

Kamelet for streaming to Kafka!
source link: http://wei-meilin.blogspot.com/2021/06/kamelet-for-streaming-to-kafka.html?utm_campaign=Feed%3A+blogspot%2FhFXzh+%28Christina+%E7%9A%84+J%E8%80%81%E9%97%86%29
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Kamelet for streaming to Kafka!
You want Kafka to stream and process the data. But what comes after you set up the platform, planned the partitioning strategy, storage options, and configured the data durability? Yes! How to stream data in and out of the platform. And this is exactly what I want to discuss today.
The Background
Before we go any further, let’s see what Kafka did to make itself blazing fast? Kafka is optimized for writing the stream data in binary format, that basically logs everything directly to the file system (Sequential I/O) and makes minimum effort to process what's in the data (Optimize for Zero Copy). Kafka is super-charged at making sure data is stored as quickly as possible, and quickly replicating for a large number of consumers. But terrible at communication, the client that pushes content needs to SPEAK Kafka.
Here we are, having a super fast logging and distributing platform, but dumb at connecting to other data sources. So who is going to validate the data sent in/out of the kafka topic? What if I need to transform the data content? Can I filter the content partially? You guessed it. The clients. We now need smart clients that do most of the content processing and speak Kafka at the same time.
What are the most used connect tools today for Kafka users?
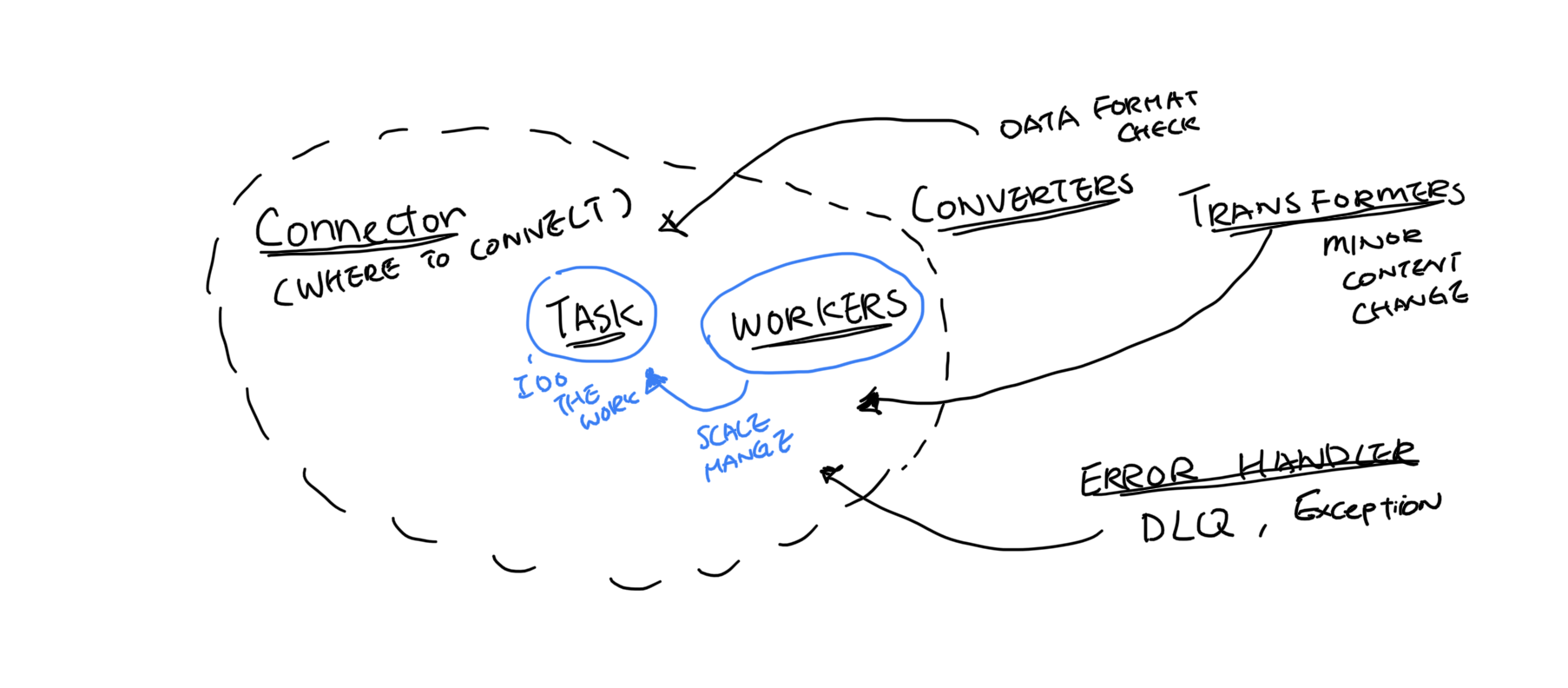
Kafka Connect is what the majority of the Kafka users are using today. It has been broken down into many parts such as connector, tasks, worker, converter, transformer and error handler. You can view the task and worker as how the data flow is executed. For a developer they will be mostly configuring the rest 4 pieces.
Connector - Describes the kind of source or the sink of the data flow, translating between the client/Kafka protocol, and knowing the libraries needed.
Converter - Converts the binary to the data format accepted by the client or vice versa (Currently there is limited support from Confluent, they only do data format) And does data format validation.
Transformer - Reads into the data format, can help make simple changes to individual data chunks. Normally you would do filtering, masking or any minor changes. ( This does not support simple calculations)
Error Handler - Define a place to store problematic data (Confluent : Dead letter queues are only applicable for sink connectors.)
After configuring, it then uses Task and Worker to determine how to scale and execute that pipe data in/out of Kaka. For instance, running a cluster of works to scale and allow tasks to perform parallel processing of streams.
Camel is another great option!
![]()
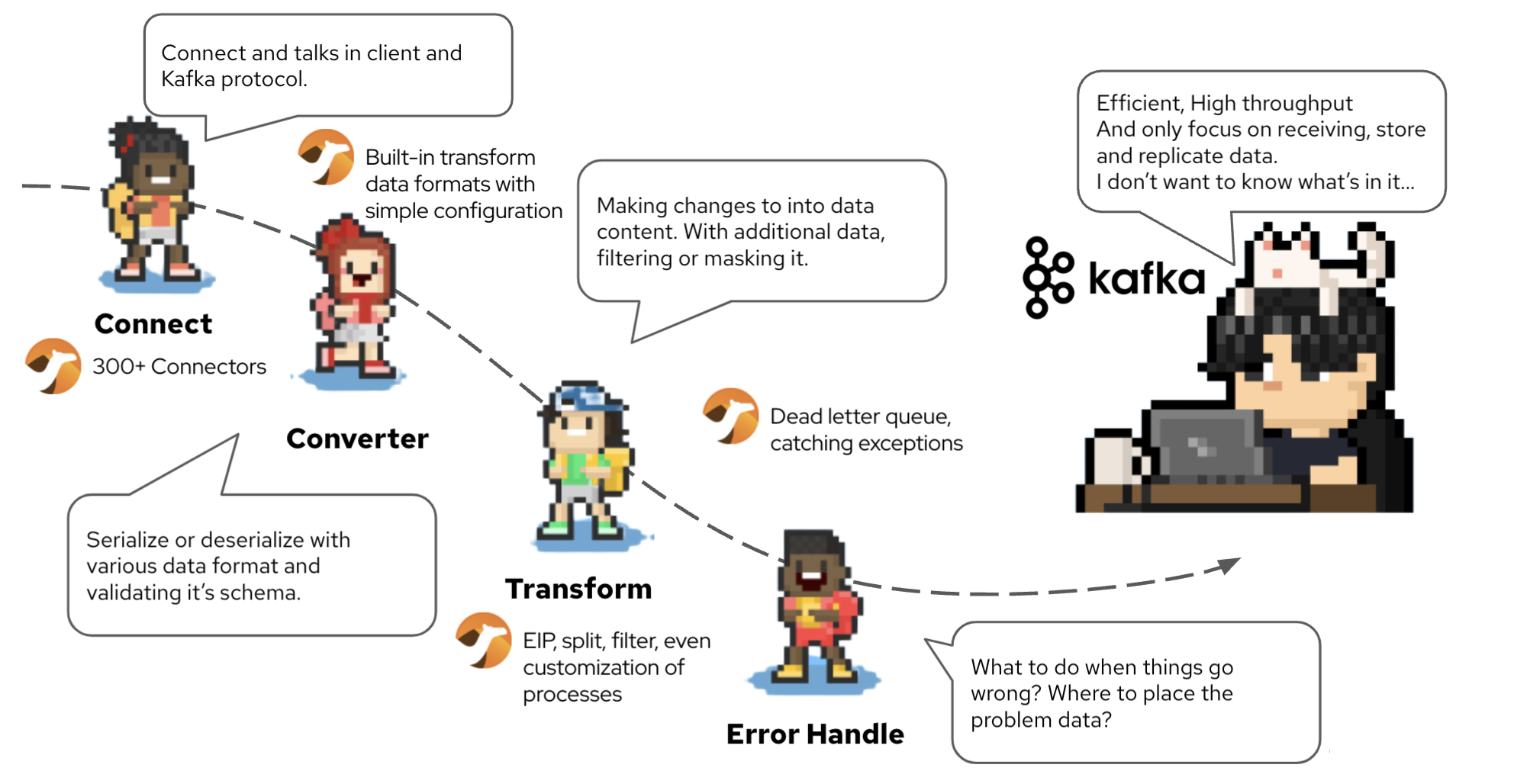
Apache Camel is a GREAT alternative for connecting Kafka too. Here’s what Camel has to offer.
Connector - Camel has more than 300+ connectors, you can use it to configure as source or the sink of the data flow, translating between the 100+client/Kafka protocol.
Converter - Validate and transform data formats with simple configuration.
Transformer - Not only does simple message modification, it can apply integration patterns that are good for streaming processing, such as split, filter, even customization of processes.
Error Handler - Dead letter queue, catching exceptions.
There are also many ways to run Camel. You can have it running as a standalone single process that directly streams data in/out of Kafka . But Kamel works EXCEPTIONALLY well on Kubernetes. It run as a cluster of instances, that execute in parallel to maximize the performance. It can be deployed as native image through Quarkus to increase density and efficiency. The platform OpenShift (Kubernetes) allows users to control the scaling of the instance. Since it’s on K8s, another advantage is that operation can operate these as a unify platform, along with all other microservices.
Why Kamelet? (This is the way!)
One of the biggest hurdles for non Camel developers is, they need to learn another framework, maybe another language (Non-Java) to be able to get Camel running. What if we can smooth the learning curve and make it simple for newcomers? We see a great number of use cases where the masking and filtering are implemented company wide. Being able to build a repository and reuse these logics will make developers work more efficiently.
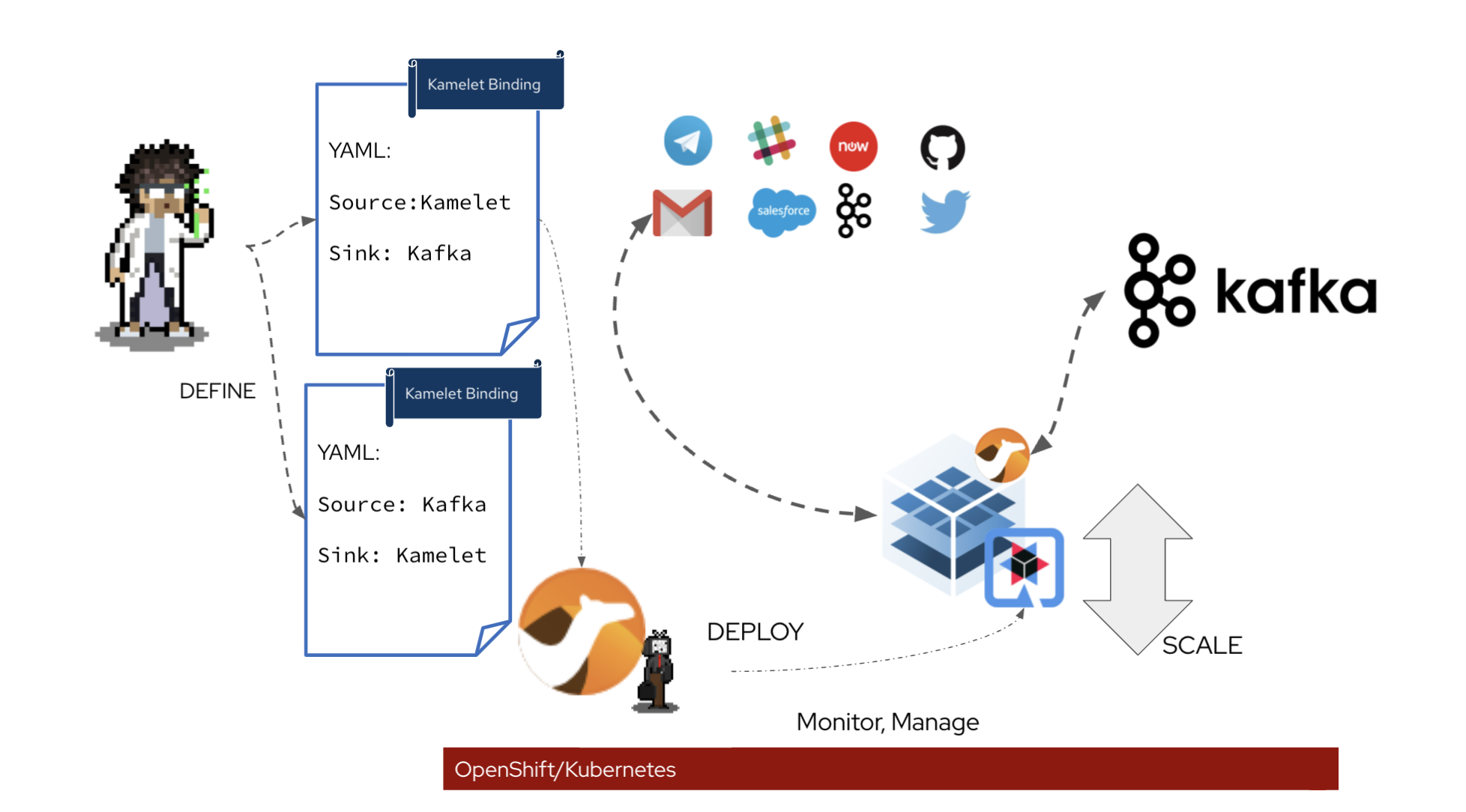
Plug & Play
You can look at Kamelets as templates, where you can define where to consume data from and send data to, does filtering, masking, simple calculation logic. Once the template is defined, it can be made available to the teams, that simply plugs it into the platform, configure for their needs (with either Kamelet Binding or another Camel route), and boom. The underlying Camel K will do the hard work for you, compile, build, package and deploy. You have a smart running data pipeline streams into Kafka.
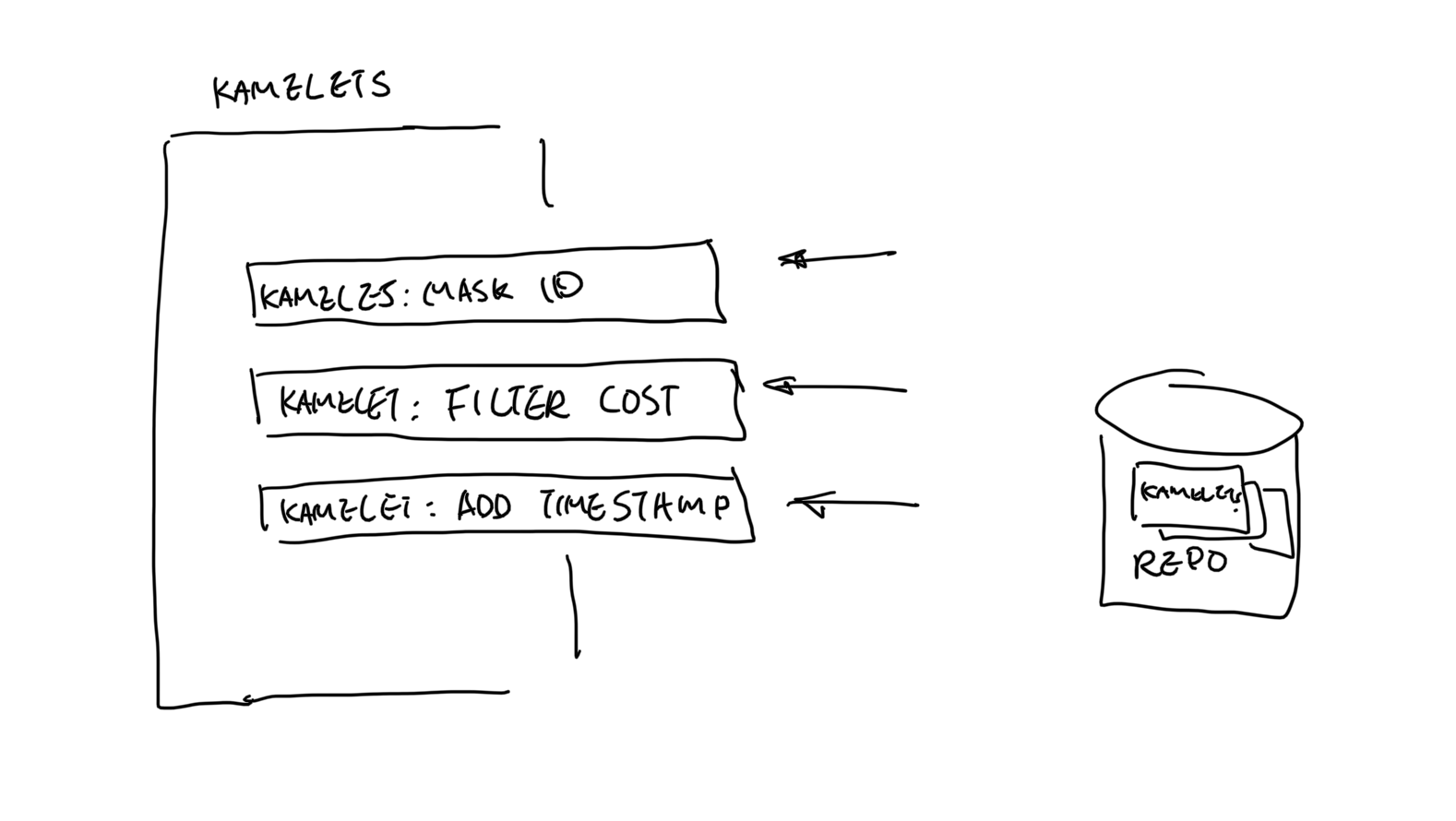
Assemble & Reuse
In a data pipeline, sometimes, you just need that bit of extra work on the data. Instead of defining a single template for each case, you can also break it down into smaller tasks. And assemble these small tasks to perform in the pipeline for each use case. .
Streams & Serverless
Kamelets allows you to stream data to/from either Kafka store or Knative event channel/broker. To be able to support Knative, Kamelet can help translate messages to CloudEvents, which is the CNCF standard event format for serverless. And also apply any pre/post-processing of the content in the pipeline.
Scalable & Flexible
Kamelet lives on Kubernetes(can also run standalone), which gives you a comprehensive set of scaling tools, readiness, liveness check and scaling configuration. They are all part of the package. It scales by adding more instances. The UI on the OpenShift Developer Console can assist you to fill in what’s needed. And also auto discover the available source/sink for you to choose where the data pipelines start or end.
Unify for DEV & OPS
In many cases, DevOps engineers are often required to develop another set of automation tools for the deployment of connectors. Kamelet can run like other applications on kubernetes, the same tools can be used to build, deploy and monitor these pipelines. The streamline DEVOPS experience can help speed up the automation setup time.
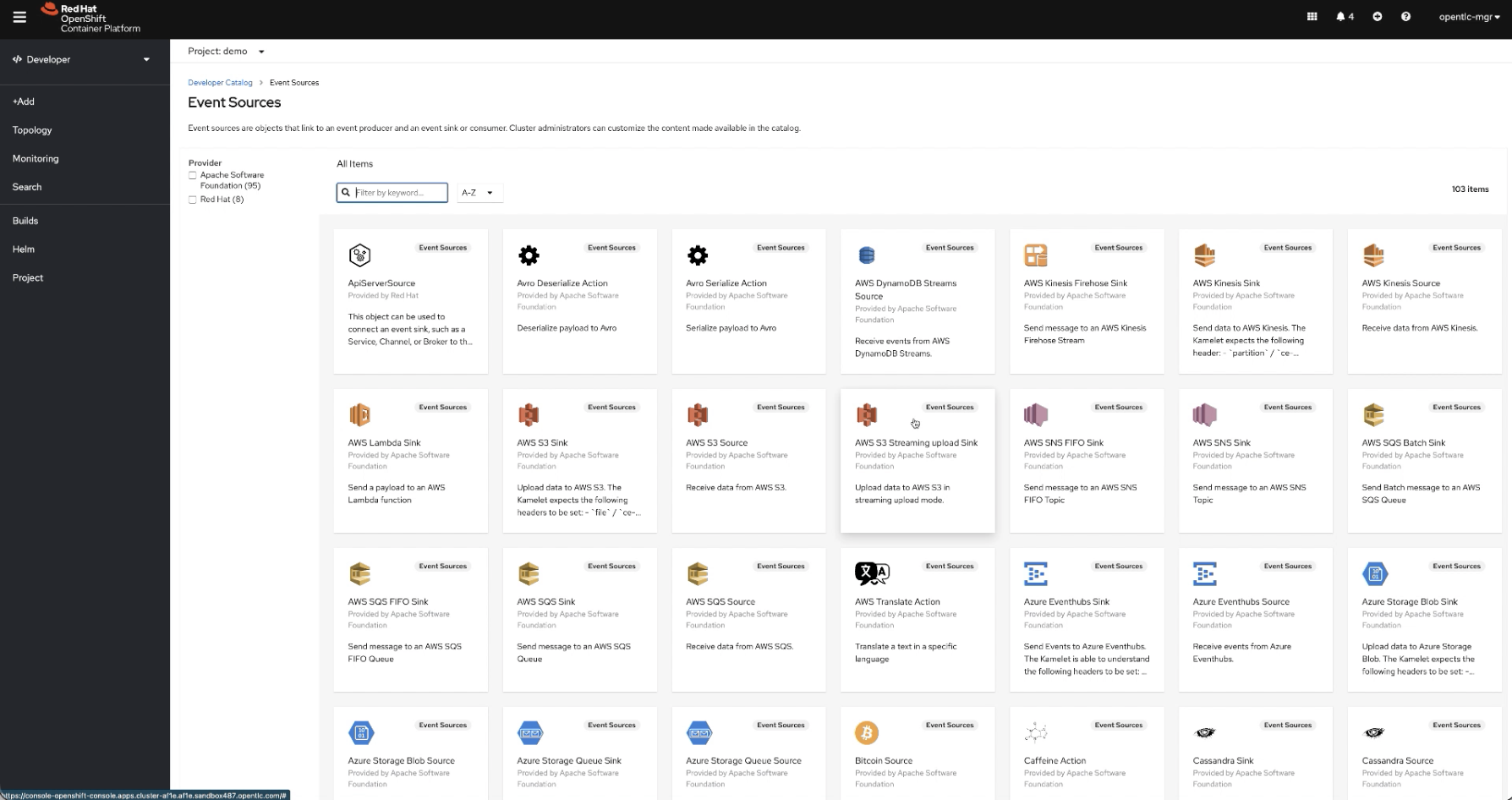
Marketplace
List of catalogues that are already available (Not enough?). If you just want to stream data directly, simple pick the ones you need and start streaming. And we welcome your contributions too.
What to know more about Kamelet? Take a look at this video, where it talks about why using Kamelet for streaming data to Kafka with a demo.
00:00 Introduction
00:30 What is Kamelet?
01:06 Why do you need connectors to Kafka, and what is required in each connector?
02:16 Why Kamelet?
07:45 Marketplace of Kamelet!
08:47 Using Kamelet as a Kafka user
10:58 Building a Kamelet
13:25 Running Kamelet on Kubernetes
15:44 Demo
17:30 Red Hat OpenShift Streams in action
19:26 Kamelets in action
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK