

❤️ 爬取抖音小姐姐无水印视频,源码奉上,保姆级教程,赶紧收藏❤️
source link: https://blog.csdn.net/perfect2011/article/details/119248324
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

目录
在群里聊天的时候,突然聊起爬抖音的美女视频,手机下载的视频总是有水印,所以今天的目标就是爬抖音的无水印美女视频。
1、目标网站
https://www.douyin.com/
搜索《 果果不一样》,很漂亮的美女,爱了,爱了。
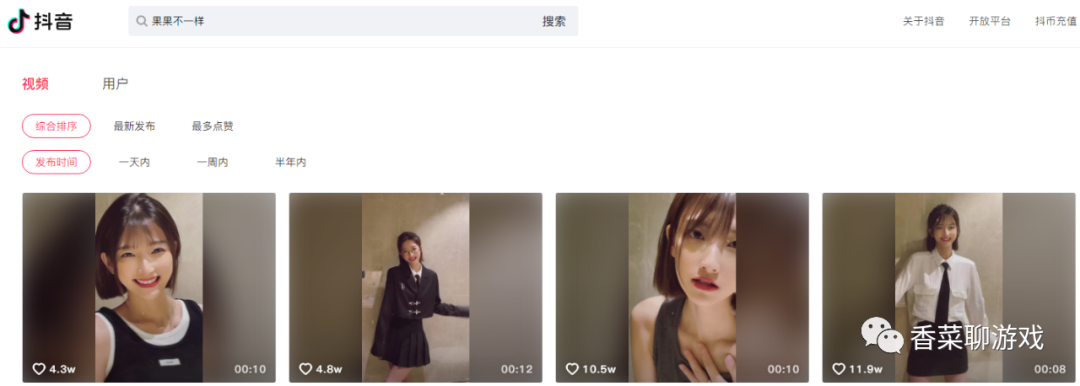
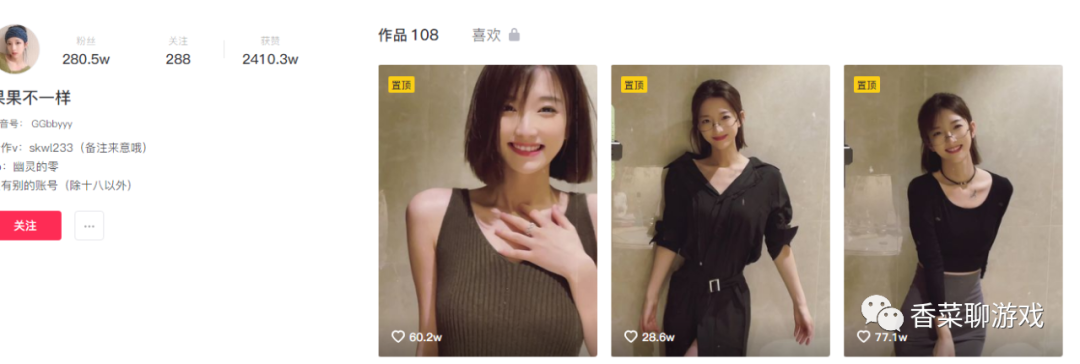
可以看到找到了目标的主页
https://www.douyin.com/user/MS4wLjABAAAAvOU5GclmETa4jehXAEspnMfYJQZAbwcJzfUFhZk4cP8?extra_params=%7B%22search_id%22%3A%22202107292202370102121680920629F001%22%2C%22search_result_id%22%3A%2260142255276%22%2C%22search_keyword%22%3A%22%E6%9E%9C%E6%9E%9C%E4%B8%8D%E4%B8%80%E6%A0%B7%22%2C%22search_type%22%3A%22video%22%7D&enter_method=search_result&enter_from=search_result
看到一长串的url ,有点懵逼,但是仔细看一下,后面的参数似乎是告诉服务器怎么进入到主页的,估计是服务器为了做统计日志用的,
直接去除后面的参数可以得到主页地址:
https://www.douyin.com/user/MS4wLjABAAAAvOU5GclmETa4jehXAEspnMfYJQZAbwcJzfUFhZk4cP8
在浏览器中输入地址验证我们的猜想,没毛病,正是我们想要的
2:技术选型
2.1 方案A
首先我想直接根据链接地址去找到视频的地址,然后直接下载。想法很直接,很暴力。
首先打开视频详情页面,分析视频的地址怎么来的,找到下面的请求,可以看到后面一堆参数,
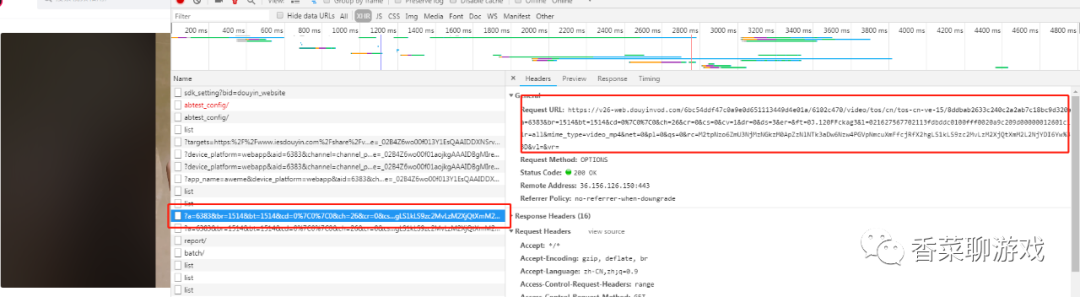
具体的参数如下面:
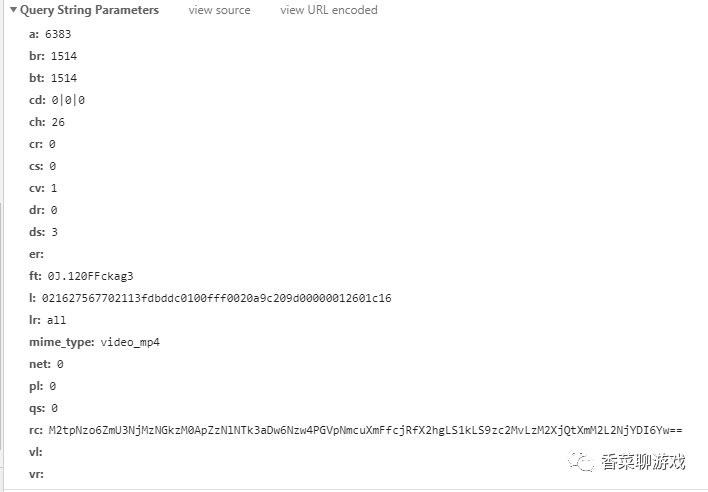
根据我仅有的爬虫知识,我猜这是为了验证用的,不知道什么算法生成的,我也懒得去分析js,一坨乱七八糟的,而且还不知道是哪个,真鸡儿难,同时毕竟也不是我的强项,我的目标是快速解决问题
我的分析中遇到的问题:
1、首先 视频主页需要动态的加载视频,也就是下滑的时候会多加载一些视频,这个可以解决,但是麻烦。
2、寻找视频的url 不知道是哪个请求,一个一个点过去才最终发现上面的url,有点费劲。
3、视频是异步加载的,需要先从主页进到详情页,然后生成上面的url,上面这个url生成我似乎搞不定,即使能搞定也要花费很久的时间
综合上面的问题,我挣扎了一段时间 还是放弃了上面的方案,事情果然没有那么简单,可能是我太菜,这也给我打开了另外一扇窗就是下面的方案B
2.2 方案B
我之前知道有种爬虫技术是selenium ,但是没用过,Selenium测试直接运行在浏览器中,就像真正的用户在操作一样,所以我准备学习一下 selenium ,我的目标是爬取我喜欢的视频,并不是精通这个技术,所以在网上一顿学习,发现还挺简单的,建议测试的同学可以学一下,很好的技术
刚开始学习的时候一脸懵逼,这玩意杂用,没学过啊,有点害怕,想放弃,不过想想还有美女视频,还是鼓起了勇气去学习,最终的结果看来决定是正确的。
3、安装环境
3.1 必要的环境
方案B 是使用selenium ,所以需要安装配套的包python + selenium + chromedriver
3.2 安装 selenium
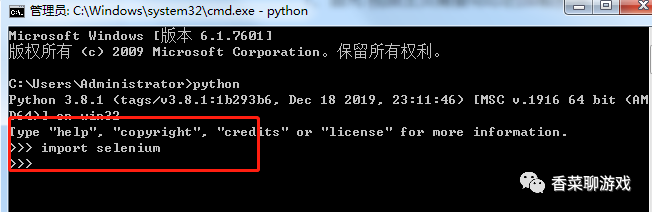
打开控制台 (win +R ,输入cmd 回车,进入控制台),输入下面的命令等待安装完成
pip install selenium
安装完成后,在控制台输入python 回车,进入python的命令行界面
然后输入 import selenium 回车,如果不报错则你已经安装完成
3.3 下载 chromedriver
chromedriver 是chrome的驱动,英文大家应该看得懂的。
注意点:需要确认你chrome的版本下载对应的driver
确认版本步骤:
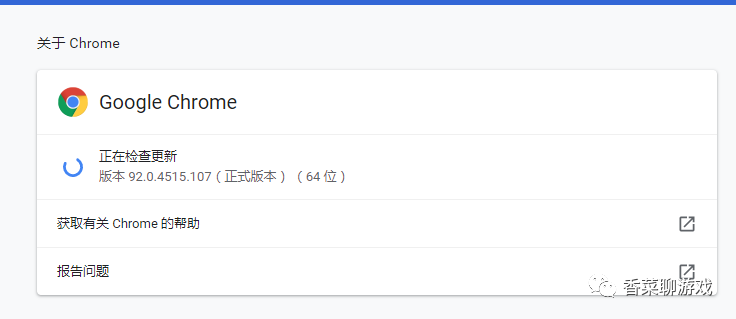
点击三个点 -> 帮助 -> 关于 Google Chrome 打开下面的界面,可以看到我的版本是92
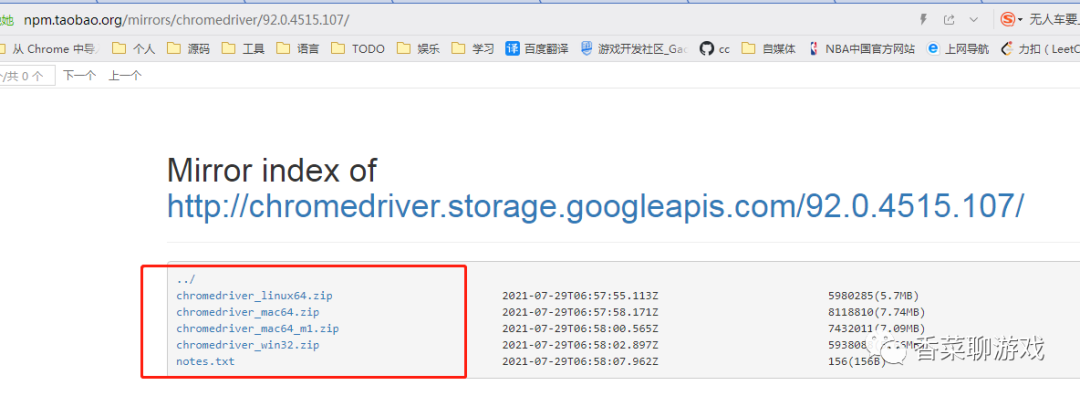
打开下面的网址,选择 对应的版本下载,放到某个地方解压即可,等待备用
下载地址:http://npm.taobao.org/mirrors/chromedriver/
4、代码实现
环境装好了,我们直接撸代码。
经过一段时间对selenium的学习,我大概先撸了一个hello world 的程序练练手,最终明白这就是模拟用户的操作的软件,真的不错,直接代码撸起。
4.1 代码
代码中基本上都加了注释,我先即使不会python的人也能看懂流程。
4.2 一些点:
1、❤️ 句柄:所谓的句柄可以理解为对象指针,或者对象的引用,总之就是代表一个对象就完了,不用考虑太多
2、❤️ 主页的滚动:经过百度得到如下的代码 window.scrollBy(0,100) 就是下拉到100像素的位置,我大概根据页面的元素定位一个视频的像素是311,所以在代码里每三个滚动的距离是311像素,我没有考虑间隔的问题,可以优化下。
3、❤️ 下滑滚动会导致下载相同的视频,因为获取到了相同元素,所以我增加了visitSet
4、❤️ 页面的关闭:在开始的时候,我打开的子页面没有关闭,会打开非常多的网页,导致电脑内存不足,程序崩了
5、❤️ 在python的当前目录需要先创建video 文件夹,要不然下载的时候会报错
6、❤️ xpath:就是为了定位标签位置,代码中看的很复杂,不要害怕,那也不是我写的,因为我也不会,下面的获取方式
在页面直接F12 打开调试界面,然后选择想要查看的元素,右键就会出现下面的菜单,直接copy XPath,贴到代码里就行了
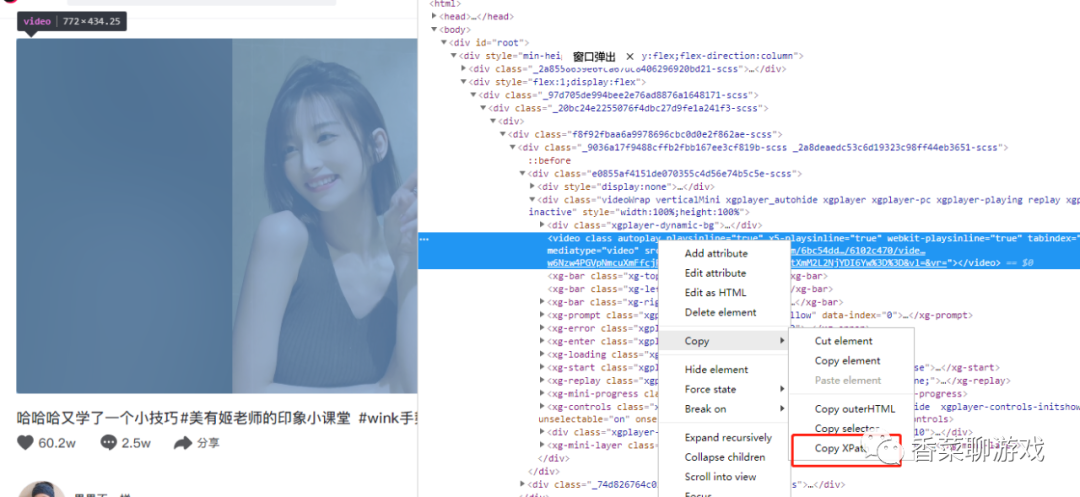
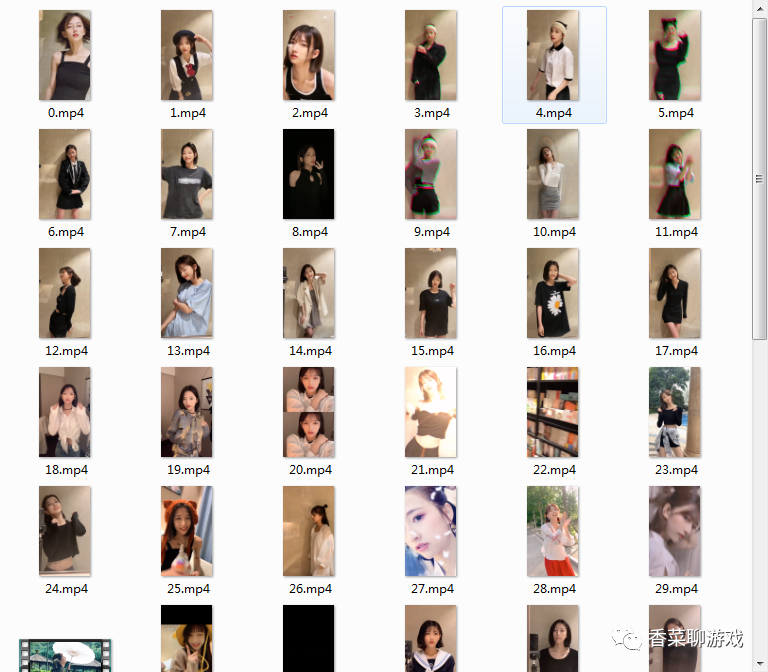
4.3 成果
下载了很多视频,可以慢慢看了,技术改变生活啊
看下运行时的画面:
在程序的控制下自动打开页面并且下载对应的视频
5、未解决的问题
☀1、滚动问题,我没有更精确的控制滚动,还有种方式就是直接在开始的时候一直滚到底,然后一次获取所有元素下载,简单暴力
☀2、验证码问题,在开始的时候总是需要手动对齐图形,所以我让程序sleep 了10秒,这种防爬虫的方式还没研究不知道怎么破解,不过不影响爬取、待研究
☀3、提供一个搜索的池子,直接从搜索主页进行出发爬取多个小姐姐的视频,不得了了,全世界的小姐姐都是你的了
在这次爬取的过程中遇到了不少的问题,虽然最后都解决了,也总结一些经验。
⚡1、遇到问题不要怕,先试试,万一行呐
⚡2、不要放弃,想想其他的方式是不是能同样解决问题,所以有了方案B
⚡3、解决问题优先,技术不会的可以以后补充,多写代码就会熟悉
⚡4、知识迁移很重要,平常多接触,在你遇到新的东西能快速上手
这次爬虫的代码大概花费了2个多小时,主要是前期的探索花了不少的时间,这篇文章花了我接近2个小时,总共花费了两个晚上的时间。唉,还是写代码简单些,希望能动动小手帮我点个赞,支持一下,谢谢各位大佬。

赶紧点赞!!!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK