
6

信息论篇-第一次上机作业,你好!
source link: https://blog.csdn.net/qq_45014265/article/details/115410269
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


信息论第一次上机作业
1.图像信源熵的求解
读入一幅图像,实现求解图片信源的熵。
'''
1.图像信源熵的求解
读入一幅图像,实现求解图片信源的熵。
'''
import math
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
#获取一个数字数组中的数组,以np.matrix形式输出,原数组
def get_strlist_data(lines): # 在这里lines = f.readlines()
'''
:param lines: 输入的是字符串形式,这样更为方便转化
:return: 字符串对应的列表list形式
'''
sizeArry = [] # 创建一个list,用来存储数据
for line in lines:
line = line.replace("\n", "")
# 因为读出来的数据每一行都有一个回车符,我们要删除
line = float(line)
# 将其转换为整数
sizeArry.append(line)
# 转换为numpy 可以识别的数组
return np.asarray(sizeArry)
def get_file_data(path):
'''
:param path: 需要读取的图片所在路径
:return: 得到字符串形式的数组
'''
# 首先打开文件从文件中读取数据
f = open(path) # path存储的是我们的目标文件所在的位置
# 我们先打开目标文件然后读取出这个文件中的每一行
lines = f.readlines()
return get_strlist_data(lines)
#图像信息矩阵化(灰度图片)
def ImagetoArray(filename):
im = Image.open(filename)
#im.show()
# 图片信息矩阵化
data = np.asarray(im)
data = np.array(data, dtype='float')
return data
#三色道分离操作
def ImagetoArrayRGB(filename,channel):
data=ImagetoArray(filename)
if channel=='r':
return data[:,:,0]
if channel=='g':
return data[:,:,1]
if channel=='b':
return data[:,:,2]
def Entropy(Mat):
M=np.size(Mat)#数据总量
Census=np.zeros(255)
for i in range(np.shape(Mat)[0]):
for j in range(np.shape(Mat)[1]):
Census[int(Mat[i][j])-1]+=1
sum=0
for i in Census:
if i == 0:
continue
else:
sum+=i*math.log(i)
entropy=-sum/M+math.log(M)
return entropy
if __name__=="__main__":
Path='菲谢尔1.jpg'
R=ImagetoArrayRGB(Path,'r')
G=ImagetoArrayRGB(Path,'g')
B=ImagetoArrayRGB(Path, 'b')
print(Entropy(R)+Entropy(G)+Entropy(B))

上图中的菲谢尔的信息量为:
15.555038790999852
2.一个发射器发出A,B,C三个消息
一个发射器发出A,B,C三个消息,他们的先验概率和条件概率分别为:
iABCP(i)9/2716/272/27
条件概率为:
P(i/j)ABCA04/51/5B1/21/20C1/22/51/10
Q1:求信源熵。
Q2:求信源最大熵。
Q3:求剩余度。
'''
2.一个发射器发出A,B,C三个消息,他们的先验概率和条件概率分别为:
i A B C
P(i) 9/27 16/27 2/27
0 4/5 1/5
1/2 1/2 0
1/2 2/5 1/10
'''
import math
def SourceEntropy(a,A):
'''
用于计算信源熵值(条件熵)
:param a: 信源的先验概率向量
:param A:条件概率
:return: 信源熵
'''
sum=0
l=len(a)#a的元素个数,对应A的行数
for i in range(l):
for j in A[i]:
if j==0:
continue
else:
sum+=a[i]*j*math.log(j)
return -sum
if __name__=="__main__":
a=[9/27,16/27,2/27]
A=[[0,4/5,1/5],[1/2,1/2,0],[1/2,2/5,1/10]]
print('第一问答案:信源熵为'+str(SourceEntropy(a,A)))
B=[[1/3,1/3,1/3],[1/3,1/3,1/3],[1/3,1/3,1/3]]
print('第二问答案:信源最大熵为' + str(SourceEntropy(a, B)))
print('第三问答案:剩余度为'+str(1-SourceEntropy(a,A)/SourceEntropy(a, B)))
结果展示:
第一问答案:信源熵为0.6474323513133665
第二问答案:信源最大熵为1.0986122886681093
第三问答案:剩余度为0.4106816772473262
3.互信息量和平均互信息量的求解

#Q3 互信息量和平均互信息量的求解
import math
import numpy as np
def MutualInformation(Px,Py,Pxy):
return Pxy*math.log2(Pxy/(Px*Py))
def AveMutualInformation(PM):
PM=PM/sum(sum(PM))
Px=[sum(PM[i][:]) for i in range(np.shape(PM)[0])]
Py=[sum(PM[:][i]) for i in range(np.shape(PM)[1])]
s=0
for i in range(len(Px)):
for j in range(len(Py)):
if Px[i]==0 or Py[j]==0 or PM[i][j]==0:
continue
else:
s+=MutualInformation(Px[i],Py[j],PM[i][j])
return s
if __name__=='__main__':
ProM=np.array([[1/2,1/2],[1/2,1/2]])
print('矩阵对应的互信息量为'+str(AveMutualInformation(ProM)))
print(MutualInformation(1/2,1/2,1))
结果展示:
矩阵对应的互信息量为0.0
2.0
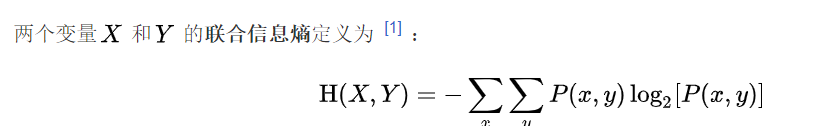
4.联合熵的求解
已知信源X和信源Y的联合概率,求解X和Y的联合熵。
#Q4 已知信源X和信源Y的联合概率,求解X和Y的联合熵。
import numpy as np
import math
def JointEntropy(PM):
#先进行归一化
PM=PM/sum(sum(PM))
s=0
for i in PM:
for j in i:
s+=j*math.log2(j)
return -s
if __name__=='__main__':
PM=np.array([[1/2,1/2],[1/2,1/2]])
print('上述概率矩阵对应的联合熵为:'+str(JointEntropy(PM)))
结果展示为:
上述概率矩阵对应的联合熵为:2.0
5.Kraft不等式的分析与判断
给定信源符号个数,码元进制数和码长,判断唯一可译码是否存在。
'''
5.Kraft不等式的分析与判断
给定信源符号个数,码元进制数和码长,判断唯一可译码是否存在
'''
if __name__=="__main__":
NumOfSource=int(input('信源符号个数:'))
Hex=int(input('码元进制数:'))
Length=int(input('码长:'))
if Hex**Length==NumOfSource:
print('存在唯一可译码。')
else:
print('不存在唯一可译码。')
结果展示:
信源符号个数:8
码元进制数:2
码长:3
存在唯一可译码。
信源符号个数:9
码元进制数:2
码长:4
不存在唯一可译码。
6.费诺编码的分析与实现
给定信源各个符号及其发生概率,求解其费诺编码的码字,平均码长和编码效率。
'''
6.费诺编码的分析与实现
给定信源各个符号及其发生概率,求解其费诺编码的码字,平均码长和编码效率
'''
import numpy as np
import math
import re
def Partition(lxh,N):
Norm_lxh=lxh/sum(lxh)
for i in range(len(lxh)):
if sum(Norm_lxh[:i+1])>=1/2:
if abs(sum(Norm_lxh[:i+1])-1/2)>=abs(sum(Norm_lxh[:i])-1/2):
return [[lxh[:i],lxh[i:]],[N[:i],N[i:]]]
else:
return [[lxh[:i+1],lxh[i+1:]],[N[:i+1],N[i+1:]]]
def Tree(lxh,N,filename):
if lxh.size==1:
print(N)
print(N,file=filename)
else:
print(Partition(lxh, N)[1])
print(Partition(lxh,N)[1],file=filename)
for i in range(len(Partition(lxh,N)[0])):
Tree(Partition(lxh,N)[0][i],Partition(lxh,N)[1][i],filename)
def AveLen(P,L):
sum=0
for i in range(len(P)):
sum+=P[i]*L[i]
return sum
def CodeEfficiency(H,L):
return H/L
def Entrify(P):
sum=0
for i in range(len(P)):
if P[i]!=0:
sum+=P[i]*math.log2(P[i])
return -sum
def BiCode(n,k):
#n为长度,k为序号
if k<=2**n:
infor=str(bin(k))
infor=infor[2:]
infor=int((n-len(infor)))*'0'+infor
return infor
else:
raise('编码错误,码树无法生成!')
def FenoCode(Num):
Code=[]
for i in Num:
for k in range(0,int(2**i)):
for j in Code:
if re.match(BiCode(i,k),j) or re.match(j,BiCode(i,k)):
break
else:
Code.append(BiCode(i,k))
break
return Code
if __name__=='__main__':
file='recode.log'
mylog = open(file, mode='w', encoding='utf-8')
N=['A','B','C','D','E','F','G']
A=np.array([1/3,1/4,1/12,1/12,1/12,1/12,1/12])
Num=np.zeros(len(N))
Tree(A,N,mylog)
mylog.close()
with open(file,'r') as f:
Infor=f.read()
for i in range(len(Num)):
Num[i]+=Infor.count(N[i])-1
print('-'*30)
print('码字为:')
Cod=FenoCode(Num)
print(Cod)
for i in range(len(A)):
print(N[i]+' '+str(round(A[i],3))+' '+Cod[i])
print('平均码长为:'+str(round(AveLen(A,Num),3)))
print('编码效率为:'+str(round(Entrify(A)/AveLen(A,Num),3)))
结果展示:
[['A', 'B'], ['C', 'D', 'E', 'F', 'G']]
[['A'], ['B']]
['A']
['B']
[['C', 'D'], ['E', 'F', 'G']]
[['C'], ['D']]
['C']
['D']
[['E', 'F'], ['G']]
[['E'], ['F']]
['E']
['F']
['G']
------------------------------
码字为:
['00', '01', '100', '101', '1100', '1101', '111']
A 0.333 00
B 0.25 01
C 0.083 100
D 0.083 101
E 0.083 1100
F 0.083 1101
G 0.083 111
平均码长为:2.583
编码效率为:0.976
7.二进制哈夫曼编码的分析与实现
给定信源各个符号及其发生概率,求解其二进制哈夫曼编码码字,平均码长,及其编码效率。
'''
7.二进制哈夫曼编码的分析与实现
给定信源各个符号及其发生概率,求解其二进制哈夫曼编码码字,平均码长,及其编码效率。
'''
import numpy as np
import math
import re
def Join(P,N,filename):
if len(N)==1:
return None
else:
P=P/sum(P) #归一化
P, N = (list(t) for t in zip(*sorted(zip(P, N))))
print(N[0], N[1], sep=' ')
print(N[0],N[1],sep=' ',file=filename)
P=[P[0]+P[1]]+P[2:]
#print(P)
N=[N[0]+' '+N[1]]+N[2:]
#print(N)
Join(P,N,filename)
return None
def AveLen(P,L):
s=0
for i in range(len(P)):
s+=P[i]*L[i]
return s
def CodeEfficiency(H,L):
return H/L
def Entrify(P):
sum=0
for i in range(len(P)):
if P[i]!=0:
sum+=P[i]*math.log2(P[i])
return -sum
def BiCode(n,k):
#n为长度,k为序号
if k<=2**n:
infor=str(bin(k))
infor=infor[2:]
infor=int((n-len(infor)))*'0'+infor
return infor
else:
raise('编码错误,码树无法生成!')
def FenoCode(Num):
Code=[]
for i in Num:
for k in range(0,int(2**i)):
for j in Code:
if re.match(BiCode(i,k),j) or re.match(j,BiCode(i,k)):
break
else:
Code.append(BiCode(i,k))
break
return Code
if __name__=='__main__':
mylog = open('recode7.log', mode='w', encoding='utf-8')
P=np.array([0.4,0.2,0.2,0.1,0.1])
M=['a','b','c','d','e']
Join(P,M,mylog)
mylog.close()
Num=np.zeros(len(P))
with open('recode7.log','r') as f:
Infor=f.read()
for i in range(len(Num)):
Num[i]+=Infor.count(M[i])
print('-'*30)
print(Num)
print('码字为:')
Cod = FenoCode(Num)
print(Cod)
for i in range(len(P)):
print(M[i] + ' ' + str(round(P[i], 3)) + ' ' + Cod[i])
print('平均码长为:' + str(round(AveLen(P, Num), 3)))
print('编码效率为:' + str(round(Entrify(P) / AveLen(P, Num), 3)))
结果展示为:
d e
b c
d e a
b c d e a
------------------------------
[2. 2. 2. 3. 3.]
码字为:
['00', '01', '10', '110', '111']
a 0.4 00
b 0.2 01
c 0.2 10
d 0.1 110
e 0.1 111
平均码长为:2.2
编码效率为:0.965
文稿:锦帆远航
代码:锦帆远航
图片:百度图片
你的支持(三连)是航航坚持下去的不懈动力哦!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK