These are effectively meaningless but the convention is to call the code section .text, the read-only data section .rdata, the read-write data section (for storing globals and setting their initial values) .data, any resources in .rsrc, and there are others for various other purposes. The names don’t do anything, they’re just for identification purposes.
Next are the Virtual Size and Virtual Address. These specify where the section should be mapped in memory, relative to the base address of the module, often referred to as an RVA. The virtual address must be aligned to SectionAlignment. The virtual size can be any number (unaligned), specifying exactly how many bytes from the file must be copied into the memory region. The allocated memory region itself will be rounded up to the nearest page boundary, so if you specify a size of 0x3E4C the section will be 0x4000 bytes in memory, but only the first 0x3E4C bytes will have data written into them.
After that you’ve got the Raw Size and Raw Address. These specify where the section’s data is stored in the file. The raw address and raw size must be aligned to FileAlignment.
The other fields are unimportant, other than the Characteristics field which has flags about how the section works. The top nibble specifies the page protection flags: 0x2 for executable, 0x4 for readable, 0x8 for executable. There’s also the “contains code” flag (0x20) and “contains initialised data” (0x40) flags at the bottom end of the field, which you shouldn’t need to care about since they don’t actually affect the functionality. The .text section usually has Characteristics value of 0x60000020, i.e. read+exec, contains code. The .rdata is readable, contains initialised data. The .data is read+write, contains initialised data.
You can translate between an RVA and a file offset using the table. Given an RVA, you scan through the section table, find the section that contains that RVA (i.e. RVA >= Virtual Address && RVA < Virtual Address + Virtual Size). You then subtract the RVA from the Virtual Address of the section to get the offset of that address in the section, and add it to the Raw Address to get the file offset.
Here’s a code example in Python:
def rva_to_offset(rva):for section in sections:if rva >= section.VirtualAddress and rva < (section.VirtualAddress + section.VirtualSize):sectionOffset = rva - section.VirtualAddressreturn section.RawAddress + sectionOffsetreturn nullYou can do the inverse, too, i.e. go from an offset to RVA:
def offset_to_rva(offset):for section in sections:if offset >= section.RawAddress and offset < (section.RawAddress + section.RawSize):sectionOffset = offset - section.RawAddressreturn section.VirtualAddress + sectionOffsetreturn nullYou can also convert from a relative virtual address (RVA) to a virtual address (VA) by adding the PE’s ImageBase field value to the RVA. So, for example, an RVA of 0x2000 would have a VA of 0x140002000, given the ImageBase of 0x140000000 shown in this particular PE. The VA is useful because it specifies the address that would be used in the real running program if the module was loaded at its preferred base address.
If you want to inject new sections, you can often do so without rebuilding the PE file. This is possible because most PE files have headers sized between 0x200 and 0x300 bytes, and the first section’s data generally doesn’t start until 0x400 because of file alignment, leaving a fairly large gap after the section table, full of null bytes. This means you can inject your own section at the end of the table, update the NumberOfSections field of the File Header, and you’re done. If you do need to make room for more sections, you can move all of the section data further down in the file by a multiple of the file alignment (usually 0x200 bytes) and just update the Raw Address field of each section to reflect the moved data. Since everything else in the PE format that refers to data in sections uses RVAs, moving the actual data around in the file doesn’t require anything else to be re-computed – you’re just remapping the location of the data.
That’s about it for sections. Now let’s talk about imports and exports.
Normally on Windows your application imports the APIs for you so you don’t have to worry about all this manual lookup stuff. This importing is done via the import table and the IAT. The import table has entries for each DLL you want to import APIs from, then a set of imports for each of those DLLs. When the program starts, the Windows image loader loads the libraries into the program memory space, then finds the required imports and writes the addresses of the API functions into the import address table (IAT).
You can also dynamically load libraries with LoadLibrary, and then find APIs by name in a loaded library with GetProcAddress. But the thing is, you need to know where those APIs are in the first place to make those API calls to find other API addresses – a catch 22. However, if you can find those two APIs through some other method, you can use them to easily and reliably load any API you like. Both of those two APIs are in kernel32.dll, to make things a bit easier.
Instead of trying to find the APIs you want via the import directory of the program executable, you can instead find them via the export directory of the DLL that contains the exports you want. As long as you know where that module is in memory, you can find the export directory, and find the APIs! But how do you know where the module is in memory? I’ll get to that later.
The export directory is a little simpler than the import directory. It starts with a header:
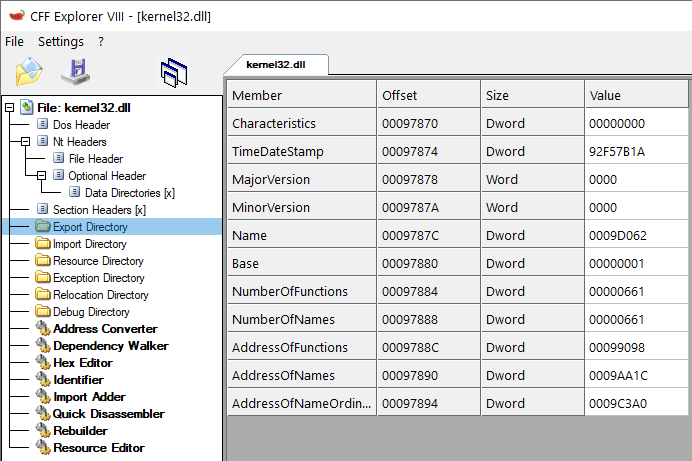
Name is the RVA of a null-terminated string that specifies the name of the DLL. If you convert the RVA to an offset you’ll find the string in the file there. In this case I’m using kernel32.dll as an example:

NumberOfFunctions is the number of exported functions, unsurprisingly.
NumberOfNames is the number of names in the export name table. This can be different to the number of exported functions, because some functions can be exported by ordinal (index in the table) rather than by name.
The export table is effectively three arrays. One for the RVAs to the functions (i.e. RVAs that point to the first instruction of the functions), one for the RVAs to the ordinals, and one for the RVAs to the function names. So for each entry you have a function, an ordinal, and a name.
AddressOfFunctions is the address of the function RVA list, which is basically an array of RVAs (kinda like pointers, here) to the function implementations.
AddressOfNames is the same but for RVAs to the name strings. Each is null-terminated.
AddressOfNameOrdinals is another array that specifies the ordinal of each function. Each is a 16-bit value.
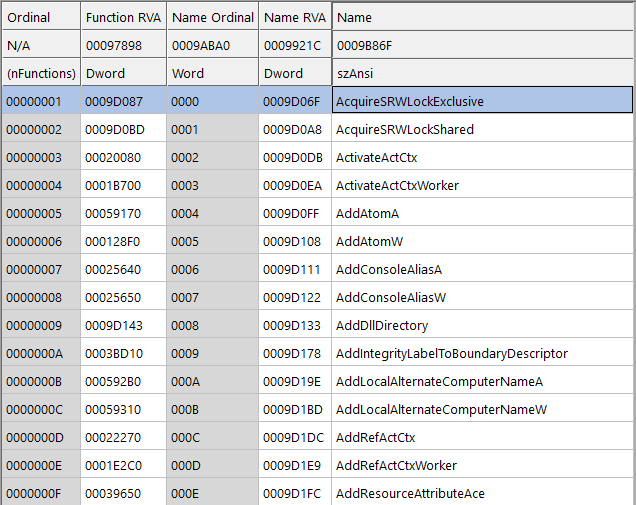
So basically you’ve got:
void* Functions[NumberOfFunctions];char_t* Names[NumberOfNames];uint16_t NameOrdinals[NumberOfNames];Each function can be accessed by those indices. Functions with no name are importable by their ordinal (index into the array) – not to be confused with a name ordinal, which is different. Don’t worry about ordinals too much, they don’t come up very often and you don’t really care about them here.
So to find a function by its name in the export table, you look at the AddressOfNames field to get the RVA of the names array, then use that to loop through each of the name RVAs to find the one that matches the name of the API you want. That gives you the index into the other arrays to find where the function is.
For example:
void* getFunction(const char* functionName){for (int n = 0; n < exportDirectory->NumberOfNames; n++){if (strncmp(functionName, exportDirectory->Names[n], peHeader->SizeOfImage) == 0){return exportDirectory->Functions[n];}}return NULL;}Keep in mind that this gives you the RVA, so if you want the virtual address you need to add the base address of the module.
So now you know how to find an API export in a PE file, as long as you know its base address. So how do you find its base address? All Windows processes have a structure called the Process Environment Block (PEB) in memory. The structure is undocumented, but extremely stable. You can access the PEB via the Thread Environment Block (TEB), which has a ProcessEnvironmentBlock field at offset 0x60 on 64-bit processes. The TEB is accessible via the GS segment register, so reading the PEB pointer is just a case of doing mov rax, gs:[0x60] or using an intrinsic such as __readgsqword(0x60).
The field at offset 0x10 of the PEB is ImageBaseAddress. This tells you the base address of the main executable module for the current process. So if your process is Task Manager, this is the image base address for the taskmgr.exe module.
The field at offset 0x18 is Ldr, also known as the loader data. It is a pointer to a PEB_LDR_DATA structure that includes information about modules loaded into the process. The InLoadOrderModuleList and InMemoryOrderModuleList fields of that structure are the heads of doubly-linked lists that describe the modules that are loaded into the process. Their offsets are 0x10 and 0x20 respectively, and this hasn’t changed since the Windows 3.x days.
Each of these linked lists uses a LIST_ENTRY struct as a header. Immediately after each entry (apart from the one inside the PEB_LDR_DATA struct itself) is an LDR_DATA_TABLE_ENTRY struct. This struct describes a module that has been loaded into the process. Its fields of key interest include DllBase, EntryPoint, FullDllName, and BaseDllName. Ignore the use of “DLL” here – it really means any executable module.
The DllBase field tells you the base address of the module after it was loaded into memory. The EntryPoint field tells you the address of the entry point for that module, which should match the AddressOfEntryPoint field from that module’s PE (albeit as a virtual address, not an RVA). The FullDllName and BaseDllName fields are UNICODE_STRING structures that contain the full path to the module file and the name of the module respectively. You can use these to find a module by name.
In short, the process to find a module in memory, by name, is:
- Read the
ProcessEnvironmentBlockpointer from the TEB atgs:[0x60]. - Read the
Ldrpointer from the PEB to get the loader data. - Iterate through either
InLoadOrderModuleListorInMemoryOrderModuleListusing theFlinkfield (forward link). - Find the
LDR_DATA_TABLE_ENTRYstruct immediately after eachLIST_ENTRYstruct. - Read the
Bufferfield ofBaseDllNameand check it against the name that you want, e.g. kernel32.dll - If it matches, read the
DllBasefield to get its base address in memory.
The base address of the module points to the DOS header (MZ …) of the module in memory. You can then apply the techniques previously discussed to find the export table and figure out where APIs are.
So let’s say you want to find LoadModule and GetProcAddress from kernel32.dll at runtime – here’s the steps in pseudocode:
// get PEB from TEB at gs:[0x60]PEB* peb = (PEB*)__readgsqword(0x60);PEB_LDR_DATA* ldr = peb->Ldr;// start at the first node// the first LIST_ENTRY is in the PEB_LDR_DATA struct, so not validLIST_ENTRY* currentNode = &ldr->InLoadOrderModuleList->Flink;IMAGE_DOS_HEADER* kernel32_dos = NULL;do{// get LDR_DATA_TABLE_ENTRY after LIST_ENTRYLDR_DATA_TABLE_ENTRY* entry = (LDR_DATA_TABLE_ENTRY*)(((uint8_t*)currentNode) + sizeof(LIST_ENTRY));USHORT length = currentNode->BaseDllName->Length;wchar_t* dllNameStr = currentNode->BaseDllName->Buffer;// case-insensitive wide string comparison, with length limitif (wcsnicmp(L"kernel32.dll", dllNameStr, length) == 0){// this is kernel32kernel32_dos = (IMAGE_DOS_HEADER*)currentNode->DllBase;break;}// not kernel32, try the next modulecurrentNode = currentNode->Flink;}while (currentNode != NULL && currentNode != &ldr->InLoadOrderModuleList);// did we find kernel32?if (!kernel32_dos)return -1;uint8_t* kernel32_base = (uint8_t*)kernel32_dos;// find the NT header at the offset specified by e_lfanewIMAGE_NT_HEADERS64* ntHeader = (IMAGE_NT_HEADERS64*)(kernel32_base + kernel32_dos->e_lfanew);// get the file & PE (optional) headersIMAGE_FILE_HEADER* fileHeader = &ntHeader->FileHeader;IMAGE_OPTIONAL_HEADER64* peHeader = &ntHeader->OptionalHeader;uint8_t* peHeaderBase = (uint8_t*)peHeader;// data directories are directly after the PE (optional) header.IMAGE_DATA_DIRECTORY* directories = (IMAGE_DATA_DIRECTORY*)(peHeaderBase + sizeof(IMAGE_OPTIONAL_HEADER64));// find the sectionssize_t sizeOfDirectories = sizeof(IMAGE_DATA_DIRECTORY) * peHeader->NumberOfRvaAndSizes;IMAGE_SECTION_HEADER* sections = (IMAGE_SECTION_HEADER*)(peHeaderBase + sizeof(IMAGE_OPTIONAL_HEADER64) + sizeOfDirectories);// get the virtual address of the export directoryIMAGE_EXPORT_DIRECTORY* exportDir = (IMAGE_EXPORT_DIRECTORY*)(kernel32_base + directories[0]->RVA);// get the export arraysDWORD* nameRVAs = (DWORD*)(kernel32_base + exportDir->AddressOfNames);DWORD* functionRVAs = (DWORD*)(kernel32_base + exportDir->AddressOfFunctions);void* fnLoadLibrary = NULL;void* fnGetProcAddress = NULL;for (int n = 0; n < exportDir->NumberOfNames; n++){char* name = (char*)(kernel32_base + nameRVAs[n]);void* func = (void*)(kernel32_base + functionRVAs[n]);if (strcmp("LoadLibrary", name) == 0)fnLoadLibrary = func;if (strcmp("GetProcAddress", name) == 0)fnGetProcAddress = func;if (fnLoadLibrary != NULL && fnGetProcAddress != NULL)break;}// did we find the APIs?if (fnLoadLibrary == NULL || fnGetProcAddress == NULL)return -2;// ok, now you've got the address of LoadLibrary and GetProcAddress and you can call them!Once you’ve got LoadLibrary and GetProcAddress you can just get any API you like, or load any DLL:
HANDLE hKernel32 = LoadLibrary("kernel32.dll");SOME_FUNCTION_TYPE fnOpenProcess = GetProcAddress(hKernel32, "OpenProcess");Congrats, you’re done.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK