

DolphinDB智臾科技的个人空间
source link: https://my.oschina.net/u/4865736/blog/5005027
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

内存表是DolphinDB数据库的重要组成部分。内存表不仅可以直接用于存储数据,实现高速数据读写,而且可以缓存计算引擎的中间结果,加速计算过程。本教程主要介绍DolphinDB内存表的分类、使用场景以及各种内存表在数据操作以及表结构(schema)操作上的异同。
1. 内存表类别
根据不同的使用场景以及功能特点,DolphinDB内存表可以分为以下四种:
- 常规内存表
- 键值内存表
- MVCC内存表
1.1 常规内存表
常规内存表是DolphinDB中最基础的表结构,支持增删改查等操作。SQL查询返回的结果通常存储在常规内存表中,等待进一步处理。
使用table函数可创建常规内存表。table函数有两种用法:第一种用法是根据指定的schema(字段类型和字段名称)以及表容量(capacity)和初始行数(size)来生成;第二种用法是通过已有数据(矩阵,表,数组和元组)来生成一个表。
使用第一种方法的好处是可以预先为表分配内存。当表中的记录数超过容量时,系统会自动扩充表的容量。扩充时系统首先会分配更大的内存空间(增加20%到100%不等),然后复制旧表到新的表,最后释放原来的内存。对于规模较大的表,扩容的成本会比较高。因此,如果我们可以事先预计表的行数,建议创建内存表时预先分配一个合理的容量。如果表的初始行数为0,系统会生成空表。如果初始行数不为0,系统会生成一个指定行数的表,表中各列的值都为默认值。例如:
//创建一个空的常规内存表
t=table(100:0,`sym`id`val,[SYMBOL,INT,INT])
//创建一个10行的常规内存表
t=table(100:10,`sym`id`val,[SYMBOL,INT,INT])
select * from t
sym id val
--- -- ---
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0 table函数也允许通过已有的数据来创建一个常规内存表。下例是通过多个数组来创建。
sym=`A`B`C`D`E
id=5 4 3 2 1
val=52 64 25 48 71
t=table(sym,id,val)常规内存表是DolphinDB中应用最频繁的数据结构之一,仅次于数组。SQL语句的查询结果,分布式查询的中间结果都存储在常规内存表中。当系统内存不足时,该表并不会自动将数据溢出到磁盘,而是Out Of Memory异常。因此我们进行各种查询和计算时,要注意中间结果和最终结果的size。当某些中间结果不再需要时,请及时释放。关于常规内存表增删改查的各种用法,可以参考另一份教程内存分区表加载和操作。
1.2 键值内存表
键值内存表是DolphinDB中支持主键的内存表。通过指定表中的一个或多个字段作为主键,可以唯一确定表中的记录。键值内存表支持增删改查等操作,但是主键值不允许更新。键值内存表通过哈希表来记录每一个键值对应的行号,因此对于基于键值的查找和更新具有非常高的效率。
使用keyedTable函数可创建键值内存表。该函数与table函数非常类似,唯一不同之处是增加了一个参数指明键值列的名称。
//创建空的键值内存表,主键由sym和id字段组成
t=keyedTable(`sym`id,1:0,`sym`id`val,[SYMBOL,INT,INT])
//使用向量创建键值内存表,主键由sym和id字段组成
sym=`A`B`C`D`E
id=5 4 3 2 1
val=52 64 25 48 71
t=keyedTable(`sym`id,sym,id,val)注意:指定容量和初始大小创建键值内存表时,初始大小必须为0。
我们也可以通过keyedTable函数将常规内存表转换为键值内存表。例如:
sym=`A`B`C`D`E
id=5 4 3 2 1
val=52 64 25 48 71
tmp=table(sym, id, val)
t=keyedTable(`sym`id, tmp)- 数据插入和更新的特点
往键值内存表中添加新纪录时,系统会自动检查新记录的主键值。如果新记录中的主键值不存在于表中,那么往表中添加新的记录;如果新记录的主键值与已有记录的主键值重复时,会更新表中该主键值对应的记录。请看下面的例子。
首先,往空的键值内存表中插入新记录,新记录中的主键值为AAPL, IBM和GOOG。
t=keyedTable(`sym,1:0,`sym`datetime`price`qty,[SYMBOL,DATETIME,DOUBLE,DOUBLE]);
insert into t values(`APPL`IBM`GOOG,2018.06.08T12:30:00 2018.06.08T12:30:00 2018.06.08T12:30:00,50.3 45.6 58.0,5200 4800 7800);
t;
sym datetime price qty
---- ------------------- ----- ----
APPL 2018.06.08T12:30:00 50.3 5200
IBM 2018.06.08T12:30:00 45.6 4800
GOOG 2018.06.08T12:30:00 58 7800再次往表中插入一批主键值为AAPL, IBM和GOOG的新记录。
insert into t values(`APPL`IBM`GOOG,2018.06.08T12:30:01 2018.06.08T12:30:01 2018.06.08T12:30:01,65.8 45.2 78.6,5800 8700 4600);
t;
sym datetime price qty
---- ------------------- ----- ----
APPL 2018.06.08T12:30:01 65.8 5800
IBM 2018.06.08T12:30:01 45.2 8700
GOOG 2018.06.08T12:30:01 78.6 4600可以看到,表中记录条数没有增加,但是主键对应的记录已经更新。
继续往表中插入一批新记录,新记录本身包含了重复的主键值MSFT。
可以看到,表中有且仅有一条主键值为MSFT的记录。
(1)键值表对单行的更新和查询有非常高的效率,是数据缓存的理想选择。与redis相比,DolphinDB中的键值内存表兼容SQL的所有操作,可以完成根据键值更新和查询以外的更为复杂的计算。
(2)作为时间序列聚合引擎的输出表,实时更新输出表的结果。具体请参考教程使用DolphinDB计算K线。
1.3 流数据表
流数据表顾名思义是为流数据设计的内存表,是流数据发布和订阅的媒介。流数据表具有天然的流表对偶性(Stream Table Duality),发布一条消息等价于往流数据表中插入一条记录,订阅消息等价于将流数据表中新到达的数据推向客户端应用。对流数据的查询和计算都可以通过SQL语句来完成。
使用streamTable函数可创建流数据表。streamTable的用法和table函数完全相同。
//创建空的流数据表
t=streamTable(1:0,`sym`id`val,[SYMBOL,INT,INT])
//使用向量创建流数据表
sym=`A`B`C`D`E
id=5 4 3 2 1
val=52 64 25 48 71
t=streamTable(sym,id,val)我们也可以使用streamTable函数将常规内存表转换为流数据表。例如:
sym=`A`B`C`D`E
id=5 4 3 2 1
val=52 64 25 48 71
tmp=table(sym, id, val)
t=streamTable(tmp)流数据表也支持创建单个键值列,可以通过函数keyedStreamTable来创建。但与keyed table的设计目的不同,keyedstreamtable的目的是为了在高可用场景(多个发布端同时写入)下,避免重复消息。通常key就是消息的ID。
- 数据操作特点
由于流数据具有一旦生成就不会发生变化的特点,因此流数据表不支持更新和删除记录,只支持查询和添加记录。流数据通常具有连续性,而内存是有限的。为解决这个矛盾,流数据表引入了持久化机制,在内存中保留最新的一部分数据,更旧的数据持久化在磁盘上。当用户订阅旧的数据时,直接从磁盘上读取。启用持久化,使用函数enableTableShareAndPersistence,具体参考流数据教程。
共享的流数据表在流计算中发布数据。订阅端通过subscribeTable函数来订阅和消费流数据。
1.4 MVCC内存表
MVCC内存表存储了多个版本的数据,当多个用户同时对MVCC内存表进行读写操作时,互不阻塞。MVCC内存表的数据隔离采用了快照隔离模型,用户读取到的是在他读之前就已经存在的数据,即使这些数据在读取的过程中被修改或删除了,也对之前正在读的用户没有影响。这种多版本的方式能够支持用户对内存表的并发访问。需要说明的是,当前的MVCC内存表实现比较简单,更新和删除数据时锁定整个表,并使用copy-on-write技术复制一份数据,因此对数据删除和更新操作的效率不高。在后续的版本中,我们将实现行级的MVCC内存表。
使用mvccTable函数创建MVCC内存表。例如:
//创建空的流数据表
t=mvccTable(1:0,`sym`id`val,[SYMBOL,INT,INT])
//使用向量创建流数据表
sym=`A`B`C`D`E
id=5 4 3 2 1
val=52 64 25 48 71
t=mvccTable(sym,id,val)我们可以将MVCC内存表的数据持久化到磁盘,只需创建时指定持久化的目录和表名即可。例如,
t=mvccTable(1:0,`sym`id`val,[SYMBOL,INT,INT],"/home/user1/DolphinDB/mvcc","test")系统重启后,我们可以通过loadMvccTable函数将磁盘中的数据加载到内存中。
loadMvccTable("/home/user1/DolphinDB/mvcc","test")我们也可以使用mvccTable函数将常规内存表转换为MVCC内存表。
sym=`A`B`C`D`E
id=5 4 3 2 1
val=52 64 25 48 71
tmp=table(sym, id, val)
t=mvccTable(tmp)当前的MVCC内存表适用于读多写少,并有持久化需要的场景。譬如动态的配置系统,需要持久化配置项,配置项的改动不频繁,已新增和查询操作为主,非常适合MVCC表。
2. 共享内存表
DolphinDB中的内存表默认只在创建内存表的会话中使用,不支持多用户多会话的并发操作,当然对别的会话也不可见。如果希望创建的内存表能被别的用户使用,保证多用户并发操作的安全,必须共享内存表。4种类型的内存表均可共享。在DolphinDB中,我们使用share命令将内存表共享。
t=table(1..10 as id,rand(100,10) as val)
share t as st
//或者share(t,`st)上面的代码将表t共享为表st。
使用undef函数可以删除共享表。
undef(`st,SHARED)2.1 保证对所有会话可见
内存表仅在当前会话可见,在其他会话中不可见。共享之后,其他会话可以通过访问共享变量来访问内存表。例如,我们在当前会话中把表t共享为表st。
t=table(1..10 as id,rand(100,10) as val)
share t as st我们可以在其他会话中访问变量st。例如,往共享表st插入一条数据。
insert into st values(11,200)
select * from st
id val
-- ---
1 1
2 53
3 13
4 40
5 61
6 92
7 36
8 33
9 46
10 26
11 200切换到原来的会话,我们可以发现,表t中也增加了一条记录。
select * from t
id val
-- ---
1 1
2 53
3 13
4 40
5 61
6 92
7 36
8 33
9 46
10 26
11 2002.2 保证线程安全
在多线程的情况下,内存表中的数据很容易被破坏。共享则提供了一种保护机制,能够保证数据安全,但同时也会影响系统的性能。
常规内存表、流数据表和MVCC内存表都支持多版本模型,允许多读一写。具体说,读写互不阻塞,写的时候可以读,读的时候可以写。读数据时不上锁,允许多个线程同时读取数据,读数据时采用快照隔离(snapshot isolation)。写数据时必须加锁,同时只允许一个线程修改内存表。写操作包括添加,删除或更新。添加记录一律在内存表的末尾追加,无论内存使用还是CPU使用均非常高效。常规内存表和MVCC内存表支持更新和删除,且采用了copy-on-write技术,也就是先复制一份数据(构成一个新的版本),然后在新版本上进行删除和修改。由此可见删除和更新操作无论内存和CPU消耗都比较高。当删除和更新操作很频繁,读操作又比较耗时(不能快速释放旧的版本),容易导致OOM异常。
键值内存表写入时需维护内部索引,读取时也需要根据索引获取数据。因此键值内存表共享采用了不同的方法,无论读写都必须加锁。写线程和读线程,多个写线程之间,多个读线程之间都是互斥的。对键值内存表尽量避免耗时的查询或计算,否则会使其它线程长时间处于等待状态。
3. 分区内存表
当内存表数据量较大时,我们可以对内存表进行分区。分区后一个大表有多个子表(tablet)构成,大表不使用全局锁,锁由每个子表独立管理,这样可以大大增加读写并发能力。DolphinDB支持对内存表进行值分区、范围分区、哈希分区和列表分区,不支持组合分区。在DolphinDB中,我们使用函数createPartitionedTable创建内存分区表。
- 创建分区常规内存表
t=table(1:0,`id`val,[INT,INT])
db=database("",RANGE,0 101 201 301)
pt=db.createPartitionedTable(t,`pt,`id)- 创建分区键值内存表
kt=keyedTable(1:0,`id`val,[INT,INT])
db=database("",RANGE,0 101 201 301)
pkt=db.createPartitionedTable(t,`pkt,`id)- 创建分区流数据表
创建分区流数据表时,需要传入多个流数据表作为模板,每个流数据表对应一个分区。写入数据时,直接往这些流表中写入;而查询数据时,需要查询分区表。
st1=streamTable(1:0,`id`val,[INT,INT])
st2=streamTable(1:0,`id`val,[INT,INT])
st3=streamTable(1:0,`id`val,[INT,INT])
db=database("",RANGE,1 101 201 301) pst=db.createPartitionedTable([st1,st2,st3],`pst,`id)
st1.append!(table(1..100 as id,rand(100,100) as val))
st2.append!(table(101..200 as id,rand(100,100) as val))
st3.append!(table(201..300 as id,rand(100,100) as val))
select * from pst- 创建分区MVCC内存表
与创建分区流数据表一样,创建分区MVCC内存表,需要传入多个MVCC内存表作为模板。每个表对应一个分区。写入数据时,直接往这些表中写入;而查询数据时,需要查询分区表。
mt1=mvccTable(1:0,`id`val,[INT,INT])
mt2=mvccTable(1:0,`id`val,[INT,INT])
mt3=mvccTable(1:0,`id`val,[INT,INT])
db=database("",RANGE,1 101 201 301)
pmt=db.createPartitionedTable([mt1,mt2,mt3],`pst,`id)
mt1.append!(table(1..100 as id,rand(100,100) as val))
mt2.append!(table(101..200 as id,rand(100,100) as val))
mt3.append!(table(201..300 as id,rand(100,100) as val))
select * from pmt由于分区内存表不使用全局锁,创建以后不能再动态增删子表。
3.1 增加查询的并发性
分区表增加查询的并发性有三层含义:(1)键值表在查询时也需要加锁,分区表由子表独立管理锁,相当于把锁的粒度变细了,因此可以增加读的并发性;(2)批量计算时分区表可以并行处理每个子表;(3)如果SQL查询的过滤指定了分区字段,那么可以缩小分区范围,避免全表扫描。
以键值内存表为例,我们对比在分区和不分区的情况下,并发查询的性能。首先,创建模拟数据集,一共包含500万行数据。
n=5000000
id=shuffle(1..n)
qty=rand(1000,n)
price=rand(1000.0,n)
kt=keyedTable(`id,id,qty,price)
share kt as skt
id_range=cutPoints(1..n,20)
db=database("",RANGE,id_range)
pkt=db.createPartitionedTable(kt,`pkt,`id).append!(kt)
share pkt as spkt我们在另外一台服务器上模拟10个客户端同时查询键值内存表。每个客户端查询10万次,每次查询一条数据,统计每个客户端查询10万次的总耗时。
def queryKeyedTable(tableName,id){
for(i in id){
select * from objByName(tableName) where id=i
}
}
conn=xdb("192.168.1.135",18102,"admin","123456")
n=5000000
jobid1=array(STRING,0)
for(i in 1..10){
rid=rand(1..n,100000)
s=conn(submitJob,"evalQueryUnPartitionTimer"+string(i),"",evalTimer,queryKeyedTable{`skt,rid})
jobid1.append!(s)
}
time1=array(DOUBLE,0)
for(j in jobid1){
time1.append!(conn(getJobReturn,j,true))
}
jobid2=array(STRING,0)
for(i in 1..10){
rid=rand(1..n,100000)
s=conn(submitJob,"evalQueryPartitionTimer"+string(i),"",evalTimer,queryKeyedTable{`spkt,rid})
jobid2.append!(s)
}
time2=array(DOUBLE,0)
for(j in jobid2){
time2.append!(conn(getJobReturn,j,true))
}time1是10个客户端查询未分区键值内存表的耗时,time2是10个客户端查询分区键值内存表的耗时,单位是毫秒。
time1
[6719.266848,7160.349678,7271.465094,7346.452625,7371.821485,7363.87979,7357.024299,7332.747157,7298.920972,7255.876976]
time2
[2382.154581,2456.586709,2560.380315,2577.602019,2599.724927,2611.944367,2590.131679,2587.706832,2564.305815,2498.027042]可以看到,每个客户端查询分区键值内存表的耗时要低于查询未分区内存表的耗时。
查询未分区的内存表,可以保证快照隔离。但查询一个分区内存表,不再保证快照隔离。如前面所说分区内存表的读写不使用全局锁,一个线程在查询时,可能另一个线程正在写入而且涉及多个子表,从而可能读到一部分写入的数据。
3.2 增加写入的并发性
以分区的常规内存表为例,我们可以同时往不同的分区写入数据。
t=table(1:0,`id`val,[INT,INT])
db=database("",RANGE,1 101 201 301)
pt=db.createPartitionedTable(t,`pt,`id)
def writeData(mutable t,id,batchSize,n){
for(i in 1..n){
idv=take(id,batchSize)
valv=rand(100,batchSize)
tmp=table(idv,valv)
t.append!(tmp)
}
}
job1=submitJob("write1","",writeData,pt,1..100,1000,1000)
job2=submitJob("write2","",writeData,pt,101..200,1000,1000)
job3=submitJob("write3","",writeData,pt,201..300,1000,1000)上面的代码中,同时有3个线程对pt的3个不同的分区进行写入。需要注意的是,我们要避免同时对相同分区进行写入。例如,下面的代码可能会导致系统崩溃。
job1=submitJob("write1","",writeData,pt,1..300,1000,1000)
job2=submitJob("write2","",writeData,pt,1..300,1000,1000)上面的代码定义了两个写入线程,并且写入的分区相同,这样会破坏内存。为了保证每个分区数据的安全性和一致性,我们可将分区内存表共享。这样即可定义多个线程同时对相同分区分入。
share pt as spt
job1=submitJob("write1","",writeData,spt,1..300,1000,1000)
job2=submitJob("write2","",writeData,spt,1..300,1000,1000)
4. 数据操作比较
4.1 增删改查
下表总结了4种类型内存表在共享/分区的情况下支持的增删改查操作。
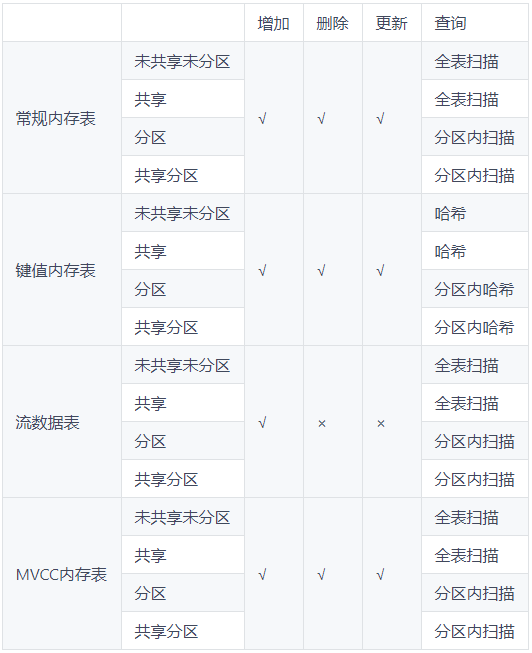
- 常规内存表、键值内存表、MVCC内存表都支持增删改查操作,流数据表仅支持增加数据和查询,不支持删除和更新操作。
- 对于键值内存表,如果查询的过滤条件中包含主键,查询的性能会得到明显提升。
- 对于分区内存表,如果查询的过滤条件中包含分区列,系统能够缩小要扫描的分区范围,从而提升查询的性能。
4.2 并发性
在没有写入的情况下,所有内存表都允许多个线程同时查询。在有写入的情况下,4种内存表的并发性有所差异。下表总结了4种内存表在共享/分区的情况下支持的并发读写情况。
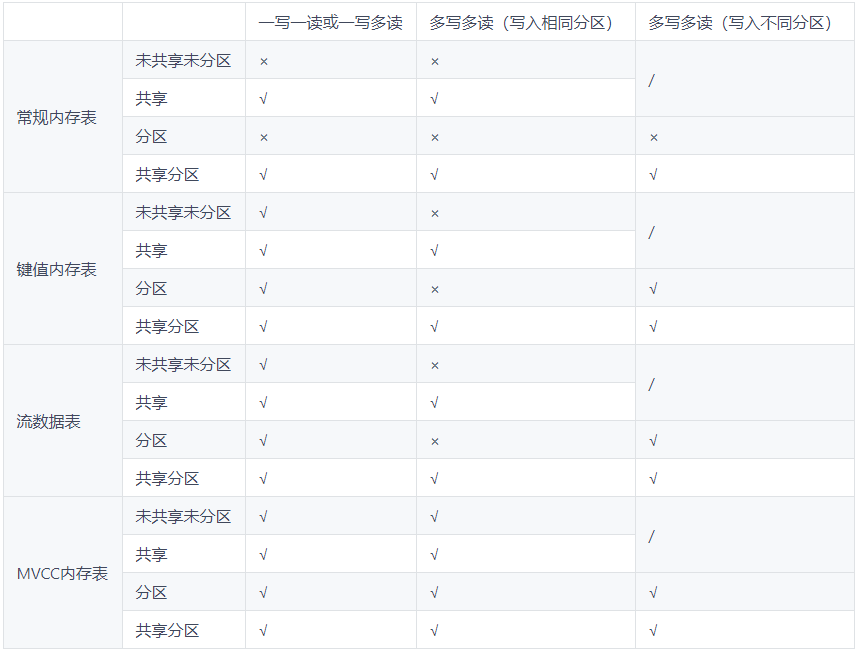
- 共享表允许并发读写。
- 对于没有共享的分区表,不允许多线程对相同分区同时写入的。
4.3 持久化
- 常规内存表和键值内存表不支持数据持久化。一旦节点重启,内存中的数据将全部丢失。
- 只有空的流数据表才支持数据持久化。要对流数据表进行持久化,首先要配置流数据持久化的目录persistenceDir,再使用enableTableShareAndPersistence使用将流数据表共享,并持久化到磁盘上。例如,将流数据表t共享并持久化到磁盘上。
t=streamTable(1:0,`id`val,[INT,INT])
enableTableShareAndPersistence(t,`st)流数据表启用了持久化后,内存中仍然会保留流数据表中部分最新的记录。默认情况下,内存会保留最新的10万条记录。我们也可以根据需要调整这个值。
流数据表持久化可以设定采用异步/同步、压缩/不压缩的方式。通常情况下,异步模式能够实现更高的吞吐量。
系统重启后,再次执行enableTableShareAndPersistence函数,会将磁盘中的所有数据加载到内存。
- MVCC内存表支持持久化。在创建MVCC内存表时,我们可以指定持久化的路径。例如,创建持久化的MVCC内存表。
t=mvccTable(1:0,`id`val,[INT,INT],"/home/user/DolphinDB/mvccTable")
t.append!(table(1..10 as id,rand(100,10) as val))系统重启后,我们可以使用loadMvccTable函数将磁盘中的数据加载到内存中。例如:
t=loadMvccTable("/home/user/DolphinDB/mvccTable","t")5. 表结构操作比较
内存表的结构操作包括新增列、删除列、修改列(内容和数据类型)以及调整列的顺序。下表总结了4种类型内存表在共享/分区的情况下支持的结构操作。
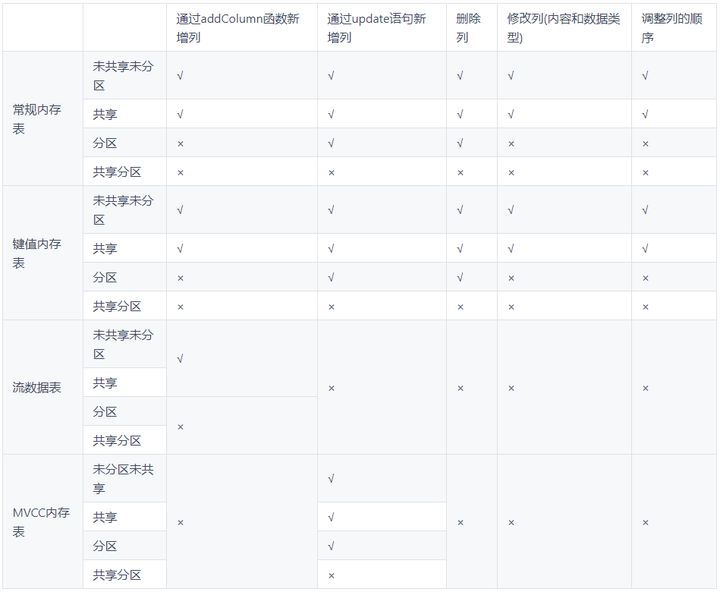
- 分区表以及MVCC内存表不能通过addColumn函数新增列。
- 分区表可以通过update语句来新增列,但是流数据表不允许修改,因此流数据表不能通过update语句来新增列。
DolphinDB支持4种类型内存表,还引入了共享和分区的概念,基本能够满足内存计算和流计算的各种需求。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK