
6

【spark, Hive, Hadoop, yarn】汇总
source link: https://www.guofei.site/2018/03/27/spark.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

【spark, Hive, Hadoop, yarn】汇总
2018年03月27日Author: Guofei
文章归类: 1-1-算法平台 ,文章编号: 153
版权声明:本文作者是郭飞。转载随意,但需要标明原文链接,并通知本人
原文链接:https://www.guofei.site/2018/03/27/spark.html
Spark
spark基本配置
from pyspark.sql import SparkSession
import os
os.environ['PYSPARK_PYTHON']="/usr/bin/python"
os.environ['PYSPARK_DRIVER_PYTHON']="/usr/bin/python"
spark = (SparkSession
.builder
.appName("mytest")
.enableHiveSupport()
.config("spark.executor.instances", "50")
.config("spark.executor.memory","4g")
.config("spark.executor.cores","2")
.config("spark.driver.memory","4g")
.config("spark.sql.shuffle.partitions","500")
.getOrCreate())
spark.sparkContext.uiWebUrl # Spark Web UI
spark.sparkContext.applicationId
cluster 模式下,想要提交多脚本,除了提交时附加外,还可以这样 spark.sparkContext.addPyFile('你的文件.py')
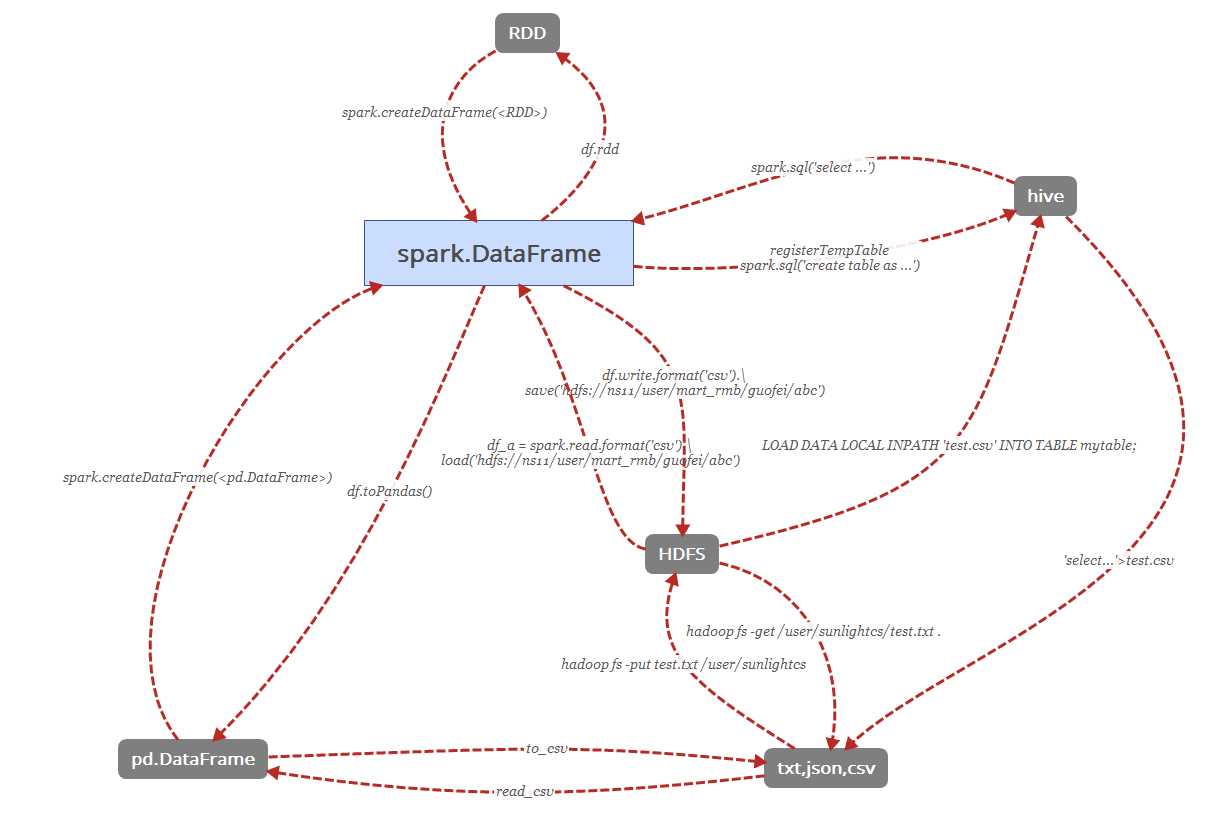
Hive to Spark
spark.sql('select ...')
Spark to Hive
- 插入普通表
df_data.registerTempTable('table2') spark.sql('create table tmp.tmp_test_pyspark2hive as select * from table2') - 静态插入分区表
df_data.registerTempTable('table2') spark.sql(''' INSERT OVERWRITE TABLE tmp.tmp_test PARTITION(dt='2018-05-02') select * from tmp_test ''') - 动态插入分区表
# 需要先把partition.mode配置为nonstrict spark.conf.set("hive.exec.dynamic.partition", "true") spark.conf.set("hive.exec.dynamic.partition.mode", "nonstrict") # 也可以在启用 SparkSession 时设置 # spark=SparkSession.builder.appName("tmp_test").\ # config("hive.exec.dynamic.partition", "true").\ # config("hive.exec.dynamic.partition.mode", "nonstrict").\ # enableHiveSupport().getOrCreate() df_data.registerTempTable('table2') spark.sql(''' INSERT OVERWRITE TABLE tmp.tmp_tmp_test PARTITION(a,b) SELECT c,d,e,a,b FROM tmp_test ''') - saveAsTable
df1_2.write.mode('overwrite').format('orc').partitionBy('dt').saveAsTable('tmp.tmp_test_guofei') # `append`, `overwrite`, `errorifexists`, `ignore` # 'overwrite' :普通表:被覆盖,分区表所有分区被覆盖(相当于先清除数据,然后写入数据) # 'append' : 无论是普通表还是分区表,原数据不会丢失,新数据也不会少 # 往往想要覆盖所涉及的分区,未涉及到的分区不变,两种方法: # 1. 上面的sql语句去 overwrite # 2. 先用命令drop相关分区,然后 append : # spark.sql(''' # ALTER TABLE tablename DROP IF EXISTS PARTITION(dt='{cal_dt_str}') # '''.format(cal_dt_str=cal_dt_str)) # 项目上,往往需要在建表后添加个人信息,spark.sql("ALTER TABLE tmp.tmp_test SET TBLPROPERTIES ('author' = 'guofei')") - insertInto
df.repartition('col1').write.insertInto('app.app_guofei8_test9', overwrite=True) # 1. 表必须已经存在 # 2. 其它效果与 saveAsTable 一样
Spark与pandas
df_data.toPandas() # 返回 pandas.DataFrame 类型
spark.createDataFrame(<pd.DataFrame>) # 返回 spark.DataFrame 类型DataFrame 与 RDD
rdd1=df_data.rdd
spark.createDataFrame(rdd1)
Spark与HDFS
df.write.save(path="/user/mart_rmb/user/guofei8/skulist_test.csv", format='csv', mode='overwrite', header=True)
df_a = spark.read.load(path="/user/mart_rmb/user/guofei8/skulist_test.csv", format="csv", header=True)
TODO: 这个版本,比之前写的版本要简洁,但脑图还没更新
spark与硬盘文件
<pd.DataFrame>.to_csv('') # pandas 存储到本地csv
os.system("hive -e 'select * from ...'>test.csv") # hive存储到本地csvHive
bash中的hive基本操作
hive -e "select * from table1" # 把查询的结果打印在控制台上。
# `-e` SQL from command line
# `-S` Silent mode
hive -e "select * from table1" > data.csv #会将查询的结果保存到 data.csv
hive -S -e "select * from table1" > data.csv
# `-S` Silent mode,效果是不会在屏幕上打印OK和数据条数
hive -f sqlfile.sql # 执行文件中的sql
# `-f` SQL from files
硬盘文件到hive
create table if not exists mytable(key INT,value STRING)
ROW FOWMAT DELIMITED FIELDS TERMINATED BY ',';
LOAD DATA LOCAL INPATH 'test.csv' INTO TABLE mytable;
Hive常用命令
- 添加一列
alter table dev.table_name add COLUMNS (col1 double COMMENT '注释1', col2 double COMMENT '注释2' );
hadoop hdfs常用命令
hadoop fs # 查看Hadoop HDFS支持的所有命令
hadoop fs -ls # 列出目录及文件信息
hadoop fs -ls /user/abc # 列出指定目录信息
hadoop fs -ls -R # 循环列出目录、子目录及文件信息
# 本地复制
hadoop fs -put test.txt /user/sunlightcs
# 将本地文件系统的test.txt复制到HDFS文件系统的/user/sunlightcs目录下
hadoop fs -get /user/sunlightcs/test.txt
# 将HDFS中的test.txt复制到本地文件系统中,与-put命令相反
# 查看内容
hadoop fs -cat /user/sunlightcs/test.txt
# 查看HDFS文件系统里test.txt的内容
hadoop fs -tail /user/sunlightcs/test.txt
# 查看最后1KB的内容
# mkdir
hadoop fs -mkdir <path>
# 删除
hadoop fs -rm /user/sunlightcs/test.txt
# 从HDFS文件系统删除test.txt文件,rm命令也可以删除空目录
hadoop fs -rm -R /user/sunlightcs
# 递归删除(删除/user/sunlightcs目录以及所有子目录)
# 复制
hadoop fs -cp SRC [SRC …] DST
# 将文件从SRC复制到DST,如果指定了多个SRC,则DST必须为一个目录
# 移动
hadoop fs -mv URI [URI …] <dest>
# 把一个路径移动到另一个路径
# 统计文件数量
hadoop fs -count [-q] PATH
# 查看PATH目录下,子目录数、文件数、文件大小、文件名/目录名
# TODO: 还不知道-q什么效果
hadoop fs -du PATH
# 显示该目录下每个文件或目录的大小(只显示下一级目录和文件)
hadoop fs -du -s PATH
# 类似于du,PATH为目录时,会显示该目录的总大小(只显示一个目录)
# hadoop fs -chgrp [-R] /user/sunlightcs
# 修改HDFS系统中/user/sunlightcs目录所属群组,选项-R递归执行,跟linux命令一样
#
# hadoop fs -chown [-R] /user/sunlightcs
# 修改HDFS系统中/user/sunlightcs目录拥有者,选项-R递归执行
#
# hadoop fs -chmod [-R] MODE /user/sunlightcs
# 修改HDFS系统中/user/sunlightcs目录权限,MODE可以为相应权限的3位数或+/-{rwx},选项-R递归执行
#
# hadoop fs -expunge
# 清空回收站,文件被删除时,它首先会移到临时目录.Trash/中,当超过延迟时间之后,文件才会被永久删除
#
# hadoop fs -getmerge SRC [SRC …] LOCALDST [addnl]
# 获取由SRC指定的所有文件,将它们合并为单个文件,并写入本地文件系统中的LOCALDST,选项addnl将在每个文件的末尾处加上一个换行符
#
# hadoop fs -touchz PATH
# 创建长度为0的空文件
#
# hadoop fs -test -[ezd] PATH
# 对PATH进行如下类型的检查:
# -e PATH是否存在,如果PATH存在,返回0,否则返回1
# -z 文件是否为空,如果长度为0,返回0,否则返回1
# -d 是否为目录,如果PATH为目录,返回0,否则返回1
#
# hadoop fs -text PATH
# 显示文件的内容,当文件为文本文件时,等同于cat,文件为压缩格式(gzip以及hadoop的二进制序列文件格式)时,会先解压缩
#
# hadoop fs -help ls
# 查看某个[ls]命令的帮助文档
yarn
yarn application -kill application_id # 杀掉一个 job
参考文献
https://blog.csdn.net/wy250229163/article/details/52354278
https://databricks.com/blog/2016/08/15/how-to-use-sparksession-in-apache-spark-2-0.html
https://blog.csdn.net/gz747622641/article/details/54133728
您的支持将鼓励我继续创作!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK