

Go的AST(抽象语法树)
source link: https://zhuanlan.zhihu.com/p/28516587
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Go的AST(抽象语法树)
什么是AST?
AST,它的全名是abstract syntax tree(抽象语法树),就算没有学过编译原理的同学应该也听说过它。
抽象语法树,其实就是使用树状结构表示源代码的语法结构,树的每一个节点就代表源代码中的一个结构。
例如,表达式10+3*(7-2)-4
抽象语法树为:
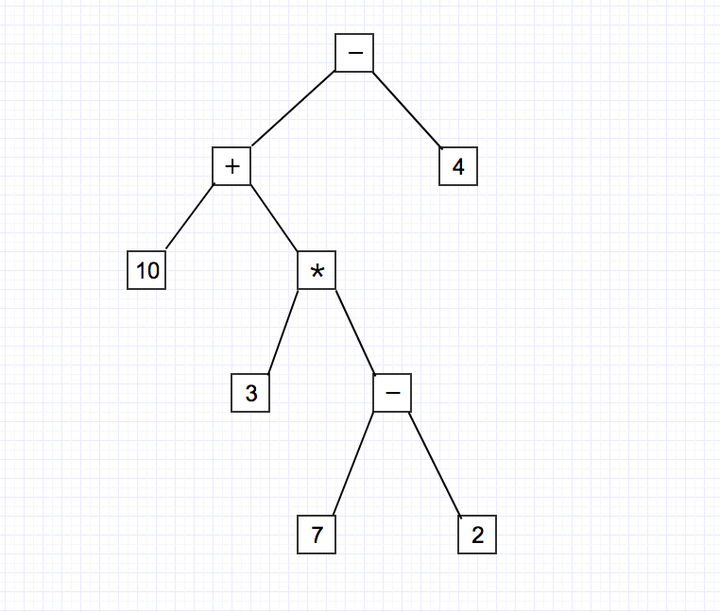
(熟悉的同学可以看到我们可以中序遍历还原该表达式。这个这里就不说了。)
为什么我们需要AST?
当我们对源代码语法分析时,其实我们是在程序设计语言的语法规则指导下才能进行的。我们使用语法规则描述该语言的各种语法成分的是如何组成的,通常用前后文无关文法或与之等价的Backus-Naur范式(BNF)将相应程序设计语言的语法规则准确的描述出来。前后文无关文法有一般分为:LL(1),LR(0),LR(1), LR(k) 等。每一种文法都有不同的要求,这些我们在编译原理书籍中可以找到,感兴趣的同学可以随便翻一本大学教科书查看,理解起来可能比较晦涩(当时考完我心里很虚,觉得要挂了,微信和编译原理老师聊天,居然说85。。。还好还好)。任何语言都必须有这自己使用的文法规则,当你了解了这些规则,你也就明白代码到底是如何组织的。
Ok,下面我们步入正题,Go如何做的语法分析的呢?
Go的AST内部是如何组织的?
我们知道,根据编译过程,一般来说首先我们需要词法分析,然后才有语法分析。Go的parser接受的输入是源文件,内嵌了一个scanner,最后把scanner生成的token变成一颗抽象语法树(AST)。
我们现在打印下输出hello,world的抽象语法树。这也是官网的例子。
package main
import (
"go/ast"
"go/parser"
"go/token"
)
func main() {
// src is the input for which we want to print the AST.
src := `
package main
func main() {
println("Hello, World!")
}
`
// Create the AST by parsing src.
fset := token.NewFileSet() // positions are relative to fset
f, err := parser.ParseFile(fset, "", src, 0)
if err != nil {
panic(err)
}
// Print the AST.
ast.Print(fset, f)
}
先看下语法树,解释下都有哪些东西:
0 *ast.File {
1 . Package: 2:1
2 . Name: *ast.Ident {
3 . . NamePos: 2:9
4 . . Name: "main"
5 . }
6 . Decls: []ast.Decl (len = 1) {
7 . . 0: *ast.FuncDecl {
8 . . . Name: *ast.Ident {
9 . . . . NamePos: 3:6
10 . . . . Name: "main"
11 . . . . Obj: *ast.Object {
12 . . . . . Kind: func
13 . . . . . Name: "main"
14 . . . . . Decl: *(obj @ 7)
15 . . . . }
16 . . . }
17 . . . Type: *ast.FuncType {
18 . . . . Func: 3:1
19 . . . . Params: *ast.FieldList {
20 . . . . . Opening: 3:10
21 . . . . . Closing: 3:11
22 . . . . }
23 . . . }
24 . . . Body: *ast.BlockStmt {
25 . . . . Lbrace: 3:13
26 . . . . List: []ast.Stmt (len = 1) {
27 . . . . . 0: *ast.ExprStmt {
28 . . . . . . X: *ast.CallExpr {
29 . . . . . . . Fun: *ast.Ident {
30 . . . . . . . . NamePos: 4:5
31 . . . . . . . . Name: "println"
32 . . . . . . . }
33 . . . . . . . Lparen: 4:12
34 . . . . . . . Args: []ast.Expr (len = 1) {
35 . . . . . . . . 0: *ast.BasicLit {
36 . . . . . . . . . ValuePos: 4:13
37 . . . . . . . . . Kind: STRING
38 . . . . . . . . . Value: "\"Hello, World!\""
39 . . . . . . . . }
40 . . . . . . . }
41 . . . . . . . Ellipsis: -
42 . . . . . . . Rparen: 4:28
43 . . . . . . }
44 . . . . . }
45 . . . . }
46 . . . . Rbrace: 5:1
47 . . . }
48 . . }
49 . }
50 . Scope: *ast.Scope {
51 . . Objects: map[string]*ast.Object (len = 1) {
52 . . . "main": *(obj @ 11)
53 . . }
54 . }
55 . Unresolved: []*ast.Ident (len = 1) {
56 . . 0: *(obj @ 29)
57 . }
58 }
- Package: 2:1代表Go解析出package这个词在第二行的第一个
- main是一个ast.Ident标识符,它的位置在第二行的第9个
- 此处func main被解析成ast.FuncDecl(function declaration),而函数的参数(Params)和函数体(Body)自然也在这个FuncDecl中。Params对应的是*ast.FieldList,顾名思义就是项列表;而由大括号“{}”组成的函数体对应的是ast.BlockStmt(block statement)
- 而对于main函数的函数体中,我们可以看到调用了println函数,在ast中对应的是ExprStmt(Express Statement),调用函数的表达式对应的是CallExpr(Call Expression),调用的参数自然不能错过,因为参数只有字符串,所以go把它归为ast.BasicLis (a literal of basic type)。
- 最后,我们可以看出ast还解析出了函数的作用域,以及作用域对应的对象。
- Go将所有可以识别的token抽象成Node,通过interface方式组织在一起。
- 在这里说到token我们需要说一下词法分析,token是词法分析的结果,即将字符序列转换为标记(token)的过程,这个操作由词法分析器完成。这里的标记是一个字符串,是构成源代码的最小单位。
比如 sum = 9-5
sum ----- 标识符
= ------ 赋值操作符
9 ------ 数字
- ------ 减法操作符
5 ------ 数字
ok,现在我们看下,语法树的生成过程。
fset := token.NewFileSet()
新建一个AST文件集合,
// A FileSet represents a set of source files.
// Methods of file sets are synchronized; multiple goroutines
// may invoke them concurrently.
//
type FileSet struct {
mutex sync.RWMutex // 加锁保护
base int // 基准偏移
files []*File // 按顺序被加入的文件集合
last *File // 最后一个文件缓存
}
然后,解析该集合,f, err := parser.ParseFile(fset, "", src, 0)
ParseFile会解析单个Go源文件的源代码并返回相应的ast.File节点。源代码可以通过传入源文件的文件名,或src参数提供。如果src!= nil,则ParseFile将从src中解析源代码,文件名为仅在记录位置信息时使用。
func ParseFile(fset *token.FileSet, filename string, src interface{}, mode Mode) (f *ast.File, err error) {
if fset == nil {
panic("parser.ParseFile: no token.FileSet provided (fset == nil)")
}
// 读取源文件,返回[]byte类型数据
text, err := readSource(filename, src)
if err != nil {
return nil, err
}
var p parser
defer func() {
if e := recover(); e != nil {
// resume same panic if it's not a bailout
if _, ok := e.(bailout); !ok {
panic(e)
}
}
// set result values
if f == nil {
// source is not a valid Go source file - satisfy
// ParseFile API and return a valid (but) empty
// *ast.File
f = &ast.File{
Name: new(ast.Ident),
Scope: ast.NewScope(nil),
}
}
p.errors.Sort()
err = p.errors.Err()
}()
// 解析文件
// 初始化解析器
p.init(fset, filename, text, mode)
// 解析器解析文件
f = p.parseFile()
return
}parse是解析器的结构体
// parser 结构体是解析器的核心
type parser struct {
file *token.File
errors scanner.ErrorList
scanner scanner.Scanner
// 追踪和问题排查
mode Mode // 解析模式
trace bool // == (mode & Trace != 0)
indent int // 跟踪输出的缩进
// Comments
comments []*ast.CommentGroup
leadComment *ast.CommentGroup
lineComment *ast.CommentGroup
// 定义下一个标识
pos token.Pos
tok token.Token
lit string
// 错误恢复
syncPos token.Pos
syncCnt int
// 非句法解析器控制
exprLev int
inRhs bool
// 普通标识符范围
pkgScope *ast.Scope
topScope *ast.Scope
unresolved []*ast.Ident
imports []*ast.ImportSpec
// 标签范围
labelScope *ast.Scope
targetStack [][]*ast.Ident
}我们来看下具体的解析过程。
func (p *parser) parseFile() *ast.File {
// 追踪模式
if p.trace {
defer un(trace(p, "File"))
}
// 如果我们扫描第一个令牌时出现错误,不影响其他的解析
if p.errors.Len() != 0 {
return nil
}
// package的条款
doc := p.leadComment
pos := p.expect(token.PACKAGE)
ident := p.parseIdent()
if ident.Name == "_" && p.mode&DeclarationErrors != 0 {
p.error(p.pos, "invalid package name _")
}
p.expectSemi()
if p.errors.Len() != 0 {
return nil
}
p.openScope()
// 作用域
p.pkgScope = p.topScope
// 声明的node集合
var decls []ast.Decl
if p.mode&PackageClauseOnly == 0 {
// import decls
for p.tok == token.IMPORT {
decls = append(decls, p.parseGenDecl(token.IMPORT, p.parseImportSpec))
}
if p.mode&ImportsOnly == 0 {
// 其余的包装体
for p.tok != token.EOF {
decls = append(decls, p.parseDecl(syncDecl))
}
}
}
p.closeScope()
assert(p.topScope == nil, "unbalanced scopes")
assert(p.labelScope == nil, "unbalanced label scopes")
// 解析同一文件中的全局标识符
i := 0
for _, ident := range p.unresolved {
assert(ident.Obj == unresolved, "object already resolved")
ident.Obj = p.pkgScope.Lookup(ident.Name) // also removes unresolved sentinel
if ident.Obj == nil {
p.unresolved[i] = ident
i++
}
}
// 构造AST文件
return &ast.File{
Doc: doc,
Package: pos,
Name: ident,
Decls: decls,
Scope: p.pkgScope,
Imports: p.imports,
Unresolved: p.unresolved[0:i],
Comments: p.comments,
}
}我们来看下AST的每种类型结构
// 所有的AST树的节点都需要实现Node接口
type Node interface {
Pos() token.Pos // position of first character belonging to the node
End() token.Pos // position of first character immediately after the node
}
// 所有的表达式都需要实现Expr接口
type Expr interface {
Node
exprNode()
}
// 所有的语句都需要实现Stmt接口
type Stmt interface {
Node
stmtNode()
}
// 所有的声明都需要实现Decl接口
type Decl interface {
Node
declNode()
}上面就是语法的三个主体,表达式(expression),语句(statement)和声明(declaration),Node是基类接口,任何类型的主体都是Node,用于标记该节点位置的开始和结束.
不过三个主体的函数没有实际意义,只是用三个interface来区分不同的语法单位,如果某个语法是Stmt的话,就实现一个空的stmtNode函数即可.
这样的好处是可以对语法单元进行comma,ok来判断类型,并且保证只有这些变量可以赋值给对应的interface.但是实际上这个划分不是很严格
来看整个内容详情:
1.普通Node,不是特定语法结构,属于某个语法结构的一部分.
- Comment 表示一行注释 // 或者 / /
- CommentGroup 表示多行注释
- Field 表示结构体中的一个定义或者变量,或者函数签名当中的参数或者返回值
- FieldList 表示以”{}”或者”()”包围的Filed列表
2.Expression & Types (都划分成Expr接口)
- BadExpr 用来表示错误表达式的占位符
- Ident 比如报名,函数名,变量名
- Ellipsis 省略号表达式,比如参数列表的最后一个可以写成arg...
- BasicLit 基本字面值,数字或者字符串
- FuncLit 函数定义
- CompositeLit 构造类型,比如{1,2,3,4}
- ParenExpr 括号表达式,被括号包裹的表达式
- SelectorExpr 选择结构,类似于a.b的结构
- IndexExpr 下标结构,类似这样的结构 expr[expr]
- SliceExpr 切片表达式,类似这样 expr[low:mid:high]
- TypeAssertExpr 类型断言类似于 X.(type)
- CallExpr 调用类型,类似于 expr()
- StarExpr 表达式,类似于 X
- UnaryExpr 一元表达式
- BinaryExpr 二元表达式
- KeyValueExp 键值表达式 key:value
- ArrayType 数组类型
- StructType 结构体类型
- FuncType 函数类型
- InterfaceType 接口类型
- MapType map类型
- ChanType 管道类型
3.Statements
- BadStmt 错误的语句
- DeclStmt 在语句列表里的申明
- EmptyStmt 空语句
- LabeledStmt 标签语句类似于 indent:stmt
- ExprStmt 包含单独的表达式语句
- SendStmt chan发送语句
- IncDecStmt 自增或者自减语句
- AssignStmt 赋值语句
- GoStmt Go语句
- DeferStmt 延迟语句
- ReturnStmt return 语句
- BranchStmt 分支语句 例如break continue
- BlockStmt 块语句 {} 包裹
- IfStmt If 语句
- CaseClause case 语句
- SwitchStmt switch 语句
- TypeSwitchStmt 类型switch 语句 switch x:=y.(type)
- CommClause 发送或者接受的case语句,类似于 case x <-:
- SelectStmt select 语句
- ForStmt for 语句
- RangeStmt range 语句
4.Declarations
- Spec type
- Import Spec
- Value Spec
- Type Spec
- BadDecl 错误申明
- GenDecl 一般申明(和Spec相关,比如 import “a”,var a,type a)
- FuncDecl 函数申明
- Spec type
5.Files and Packages
- File 代表一个源文件节点,包含了顶级元素.
- Package 代表一个包,包含了很多文件.
AST的效果?
所以构建成的一棵树就是这样:
有人还专门给Go的语法树做了个可视化:yuroyoro/goast-viewer,有兴趣可以试试,相信会对语法树更加清晰。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK