

图片风格迁移:基于实例缓解细节丢失、人脸风格化失败问题
source link: https://my.oschina.net/u/4526289/blog/5159386
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

摘要:本文介绍的基于实例的方法可以很好的缓解细节丢失、人脸风格化失败等问题并得到高质量的风格转换图像。
本文分享自华为云社区《基于实例的风格迁移》,作者:柠檬柚子茶加冰 。
基于神经网络的风格迁移方法虽然生成了令人惊艳的风格转换图,然而目前的大部分方法只能学到一些类似颜色分布,整体结构等,对于局部区域的纹理细节等,并不具备很好的学习能力,在这些细节区域还会带来扭曲和变形。本文介绍的基于实例的方法可以很好的缓解以上问题并得到高质量的风格转换图像。

注:风格指的是图片颜色、纹理的变化等,部分论文认为内容(content)也是一种风格。
前言:
目前的风格迁移几乎大部分都是在GAN(生成对抗网络)的基础上组合AdaIn(适应性实体正则化),加上vgg网络构成的感知损失(contentloss)等来进行优化;还有较为经典的pixel2pixel、cyclegan等利用成对数据或者cycle loss进行图像翻译(ImageTranslation)任务等。基于神经网络的风格迁移方法虽然生成了令人惊艳的风格转换图,然而目前的大部分方法只能学到一些类似颜色分布,整体结构等,对于局部区域的纹理细节等,并不具备很好的学习能力,在这些细节区域还会带来扭曲和变形。尤其最近尝试了许多方法,进行人脸风格化等,包括(u-gat-it, stylegan等)都这些基于神经网络的方法在对一些类似油画、水彩等风格都不具备很好的效果。
下面首先介绍两篇效果较好的基于神经网络的风格迁移方法:其中,U-GAT-IT在二次元人脸上具有较好的效果,whitebox在风景类图片上具有较好的效果。
U-GAT-IT: UNSUPERVISEDGENERATIVE ATTENTIONAL NETWORKS WITH ADAPTIVE LAYERINSTANCE NORMALIZATION FORIMAGE-TO-IMAGE TRANSLATION
u-gat-it适用于形变较大的人脸到二次元风格的Image to Image Translation任务。作者将注意力模块引入到整个框架的生成器和判别器部分,使模型专注于一些语义上重要的区域而忽略一些微小的区域。作者还组合了实体正则化(Instance Normalization)和层正则化(LayerNormalization)提出了自适应层实体正则化(Adaptive layer InstanceNormalization)AdaLIN。AdaLIN公式帮助注意力模块更好的控制形状和纹理的改变。

整个模型结构如图,包括两个生成器G_{s->t}Gs−>t和G_{t->s}Gt−>s和两个判别器D_sDs和D_tDt,以上结构图为G_{s->t}Gs−>t和D_tDt的结构,表示source到target(真实到二次元),G_{t->s}Gt−>s和D_sDs则和它相反。
整个生成器的流程为:不成对的数据输入生成器模块,经过降采样和残差块等提取K个特征图E,辅助分类器用来学习这k个特征的权重W(类似于CAM,利用全局平均池化和全局最大池化得到权重w),最终得到注意力特征图a = w ∗ sa=w∗s。特征图再输入到一个全连接层获取均值和方差,通过论文提出的AdaLIn函数得到最终normalize后的特征图,将此特征图输入解码器后得到转换后的图片。

判别器的话就是通过一个二分类网络来生成特定损失,约束生成的图片和训练数据分布一致。
实际训练中,Ugatit训练速度较慢,虽然会生成部分较好的二次元风格图片,但是这种没有利用人脸关键点等信息的方法会造成部分生成的图片人物形变夸张,达不到工业应用标准。
whitebox: Learning toCartoonize Using White-box Cartoon Representations
适合风格:真实人物 -> 偏真实的目标风格
不适合风格:油画等抽象风格
主要贡献:模拟人类绘画行为的三种表示(the surface representation, thestructure representation, and the texture representation.)来构成相关的损失函数。

网络结构如上,结构较为简单,主要是各种loss:
1.预训练的VGG网络提取高维和低维特征构成structureloss和content loss;
2.surface representation模拟绘画的抽象水彩画等(通过一个滤波器得到);
3.the texture representation则类似于素描风格,通过一个color shift算法生成;
4.structure representation由KMeans聚类得到,得到结构化的色块分布。
总结:该方法可以生成效果很好的宫崎骏等类似的日本动画风格,但是对于人物等风格转换会带来细节的丢失。本文模拟人类画师而提出的多种representation产生的loss等具有很好的参考意义。
基于实例合成的人脸风格迁移
以上介绍的风格迁移方法,其实都可以归为一类,都是使用神经网络通过学习一大批风格类似的数据来学习对应的风格。这种方法在风景类图片或者细节较少的人脸图像上(二次元)等可以取的较好的结果,然而对于具有丰富信息的风格图,这种方法大都只能学习到一些颜色分布等,产生的风格图会丢失大量的局部细节。尤其人脸风格化,仅仅使用注意力(U-GAT-IT)仍然会产生大量的失败风格转换图,虽然有论文(LandmarkAssisted CycleGAN for Cartoon Face Generation)利用人脸关键点约束来达到一个较为稳定的转换效果,但是对于较为复杂的风格图,这些方法仍然有些能力不足。此时,基于实例合成的风格迁移就可以很好的缓解这些问题(细节丢失、人脸风格化失败等)。
Example-Based Synthesis of Stylized Facial Animations
效果对比:
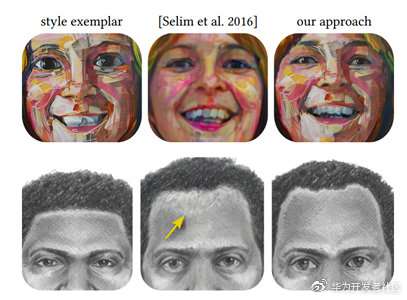
上图中第二列的图片就是一种基于神经网络的风格化方法,包括以上介绍的whitebox方法,都试着平滑最终转换图片的局部纹理,以达到绘画效果。然而结果就是对于具有丰富纹理的风格图,这些方法都差强人意。
本文的方法,通过输入一张富含纹理的人脸风格图S,一段视频帧T,可以得到一段风格化后的人脸视频帧O。

文章的具体方法思想倒是挺简单:通过输入的风格图和关键帧(待转换图),得到一系列引导图(Gseg,Gpos, Gapp, Gtemp),运用Fišer在2016年提出的运用引导图合成数据的算法(StyLit:Illumination-Guided Example-Based Stylization of 3D Renderings)。重点是多种引导图的构建与意义。
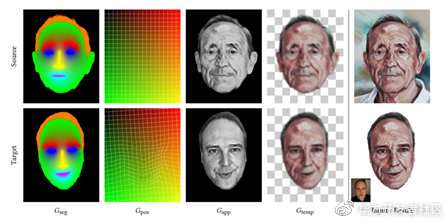
分割图(Gseg):
目的:由于风格图不同区域有不同的笔触,因此将人脸区域划分为眼睛、头发、眉毛、鼻子、嘴等区域。具体得到该图的方法如下图:

简单的解释下上图,为了得到原始人脸a的的三分图b,作者先得到了一个粗糙的头像分割图c,接着使用人脸关键点(下巴关键点),得到一个封闭的掩码e。为了得到皮肤区域f,作者使用了一个皮肤的统计模型来筛选属于皮肤的像素,得到图h。最后,为了得到人脸其它区域的分割图(人眼等),使用人脸关键点,并为了防止关键点不准确,通过模糊相关区域得到最终的图i。
位置指导图(Gpos):
像素坐标归一化到0-1,接着使用原图和目标的人脸关键点,并使用"moving
least squares deformation",最终得到目标图相对原图的坐标点形变图。
外观指导图(Gapp):
转换为灰度图,修改对比度等。
时序指导图(Gtemp):
利用之前研究的手绘的序列在低频区域具有时序一致性,通过模糊风格参考图S和前一帧合成的风格转换图O,得到时序指导图。
合成
得到以上的指导图后,作者使用StyLit方法得到合成后的风格图;另外,人眼和嘴巴区域通过额外的较之前的Gseg更为严格的掩码(d)来合成,如下图:
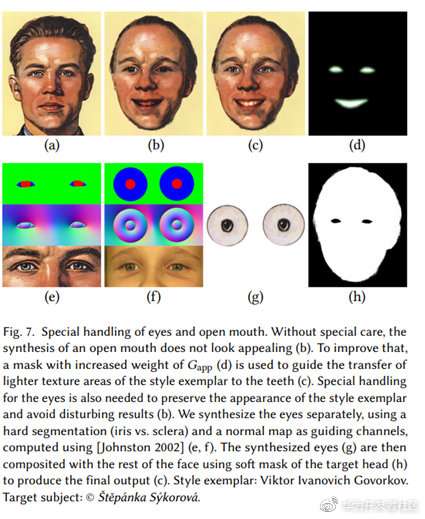
结果展示: 第一行为风格参考图,第二行为转换后的风格图。

Real-Time Patch-Based Stylization of Portraits Using Generative
AdversarialNetwork
以上介绍的方法合成风格图时准备工作太多,需要生成(Gseg, Gpos,Gapp, Gtemp)等四种图,且会存在部分失败的步骤(关键点获取失败、分割失败等)就会导致风格转换失败;然而不可否认,上文介绍的基于实例的合成方法生成的风格图质量极高,本文的作者提出使用GAN来结合这种方法,能生成高质量风格图,且利用GPU来达到较高的推理速度。
方法也及其简单,利用上文的方法生成质量较高的风格化数据,并使用常用的对抗损失、颜色损失(风格图参考图和转换后的风格图之前求L1距离),感知损失(预训练VGG提取风格参考图和转换后的风格图的特征求L2距离);
网络结构方面,作者在以前研究者的基础上增加了残差连接,残差块等,如下图:
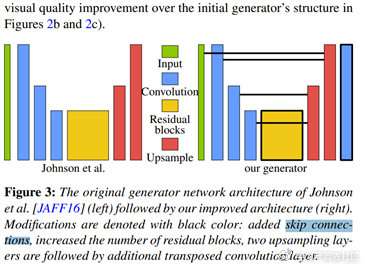
总结:本文整体没有特别出彩的地方,但是给我们提供了一个思路,利用效果较好但是速度较慢的方法生成高质量的大规模训练集,使用以上架构(GAN+常见风格迁移loss等),可以得到效果较好且速度较快的风格迁移方法。
FaceBlit: Instant Real-time Example-based StyleTransfer to Facial Videos
本文同样是一种基于实例的风格迁移方法,作者对比了以上两篇论文,其中以上介绍的第一篇论文Example-BasedSynthesis of Stylized Facial Animations虽然具备非常高的质量,然而这个方法在合成前的准备工作太多,完成一张图片的风格化需要数十秒。第二篇论文Real-TimePatch-Based Stylization of Portraits Using Generative Adversarial Network虽然在gpu上具有较快的速度,然而需要很长的训练与资源消耗。以下为作者与两者的结果对比:
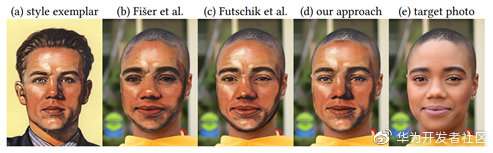
其中,a是风格图,b和c分别是以上的两篇论文的结果,d是原图。
作者首先改进了第一篇论文中使用的指导图,第一篇论文中使用了四种指导图(分割图、外观指导图、位置指导图、时序指导图),本文作者将以上的四种指导图压缩为位置指导图Gpos和外观指导图Gapp两种,并且改变了他们的生成指导图的算法,最终数十毫秒即可生成指导图。
位置指导图(Positional Guide)
首先是获取人脸关键点,对于风格图,使用预训练的算法提前生成即可。对于真实人脸图片,作者通过在输入人脸检测器前降低其分辨率到之前的一半来获得较快速度的检测(对于精度的影响可以忽略)。获取到人脸关键点后,通过将这些坐标信息嵌入RGB三通道,R是关键点x,G是y;然后使用第一篇论文中使用的"moving least-squaresmethod"来计算从原图到风格图的关键点变形;对于最后剩下的一个B通道用来存储分割图,其中风格图的分割图可以预先生成,而原图的掩码则使用以下方法生成:

简单来说,通过将关键点连线和绘制一个椭圆区域,得到一个部分人脸区域,最后通过分析皮肤的颜色分布来扩张这个区域边界,最终得到整个人脸的掩码。
外观指导图(Appearance Guide)
首先将原图转换为灰度图,使用该灰度图减去高斯模糊后的灰度图:

得到以上两幅图后,作者通过以下公式构建了一个表,来记录多个坐标之间的距离。

并将这个表输入到StyleBlit(一种基于实例的快速合成算法,下面介绍)
StyleBlit: Fast Example-Based Stylization with Local Guidance
以上的文章,其实主要都是在构建各种指导图,或者已有算法得到高质量的数据集进行训练,核心的风格迁移生成算法为本文类似的方法。本文介绍的方法是当前最优(根据给出的指导图的不同)、速度最快的基于实例或者叫指导图的风格化合成方法。至于速度有多快,原文中是这样说的:在单核CPU上,我们可以以每秒10帧的速度处理100万像素的图像,而在普通GPU上,我们可以以以每秒100帧的速度处理4K超高清分辨率视屏。
这里只简单阐述论文的思想,后续会详细的从stylit到styleblit介绍。StyleBlit的想法并不复杂,假设我们有两幅图像或者两个风格不同的物体(3d或者2d),算法的核心思想是将原始图像的像素值通过某种映射粘贴到目标图像上((通过类似打补丁的方式)。假设原始图像的像素集合为{p1,p2…pn},目标图像的像素为{q1,q2,…qn},我们有一个额外的表,表的值为{p,q,error},也就是上文介绍的类似如下的关于原始像素和目标像素坐标,且两者之间错误率的表:
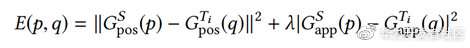
我们的目标是风格化或者渲染目标图像,因此需要遍历目标图像所有像素{q1,q2,…qn},在找到对应的原始图像中最近的像素点后,计算二者的错误率,如果低于某个阈值,那么就将原始像素的颜色等复制到目标图像。
当然还有一些细节,比如作者将像素点分层,通过从顶层到低层这种优先级计算错误率,寻找最合适的原图像素点(红色点为目标图像素点,黑色和蓝色为原图像素点,蓝色为最近的三个层级的像素点):
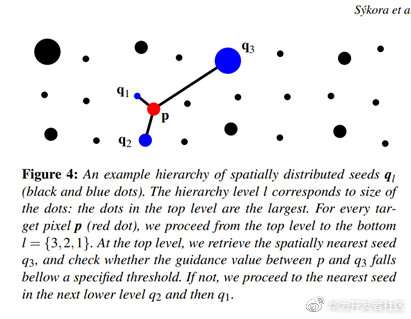
最终算法伪代码如下:

结果展示:风格参考物体为圆球,目标物体为人形建模

结论:只要有合适的引导图,从2d到3d、人脸风格转换等,该方法都可以快速高效的生成高质量的目标图像。从实验结果来看,优于绝大多数基于神经网络的风格迁移。
注:
图像翻译: 有研究者认为图像翻译应该是比风格迁移更为宽泛的一个概念,比如白天黑夜的图像转换,线条图上色、春到冬、马到斑马、2D到3D转换、超分辨率重建、缺失图像修复、风格化等,这些都属于Image to Image Translation任务。总体可以总结为将输入图转换为目标图,输入图和目标图都符合其特定的数据分布。本文主要讲的是最近看的一些风格迁移论文。
AdaIn: AdaIN的思路为,它致力于从一张图片由VGG16输出的特征图中分别提取内容和风格信息,并且将这两个信息分离开来;原始图片经过减去均值和除以方差normalize后可以减去风格,加上风格图提取的均值方差反向normalize可完成风格迁移;
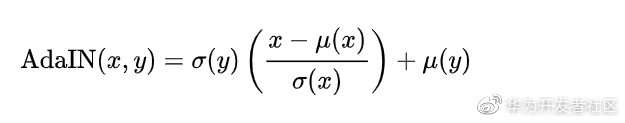
想了解更多的AI技术干货,欢迎上华为云的AI专区,目前有AI编程Python等六大实战营供大家免费学习。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK