

M:N协程原理与设计
source link: https://zhuanlan.zhihu.com/p/362621806
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

M:N协程原理与设计
作者:quintonwang,腾讯 TEG 后台开发工程师
什么是M:N协程?为什么要支持M:N协程?如何设计M:N协程?tRPC-Cpp引入了公司开源组件Flare/fiber作为底层库,本文多角度分析梳理了M:N协程的关键原理和特性。
1 常见线程模型的问题
在高并发编程场景,如互联网后台类业务中,既要保证高性能,也要保持编程的便利性。目前trpc-cpp中支持了2类模型:线程模型、N:1协程。
线程是操作系统的最小调度单元,可以通过系统调用挂起,也可能被操作系统随时抢占打断。以下是常见的各种线程并发模型。
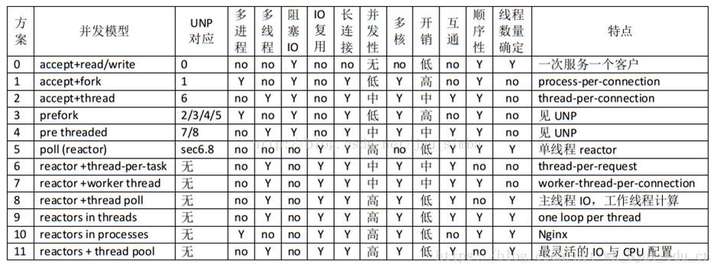
为了支持高并发,多路复用(Window/IOCP,Linux/epoll等)是必须的手段。线程数量过多,会极大地降低系统性能。为此,trpc-cpp中实现了其中2种并发模型,都采取了“有限线程”+“多路复用”的方案。
1.1. IO/Handle分离:方案11
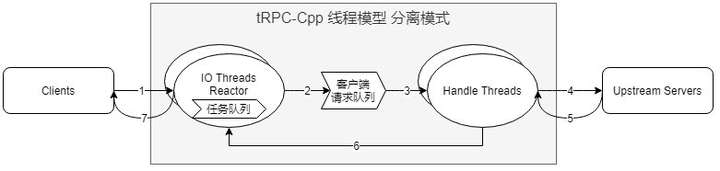
这也是很常见的线程模型,在Thrift、Tars等RPC框架中都有实现。关键特征即在于IO、Handle线程独立,通过队列通信。
- 各个Handle线程很自然地达到负载均衡。
- 各个任务天然隔离,适应任意类型的业务:IO-Bound、CPU-Bound等。
- 一个请求/回复,至少经过2个线程,会引入额外的调度延迟,在低延迟业务中有所不足。IO/Handle之间的通知机制需要良好设计,避免过多唤醒的系统调用。
- 在高并发时,IO/Handle之间的全局队列需要良好的设计,否则可能成为系统瓶颈。
- 由于Handle中提供了Promise/Future风格接口,此处需要额外注意continuation的运行线程控制,另外也需要考虑到CPU-Bound或者阻塞逻辑对continuation的影响,否则业务编程困难。
- 在部分业务场景,合适的IO/Handle线程数量比例难以估算,配置困难。
1.2. IO/Handle合并:方案9
这种线程模型,和传统的高性能框架比较相似,如Nginx、Seastar等,关键特征在于各个工作线程独立运行,消除竞争,追求极致效率。
- 架构简洁可靠:全异步方案,逻辑统一,易于理解。
- 对于NUMA架构天然适配。
- 一个请求/回复,只在一个线程处理,对于低延迟业务友好。
- 可以做到无锁编程。
- 不允许阻塞代码,否则可能引起问题,所以对于业务开发门槛稍高。对于CPU-Bound业务同样不合适。
- 同一个线程中的各个任务容易互相干扰。
1.3. N:1协程
N:1协程也即在多个协程协作运行在一个系统线程上,当然系统线程可以有多个。基于封装层次,分为:非hook、部分hook、全面hook。 目前常见的C++协程实现都是这种,如libco,spp协程等。
trpc-cpp在上述IO/Handle分离线程模型的Handle线程中支持N:1协程的子模式。协程库实现来自spp框架,是部分hook,也即网络相关的系统调用。默认是没有开启的,需要用户主动调用spp提供的网络接口。
这个方案很大的优点是,可以完全无锁编写同步风格代码,对于普通的互联网后台业务(IO-Bound型)编程是很友好的。
但是也有一个明显的缺点,各个线程之间无法均衡任务,导致一个线程中的某个协程运行过久,会影响到本线程的其他协程,也即不适合CPU-Bound型业务。这与上述IO/Handle合并模式相似。
2 M:N协程设计
2.1. Flare/fiber简介
为了综合上述各种方案的优缺点,也即兼顾易用性和实用性,取得一种折中平衡的效果,我们可以考虑在协程中引入“Work-Stealing”机制,也即M:N协程(M个用户协程对应N个系统线程,为了区别于上述的N:1协程)。
凡事有利弊,引入了线程之间的竞争,导致理论上的极限性能会不如上述两种无竞争的模型。不过通过精心的设计,可以做到利远大于弊。这体现了一种设计上的权衡。而Golang/goroutine、brpc/bthread、libgo正是类似的思想。
Flare/fiber是公司内部开源协同的M:N协程库,从设计到实现,都体现了独特的思考。主要特性如下:
- 多个线程间竞争共享fiber队列,在精心设计下可以达到较低的调度延迟。目前调度组大小(组内线程数)限定为8~15之间。
- 为了减少竞争,提升多核扩展性,设计了多调度组机制,调度组个数以及大小可以配置。
- 为了减少极端情况下的不均衡性,调度组间支持fiber窃取:分为NUMA Node内组间窃取,跨NUMA Node组间窃取,并支持分别设置窃取系数,以控制窃取倾向策略。
- 完善的同步原语。
- 与pthread良好的互操作性。
- 支持Future风格API。
trpc-cpp基于开源协同的精神,引入fiber作为底层的M:N协程库。以下对其关键设计和实现做一些分析。
2.2. 运行框架
- 为了适应NUMA架构,flare/fiber支持多个调度组(SchedulingGroup)。图中最左边的组显示了完整的运行调用关系。其他的组有所简化,为了展示组间的fiber窃取(Work-Stealing)。
- 图中数量确定的组件:Main Thread(全局唯一),master fiber(FiberWorker内唯一),RunQueue(SchedulingGroup内唯一),TimerWorker(SchedulingGroup内唯一)。其他组件数量都只是示意(可配置或者动态改变)。
2.3. 调度组
为了更好地适配NUMA架构,fiber支持调度组。调度组和Node的对应比例为N:1。如果为UMA/SMP架构,或者设置为对NUMA不感知,那么相当于全局只有1个Node。
一个调度组包含:
- 一个数据结构RunQueue:有界无锁队列,用来存放所有待运行(Ready)的fiber。
- 一组线程FiberWorker:从RunQueue中获取fiber执行。
- 一个线程TimerWorker:按需生产定时任务的fiber。
2.4. fiber调度
fiber有4种状态,其转换关系如下:
上图中的Waitable是fiber环境的同步原语(见后文介绍),其实现是一个侵入式的双向链表,用于挂载阻塞的fiber。
一个fiber用FiberEntity表示,内存空间布局如下:
+--------------------------+ <- Stack bottom
| fiber control block |
+--------------------------+ <- 512 byte
| ... |
| ... | <- (Used stack space)
| ... |
+--------------------------+ <- Stack top.
| ... |
| ... | <- (Unused stack space)
| ... |
+--------------------------+ <- Stack limit
| guard page (opt) | <- (User fiber only)
+--------------------------+ <- Stack limit + PAGE_SIZE
Stack Limit即协程栈大小,可由用户指定。
fiber支持gdb调试插件,为了枚举fiber,采用暴力线性搜索内存空间的策略。此结构会对齐1MB内存边界分配,以减小插件搜索地址空间。fiber启动后其栈底(高地址,也即FiberEntity的起始地址)会存放fiber ID和预设的MagicNumber,便于gdb插件识别。栈底+512B处,存放fiber的调用栈,阻塞的fiber则还包含其CPU相关寄存器状态。
2.5. FiberWorker工作流程
任务调度主要是针对RunQueue(待运行队列)的生产和消费,这种场景我们通常会想到使用条件变量等方式。但是这里有如下考虑:
- 条件变量则避免不了一个组内的全局锁,会存在较高的竞争,而且RunQueue的无锁设计也没有意义了(当然这里是反果为因了)。
- 过多地系统调用(唤醒/睡眠),会极大地影响性能。如果完全轮询(类似DPDK),确实可以做到低延迟,但是太过浪费系统资源。
于是,fiber采用了一种折中平衡策略,用至多2个线程并行轮询(Spinning,一次最多10000个CPU周期)。
- 在获取fiber时,如果取到fiber则直接运行。如果没取到fiber并且轮询线程不足2个,则进入轮询状态。
- 如果一个轮询线程能取到fiber,则在运行此fiber之前,唤醒另外一个线程。轮询超时则睡眠。
- 在生产fiber时,如果存在轮询线程,则直接让他退出轮询去取fiber。否则唤醒一个线程。
当然,在上述选取轮询线程/睡眠线程中,都按照固定编号排序,选择第一个(LSB)可选项。这是由于多个fiber很可能是协作式任务,将他们集中在固定的线程上运行(FiberWorker可以配置绑核,而且操作系统也会更倾向把相同的线程运行在固定的CPU),会提高CPU Cache的热度。
2.6. fiber窃取
如果fiber创建属性指定不允许窃取,那么fiber只会在初始的调度组内执行,否则可能由其他组窃取。按照性能的不同,窃取分为两种:
- NUMA Node内:性能与正常调度相同。纯粹为了平衡组间负载,默认开启。
- NUMA Node间:性能较差。默认不开启。
不论是组内还是组间,其原理是一样的,只是工作线程acquire的目标RunQueue不同而已。而且其算法也相同,只是窃取频率系数不同,可以参数指定。其算法不复杂,与步长算法类似,这里略过。
2.7. 定时器
TimerWorker是一个独立的系统线程,支持两种定时任务:
每个FiberWorker维护一个thread_local的定时器数组。每个定时器对应一个uint64的ID,也即Entry对象地址。
TimerWorker中维护一个定时器的优先级队列。循环读取各个FiberWorker的数组并加入优先级队列。然后按照当前时刻依次执行。然后睡眠(阻塞在条件变量)到下一个定时器超时。
- 添加定时器:创建定时器对象,标记启用,并放在thread_local数组,更新最早超时时间。如果FiberWorker正在睡眠,则通知唤醒。
- 删除定时器:直接把启动标记清除即可。
通常来说,定时器的到期回调会启动一个fiber来执行真正的任务。不过并非必须。
这里之所以采用一个单独的系统线程来实现定时器,一方面是保持FiberWorker的纯粹性,一方面也避免了阻塞操作长期占用一个FiberWorker线程。
2.8. 上下文切换
不论是线程/fiber,其运行机制是相似的,只不过线程的上下文切换由系统调用/操作系统抢占触发,而fiber由其主动触发。
上下文切换,也即保存原执行逻辑的运行环境,并恢复目的执行逻辑的运行环境。而运行环境通常包括:CPU(寄存器:IP + Flags + Callee-Saved)+ 内存(栈:BP + SP)。
这部分工作,目前可以采用成熟的开源库实现,如 glibc/ucontext,boost::context 等。fiber基于boost::context定制化实现。
下图是其在内存层面的视角:
下图是其在执行过程方面的视角(示例):
为了方便管理/编码,把原始线程(FiberWorker)也用fiber表示,称作master fiber,只不过其运行环境就是操作系统分配的线程栈,于是不需要为其分配额外的内存保存其运行环境。
master fiber不参与调度(也即从不入队),每个FiberWorker维护一个threal_local对象,其进出口也即对应到前述代码行:fiber→Resume()。
3 fiber与线程的互操作性
3.1. 同步原语
在更高的层次看,fiber和线程其实是类似的,所以fiber也提供了一套同步原语:Mutex,ConditionVariable,Latch。另外还有:FiberLocal,this_fiber等。
一段代码在fiber和线程中运行的区别,也正是上述这些。为了明确概念,阻塞分为2种:线程阻塞,fiber阻塞。
特别注意下列事项:
- 由于FiberWorker个数有限,如果大量fiber线程阻塞、或者长时间运行,会导致其他fiber响应缓慢。
- 线程mutex(std::mutex)要求在同一个线程中加锁、解锁,否则为未定义行为。在fiber中对线程mutex加锁后,不能触发fiber阻塞,否则可能由于fiber调度到其他FiberWorker运行导致未定义行为。
3.2. Promise/Future
严格来说,Promise/Future只是一种接口封装风格,与fiber等运行模型是无关的。不过在flare/fiber中,提供了一种良好的实现并与fiber很好的配合起来。
Promise/Future的实现没有实现任何阻塞接口,对于用户来说,最重要的接口即为:Promise<T...>::SetValue(T&&...) 以及 Future<T...>::Then(F&&)。
Promise/Future本身是线程安全的,也是fiber安全的,不过在编码时,要额外注意continuation的运行环境。取决于生产端(Promise.SetValue)和消费端(Future.Then)的时机,后来者会直接运行continuation。也即如果生产端和消费端运行在不同环境,那么continuation可能运行在其中任意一个。这个问题在链式调用中,可能更加复杂。在了解清楚原理之后,有几种方式可以“简单地”保持“正确性”(但不意味着只能这样用):
- 保证continuation代码不依赖特定的运行环境
- 生产端和消费端始终在同一种环境(相对概念)中使用:
- 在同一个fiber:实践中很少使用
- 在同一个线程:实践中往往依赖于事件循环的线程运行模型,如seastar等
- 跨fiber:注意fiber安全
- 跨线程:注意线程安全
- 跨环境简单传值:不使用continuation,而是同步等待结果,然后继续执行后续逻辑。请见下。
3.3. 传值
如果需要获取Future的值,提供额外的工具函数实现。针对fiber和线程环境,分别提供了不同版本。其中分别用了fiber和线程的同步原语实现。
这样的设计就可以做到fiber和线程之间的互相传值。这段代码展示了从线程向fiber传值,其他传值(fiber->fiber,线程->线程,fiber->线程)也是类似:
void EchoServiceImpl::Echo(...) {
Promise<int, std::string> p;
auto future = p.GetFuture();
auto http_cb = [p = std::move(p)] (int status, std::string body) mutable {
p.SetValue(status, std::move(body));
};
// 回调函数运行在外部线程中
AsyncHttpGet(req.uri(), std::move(http_cb));
// 在fiber中同步等待,不阻塞底层线程,只是挂起本fiber,由上述回调唤醒
auto&& [status, body] = BlockingGet(&future);
if (status != 200) {
FLARE_LOG_WARNING("HTTP request failed with status {}.", status);
} else {
FLARE_LOG_INFO("Received HTTP response: {}", body);
}
}
3.4. 执行流工具
Promise/Future的强大性,体现在链式调用。通过组合操作,可以表达出很多常用的并联、串联逻辑,也称作执行流。
已经提供了一些常用的执行流工具,用户也可以自行实现其他的工具:
- Split
- WhenAll
- WhenAny
- Repeat
- RepeatIf
4 性能与思考
4.1. 性能测试
性能包含多种指标,如吞吐量(QPS)、平均延迟、尾延迟(P99/P999)、最小延迟、最大延迟等。
不同的业务场景,对于性能的评价可能是不同的。以通常的互联网后台系统而言,我们往往最关注的是:吞吐量、平均延迟、尾延迟。
M:N的设计初衷,即在于,引入线程竞争,适度牺牲性能,换取业务实用性。而其实用性最主要体现在,对长尾请求的抗干扰性。此外,和N:1协程一样,同步编程范式也极大地提高了易用性。
为了衡量fiber的性能,我们分别进行了如下测试:
- 尾延迟测试:和其他线程模型对比,观察的长尾请求的抗干扰性。
- 多核测试:观察不同CPU核数情况下的性能表现。
- NUMA测试:测试是否感知NUMA、是否分调度组,对性能的影响。
测试结果表明,M:N的各种优缺点都是完全符合设计预期的。而测试数据比较繁杂,就不做具体展示了。
4.2. 其他思考
- 在高并发编程场景,为了保证性能,非阻塞是必须的手段,但是归根到底,还是多路复用,也即依赖内核。在用户层能做的,通常表现为各种接口风格,却并非影响性能的关键。
- 前述的多种模型,其实是各有特点,并非一定有高低之分,运行场景也很重要:
- 设计优良的N:1协程(boost::fiber,当然也支持M:N协程)和多线程reactor(如seastar)在IO-Bound型业务应该具有比较明显的性能优势。
- reactor+线程池(如boost::asio),和M:N协程(brpc,flare/fiber)牺牲了一些性能,但是具有更广泛地适应性。
- 对于用户编程的便利性而言,其实最重要的是有一个统一的生态,各种库能够在统一的逻辑下互相调用。由于C++的多种编程范式和历史原因,缺少易用统一的生态,甚至没有任何网络标准库,导致各自造轮子互不兼容,这是C++目前最大的问题了。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK