

性能调优篇:困扰我半年之久的RocketMQ timeout exception 终于破解了
source link: https://my.oschina.net/u/4052033/blog/5036916
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

在内网环境中,超时问题,网络表示这个锅我不背。
笔者对于超时的理解,随着在工作中不断实践,其理解也越来越深刻,RocketMQ在生产环境遇到的超时问题,已经困扰了我将近半年,现在终于取得了比较好的成果,和大家来做一个分享。
本次技术分享,由于涉及到网络等诸多笔者不太熟悉的领域,如果存在错误,请大家及时纠正,实现共同成长与进步。
1、网络超时现象
时不时总是接到项目组反馈说生产环境MQ发送超时,客户端相关的日志截图如下:  今天的故事将从张图开始。
今天的故事将从张图开始。
2、问题排查
2.1 初步分析
上图中有两条非常关键日志:
-
invokeSync:wait response timeout exception 网络调用超时
-
recive response,but not matched any request
这条日志非常之关键,表示尽管客户端在获取服务端返回结果时超时了,但客户端最终还是能收到服务端的响应结果,只是此时客户端已经等待足够时间后放弃处理了。
关于第二条日志,我再详细阐述一下其运作机制,其实也是用一条链接发送多个请求的编程套路。一条长连接,向服务端先后发送2个请求,客户端在收到服务端响应结果时,怎么判断这个响应结果对应的是哪个请求呢?如下图所示:  客户端多个线程,通过一条连接发送了req1,req2两个请求,但在服务端通常都是多线程处理,返回结果时可能会先收到req2的响应,那客户端如何识别服务端返回的数据是对应哪个请求的呢?
客户端多个线程,通过一条连接发送了req1,req2两个请求,但在服务端通常都是多线程处理,返回结果时可能会先收到req2的响应,那客户端如何识别服务端返回的数据是对应哪个请求的呢?
解决办法是客户端在发送请求之前,会为该请求生成一个本机器唯一的请求id(requestId),并且会采用Future模式,将requestId与Future对象放入一个Map中,然后将reqestId放入请求体中,服务端在返回响应结果时将请求ID原封不动的放入到响应结果中,当客户端收到响应时,先界面出requestId,然后从缓存中找到对应的Future对象,唤醒业务线程,将返回结构通知给调用方,完成整个通信。
故从这里能看到,客户端在指定时间内没有收到服务端的请求,但最终还是能收到,矛头直接指向Broker端,是不是Broker有瓶颈,处理很慢导致的。
2.2 Broker端处理瓶颈分析
在我的“经验”中,RocketMQ消息发送如果出现瓶颈,通常会返回各种各样的Broker Busy,而且可以通过跟踪Broker端写入PageCache的数据指标来判断Broker是否遇到了瓶颈。
grep "PAGECACHERT" store.log
得到的结果类似如下截图: 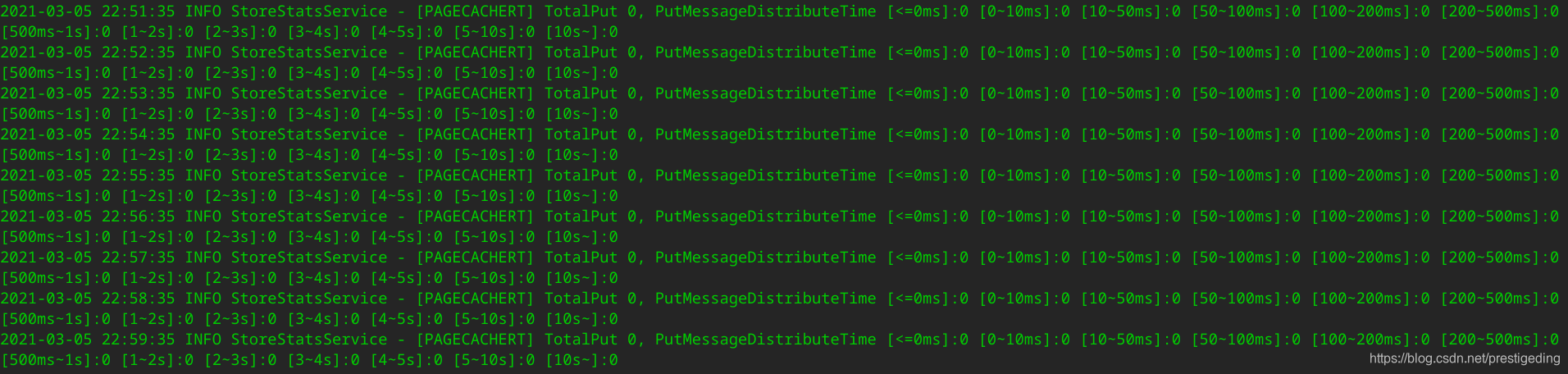
温馨提示:上图是我本机中的截图,当时分析问题的时候,MQ集群中各个Broker中这些数据,写入PageCache的时间没有超过100ms的。
正是由于良好的pagecache写入数据,根据如下粗糙的网络交互特性,我提出将矛盾点转移到网络方面: 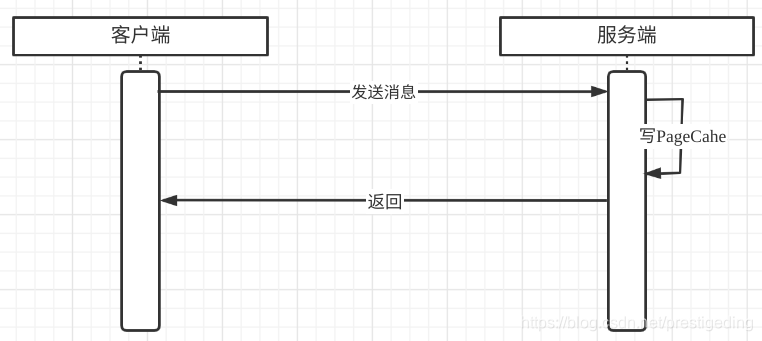 并且我还和业务方确定,虽然消息发送返回超时,但消息是被持久化到MQ中的,消费端也能正常消费,网络组同事虽然从理论上来说局域网不会有什么问题,但鉴于上述现象,网络组还是开启了网络方面的排查。
并且我还和业务方确定,虽然消息发送返回超时,但消息是被持久化到MQ中的,消费端也能正常消费,网络组同事虽然从理论上来说局域网不会有什么问题,但鉴于上述现象,网络组还是开启了网络方面的排查。
温馨提示:最后证明是被我带偏了。
2.3 网络分析
通常网络分析有两种手段,netstat 与网络抓包。
2.3.1 netstat查看Recv-Q与Send-Q
我们可以通过netstat重点观察两个指标Recv-Q、Send-Q。 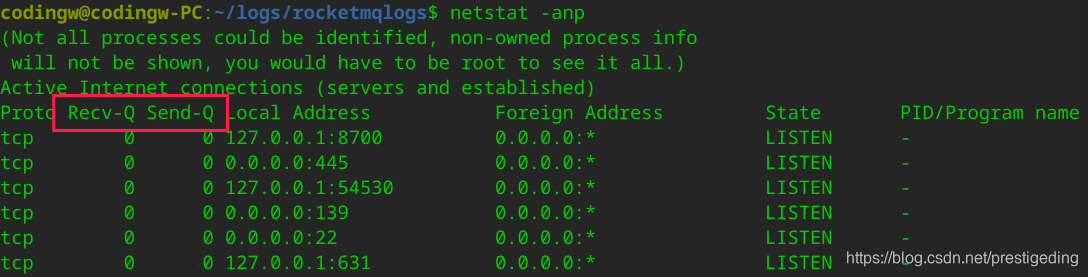
-
Recv-Q tcp通道的接受缓存区
-
Send-Q
tcp通道的发送缓存区
在TCP中,Recv-Q与Send-Q的作用如下图所示: 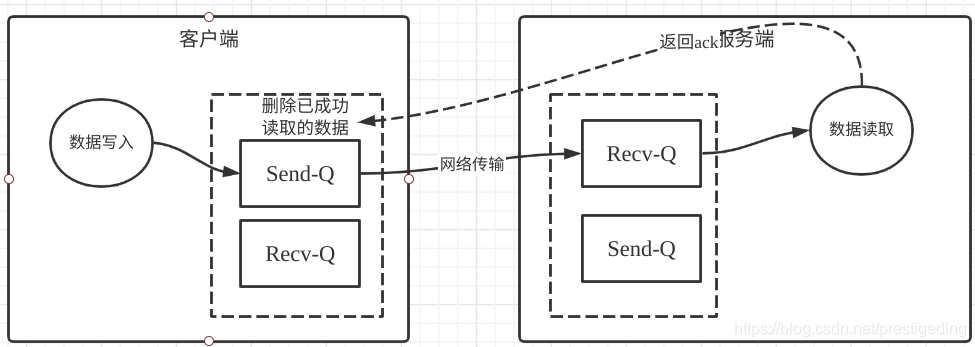
- 客户端调用网络通道,例如NIO的Channel写入数据,数据首先是写入到TCP的发送缓存区,如果发送发送区已满,客户端无法继续向该通道发送请求,从NIO层面调用Channel底层的write方法,会返回0,表示发送缓冲区已满,需要注册写事件,待发送缓存区有空闲时再通知上层应用程序可以发消息。
- 数据进入到发送缓存区后,接下来数据会随网络到达目标端,首先进入的是目标端的接收缓存区,如果与NIO挂钩的化,通道的读事件会继续,应用从接收缓存区中成功读取到字节后,会发送ACK给发送方。
- 发送方在收到ACK后,会删除发送缓冲区中的数据,如果接收方一直不读取数据,那发送方也无法发送数据。
网络同事分布在客户端、MQ服务器上通过每500ms采集一次netstat ,经过对采集结果进行汇总,出现如下图所示: 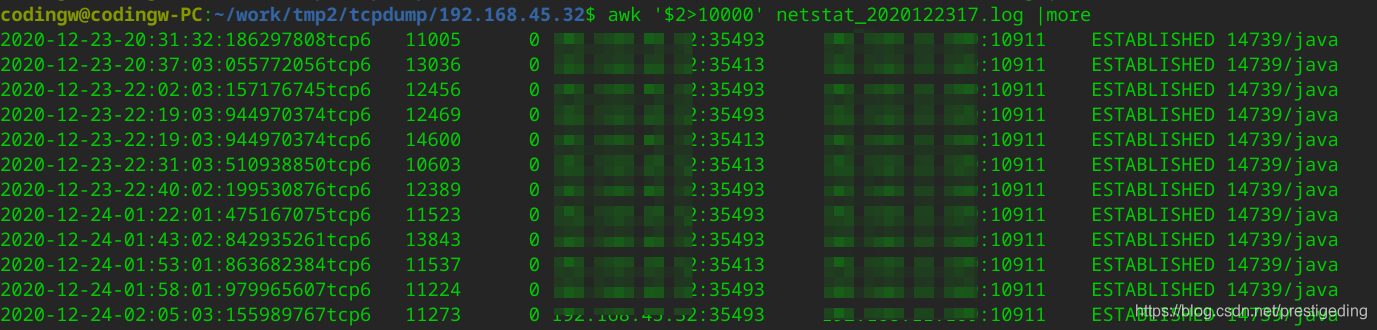 从客户端来看,客户端的Recv-Q中会出现大量积压,对应的是MQ的Send-Q中出现大量积压。
从客户端来看,客户端的Recv-Q中会出现大量积压,对应的是MQ的Send-Q中出现大量积压。
从上面的通讯模型来看,再次推断是否是因为客户端从网络中读取字节太慢导致的,因为客户端为虚拟机,从netstat 结果来看,疑似是客户端的问题(备注,其实最后并不是客户端的问题,请别走神)。
2.3.2 网络转包
网络组同事为了更加严谨,还发现了如下的包: 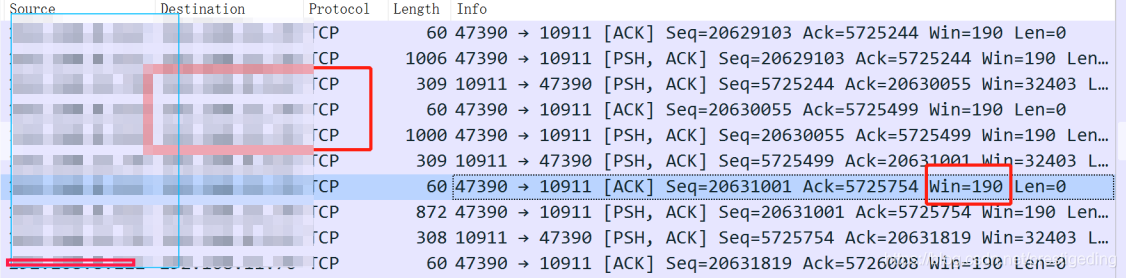 这里有一个问题非常值得怀疑,就是客户端与服务端的滑动窗口只有190个字节,一个MQ消息发送返回包大概有250个字节左右,这样会已响应包需要传输两次才能被接收,一开始以为这里是主要原因,但通过其他对比,发现不是滑动窗口大于250的客户端也存在超时,从而判断这个不是主要原因,后面网络同事利用各种工具得出结论,网络不存在问题,是应用方面的问题。
这里有一个问题非常值得怀疑,就是客户端与服务端的滑动窗口只有190个字节,一个MQ消息发送返回包大概有250个字节左右,这样会已响应包需要传输两次才能被接收,一开始以为这里是主要原因,但通过其他对比,发现不是滑动窗口大于250的客户端也存在超时,从而判断这个不是主要原因,后面网络同事利用各种工具得出结论,网络不存在问题,是应用方面的问题。
想想也是,毕竟是局域网,那接下来我们根据netstat的结果,将目光放到了客户端的读性能上。
2.4 客户端网络读性能瓶颈分析
为此,我为了证明读写方面的性能,我修改了RocketMQ CLient相关的包,加入了Netty性能采集方面的代码,其代码截图如下:  我的主要思路是判断客户端对于一个通道,每一次读事件触发,一个通道会进行多少次读取操作,如果一次读事件触发,需要触发很多次的读取,说明一个通道中确实积压了很多数据,网络读存在瓶颈。
我的主要思路是判断客户端对于一个通道,每一次读事件触发,一个通道会进行多少次读取操作,如果一次读事件触发,需要触发很多次的读取,说明一个通道中确实积压了很多数据,网络读存在瓶颈。
但令人失望的是客户端的网络读并不存在瓶颈,部分采集数据如下所示:  通过awk命令对其进行分析,发现一次读事件触发,大部分通道读两次即可将读缓存区中的数据抽取成功,读方面并不存在瓶颈,对awk执行的统计分析如下图所示:
通过awk命令对其进行分析,发现一次读事件触发,大部分通道读两次即可将读缓存区中的数据抽取成功,读方面并不存在瓶颈,对awk执行的统计分析如下图所示: 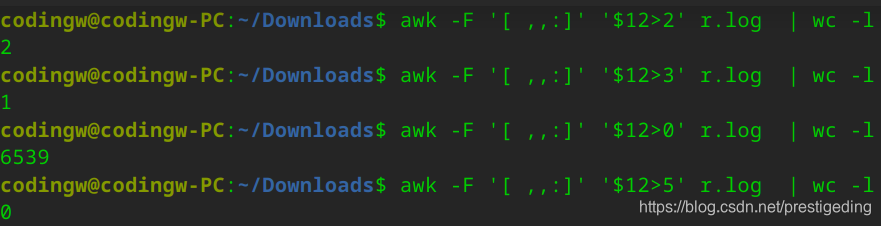 那矛头又将指向Broker,是不是写到缓存区中比较慢呢?
那矛头又将指向Broker,是不是写到缓存区中比较慢呢?
2.5 Broker端网络层面瓶颈
经过上面的分析,Broker服务端写入pagecache很快,维度将响应结果写入网络这个环节并未监控,是不是写入响应结果并不及时,大量积压在Netty的写缓存区,从而导致并未及时写入到TCP的发送缓冲区,从而造成超时。
笔者本来想也对其代码进行改造,从Netty层面去监控服务端的写性能,但考虑到风险较大,暂时没有去修改代码,而是再次认真读取了RocketMQ封装Netty的代码,在此次读取源码之前,我一直以为RocketMQ的网络层基本不需要进行参数优化,因为公司的服务器都是64核心的,而Netty的IO线程默认都是CPU的核数,但在阅读源码发现,在RocketMQ中与IO相关的线程参数有如下两个:
- serverSelectorThreads 默认值为3。
- serverWorkerThreads 默认值为8。
serverSelectorThreads,在Netty中,就是WorkGroup,即所谓的IO线程池,每一个线程池会持有一个NIO中的Selector对象用来进行事件选择,所有的通道会轮流注册在这3个线程中,绑定在一个线程中的所有Channel,会串行进行读写操作,即所有通道从TCP读缓存区,将数据写到发送缓存区都在这个线程中执行。
我们的MQ服务器的配置,CPU的核属都在64C及以上,用3个线程来做这个事情,显然有点太“小家子气”,该参数可以调优。
serverWorkerThreads,在Netty的线程模型中,默认情况下事件的传播(编码、解码)都在IO线程中,即在上文中提到的Selector对象所在的线程,为了降低IO线程的压力,RocketMQ单独定义一个线程池,用于事件的传播,即IO线程只负责网络读、写,读取的数据进行解码、写入的数据进行编码等操作,单独放在一个独立的线程池,线程池线程数量由serverWorkerThreads指定。
看到这里,终于让我心潮澎湃,感觉离真相越来越近了。参考Netty将IO线程设置为CPU核数的两倍,我第一波参数优化设置为serverSelectorThreads=16,serverWorkerThreads=32,在生产环境进行一波验证。
经过1个多月的验证,在集群机器数量减少(双十一之后缩容),只出现过极少数的消息发送超时,基本可以忽略不计。
温馨提示:关于Netty线程模型的详解,可以参考 图解Netty线程模型

本文详细介绍了笔者排查MQ发送超时的精力,最终定位到的是RocketMQ服务端关于网络通信线程模型参数设置不合理。
之所以耗费这么长时间,其实有值得反思的地方,我被我的“经验”误导了,其实以前我对超时的原因直接归根于网络,理由是RocketMQ的写入PageCache数据非常好,基本都没有超过100ms的写入请求,以为RocketMQ服务端没有性能瓶颈,并没有从整个网络通信层考虑。
好了,本文就介绍到这里了,关注、点赞、留言是对我最大的鼓励。
掌握一到两门java主流中间件,是敲开BAT等大厂必备的技能,送给大家一个Java中间件学习路线,助力大家实现职场的蜕变。
最后分享笔者一个硬核的RocketMQ电子书,您将获得千亿级消息流转的运维经验。 
获取方式:RocketMQ电子书。
温馨提示,本文首发个人网站:https://www.codingw.net
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK