

博弈论+机器学习=?
source link: https://www.huxiu.com/article/441441.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

博弈论+机器学习=?
本文来自微信公众号:一席(ID:yixiclub),作者:方飞,头图来自:视觉中国
除了我们今天提到的这些项目以外,研究者还在尝试用人工智能解决更多社会性的问题。比如我们组也在研究如何提升交通出行的效率,学校里有同事在尝试优化肾脏匹配的流程,优化交通信号控制来减轻城市堵塞。在斯坦福那边,有的研究者利用卫星图象来估计和预测贫困水平和农作物的产量,还有多个大学都有在做一些帮助年轻流浪者的项目。
博弈论+机器学习=?
(2021.06.19 重庆)
大家好,我是方飞,是卡内基梅隆大学计算机学院的助理教授。很遗憾今天因为疫情的原因不能来到现场,所以通过视频的方式来和大家分享。
提起计算机科学,我们想到的可能是一些算法,或者是在某些游戏中有出色表现的智能程序。但其实这些进展现在已经可以被用来解决现实生活中一些更实际的问题了。我的研究重点就是如何开发和利用人工智能算法,去分析和解决一些社会性的挑战,去做一些对社会有利的好事。
比如公共安全问题是人类当前面临的一个比较大的挑战,机场、地铁站、轮渡等交通枢纽更是特别容易被犯罪分子盯上,一个主要原因就是它们的人流量比较大,所以一般政府也会派更多巡逻人员在附近进行戒备。我们可以做些什么吗?
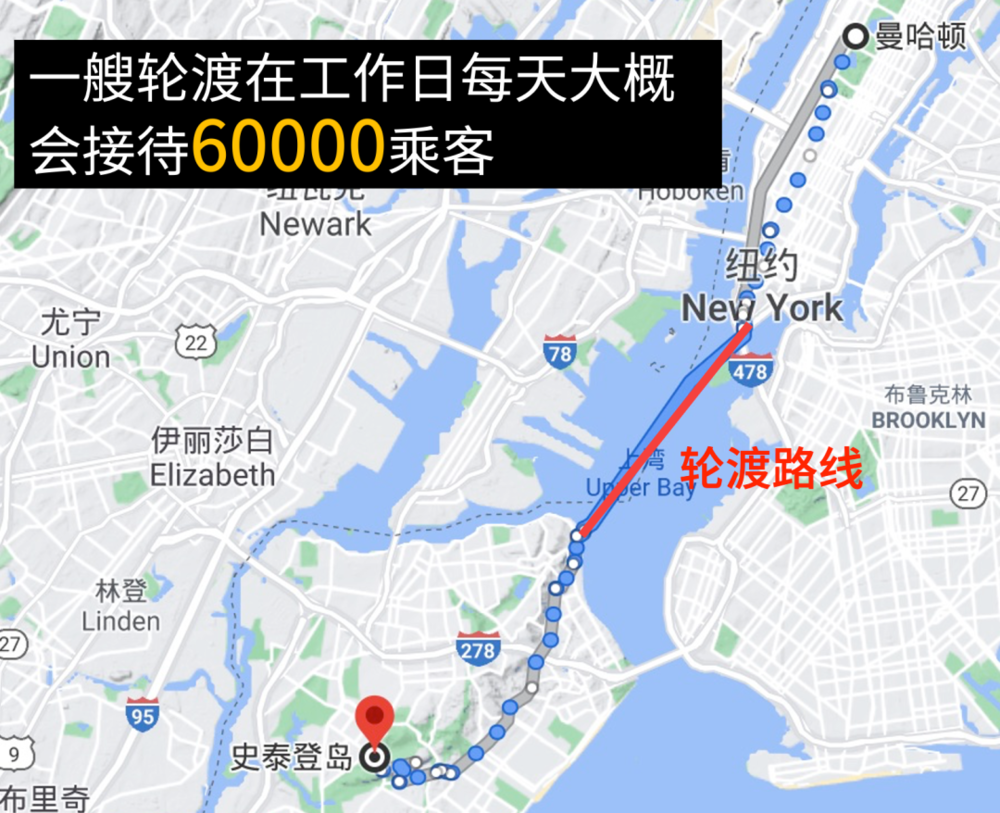
不知道大家有没有人去过纽约,在纽约有一个非常著名的轮渡,叫斯坦顿岛轮渡,它连接了曼哈顿和斯坦顿岛。

这个轮渡是免费的,如果你是观光客的话,可以在这个轮渡上欣赏自由女神像,是一个很适合拍照的地方。
纽约也有很多上班族为了避免曼哈顿那边高昂的生活成本,会选择住在斯坦顿岛,然后坐这个轮渡去上班,所以在工作日的时候这个轮渡每天能接待好几万名乘客,人流量很大。
和机场、地铁站一样,以前也曾经发生过对大型船只的攻击事件,比如2000年美国科尔号驱逐舰遭到了袭击,2002年法国的超级轮渡林堡号上发生了爆炸。
在这些袭击事件当中,会有一些攻击者驾驶着装满了爆炸物的小船,撞向这些目标船只,然后导致这样的爆炸。

因为接待的人流量比较大,斯坦顿岛轮渡也就成为了美国海防比较重点保护的目标。
虽然它到目前为止还没有遇到过这样的危险,但出于安全考虑,美国海防希望能够通过加强巡逻的方式,给斯坦顿岛轮渡提供更好的安全保障。
首先,他们给轮渡配备了这样的巡逻船只,巡逻船上有机枪,可以阻止一定距离内船只的靠近。

但问题在于,同时段可能有多个轮渡在运行,但它的巡逻船可能只有一到两艘。
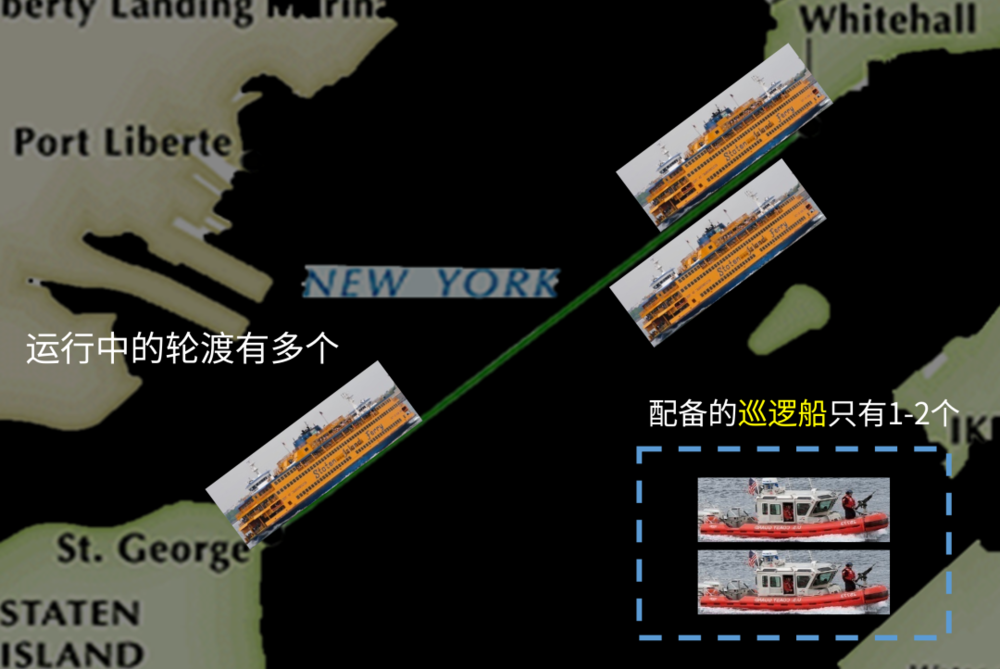
所以之前美国海防一般会采取的方式是,他们会选取其中一艘轮渡,然后把仅有的一到两艘巡逻船都派到这个轮渡的边上去保护它,一路跟随着这个轮渡从一个码头走到另外一个码头。

但巡逻船们自始至终只跟着一艘轮渡走,导致的问题就是,其他的轮渡在大多数的时候都是没有被保护的。
而且在实际中,不同的轮渡在不同时间点的重要性可能是不一样的,比如说早高峰的时候,从斯坦顿岛到曼哈顿这个方向上的轮渡人会比较多。所以如果你是纯粹随机找一艘船只保护它的话,对于整体来说并不是一个特别好的保护方案。
于是我们需要解决的问题就是,如何在不增加巡逻船数量和巡逻时间的情况下,能够更高效地安排巡逻船的巡逻方案,使得整个轮渡系统的安全得到最大程度的保护。
其实在这之前,同样是加强交通枢纽的保护,我的博士导师Milind Tambe曾经用博弈论的方法,优化了机场附近的检测点设置以及机场大厅的巡逻方案,被应用到了洛杉矶国际机场的保护当中。

我也是被他这个项目吸引,加入了他的团队,然后参与到这个轮渡保护的工作中来。受到机场项目的启发,我们也尝试用博弈论的方法来解决这个轮渡问题。
那么,什么是博弈论呢?实际上博弈论是经济学和应用数学的一个分支,专门研究在有合作和竞争的多人博弈中决策者的一些行为和策略,在大众的印象中可能更多的是被用在经济学中。
比如在小企业的经营中,一个精明的经理人,可以选择等着一些大的企业去开发市场,然后自己在适当的时候去搭便车,从而节省一些成本。
这种现象在经济生活中比较常见,它可以被看成是这个小企业和大企业之间的博弈。那么什么时候小企业搭便车最划算呢?博弈论的分析就可以帮助解答这样的问题。
到现在为止其实有好多位博弈论的研究者获得了诺贝尔经济学奖,最著名的可能是约翰·纳什,他提出了纳什均衡,对博弈中的均衡分析有着贡献,他也是电影《美丽心灵》男主角的原型。

回到轮渡的问题,我们在分析的时候就意识到这本质上也是一个博弈问题,它是制定巡逻策略的防御者以及制定攻击策略的攻击者之间的一个博弈。

当巡逻方案改变的时候,攻击方案可能也会改变,而最后攻击是否能成功,就是取决于双方选取的策略。
美国海防平时需要给每一艘巡逻船选取巡逻路线,它有很多的路线可以选择,比如说最简单的让巡逻船从一个码头走到另外一个码头。

或者它可以走到中间然后再走回来。
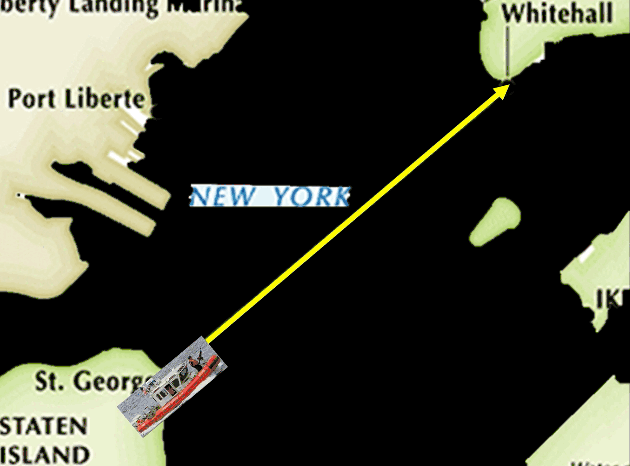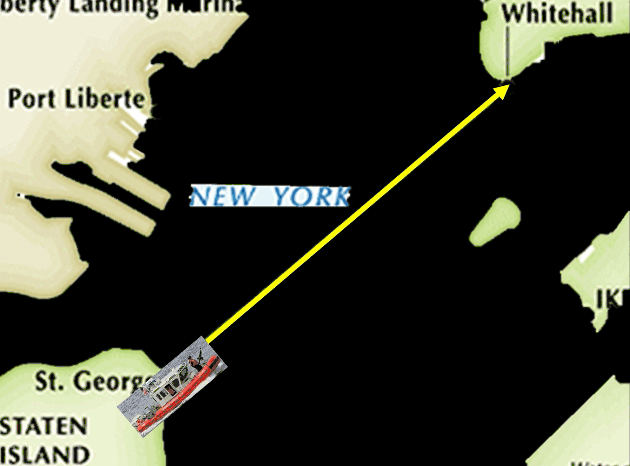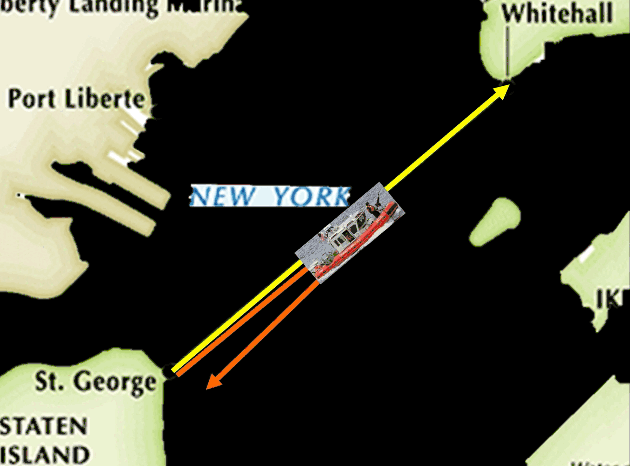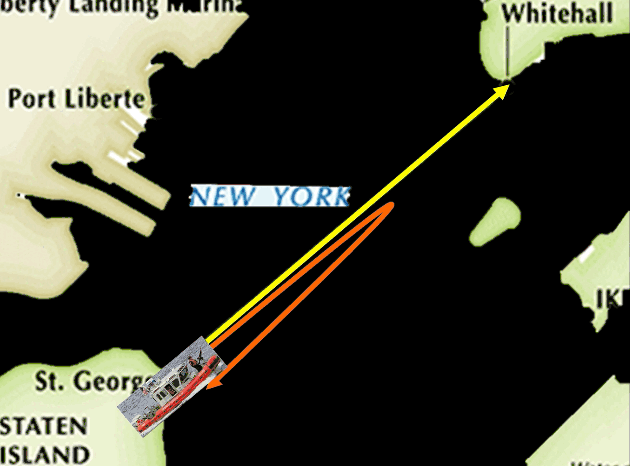
或者它也可以采取更复杂的来回走这样一个路线。
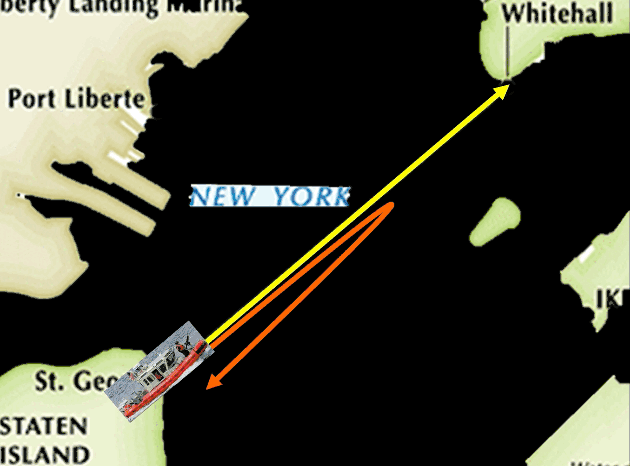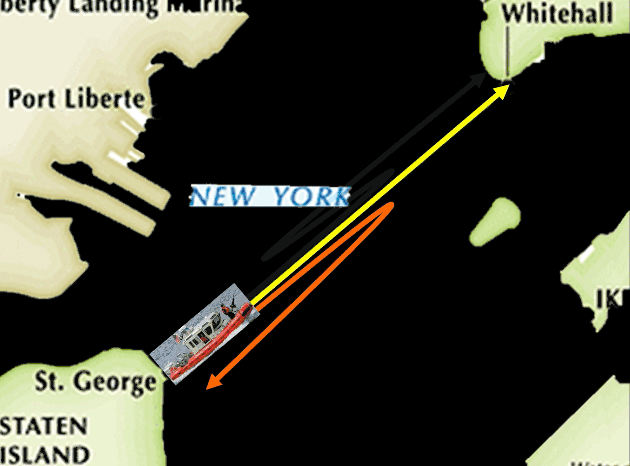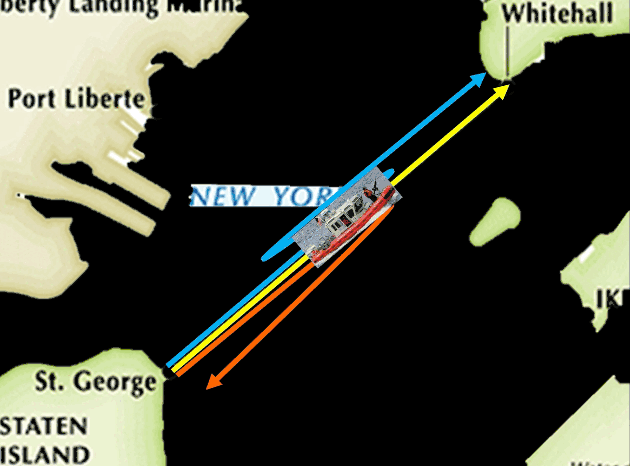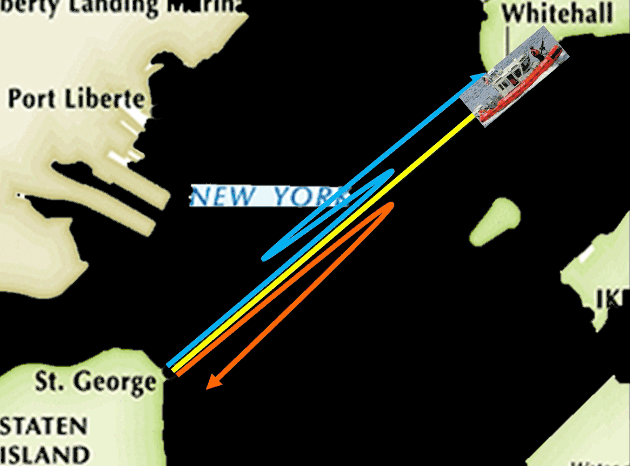
当然还有很多很多可能的路线。但是我们可以想象,如果巡逻船每天都用固定路线巡逻的话,这个巡逻方式非常容易被攻击者利用——他们很容易找到漏洞。
因为攻击者一下子就知道早上十点钟的时候巡逻船总是在这个地方,我只要去攻击在其他地方的轮渡就可以了。
这种情况下,防御者可能没有办法阻止攻击者攻击,那么攻击者就容易赢,他可以获得一个收益,我们假设为五,与此同时防御者就会得到一个负五的收益。
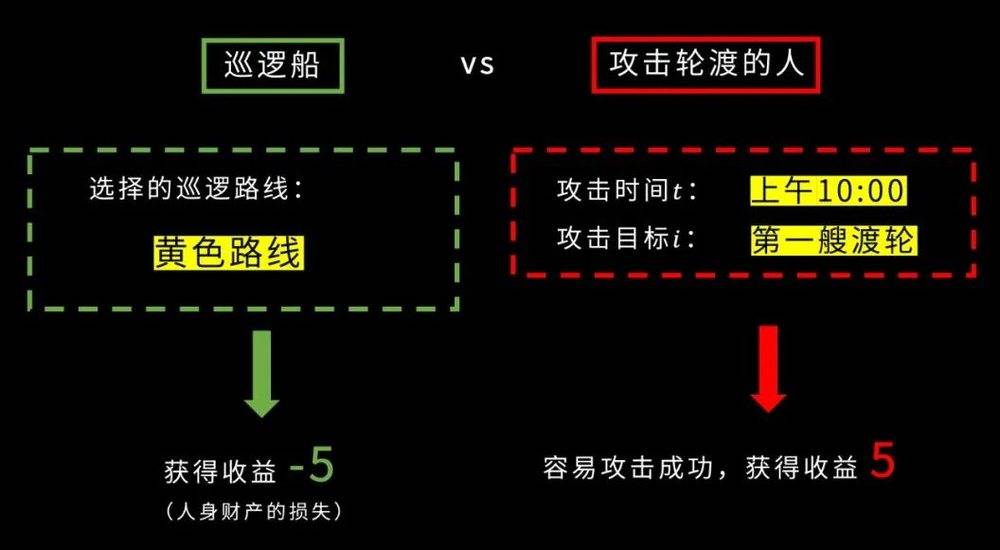
所以这样有确定性的巡逻方案是不合适的。
在真正的应用中,收益是由美国海防那边进行评估并且制定的,一般来说这个数字与攻击是否能够成功,以及成功以后会造成的人身和财产的损失成正比。
在这里我们可以看到,我们假设攻击者获得的收益,和巡逻船作为防御者获得的收益正好是互为负数的,加起来是零。我们把这种问题认为是博弈论中一类比较特殊的博弈,叫做零和博弈。
这种博弈是一个严格竞争的环境,一方的收益就是另一方的损失,我损失多少你就收益多少,要么我赢,要么你赢,没有双赢的可能。我们的收益或者损失的总和总是零,没有合作的可能。
一个比较常见的零和博弈就是石头剪刀布这个游戏,在这样简单的博弈当中,一个均衡策略就是,参与这个游戏的双方都以三分之一的概率,来出剪刀、石头、布这三个选项。
在我们这个比石头剪刀布更加复杂的零和博弈里面,要如何去计算均衡策略呢?我们希望能够找到一个巡逻策略,使得攻击者的预期收益是最小的。
这个巡逻策略必须是有随机性的。比如一艘巡逻船在10点的时候有可能出现在很多地方,它可能在曼哈顿码头那一边,也可能在斯坦顿岛码头这一边。
然后它可能会沿着不同的路线行驶,我们需要通过计算来找到它具体行驶的路线,以及走每条路线对应的概率。
那么怎样才能找到这个最好的概率值呢?具体来说,我们可以把轮渡行驶的这条路线离散化,然后去列举巡逻船所有可能的巡逻路线,再去列举攻击者可能选取的所有攻击目标和攻击时间,去求解这样一个优化问题。

在这个优化问题中,防御者想要的是最小化攻击者的预期收益,而攻击者想要的是最大化这个数值,最后我们通过线性规划求解得到,巡逻船走每条可能的巡逻路线的概率。

按照这个概率,我们得到了一个新的巡逻方案。在这个新的巡逻方案下,巡逻船不再只走固定的路线,也不会被要求从头到尾只跟着一艘轮渡了,而是可以在半途变换队形去保护其他的轮渡,而且当某一艘轮渡的重要性增加的时候,它被保护的概率也会增加。
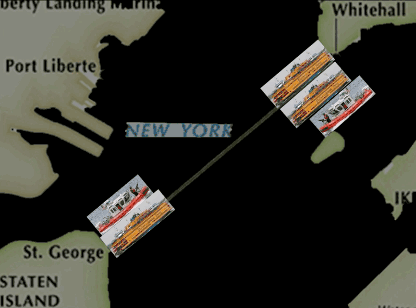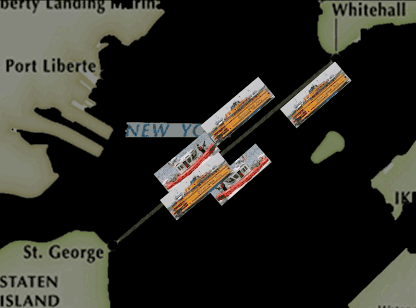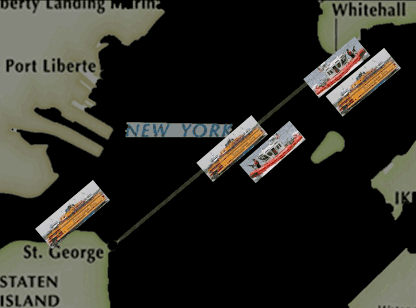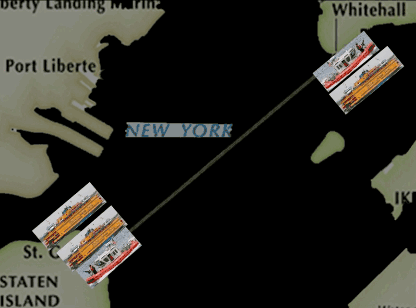
由于我们算出来的这个巡逻路线有随机性,所以这个动画中显示的只是一个可能的路线样本,实际上它每天采取的路线都是会变化的。
我们这个巡逻方案从2013年开始就被美国海防在实际中使用了,你可能会好奇,最后的方案到巡逻员手上是什么样子的?其实我们给他们的只是代码,他们自己会去制定收益,然后跑出巡逻路线。
每天早上美国海防会将当天的巡逻路线交给船员,告诉他们比如今天你前十分钟跟着这艘船走,十分钟以后拐弯去跟着另外一艘船走,然后加速等等。这是一个他们在运行过程中拍摄的视频。
您目前设备暂不支持播放
在这个视频当中我们可以看到巡逻船在这里做了一个转弯。

在之前,这样的转弯都不曾出现在他们可能的方案中。所以可以说是我们这个基于计算博弈论的巡逻方案,给他们带来了一个很大的巡逻方式的改变。
他们跟我们提到说,感觉新的巡逻方案和以前的巡逻方案对比,好像是在篮球场上从一个点对点的防御,变成了一个区域性防守。
还有一些经常在这片海域工作的人,也跟美国海防那边反馈说,感觉最近一段时间防御增强了!

而实际上巡逻船的数量以及巡逻的时间都是没有变化的。这就是我们用计算博弈论来应对安全问题的一个例子。
在我们做完轮渡项目后,就去各个地方演讲介绍我们的工作。其中有一次是在世界银行,当时听演讲的一个观众比较了解野生动物保护工作,然后就和我们提到说,你们的这个工作好像跟护林员在保护区里面进行巡逻有一点类似。
我们意识到,或许我们的工作可以应用到更广泛的领域当中。因此我们开始和一些动物保护组织的人接触,看看我们的工作能否帮到他们。
从他们那里我们了解到,世界上有很多地方有盗猎的现象。盗猎者会放置一些陷阱、猎套,等着动物上钩,然后去卖掉动物的肉,或者是更有价值的,比如象牙、犀牛角这一类的动物制品来获利。

▲ 一些猎套和陷阱
往往这样的盗猎行为会非常严重地影响比如大象、老虎、犀牛这些物种,而这些物种的损失可能会进一步影响整个生态系统,所以反盗猎的工作非常重要。
在保护区里面,一般会有护林员巡逻,去清理这些猎套。但是护林员比较少,而猎套又很便宜,也容易制作,到处都可以放,所以盗猎现象还是很严重,我们就想要帮助他们制定一些更好的巡逻策略。
在决定做这个项目之后,我们也跟多个动物保护组织的人聊过,在和WCS野生动物保护协会聊的时候,他们就说乌干达那边有一些国家公园有比较完整的数据,可以跟我们合作。于是,我们就选取了乌干达伊丽莎白国家公园作为第一个研究地点。

一开始,我们想直接套用保护轮渡的那一套解决方案,因为感觉这两个问题都是防御者对攻击者的问题,只是在反盗猎中,攻击者变成了这些盗猎者。
但是很快我们就意识到,这两个问题其实有本质的不同。在保护轮渡的问题里面,很幸运的是,我们考虑的这种攻击还没有真正发生过,因为这样的一次攻击成本巨大,一旦成功它的影响也巨大。
所以攻击者会花大量的时间和精力去了解巡逻方案,并且去设计一个最佳的攻击策略。他会提前定好今天的哪个时间攻击哪艘船,不会根据观察到的海上的信息临时改变他的攻击策略。
用博弈论的术语来说,在这个问题中,我们可以假设他们是完全理性的。而且这是最极端也是最差的情况,如果他们不完全理性,最后的结果只会对我们更好。
但是在反盗猎的这个问题当中,制作猎套的成本大概就十块钱人民币,盗猎者们并不需要花那么多时间和精力去进行计算在哪一个点放猎套预期收益最大,他们会非常频繁地在各种地方下猎套,想放哪里就放哪里。所以盗猎者的行为模式也就更加地复杂,我们不能假设他们是完全理性的。
当我们想要阻止盗猎行为时,我们首先要能够预估他们的行为模型。这就是为什么在这个问题里面,我们需要引进机器学习,从实际的数据当中去学习和预测盗猎者的行为模型。
乌干达当地给我们提供了大概12年的巡逻数据,从中我们可以提取一些特征,比如说护林员往年在不同地方花费的巡逻时间。

然后我们还分析了当地的一些地理相关的信息,提取了一些可能会影响盗猎者行为的特征,比如说不同地点的海拔,动物的密度分布,还有跟村庄的距离等等,因为这些特征也会影响盗猎者的行为。
比如如果一个地方离村庄太近的话,它的野生动物可能就比较少,如果距离太远的话,对于盗猎者来说,他跑到那个地方去需要花的时间和精力就太大了,所以到村庄的距离是一个很容易会影响盗猎者决策的因素。
除此之外,我们还会对以往的数据进行标注,看看每一个网格点上是否有存在过猎套,或者是有过盗猎行为。
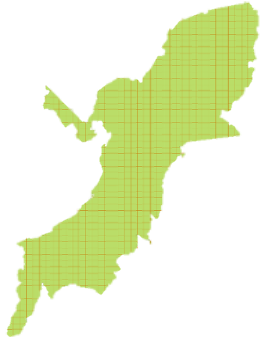
▲ 将地图分成1km*1km的网格
这里我们就遇到了一个困难,因为我们发现绝大多数的数据点上是没有找到猎套的,只有在非常少的数据点上被标记了一些盗猎的行为——这些数据量是不足以支撑一个很复杂的模型的。

▲ 红色点代表发现过盗猎行为
并且我们的数据来源是护林员巡护当中发现的一些东西,标注上其实有一些主观的不确定性。
如果他们发现了一些猎套,那么我们可以很肯定地说这个地方有盗猎行为。但如果他们没有在某个地方发现猎套,这难道就意味着那个地方真的不存在盗猎行为吗?并不是的。
所以这也给我们的机器学习工作带来一些困难。为了应对这些数据性的挑战,我们把整个公园分成了几个区域块,然后根据每个区域拥有的数据量的大小,采用不同的机器学习模型,对它们的盗猎风险进行预测。
最后,得到了一个盗猎风险的热度图,这个热度图上更红的地方就代表着我们预测的盗猎风险更高。

▲ 为保护当地数据信息,上图仅为结果示意图,并非真实的预测结果。
当我们把这个预测结果与他们以往的巡逻路线去作对比的时候,就发现有一些我们预测出来的中高风险的盗猎区域,在以前是很少被巡逻到的。那么这些预测到底准不准呢?
我们和当地的护林员合作,请他们去做了一个月的实地测试。在这一个月当中,当地的巡护人员去了这两个方框所在的地方。
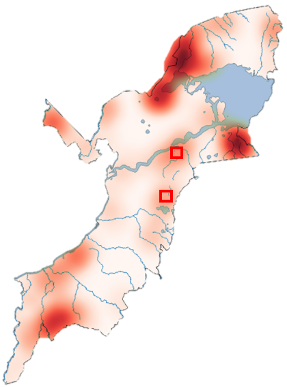
这两个地方都是我们预测出来有盗猎风险,但是在以往的巡逻中很少涉足的地方,请他们去看看在这里是否会找到一些猎套。
于是在这一个月中,他们发现了19次人类活动的痕迹,还发现了已经被猎杀的大象,以及多个已经生效的,或者是还没有被部署好的羚羊猎套和大象猎套。
您目前设备暂不支持播放
我们从这个视频当中也可以看到,其实找猎套并不是一件特别容易的事情,如果你没有经验的话,很可能你走过那个地方,但却什么都找不到。
值得一提的是,如果我们把这一个月的数据跟以往的数据进行对比,可以看到它超过了91%的历史月份,而且找到猎套的次数远远高于平均历史数据。

因此我们就考虑说,或许可以做一个更长期的实地测试,于是当地护林人员又进行了一次八个月的实地测试。
在这次测试当中,护林人员巡逻了超过450公里。他们选取了27个区域,其中有5个被预测出来的高风险区域,22个被预测出的低风险区域。

在这个过程中他们发现,被预测为高风险的区域里面,每公里找到的猎套数量是十倍于低风险区域的。
所以可以说用我们的模型能够比较好的预测出高风险区域和低风险区域,可以作为给当地巡护人员的重要参考。
在这之后我又通过邮件联系了世界自然基金会(WWF)在中国东北的办公室,然后发现盗猎问题在我们中国东北这一块也是比较严重的。
因为东北这边的地理信息数据没有乌干达那边那么充足,所以这一次我们从卫星图片上提取了一些地理信息。
并通过向护林员发放问卷的方式收集了一些额外信息,来弥补当地地理信息数据不足这一难题。之后结合多个机器学习模型,得到了这样一个盗猎风险的预测结果。
2017年时,我正好有机会回国,所以这一次我去东北和我们的合作者一起参与了实地测试。

当时我们走了两天,第一天的时候什么都没有发现,第二天开始的时候,依然没有发现什么东西。合作者当时和我说,方博士,你这个算法好像不太行呀,预测出来的结果可能并不是你想得那么好。
但是过了20分钟以后,我们到了一个地方,在这个地方我们找到了20多个猎套,数量比他们平时能找到的猎套数量要多很多。

▲ 方飞及团队在东北进行了两次实地测验。2017年10月的实地测验找到了22个猎套,2019年12月的实地测验找到了42个猎套。
除了找猎套以外,我们也尝试着像类似之前给轮渡设计巡逻船路线的方式,给护林员们也规划了一些巡逻路线。
比如2015年,我们曾经给马来西亚那边的一个保护区提交了一组巡护方案,但是他们的反馈却是——这个巡护方案完全没有办法用。
我们一开始也不是特别能够理解为什么,于是他们就邀请我们去马来西亚进行实地考察。去了那边之后发现,确实是没有办法按照我们的路线走——因为那个地方的地形实在是太复杂了。
我们当天在保护区里面走了大概8个小时,这之中你可以看到有时候要上山,有的时候要沿着河在水里面走,我当时整个裤子都湿掉了,走起来真是挺麻烦的。

所以在我们提交的模型下,告诉他们从这个网格点走到隔壁的网格点,在实际当中很可能是非常非常难走的。
于是我们就根据这个地势的实际复杂情况,修正了巡逻路线的设计,在这个区域中找到了一些比较好走的能够直行的巡逻路线。

在这样的修正之后,巡护人员的确可以更好地按照巡逻路线执行了,而且他们在这个巡护过程中又找到了数量可观的人类活动和动物活动的痕迹。

再一次说明这种基于人工智能的巡护方案设计是有价值的,是可以给当地的巡护人员提供参考的。
整体来讲,我们这个项目叫做PAWS(Protection Assistant for Wildlife Security)。它首先是通过机器学习给这个地方的盗猎人员进行行为的建模,然后再基于博弈论去进行路线的规划,再进一步考虑当地复杂的地形进行具体的路线设计。

当我们把这个路线推荐给巡逻人员以后,巡逻人员可以进一步收集盗猎的数据,然后把这些新的数据返回来去优化我们的模型。
除了前面的工作以外,我们在防止盗猎的整个链条上还有很多值得去做的事情。比如我们可以想一下盗猎者为什么会盗猎?因为他们可以获得很多利润,即使被抓住受到的惩罚也不是很大,那我们是不是可以想办法从源头上去阻止盗猎?
此外,我们可不可以去发动当地的居民一起帮忙解决盗猎?但是当居民给巡逻人员提供线索时,我们需要怎么样去分辨和合理利用他们的线索呢?关于这些问题,我们也都在进行研究。
在轮渡保护、反盗猎这两个问题中,其实都是一个防御者和攻击者的模型,但在很多其他的领域中,我们往往会遇到比这个更加复杂的多人交互的情形。这时我们也可以不局限于计算博弈论,而可以考虑用多智能体系统和机器学习相结合来解决更多的问题。
平台分配送餐员
一个具体的例子就是食品营救问题。匹兹堡这边有一个食物救助平台,叫412 Food Rescue,它的目标就是帮助解决食品浪费和食品短缺的问题。

当一些超市和饭馆有不能出售,但是还可以食用的食物时,比如说超市里面还有几天就要过期的食物,他们就会联系这个平台,然后食物救助平台会联系当地的一些可能需要食物的群体,比如说一些低收入的单亲妈妈的救助站,把这些食物送到她们手上。那么谁来完成运送食物的工作呢?
这个平台主要是依赖志愿者。但是这里就面临了一个问题,这些志愿者并不是他们签下来的员工,他们是完全自发的行动。所以作为平台来说,它并不能确定每一个任务是否会被志愿者领取。
想要进一步提高营救任务的完成率,减少食物浪费,平台需要采取一些通知和干预的机制。
他们之前采用的一个通知机制是,当任务发布后,它会先通过APP通知五英里以内的志愿者。

如果等待15分钟以后,这个任务还没有被领取的话,他们就会再一次去通知所有的志愿者。
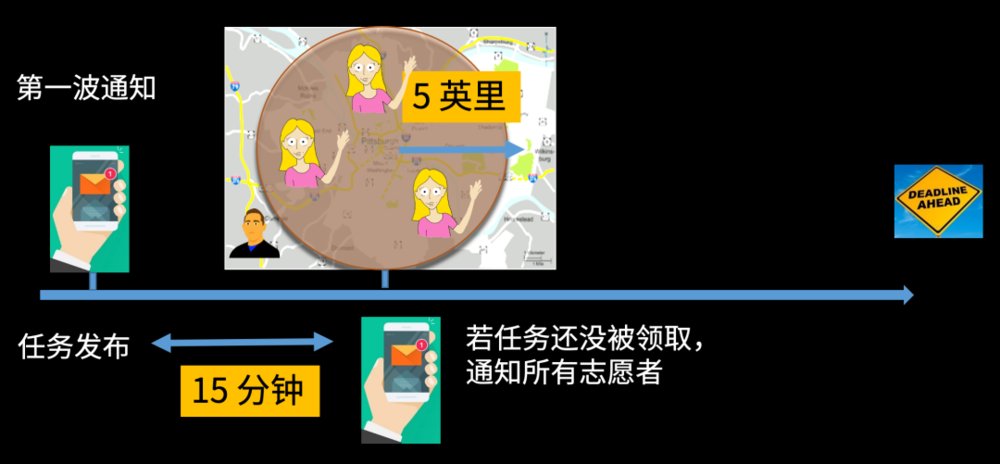
如果领取食物的截止时间前60分钟食物还没有被领取的话,他们就会通过一些人工干预,比如说发短信甚至打电话给他们比较熟悉的一些志愿者,去请他们帮忙。

但是这个机制的问题在于,如果你需要很多的人工干预,他们是没有那么多人力的,如果你一直通过APP去推送通知的话,通知推送过多可能会适得其反,导致志愿者对整个志愿工作都失去兴趣。那么我们能做些什么,来帮助他们提高整个系统的运行效率呢?
我们的第一个想法是,帮助他们预测每一个任务的领取状态——就是当一个任务发布的时候,利用时间、天气、位置等相关特征,去预测这个任务会不会被志愿者领取。
这样一来,我们就可以把那些比较需要人工关注的任务,早些摆到工作人员的眼前,节省他们一些时间。
第二个想法是,我们想要帮助他们优化整个通知和干预的机制,比如说等待的时间和发送通知的距离,都可以做一些调整。于是我们把这个想法转化成了一个优化的问题。

目标就变成了,找到三个最合适的值,使得总的通知次数以及人工干预的次数都最小化。
最后解出的一个比较好的结果是:平台第一波去通知5.5英里以内的志愿者,然后等待16.5分钟;没有人的话再去通知第二波,如果距离最晚领取食物的时间只剩45分钟的时候还没有人领取的话,就进行人工干预。
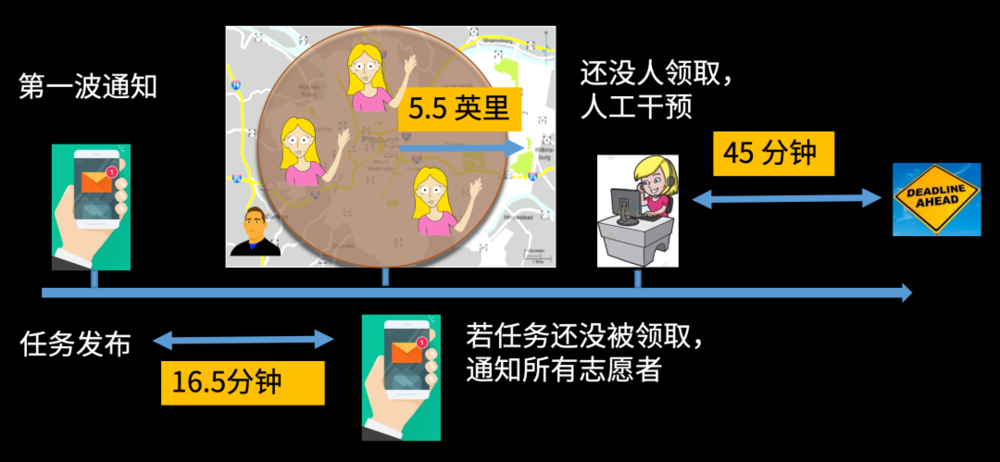
这个是我们在实验室里面的一个测试,而从2020年1月份开始,412 Food Rescue开始在实际中也采用了我们这个方案。
计算机解决不了的现实问题
所以总结来说,我们的研究目标就是希望能够利用人工智能来帮助人们解决一些社会性的挑战。
虽然说人工智能近些年有了很大的发展,可以帮助我们做很多的事情,但是在我们的研究中,也发现了一些很重要的非技术性的挑战。
在很多研究项目当中,我们需要跟不同领域的专家进行合作。比如说在反盗猎的这个项目中,我们要和动物保护组织的人合作;在应对食物短缺的问题里面,我们要和食品研究平台的专家合作。
在这样的合作当中,我们作为人工智能方向的研究者,平时习惯性的思维就是:我要给这个问题建模,然后把它转换成一个优化问题去解决。
但是往往我们一开始觉得的这个问题中需要优化的点,和这个领域的专家眼中最需要优化的点是不一样的。所以在最开始的沟通当中,经常会有一些交流上的困难,往往专家提出来的痛点,在我们看来都是计算机没有办法解决的问题。
比如说在反盗猎的项目当中,动物保护组织的人就跟我们说,他们希望解决的一个问题是,怎么给巡护人员提供更好的物质和设备上的保障,能让他们更投入地去进行巡护工作?
这个问题就很难用数学和计算机的模型去解决。这也是为什么我们需要跟这些专家不断地讨论,深入地沟通,甚至参与到他们的日常工作当中,就是为了去找到哪些问题是在这个领域中很重要,并且也可以通过人工智能来解决的。
除此以外,在我们的合作过程中还有一些语言交流方面的问题,比如如果我和护林员说:“我们要通过神经网络学习一个盗猎者的模型。”如果他们没有相关知识的话,可能就很难理解我想表达什么。
所以我们需要用最基础的语言去传递信息,并且在设计算法的时候,需要考虑最后结果的可解释性。比如我们使用机器学习模型的话,往往一开始会考虑用决策树模型,因为它最后出来的结果是比较好解释的。
一旦合作的人能够理解你的解决办法,能够理解最后的这个模型,他就更容易去接受,去尝试实地测试,并且在这个过程中,他们会对人工智能建立一定的信任,在这个信任的基础之上,我们就可以去尝试再给他们用一些更复杂的模型。
除了我们今天提到的这些项目以外,人工智能的研究者们还在尝试着用人工智能解决更多社会性的问题,比如我们组也在研究如何提升交通出行的效率,我在学校的同事们有人在尝试优化肾脏匹配的流程。
优化交通信号控制来减轻城市堵塞。
在斯坦福那边,有的研究者利用卫星图象来估计和预测贫困水平和农作物的产量。

还有多个大学都有在做一些帮助年轻流浪者的项目。

我也希望能够吸引更多的人参与到“AI向善”这个活动当中,希望有更多的研究者和技术人员能够关注这一块的问题,能够把人工智能的发展应用到解决社会问题上。
本文来自微信公众号:一席(ID:yixiclub),作者:方飞
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK