

Sweave:打造一个可重复的统计研究流程
source link: https://cosx.org/2010/11/reproducible-research-in-statistics/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

警告:本文提到的工具在更新中,请暂时不要按本文的配置去做,静候 LyX 2.0.3 的发布。
我们都痛恨统计造假。我们都对重复性的工作感到厌倦。如果你同意这两句话或这两句话适用于你的现状,那么本文将介绍一套开源、免费的工具来克服这两个问题。当然,前提是你愿意改变,这里的工具可以让这两种现象没有藏身之地,但无法改变造假和重复劳动的现实。以下为吊胃口视频(墙外观众可以看 Vimeo;墙内看不到视频的可以任选一个链接下载本视频的 AVI 文件:链接 1、链接 2、链接 3):
1. 统计研究流程
“收集、整理、分析和表述数据” 是从流程上对统计学的定义,大部分统计研究都会全部或部分包括这四个步骤。其中,收集和整理数据有相当大部分的体力活(抽样设计除外),分析数据基本上是脑力活(当然也有人把它做成了体力活,Excel 可能是个代表),表述数据则是二者兼有。统计造假无非有两种:一种是捏造数据,另一种是捏造结果。前者很难从工具的角度解决,它是个道德问题,但如果数据源是大家都可以公开获得的,那么这个造假也可以从工具角度消除;后者则是我们更容易控制的,比如对于刊物的审稿编辑来说,他可以要求作者提供数据分析的详细过程,用以检验整个分析是否可以在自己手中被重复生成(reproduce)。
整个统计分析的流程如果能一遍成功,那么我们可能是太幸运了,更多情况是,我们要一遍又一遍重复劳动,因为这个流程中出差错或变故的可能性太多了。例如,发现数据源中有错误数据,或是过了一段时间又有新数据增加进来,或是分析的目标变量改变了,或是变量变换的计算公式变了,等等。通常我们面对变化的解决方案就是从头再来:更新数据,重新计算,重新复制,重新粘贴结果,重新调整报告格式…… 这一系列过程之所以变得不可自动重复进行,本质原因是我们把本应该流程化的操作分解成了不可替代的手工劳动。什么样的手工劳动是不可替代的?最常见的可能就是复制粘贴和点菜单。例如从 Excel 表中复制一部分数据,粘贴到统计软件中,点菜单 “统计分析–> 回归–>选入因变量自变量–>输出结果–>复制回归系数–>粘贴到 Word 中并调整格式”。据我所知,目前计算机还没有发展到能智能记忆这些手工操作过程、过一段时间之后再自动 “回放” 的地步。计算机能 “记忆” 和执行的只有代码。
2. 可重复的统计研究
所谓可重复的(reproducible)统计研究,就是一个研究结果既可以在作者手中生成出来,也可以 “移植” 到他人的平台中用同样的工具重复生成出来,就像物理或化学或生物实验一样,需要每一位实验者在相同条件下都能观察到实验结果。如果一个回归系数仅仅在作者的结果中显著,而在他人手中无法重现,那么这就是不可重复的统计分析。这里 “无法重现” 的原因有很多,包括:数据不可获得、软件不可获得、分析代码不可获得或分析过程缺乏详细说明。如果用 “读者可重复” 的标准来要求统计论文或报告,当今(尤其国内)恐怕能发表的统计分析可能就不会剩下太多了,因为提供数据和分析过程似乎偏离了论文的主题。(题外话:在统计之都主站发表的文章中,凡是涉及到数据和分析的,都一律提供详细过程,保证可重复性,这一点对于 “珍惜版面” 的纸质刊物来说可能不太现实)
当然,有些统计研究不可重复是可以理解的,典型的如数据需要保密。但期望 “透明” 总是人类本性,即使我们不把它考虑为一个道德问题,也应该从自身工作便利角度考虑一下这个问题。
经过这一大段云里雾里的介绍,我将要推荐的是用代码工作,并且尽量在代码中减少 “硬编码” 部分,即:让代码具有广泛适用性,而不要仅仅对一个特定大小的数据的特定变量做特定处理。即使使用“硬编码”,也要考虑将来维护的便利性,例如只需要改一下文件名,重新跑一遍程序,所有的流程可以不变就可以一步重新生成最终的报告。这可能吗?当然。Sweave 就是一种工具。
3. Sweave 介绍
首先声明,用代码工作并不适合所有人和所有情况,尽管磨刀不误砍柴工,但这把刀并不好磨。如果我们希望统计分析的流程能畅通无阻,那么这个过程中我们使用的工具必须能相互 “沟通”。从统计软件中复制粘贴结果到 Word 中这样的做法很难重复,是因为 Word 很难自动从统计软件中获取结果,换句话说,它们太难相互沟通。软件之间沟通的最便利途径就是大家都能基于源代码工作,或基于纯文本工作,因为即使回到石器时代,计算机总是能处理纯文本文件的。Sweave 生存的重要原因就是,LaTeX(一流的排版工具)和 R 语言都基于源代码工作。下面简单介绍一些什么是 Sweave。
从形式上来看,Sweave 也没太多新奇之处:它无非就是将 LaTeX 文档和 R 代码混合起来,先调用 R 执行一遍这个文档中有特定标记的代码,并输出相应的结果到这个文档中(源代码都被相应的计算结果代替),然后再调用 LaTeX 编译文档为 PDF。了解动态网页的人可能觉得这完全是动态网页的概念——输出是动态的,而非写死的结果。举个例子,Sweave 文档看起来是这样的:
\documentclass{article}
\title{A Test Sweave Document}
\author{Yihui Xie}
\usepackage{Sweave}
\SweaveOpts{pdf=TRUE, eps=FALSE}
\begin{document}
\maketitle
We can take a look at some random numbers from N(0, 1):
<<test1>>=
x = rnorm(5)
x
@
The 3rd number is \Sexpr{x[3]}.
Draw a plot for the iris data:
<<test2, fig=TRUE, results=hide>>=
plot(iris[, 1:2])
@
\end{document}
表面看来这就是一篇 LaTeX 文档,只不过其中插入了一些用<<>>=标记开头、用@结尾的 R 代码段(PHP 程序员可以想象<?php ?>)。R 自带一个Sweave()函数,可以用来预处理这些代码段以及其中的\Sexpr{}宏。我们可以将以上代码保存为一个.Rnw文件如myfile.Rnw,然后在 R 中Sweave('myfile.Rnw'),这样myfile.Rnw就被替换为myfile.tex(即 LaTeX 文档),而其中的内容则被替换为了相应的输出:
\documentclass{article}
\title{A Test Sweave Document}
\author{Yihui Xie}
\usepackage{Sweave}
\begin{document}
\maketitle
We can take a look at some random numbers from N(0, 1):
\begin{Schunk}
\begin{Sinput}
> x = rnorm(5)
> x
\end{Sinput}
\begin{Soutput}
[1] 0.74541470 -1.49287775 -1.66834084 0.08252667 0.92772016
\end{Soutput}
\end{Schunk}
The 3rd number is -1.6683408359077.
Draw a plot for the iris data:
\begin{Schunk}
\begin{Sinput}
> plot(iris[, 1:2])
\end{Sinput}
\end{Schunk}
\includegraphics{myfile-test2}
\end{document}
从这个极端简化的例子来看,我们完全不必复制粘贴结果,比如我们生成了一个变量x,从中提取第三个数字x[3]输出在正文中,而不必写死-1.668;图形也一样,它可以根据数据动态生成,而不必先画好一幅图再插入文档中。最后我们运行pdflatex编译这份文档,就得到了最终的报告(本例 PDF 下载)。
为什么 Sweave 是一个具有 “可重复” 性质的工具?原因就是代码控制了流程。比如我们可以用代码读取数据,进行变量转换,建模,输出我们需要的部分(而不是甭管有用没用、一气儿输出三十页统计报告)。代码的灵活性是无限的,它也忠实记录了统计分析的详细过程,所以我们不可能捏造结果,另外也能大大减轻手工重复劳动。
4. 懒人的工具
既然 Sweave 是基于 LaTeX 的,那么先说 LaTeX:我用了几年 LaTeX,对它是又爱又恨。它在排版上当然是超一流的工具,输出的 PDF 文档整洁利索、结构分明,一看就是科学范儿,但我实在痛恨敲 LaTeX 命令。传说中的 LaTeX 介绍都说它能让你专注于写作而不必担心格式,可对我来说这是不太可能的,确实 LaTeX 可以自动安排格式,而且调整起来也方便,但我一直觉得写 LaTeX 文档很不直观,我对章节分布很难形成概念,光是\section{}这种命令,让人很难有章节标题的感觉;还有图表,完全不形象,看着\includegraphics{}根本不知道这里插的是哪幅图。所以从某种程度上来说,LaTeX 本身是很考验人的记忆力的,你要记住哪个标签是什么意思,现在在写哪一节,等等。直到后来用上了 LyX,这些 “不满” 才一扫而光。LyX 是一个看起来“所见即所得”(WYSIWYG)的工具,但实际上是“所见即所想”(What You See Is What You Mean),换句话说,它是披着 Word 外衣的 LaTeX,尽管内部运行方式和 Word 截然不同。如果你熟悉 LaTeX,那么打开 LyX 的菜单你将几乎处处发现 LaTeX 的踪迹。LyX 对 LaTeX 用户可以说是体贴细致入微:我们不必担心特殊字符问题(都会被替换为\引导的字符或等价的命令),不必担心图片的格式(会自动转换),不必担心忘记引用某个需要的 LaTeX 宏包(比如插入图片时会自动在导言区加上\usepackage{graphicx}),写列表的时候不必反复敲\item命令(写完一个,回车就会自动生成下一个),当文档含有目录时会自动调用两次或三次pdflatex来编译目录,数学公式可以直接用眼睛看到,…… 易用性不亚于 Word(前提是你懂 LaTeX),排版质量高出 Word 百倍。这就是个 “不给马儿吃草又要让马儿跑得快” 的懒人工具。
幸运的是这个懒人工具在设计时竟然也考虑了 “文学编程”(literate programming,这翻译有点奇怪),因此也就为 Sweave 嵌入 LyX 留下了铺垫。先岔开话题回到第 3 节:Sweave 的这种编程方式就是文学编程的一种实现,而文学编程如其字面意思所指,是将程序融入文学作品中(这里文学泛指普通文本),这些程序运行之后将输出结果到文字中。与文学编程相对应的便是常见的结构化编程,也就是我们经常看见的大篇纯程序代码。文学编程的提出者为 Donald Knuth——也就是 TeX 的作者。
LyX 给文学编程留下的后路基本上在一个叫literate-scrap.inc的文件中(安装目录的Resources/layouts/或者用户目录的layouts文件夹下),它定义了文学编程文档的输出类型(literate),而另外在 LyX 的选项文件preferences中,我们又可以定义从literate到 LaTeX 的转换器,也就是 Sweave() 函数或等价的 Sweave 处理方式——将 Rnw 文件用 R 运行得到 tex 文件。比如我们可以这样定义:
\converter "literate" "pdflatex" "R -e Sweave($$i)" ""
这里面的血腥细节我就不详细介绍了,后面我会给出普通用户可以接受的配置方式。总之这里大意就是:literate类型的 LyX 文档可以输出为 Sweave 文档,通过 R 执行转化之后可以生成 tex 文档,LyX 此时再进来调用pdflatex编译生成报告。这就是 Sweave 在 LyX 中的执行过程。在外面看来,也就是本文开头的视频中所展示的过程。
5. 自动配置工具
配置这一套工具对于初学者来说显得有些困难,因为这里面的新概念和高级概念太多了。比如可能大多数 Windows 用户一辈子都不会遇到一个叫 “PATH 环境变量” 的东西,还有 LaTeX 宏包的安装过程,以及大量的命令行工作细节(例如命令行重定向),等等。即使抛开配置不谈,光是 LaTeX 和 R 的学习也够折腾好一阵子了。抱着 “苦不苦想想红军两万五” 的信念,这里的三个月学习时间也许能替代十年的重复劳动(也许,只是也许,不要轻易相信我的广告)。
如果你已经装好了 LyX(及其配套 LaTeX 程序如 MikTeX、TeXLive 或 MacTeX 和 R(版本 >= 2.12.0),整个配置过程只需要在 R 中执行一句话:
source('http://gitorious.org/yihui/lyx-sweave/blobs/raw/master/lyx-sweave-config.R')
R 会自动处理那些血腥细节:下载文件并解压缩、复制到正确的文件夹,安装需要的 LaTeX 宏包和更新 LaTeX 的文件名数据库、重新配置 LyX、设定环境变量 PATH(放入 R 的 bin 路径)。这段代码适用于 Windows、Ubuntu(理论上其它 Linux 发行版也不会有问题)和 Mac OS。
大部分血腥细节的解释参见:How to Start Using (pgf)Sweave in LyX in One MinuteSweave in LyX in One Minute”)
这里需要说明的是,我倾向于用 pgfSweave 包,它是对 Sweave 的一个扩展,R 自身的 Sweave 尽管已经很强大了,但我对它有几点不满(非偏执狂请略过):
- 它对代码的自动整理功能:大多数人都痛恨阅读源代码,尤其是乱糟糟的源代码(没有空格没有缩进),或者是没有注释的源代码,为了不要折磨读者,我们应该保持代码的整洁,而另一方面我们也不希望折磨写代码的人,因此我们需要一个自动整理代码的工具。R 自身的 Sweave 中有一个 keep.source 选项,若为 TRUE,则完整保留用户输入的代码并原样输出,这在很多情况下都很糟糕;若为 FALSE,则会自动整理代码,但代价是除掉注释,这也很糟糕。这件事长期以来无法找到平衡点:既自动整理代码,又保留注释。最终这个问题被邱怡轩以一个小技巧部分解决了,但这种技巧并不 “优雅”,所以指望 R core 收录是无望了,最终我把这段代码提供给 pgfSweave 包的作者被收录在这个包中(嘿嘿,俺们草根有力量),所以 pgfSweave 有自动整理代码的功能,并且可以保留注释;注意 pgfSweave 包默认是不整理代码的,必须在全局选项中设置 tidy 为 TRUE 才行,即插入 LaTeX 命令:
\SweaveOpts{tidy=TRUE},然后在最开头的 R 代码段中使用options(keep.blank.line = FALSE),这样能得到最好的输出。 - 图形格式和大小设定:Sweave 默认会生成 PDF 和 postscript 格式的图片(分别可用 pdf = TRUE/FALSE 和 eps = TRUE/FALSE 控制),通常矢量图当然比位图强百倍,美观、无损缩放,但 R 图形有个小问题(纯属挑剔)就是字体,默认情况下图形都是用无衬线字体(Windows 底下如 Arial 字体),这和 LaTeX 文档的字体可能不一致(尽管这个不一致可以在一定程度上减轻,而 pgfSweave 直接从根本上解决了这个问题,因为它是以 tikz 格式记录 R 图形,这种格式实际上就是 LaTeX 代码,因此编译文档的时候图形也会被重新编译,所以图中的文本的字体和正文就完全一致了(例);另外,默认 Sweave 中图形大小的控制方式也很不直观,选项 width 和 height 是控制图形设备的宽和高的,而非实际 LaTeX 文档中图形的宽高,我们只能通过 LaTeX 命令
\setkeys{Gin}{width=?}来设定(尽管这个也有办法绕过去),而 pgfSweave 则默认采取了直观的指定宽高方式,即:直接在选项中指定。 - Sweave 本身没有缓存功能,这对于大批量的计算来说是个灾难:所谓缓存就是计算结果被缓存在某个位置,下次运行 Sweave 文档的时候如果代码没有修改,这些结果则可以不必被重新计算一遍,直接从缓存里读出来就可以了,这是 cacheSweave 包的功能; pgfSweave 在这个基础上更进一步,让图形也有缓存功能了。缓存可以让整篇文档在 R 层面上的编译速度加快(但事实上由于 pgfSweave 用 tikz 图形而这种图形需要 LaTeX 编译,所以整体速度未必真的加快了);
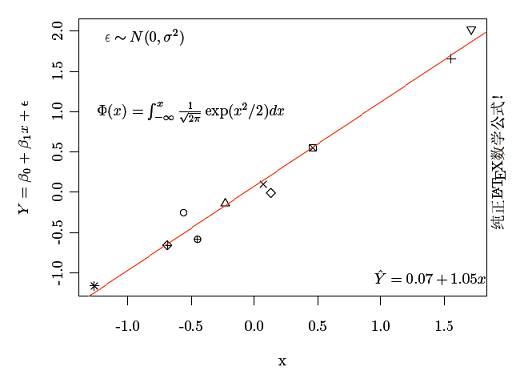
LyX 和 pgfSweave 包生成的图形
6. 演示和问题
如果工具都准备齐全了,那么可以下载两个演示文件了解一下 LyX/pgfSweave 的效果(demo 1;或 demo 2^ 和相应的 BibTeX 文献库 [编者注:这三个链接现在已经失效,抱歉。]),其中一个例子简单,一个复杂。简单例子就像前面视频中显示的一样,只是感觉一下基本功能;复杂例子实际上是我自己的一次作业,略作改编:它演示了从 URL 读入数据,并进行一些极大似然估计、似然比检验和基于 Delta 方法的区间估计,还有简单的 t 检验和画图(包括 base 图形和 ggplot2 图形)。其中图表都是动态生成,几乎没有任何写死的数字。
这个例子的数据在所有人都可以公开访问的网站上,所以数据有可重复性;分析代码全都嵌在 LyX 文档中,所以分析过程也有可重复性。这里面不涉及到生成随机数,所有计算都是确定性的,因此所有人用相同的工具可以重复生成我的结果。
除了可重复性之外,由于分析流程全都用代码记录,所以我不必担心数据的提供者突然更换源数据中的几个数值,如果发生这种情况,我只需要重新点一次按钮就可以了。当然,有时候要是数据发生了很大的变化,导致结论都变了,那么就需要修改正文文本了(实际上结论也是有可能动态化的,这里对于一份普通作业来说就没必要搞那么复杂了)。
另外,LyX 文档本身其实也是纯文本文件,这也为文件的版本控制留出了一条路。我们可以使用版本控制工具 SVN 或 GIT 来管理我们的文档,每次的修改和更新部分一目了然,而且可以团队合作共同写一份报告(版本控制工具会自动合并各位成员的修改),这比 Word 里面笨重的 “审核修订” 功能又强了百倍,你再也不必总是发送邮件附件 “某主题报告张三 20101104.doc” 或“某主题报告李四 20101103.doc”给你的同事,然后用肉眼修订。LyX 本身支持 SVN,(预计)到本年年末,LyX 2.0 横空出世时,这个版本控制功能将极大增强。这似乎有点离题,但我要说的是 “透明” 工作方式带来的天然优势。
免费的午餐是不存在的,用 LyX 和 pgfSweave 也要付出一些代价,这些可能的痛苦我都在上面提到的英文博客中解释了,这里简要提一下:
- 查错略有些麻烦:如果 R 代码没有错误,那么万事大吉,点一下按钮就可以生成 PDF 报告了,但这种情况恐怕少之又少,当代码运行出错的时候,LyX 无法知道 R 出了什么错,它不会记录 R 运行的日志,这个问题可以通过命令行重定向解决。我在自动配置文件中已经写好了,读者可以不必关心细节,如果 R 运行出错,那么可以到 LyX 临时目录下找一个
*.Rnw.log文件,这里的*是你的 LyX 文档名称,临时目录可以在 LyX 菜单 “工具–> 选项–>路径–>临时文件夹”中找到,也可以自行设置(我通常把默认的目录换成一个更 “浅” 一些的目录,方便我查看日志,要不然得走到系统默认的很深的隐藏目录中去)。这个日志文件会记录 R 的运行过程,你可以从最后几行看出来到底运行到哪个代码段出了错; - 警惕 LaTeX 特殊字符:LaTeX 本身大概有十来个特殊字符,如果要使用它们本身,则需要用 \ 引导,比如百分号需要写成
\%,否则%意思是注释;由于 pgfSweave 生成的是 LaTeX 代码图形,里面要是含有特殊字符则会让 LaTeX 编译失败,这种情况可以手工处理,比如plot(x_1, y)会生成 x 轴标签 x_1,我们可以手工指定 x 轴标签plot(x_1, y, xlab = "x\\_1"),这样就不会编译出错了;另外一个办法是看 tikzDevice 包的帮助文档,它有办法自动处理这样的特殊字符;最后一个办法就是不用 tikz 图形,改用 PDF 图形,在代码段的选项中设定<<tikz=FALSE, pdf=TRUE>>=,损失样式,换取 “安全”; - 超大图形:如果一幅图形非常复杂,则相应的 tikz 文件也会非常大,这会让 LaTeX 抱怨内存不够用,编不过去,这种情况下也可以取道 pdf(例如我的硕士论文图 1 和图 9);
- 使用 lattice 和 ggplot2 图形的时候一定要记得
print()图形,否则图不会被画出来,这和 base 图形是不一样的;
可以看到,尽管这些痛苦存在,但并非跨不过去。只是初学者一定要注意,免得处处受挫。
本文看似很长,但如果仅仅从使用角度来说,可能五分钟就足够你完成配置并写出一篇动态统计分析报告了。这里面的细节太繁杂,为了避免 “欲练此功,挥刀自宫”,我把配置过程揉进了一个 R 脚本,随后的事情就是理解各种工具的工作原理(理不理解其实关系也不大)、学习基本用法(主要是各种 Sweave 选项,参见?RweaveLaTeX和?pgfSweave),我想新手上手可能也不一定就那么难。我要强调的是时刻保持挑剔的心态,不要制造垃圾代码,让文档尽量简洁。如果真把 LyX 当 Word 用(这里选 12 号字、那里强制换行),那就糟糕了——你没领悟 LaTeX 的排版哲学。
统计的透明,仅仅靠道德宣传和约束恐怕是永远都不可能实现的,我们需要使用透明的工具。很多人认为工具只是低层次的东西,然而也许我们能通过工具推动一套制度。本文也可以说是象牙塔中的一种想象,它是否能得到实际应用,还要经过实践检验。不管怎样,如果能真正步入 Sweave 殿堂,一切报表工具将是浮云。
总之,自由软件的自由,不仅仅是开源这么简单。
8. 参考资料
- LaTeX 学习材料:A Not So Short Introduction to LaTeX (英文、中文 1、中文 2);这是几年前我的 LaTeX 入门材料
- Sweave 手册及相关信息1
- pgfSweave 包开发网站
- LaTeX and Sweave without Tears(个人报告)
这里要特别感谢爱荷华州立大学统计系 579 课程的同学们不断向我反馈程序问题,才能使得这段程序日臻完善,让看起来遥不可及的 Sweave 能飞入寻常百姓家。
- 编者注:这个链接现在已经失效,抱歉。 ↩
中国人民大学统计硕士,爱荷华州立大学统计学博士,R 包 knitr 的主要作者。现为 RStudio 软件工程师,曾负责 Shiny 包相关开发工作,后转入 R Markdown 相关扩展包的开发,包括 bookdown 和 blogdown。对统计计算、可视化、以及各类网页相关技术感兴趣,有志于对技术写作工具做减法工作,坚信人类浪费了太多时间在期刊论文、学位论文、书籍的排版上。平时主要活跃在 Github 上。个人主页在 https://yihui.name,思想偏激,流水账、意识流甚多,小人之心甚重,慎入。
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:[email protected]),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK