

那些必须要掌握的Hive数据倾斜与调优手段 - InfoQ 写作平台
source link: https://xie.infoq.cn/article/bcc86619af965c408abc10819
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

一、什么是数据倾斜?
由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点。
二、Hadoop 框架的特性
A、不怕数据大,怕数据倾斜
B、Jobs 数比较多的作业运行效率相对比较低,如子查询比较多
C、 sum、count、max、min 等聚集函数,通常不会有数据倾斜问题
三、主要表现
任务进度长时间维持在 99%或者 100%的附近,查看任务监控页面,发现只有少量 reduce 子任务未完成,因为其处理的数据量和其他的 reduce 差异过大。 单一 reduce 处理的记录数和平均记录数相差太大,通常达到好几倍之多,最长时间远大 于平均时长。
四、容易数据倾斜情况
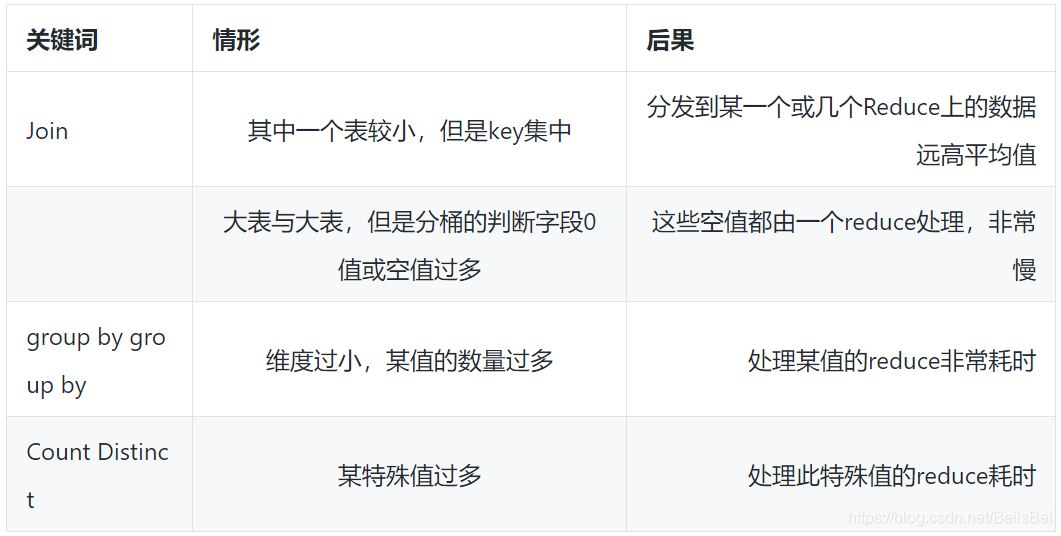
A、group by 不和聚集函数搭配使用的时候
B、count(distinct),在数据量大的情况下,容易数据倾斜,因为 count(distinct)是按 group by 字段分组,按 distinct 字段排序
C、小表关联超大表 join
五 、产生数据倾斜的原因
A:key 分布不均匀
B:业务数据本身的特性
C:建表考虑不周全
D:某些 HQL 语句本身就存在数据倾斜
六、业务场景
1、空值产生的数据倾斜
(1)场景说明
在日志中,常会有信息丢失的问题,比如日志中的 user_id,如果取其中的 user_id 和用户表中的 user_id 相关联,就会碰到数据倾斜的问题。
(2)解决方案
解决方案 1:user_id 为空的不参与关联
select * from log a join user b on a.user_id is not null and a.user_id = b.user_idunion allselect * from log c where c.user_id is null;
解决方案 2:赋予空值新的 key 值
select * from log a left outer join user b oncase when a.user_id is null then concat('hive',rand()) else a.user_id end = b.user_id
(3)总结
方法 2 比方法 1 效率更好,不但 IO 少了,而且作业数也少了,方案 1 中,log 表 读了两次,jobs 肯定是 2,而方案 2 是 1。这个优化适合无效 id(比如-99,’’,null)产 生的数据倾斜,<font color=#FF0000>把空值的 key 变成一个字符串加上一个随机数,就能把造成数据倾斜的 数据分到不同的 reduce 上解决数据倾斜的问题。
改变之处:使本身为 null 的所有记录不会拥挤在同一个 reduceTask 了,会由于有替代的 随机字符串值,而分散到了多个 reduceTask 中了,由于 null 值关联不上,处理后并不影响最终结果。
2、不同数据类型关联产生数据倾斜
(1)场景说明
用户表中 user_id 字段为 int,log 表中 user_id 为既有 string 也有 int 的类型, 当按照两个表的 user_id 进行 join 操作的时候,默认的 hash 操作会按照 int 类型的 id 进 行分配,这样就会导致所有的 string 类型的 id 就被分到同一个 reducer 当中。
(2)解决方案
把数字类型 id 转换成 string 类型的 id
select * from user a left outer join log b on b.user_id = cast(a.user_id as string)3、大小表关联查询产生数据倾斜
注意:使用 map join 解决小表关联大表造成的数据倾斜问题。这个方法使用的频率很高。
<font color=#FF0000>map join 概念:将其中做连接的小表(全量数据)分发到所有 MapTask 端进行 Join,从而避免了 ReduceTask,前提要求是内存足以装下该全量数据。
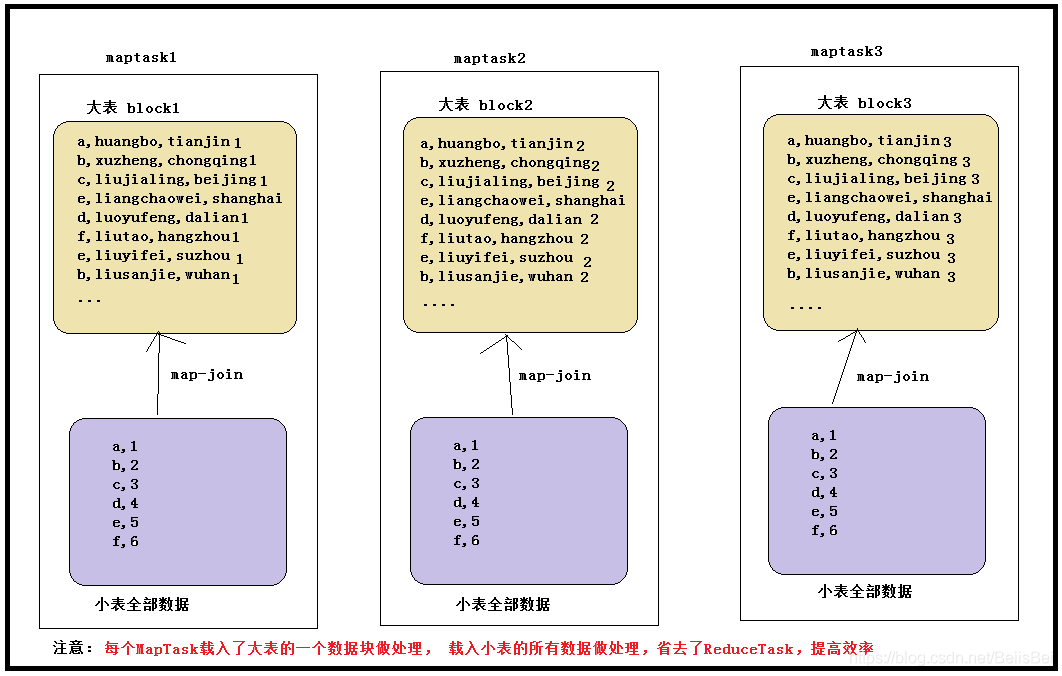
以大表 a 和小表 b 为例,所有的 maptask 节点都装载小表 b 的所有数据,然后大表 a 的 一个数据块数据比如说是 a1 去跟 b 全量数据做链接,就省去了 reduce 做汇总的过程。 所以相对来说,在内存允许的条件下使用 map join 比直接使用 MapReduce 效率还高些, 当然这只限于做 join 查询的时候。
在 hive 中,直接提供了能够在 HQL 语句指定该次查询使用 map join,map join 的用法是 在查询/子查询的 SELECT 关键字后面添加/*+ MAPJOIN(tablelist) */提示优化器转化为 map join(早期的 Hive 版本的优化器是不能自动优化 map join 的)。其中 tablelist 可以是一个 表,或以逗号连接的表的列表。tablelist 中的表将会读入内存,通常应该是将小表写在 这里。
MapJoin 具体用法:
select /* +mapjoin(a) */ a.id aid, name, age from a join b on a.id = b.id;select /* +mapjoin(movies) */ a.title, b.rating from movies a join ratings b on a.movieid =b.movieid;
在 hive0.11 版本以后会自动开启 map join 优化,由两个参数控制:
set hive.auto.convert.join=true; //设置 MapJoin 优化自动开启set hive.mapjoin.smalltable.filesize=25000000 //设置小表不超过多大时开启 mapjoin 优化
如果是大大表关联呢?那就大事化小,小事化了。<font color=#FF0000>把大表切分成小表,然后分别 map join。
那么如果小表不大不小,那该如何处理呢???
使用 map join 解决小表(记录数少)关联大表的数据倾斜问题,这个方法使用的频率非常高,但如果小表很大,大到 map join 会出现 bug 或异常,这时就需要特别的处理
举一例:日志表和用户表做链接
select * from log a left outer join users b on a.user_id = b.user_id;users 表有 600w+的记录,把 users 分发到所有的 map 上也是个不小的开销,而且 map join 不支持这么大的小表。如果用普通的 join,又会碰到数据倾斜的问题。
改进方案:
select /*+mapjoin(x)*/* from log aleft outer join (select /*+mapjoin(c)*/ d.*from ( select distinct user_id from log ) c join users d on c.user_id = d.user_id) xon a.user_id = x.user_id;
假如,log 里 user_id 有上百万个,这就又回到原来 map join 问题。所幸,每日的会员 uv 不会太多,有交易的会员不会太多,有点击的会员不会太多,有佣金的会员不会太多等等。所以这个方法能解决很多场景下的数据倾斜问题。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK