

(二)毫米波雷达公开数据库
source link: https://zhuanlan.zhihu.com/p/372804658
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

(二)毫米波雷达公开数据库
众所周知,对于深度学习算法来说,高质量,大规模的数据是非常非常重要的因素。在早期的很多工作中,研究人员都是自己采集和标注数据。这样做一方面非常费时费力,一方面这些非公开的数据库也给算法对比带来不便。随着研究的不断深入,近几年也开始慢慢出现了一些毫米波雷达的公开数据库。但是相比较于图像和激光雷达,无论是数据的规模还是多样性,毫米波雷达数据库都还处于初级阶段。根据包含数据种类的不同,我把这些数据库分为多模态数据库和单模态数据库。前者除了雷达数据,还可能包括同步的图像和激光雷达数据,因此也可以用来进行数据融合的研究。而后者只包括了雷达数据,相对来说应用范围较窄。一般来说,如果没有同步的相机或者激光雷达,单纯的雷达数据是很难标注的。因此,一般公开发表的带有标注的数据库都是多模态数据库。本专栏侧重深度学习算法在雷达数据上的应用,因此这里只介绍有标注信息的多模态数据库。
NuScenes[1]
这个数据库由Motional公司(之前叫nuTonomy)于2019年3月发布,是第一个公开发表的多模态数据库,包含了在波士顿和新加坡的1000个路况场景中采集的140万张图像(6个Camera),39万帧激光雷达数据(1个LiDAR),140万帧毫米波雷达数据(5个RADAR),以及在4万个关键帧中标注的140万个物体框。2020年7月还进一步发布了用于激光雷达语义分割的标注数据。下图是一个场景的例子,不过只显示了图像和激光雷达数据。

除了数据本身,NuScenes还在各种学术会议(比如CVPR2019,NeurIPS 2020,ICRA 2021)上发布了挑战任务,包括物体检测,物体跟踪,路径预测和语义分割。从网站提供的资料来看,很多参赛者都利用了多种数据,这对多传感器融合的研究是一个很大的促进。对于雷达数据来说,NuScenes的缺点是只包含了稀疏的点云,这就限制了基于雷达数据的算法研究。
CARRADA[2]
这个数据库由法国的研究者于2020年首次发布,2021年又发布了新的版本。CARRADA包含了同步的图像和雷达数据,一共30个序列,12666帧(21.1分钟),其中7193帧包含标注的物体。标注的物体有三类,分别是行人,自行车和汽车。标注的格式有三种,分别是sparse point,bounding box和dense mask。CARRADA包含了底层的雷达数据,其格式为Range-Angle-Doppler Tensor。但是CARRADA的采集场景并不是真实的交通路况,因此其实用性会受到一定影响。
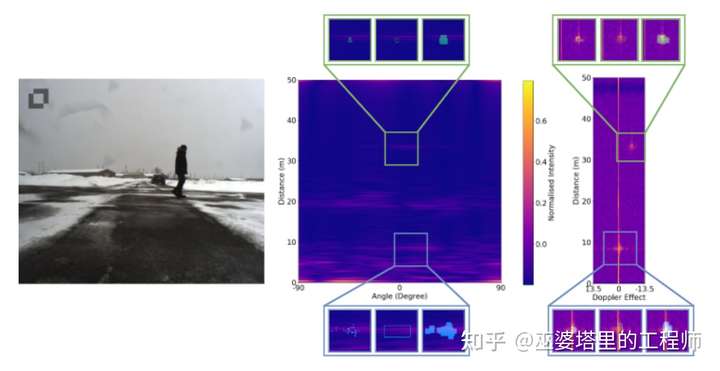
SCORP[3]
同样在2020年,加拿大,法国和德国的研究人员联合发布了SCORP数据库。这是第一个包含了ADC数据(经过数模转换后的I-Q samples)的公开数据库。ADC数据经过多次FFT处理后才得到RAD Tensor,因此SCORP的数据与CARRADA相比又更底层了一些。值得一提的是,这两个数据库的创建者中都包括了Valeo公司的研究人员。
SCORP数据库提供了三种数据表示,分别是Sample-Chirp-Angle (SCA) Tensor,Range-Azimuth-Doppler (RAD) Tensor以及Point Cloud。这三种数据来自雷达信号处理中的三个不同阶段。目前来说,机器学习算法常用的是Point Cloud,也有少量采用RAD Tensor的工作。这部分内容可以参考我之前的文章:
SCORP数据库包含了同步的图像数据,也用来辅助标注Free Space。针对这对三种不同的数据形式,作者测试了三种神经网络结构来试验Free Space Segmentation的效果。总的来说,SCORP是一个相对全面的数据库,但依然还存在三点不足:1)数据量较少,只有来自11个序列的3913帧数据;2)没有BoundingBox标注,无法测试物体检测和跟踪算法。3)雷达和图像数据都来自于单个传感器,视场较窄,无法实现360度的感知。
CRUW[4]
这个数据库由华盛顿大学的研究者于2020年发布。这是一个相对大规模的数据库,包含了各种真实场景下(Parking lot,Campus road, City street, Highway)的40万帧图像和雷达数据。采集的传感器包括2个像机和2个雷达。CRUW提供了物体级别的标注,包括物体的位置,大小和类别,并且在图像数据上进一步提供了mask的信息。雷达数据的格式是Range-Azimuth Map。值得一提的是,作者基于此数据库发表了一个基准的多传感器融合物体检测算法,并且在2021年发布的基于此数据库的挑战比赛。
SeeingThroughFog[5]
这个数据库包括了采用相机,毫米波雷达,激光雷达,热传感等多种传感器采集的超过10万个物体的数据。有意思的是,这些数据是在极端的天气环境下采集,包括雾天,雪天和雨天,来自于欧洲北部大约1万公里的行程。其目的是为了证明在极端天气环境下,多传感器的冗余性以及数据融合带来的性能提升。针对这一点,作者对比了很多方法,也提出了一种基于Entropy的融合算法。感兴趣的朋友可以参考他们的论文。
未来发展方向
以上大致介绍了目前为数不多的一些毫米波雷达数据库。这些数据库各有侧重,也各有优缺点。个人认为,未来的毫米波雷达数据库应该包括以下方面:
1)多模态数据:包括同步的图像,激光雷达等数据,用来进行多传感器融合的研究。
2)多数据类型:包括ADC数据,Rangle-Azimuth-Doppler Tensor数据,点云数据等,为不同层次的算法研究和实际应用提供支持。
3)360度视场:这需要多个雷达配合完成,以满足多种自动驾驶应用的需求。
4)大规模数据:这是深度学习算法的基础。一般来说,至少要有超过10万帧的不同场景,不同天气条件下采集的数据。
5)丰富的标注信息:包括物体的类别,位置,大小,方向甚至mask;以及场景的语义信息,比如free space, occupied space等。
本文内容部分参考了综述文章:
Application of Deep Learning on Millimeter-Wave Radar Signals: A Review
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK