
5

ImageNet Classification with Deep Convolutional Neural Networks(AlexNet)
source link: https://xiang578.com/post/alexnet.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
ImageNet Classification with Deep Convolutional Neural Networks(AlexNet)
作者以及相关性
- Alex Krizhevsky
- Ilya Sutskever
- Geoffrey E. Hinton
- 本文被认为是这一轮深度学习浪潮的开端
- 将 CNN 技术最先应用到图像识别领域,利用 CNN 参数共享的特性,减少网络的规模
- 解决深度网络难训练(速度慢)以及容易过拟合问题(更多数据或者网络技巧)
数据集与指标
- ImageNet LSVRC-2010 contest: 图片 1000 分类
- top-1 和 top-5 错误率为指标
模型/实验/结论
由于当时的 GPU 显存限制,无法将所有的数据加载到单独 GPU 中,作者使用两个 GPU 并行训练。
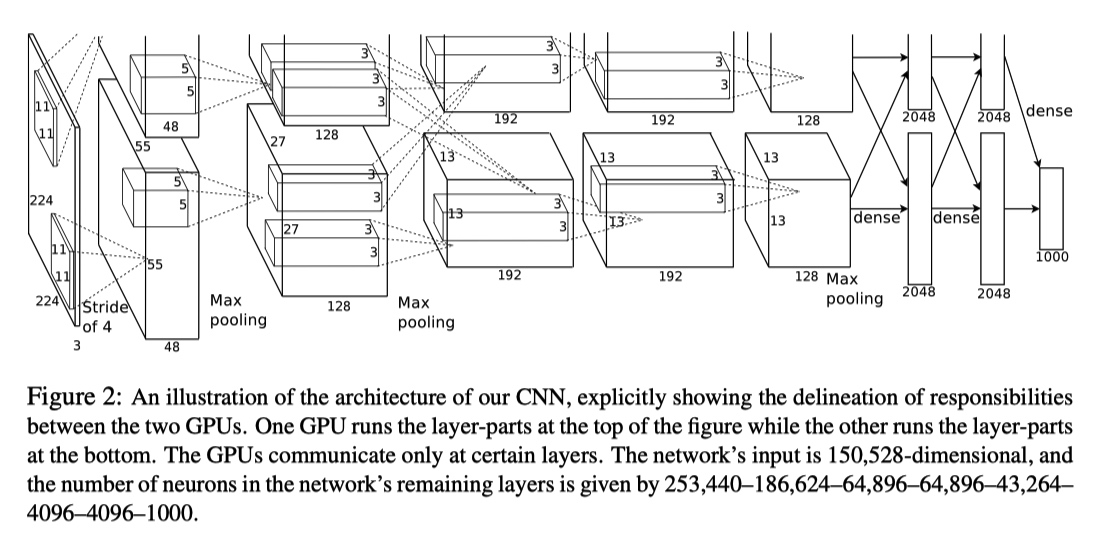
整个模型如下图所示,由 5 个卷积层以及 3 个全连接层组成。其中在 CONV3、FC1、FC2、FC3 层进行两个 GPU 的数据交互。
- [227, 227, 3] INPUT: 原始论文中 224 为笔误。
- [55, 55, 96] CONV1: (11*11*3,96) filters, Stride 4, pad 0
- [27, 27, 96] MAX POOL1: (3*3) filters, Stride 2
- [27, 27, 96] NORM1: Normalization layer
- [27, 27, 256] CONV2: (5*5,256) filters, Stride 1, pad 2
- [13, 13, 256] MAX POOL2: (3*3) filters, Stride 2
- [13, 13, 256] NORM2: Normalization layer
- [13, 13, 384] CONV3: (3*3,384) filters, Stride 1, pad 1
- [13, 13, 384] CONV4: (3*3,384) filters, Stride 1, pad 1
- [13, 13, 384] CONV5: (3*3,256) filters, Stride 1, pad 1
- [6, 6, 256] MAX POOL3: (3*3) filters, Stride 2
- [4096] FC1: 两个 GPU 中的 CONV 层结果进行全连接
- [4096] FC2: FC1 进行全连接
- [1000] FC3: FC2 进行全连接,最后输出分类结果
参数数量 60 million
- 使用 ReLU 作为激活函数:比 tanh 计算开销小,以及收敛速度快。根据问题的特点选择激活函数(大模型、大数据集)
- Local Response Normalization(Norm Layers):局部响应归一化层,后来很少使用。 在经过 ReLU 作用之后,对相同空间位置上(bx,ybx,y)的相邻深度(bjbj )的卷积结果做归一化。n 指定相邻卷积核数目,N 为该层所有卷积的数目。k,n,α,βk,n,α,β 都是超参数。本文使用 k=2,n=5,α=10−4,β=0.75k=2,n=5,α=10−4,β=0.75, 分别降低 top-1 和 top-5 错误 1.4% 和 1.2%
bix,y=aix,y/⎛⎝k+α∑j=max(0,i−n/2)min(N−1,i+n/2)(ajx,y)2⎞⎠βbx,yi=ax,yi/(k+α∑j=max(0,i−n/2)min(N−1,i+n/2)(ax,yj)2)β
- Pooling:s=2 < z=3,有部分重叠,作者通过实验发现这种方法可以更好地避免过拟合。
- data augmentation:
- 对图像进行裁剪以及翻转,扩大数据。这种策略对测试带来影响,测试时裁剪出图片四个角落以及中间部分,得到 5 张图片,另外翻转得到 5 张图片,最后分类结果又这 10 图片的平均得分确定。
- 利用 PCA 改变 RGB 通道的强度。
- Dropout:每次训练的时候,从模型中 sample 出一个小的模型,减少过拟合。
参数:dropout 0.5,batch size 128, SGD Momentum 0.9, Learning rate 1e-2 reduce by 10,L2 weight decay 5e-4
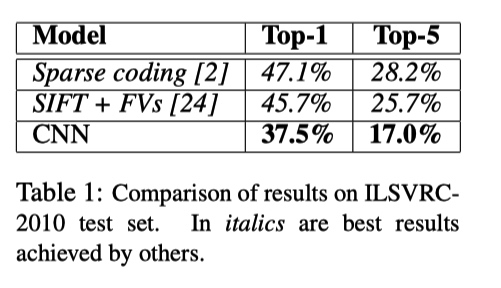
测试集上结果
取出 CONV1 相关的 filters卷积侧重点不同,GPU1 颜色无关,GPU2 颜色相关。多次实验发现都存在这种现象,说明使用多个 GPU 训练是必要的,模型可以捕捉更多信息。

取所有最后一个隐层向量,找到与测试图片欧拉距离最小的训练图片(下图中第一列为测试图片,之后几列是欧拉距离最小的训练集中图片)。肉眼可以发现,同一分类的图片有很大关联性。证明模型能学习图片之间的关系。

- 通过移除 AlexNet 网络中的某几层发现错误率均有提高,这个网络时必要以及有效的。
- 文章中作者通过大量的实验确定模型的细节问题,值得我们学习。
- 当时的 GPU 限制作者的想象力……
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK