

[Reading] Rich feature hierarchies for accurate object detection and semantic se...
source link: https://blog.nex3z.com/2021/04/08/reading-rich-feature-hierarchies-for-accurate-object-detection-and-semantic-segmentation/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

[Reading] Rich feature hierarchies for accurate object detection and semantic segmentation
Author: nex3z 2021-04-08
Rich feature hierarchies for accurate object detection and semantic segmentation (2013.11)
Contents [show]
文章的主要贡献有:
- 提出了一种将卷积神经网络(CNN)用于目标检测的方法,称为 R-CNN(Regions with CNN features)。先通过 selective search 生成一系列候选区域(region proposal),然后再使用 CNN 对候选区域进行特征提取,接着使用 SVM 对提取到的特征向量进行分类。
- 提出了一种在数据不足的情况下训练高容量 CNN 的方法。先在较大的辅助数据集上进行有监督的预训练,再在较小的目标数据集上进行微调。
- 使用边界框回归(bounding-box regression)对预测的边界框进行进一步微调,提高定位的精度。
针对目标检测任务,文章提出了两点洞察:
- 可以在候选区域上,使用高容量的 CNN 来对目标进行识别和分割;
- 带标记的数据不足时,可以先在辅助问题上进行有监督的预训练,再在领域特定问题上进行微调(fine-tuning),可以显著提升效果。
由这两点洞察,文章结合候选区域和 CNN,提出了一种称为 R-CNN 的目标检测算法,其性能较之前最佳算法有了大幅提升。
在目标检测问题中,要对目标进行识别和定位。解决定位问题的一种方法是将定位的一种方法是将定位问题看成是回归问题,但在实践中效果不佳;另一种方法是使用滑窗(sliding-window),但在 CNN 中,高层的感受野非常大,滑窗步长对应原图的像素间隔也很大,使用滑窗难以进行精确定位。
为解决定位问题,文章提出的方法是使用区域进行识别。在测试时,先对输入图像生成约 2000 个类别无关的候选区域,再通过 CNN 从每个区域中提取固定长度的特征向量,最后使用类别相关的线性 SVM 对候选区域进行识别。每个候选区域可能有不同的尺寸,而 CNN 的输入尺寸是固定的,文章通过简单的仿射图像变形(affine image warping)来将候选区域图像调整至 CNN 的输入尺寸。
目标检测问题的另一个挑战是标记数据太少,不足以训练 CNN。针对此种情况的一般做法是先使用无监督的预训练,再使用有监督的微调。文章使用的方法是先在一个很大的辅助数据集(ILSVRC)上进行有监督的预训练,然后再使用小数据集(PASCAL)进行领域特定的微调,获得了很好的效果,证明这是一种在数据不足的情况下训练高容量 CNN 的有效范式。
通过错误分析,文章指出 R-CNN 的主要错误模式为定位错误,通过添加一个简单的边界框(bounding-box)回归,大幅降低了定位错误。
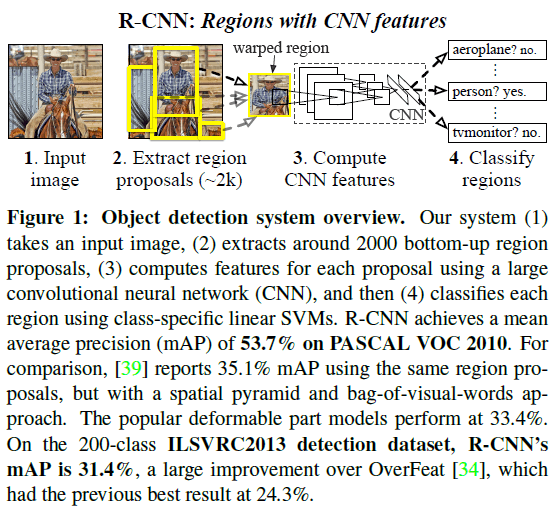 Figure 1
Figure 1R-CNN 也存在一些不足之处,成为之后改善的主要方向,包括:
- CNN 的输入尺寸是固定的,而候选区域具有不同的尺寸,将候选区域通过仿射变换调整到固定尺寸,会让图像发生扭曲。
- CNN 对每个候选区域独立地进行特征提取,效率较低。候选区域的重叠部分是可以共享计算的。
- 要对大量候选区域进行特征提取,数据量很大需要磁盘存储,效率较低。
- 整个检测流程包括候选区域生成、候选区域特征提取、SVM 分类、边界框回归多个步骤,训练和预测都比较复杂。
2. R-CNN
2.1. 模块设计
2.1.1. 候选区域
R-CNN 进行识别的第一步是生成候选区域。生成候选区域的方法有很多,且 R-CNN 对生成候选区域的方法不可知,并不依赖特定的方法。文章使用了选择性搜索(selective search)来生成候选区域。
2.1.2. 特征提取
文章使用 AlexNet 对候选区域进行特征提取。将候选区域缩放至 227×227 像素的 RGB 图像后,通过 5 个卷积层和 2 个全连接层,得到长度为 4096 的特征向量。一些图像示例如 Figure 2。
 Figure 2
Figure 22.2. 测试时检测
在测试时,先使用 selective search 在测试图像上生成约 2000 个候选区域,将区域尺寸变换为 CNN 输入尺寸后,通过 CNN 计算特征。对每个类别,训练一个 SVM 对 CNN 输出的特征向量进行打分。得到图像中所有区域的分数后,再对每个类别独立地使用 NMS(non-maximum suppression),即如果某个区域与具有更高分数的区域的 IoU(intersection-overunion)超过门限,则拒绝该区域。
文章指出,R-CNN 的计算效率体现在两方面:一是 CNN 的参数被所有类别共享,二是 CNN 输出的特征向量维数比当时的其他方法要低(UVA 检测系统的特征长度为 360k,R-CNN 为 4k,前者比后者大两个数量级)。实际中 R-CNN 检测一张图像的平均耗时为 13s(GPU)和 53s(CPU)。
2.3. 训练
2.3.1. 监督预训练
训练 CNN 时,文章首先在一个很大的辅助训练集(ILSVRC2012)上对 CNN 进行预训练。这个辅助训练集原本是用于图像识别的,只有图像级别的标注,没有位置信息,此时训练 CNN 进行图像识别。
2.3.2. 特定领域微调
之后再在新任务(检测)和新领域(变形后的候选窗)上对网络进行微调。此时需要将原 CNN 最后的 1000 路分类层替换为 (N+1) 路分类层(N 个对象类别,加一个背景类)。
此阶段对正例和负例(背景)的定义为:
- 所有与真实标注框(ground-truth box)的 IoU ≥0.5 的候选框作为正例;
- 其余为负例。
网络使用 SGD 进行训练,每轮迭代中,每个小批量(mini-batch)包含 128 个样本,由均匀采样的 32 个正例窗口和 96 个背景窗口构成。因为正例窗口比背景少得多,这里的采样偏向正例。
2.3.3. 目标类别分类器
文章指出,如果候选区域与真实标注框(ground-truth box)完全重叠,或者完全不重叠,可以明确地判断候选框中有/无目标物体。但对于与真实框部分重叠的候选区域,是否认为其中有目标物体是比较模糊的。文章通过将候选区域与真实标注框的 IoU 与一个门限比较,判断候选区域属于正例还是负例。通过网格搜索,找到了用于判断的最佳 IoU 门限为 0.3,于是得到此阶段对正例和负例(背景)的定义为:
- 只使用真实标注框作为对应类别的正例;
- 将与真实标注框的 IoU<0.3 的候选框作为负例;
- 忽略其余(IoU≥0.3 但非标注框)候选框。
有了 CNN 提取的特征和训练标签,文章为每个类别训练了一个线性 SVM 进行分类。
注意在特定领域微调和目标类别分类器两个阶段中,对正例和负例的定义不同。文章提到,在首先通过搜索确定了训练 SVM 时的最优正负例定义后,曾在 CNN 微调时使用同样的正负例定义,但发现效果没有现在好。文章的假设是微调时的数据十分有限,现在的定义通过将 IoU 在 0.5 到 1 的区域作为正例,引入了一些抖动,同时使得正例的数量增加了 30 倍,可以起到避免过拟合的作用。但文章同时指出,引入的带抖动的样本可能是局部最优的,导致网络没有在准确的位置上进行微调。
文章也尝试了在网络最后直接使用 21 路的 softmax 来分类,但这样导致网络在 VOC 2007 上的 mAP 从 54.2% 下降到 50.9%。文章认为此现象的原因是在进行 CNN 的微调时,训练样本中的正例并没与强调精确的定位,softmax 分类器在这些随机采样的负例上训练。而训练 SVM 时对负例的定义更严格(IoU<0.3)。
2.5. 网络性能
文章给出了网络在 PASCAL VOC 和 ILSVRC2013 的性能分别如 Table 1 和 Figure 3 所示。R-CNN 在 PASCAL VOC 的 mAP 达到了 53.7,与之前的最优算法相比有了大幅提升。
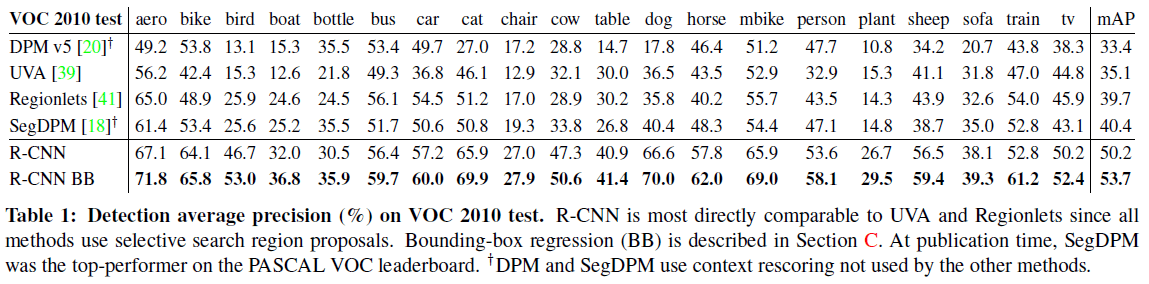 Table 1
Table 1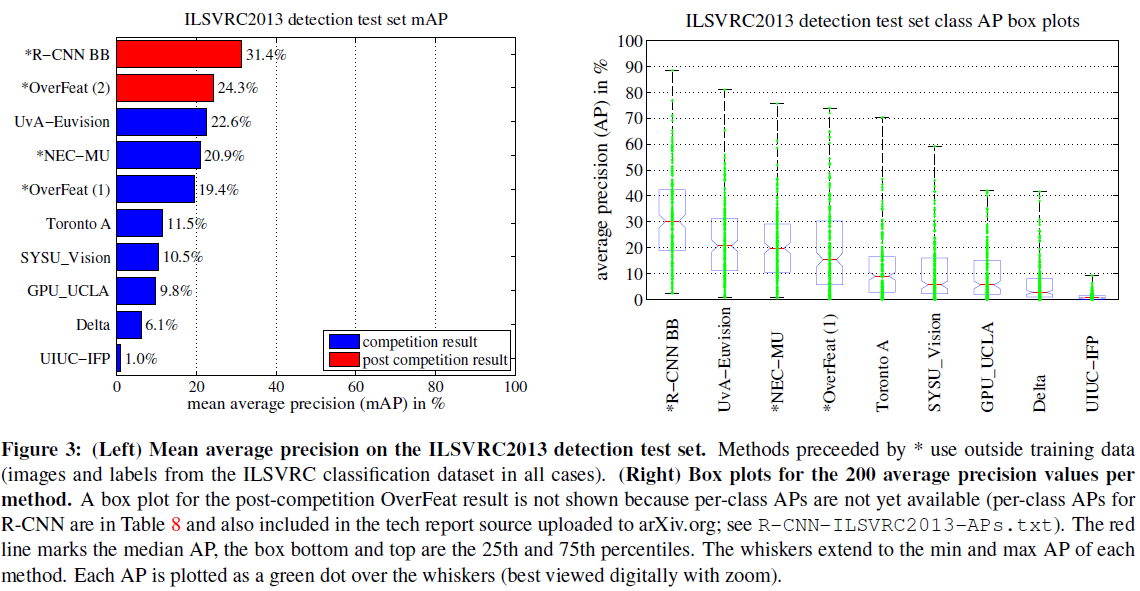 Figure 3
Figure 32.4. 网络架构选择
文章指出对 CNN 的架构选择会对 R-CNN 的检测性能产生大幅影响。R-CNN 中使用了 AlexNet(Table 3 中 T-Net),同时文章也比较了使用 VGG16 (Table 3 中 O-Net)的性能,如 Table 3 所示。
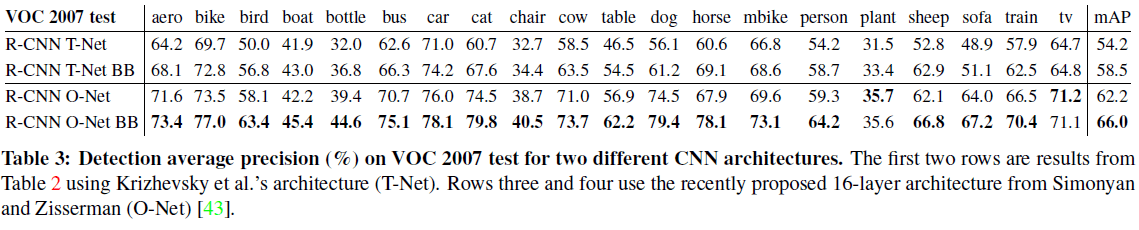 Table 3
Table 32.5. 边界框回归
通过错误分析,文章发现大部分错误都是定位错误。为了提高定位准确度,文章训练了一个线性模型,使用 pool5 的特征,为通过 selective search 得到的候选区域预测一个新的检测窗口。这一方法大幅降低了检测中的错误定位,将 mAP 提升了 3 到 4 个点。
具体来说,边界框回归的输入为 N 对训练样本 {(Pi,Gi)},i=1,…,N,其中 Pi=(Pix,Piy,Piw,Pih) 为候选区域 Pi 边界框中心的像素坐标和宽高(后续省略上标 i)。标注框 G 使用类似的定义,即 G=(Gix,Giy,Giw,Gih)。
边界框回归的目标是学习一种从候选框 P 到真实标注框 G 的变换。文章使用 4 个函数 dx(P)、dy(P)、dw(P)、dh(P) 来描述这种变换:前两个函数表示对 P 中心的尺度不变(scale-invariant)变换,后两个表示对 P 宽高的对数空间变换。对 P 的预测 ˆG 为
ˆGx=Pwdx(P)+PxˆGy=Phdy(P)+PyˆGw=Pwexp(dw(P))ˆGh=Phexp(dh(P))
其中每一个 d∗(P) 函数都是候选区域 P 的 pool5 特征的线性函数,记为 ϕ5(P),于是有 d∗(P)=wT∗ϕ5(P),其中 w∗ 为可学习的模型参数,通过优化下述带正则的最小二乘目标(岭回归)得到
w∗=argmaxw∗N∑i(ti∗–wT∗ϕ5(P))2+λ||w∗||2
对于训练样本 (P,G),回归的目标 t∗ 定义为
tx=(Gx–Px)/Pwty=(Gy–Py)/Phtw=log(Gw/Pw)th=log(Gh/Ph)
在实现过程中,文章发现了两个问题。首先,正则化非常重要,基于验证集,设置 λ=1000。其次,需要注意训练样本 (P,G) 的选择,如果 P 和 G 相距太远,学习 P 到 G 的映射不太实际,也没有意义。对于候选框 P,文章将其分配给与之 IoU 最大的 G,同时要求 P 和 G 的 IoU 要大于一个阈值(文章使用 0.6),否则丢弃 P。
测试时,对候选区域打分后,只通过边界框回归对其进行一次预测。虽然可以再对预测的边界框进行打分,迭代多次,但并没有带来效果提升。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK