

(FM) Factorization Machines
source link: https://xiang578.com/post/fm.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Factorization Machines(FM) 由日本 Osaka University 的 Steffen Rendle [1] 在 2010 年提出,是一种常用的因子机模型。
假设现在有一个电影评分的任务,给定如下如所示的特征向量 x(包括用户名、当前在看的电影、已经打分的电影、时间特征、之前看的电影),预测用户对当前观看电影的评分。
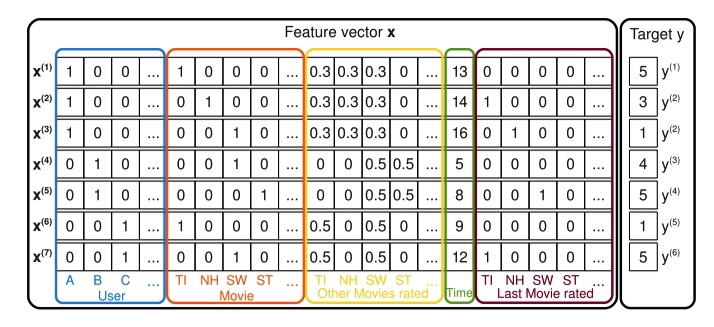 电影评分
电影评分作者在线性回归模型的基础上,添加交叉项部分,用来自动组合二阶特征。
其中交叉特征的权重由两个向量的点积得到,可以解决没有在模型中出现的特征组合权重问题,以及减少参数数量。
通过下面的方法来化简交叉项权重计算,算法复杂度降到线性。
对交叉项部分的求导:
其中 与 无关,可以在计算导数前预处理出来。
FM vs SVM
对于经典的特征组合问题,不难想到使用 SVM 求解。Steffen 在论文中也多次将 FM 和 SVM 做对比。
在考虑 SVM 的 Polynomial kernel 为 ,映射
SVM 的公式可以转化为:
论文中提到一句上面的公式中 和 表达能力类似,我猜这也是为什么 FM 中没有自身交叉项的原因吧。
FM 相比于 SVM 有下面三个特点: 1. SVM 中虽然也有特征交叉项,但是只能在样本中含有相对应的特征交叉数据时才能学习。但是 FM 能在数据稀疏的时候学习到交叉项的参数。 2. SVM 问题无法直接求解,常用的方法是根据拉格朗日对偶性将原始问题转化为对偶问题。 3. 在使用模型预测时,SVM 依赖部分训练数据(支持向量),FM 模型则没有这种依赖。
FM 用来做回归和分类都很好理解,简单写一下如何应用到排序任务中。以 pairwise 为例。假设排序结果有两个文档 和 ,显然用户点击文档有先后顺序,如果先点击 ,记 label ,反之点击 ,label 。模型需要去预测 。
参考逻辑回归,用最大似然对参数进行估计,得到损失函数为 。优化过程和前面提到类似。
NFM 和 AFM 两篇论文是同一个作者写的,所以文章的结构很相近。
FM 模型由于复杂度问题,一般只使用特征二阶交叉的形式,缺少对 higher-order 以及 non-liner 特征的交叉能力。NFM 尝试通过引入 NN 来解决这个问题。
NFM 的结构如下:第一项和第二项是线性回归,第三项是神经网络。神经网络中利用 FM 模型的二阶特征交叉结果做为输入,学习数据之间的高阶特征。与直接使用高阶 FM 模型相比,可以降低模型的训练复杂度,加快训练速度。
NFM 的神经网络部分包含 4 层,分别是 Embedding Layer、Bi-Interaction Layer、Hidden Layers、Prediction Score。
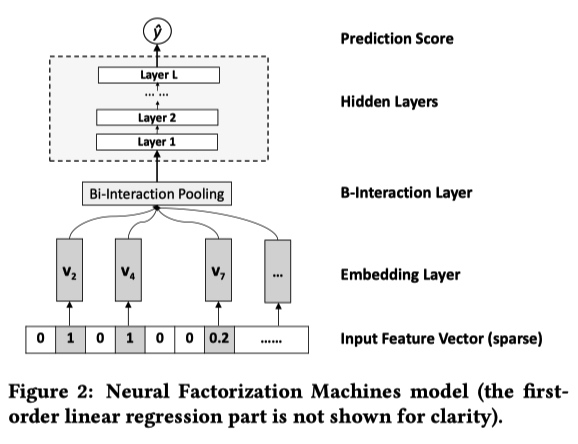 NFM
NFM- Embedding Layer 层对输入的稀疏数据进行 Embedding 操作。最常见的 Embedding 操作是在一张权值表中进行 lookup ,论文中作者强调他们这一步会将 Input Feture Vector 中的值与 Embedding 向量相乘。
- Bi-Interaction Layer 层是这篇论文的创新,对 embedding 之后的特征两两之间做 element-wise product,并将结果相加得到一个 k 维(Embeding 大小)向量。这一步相当于对特征的二阶交叉,与 FM 类似,这个公式也能进行化简:
- Hidden Layers 层利用常规的 DNN 学习高阶特征交叉
- Prdiction Layer 层输出最终的结果:
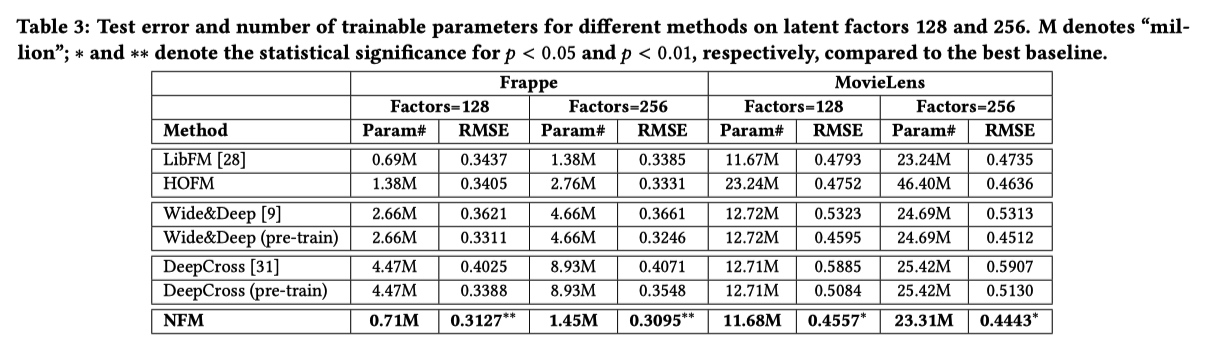
实验结果:
AFM(Attentional Factorization Machine), 在 FM 的基础上将 Attention 机制引入到交叉项部分,用来区分不同特征组合的权重。
单独看上面公式中的第三项结构:
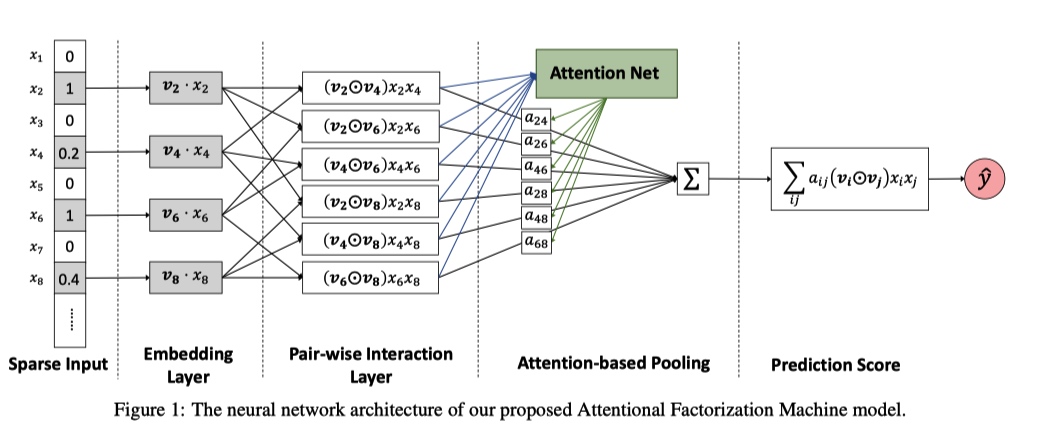
- Embedding Layer 与 NFM 里面的作用一样,转化特征。
- Pair-wise Interaction Layer 是将特征两两交叉,如果对这一步的结果求和就是 FM 中的交叉项。
- Attention 机制在 Attention-based Pooling 层引入。将 Pair-wise Interaction Layer 中的结果输入到 Attention Net 中,得到特征组合的 score ,然后利用 softmax 得到权重矩阵 。
- 最后将 Pair-wise Interaction Layer 中的二阶交叉结果和权重矩阵对应相乘求和得到 AFM 的交叉项。
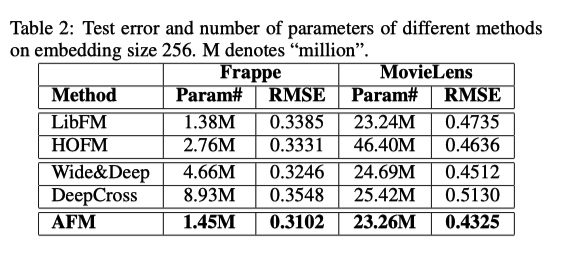
和前一节的实验结果对比,AFM 效果比 NFM 要差一些。这大概就能说明为什么论文中提到 NFM,但是最后没有把 NFM 的结果贴出来,实在是机智。又回到,发论文是需要方法有创新,还是一味追求 state-of-the-art。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK