

论学好《编译原理》对玩游戏的重要性
source link: https://zhuanlan.zhihu.com/p/197979867
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
论学好《编译原理》对玩游戏的重要性
源代码链接:
阿里云学生机用来搭建求生服务器最合适不过了,CPU、内存、硬盘、带宽都够一个小队开黑用的,不多也不少,刚好够用。但是麻烦的是每次换地图都得手动把vpk包传到服务器上,然后还得在游戏里用命令行换图,换图之前得先用工具查一下vpk里的配置文件才能知道地图关卡代号是啥,挺麻烦的。
但是近期我找到了一个好办法,那就是做一个后台管理网站,这样就算没有我,队里每个人也可以轻松搞定上传vpk+切地图这个操作了。
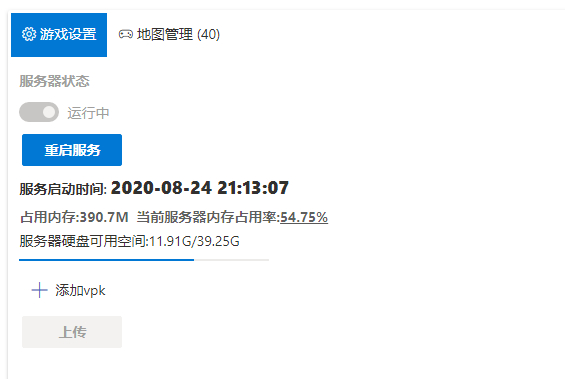
单纯的vpk上传是很简单的,麻烦的是提取vpk种的关卡信息,vpk中的配置文件使用的是一种被称为Valve KeyValues的格式,官方文档链接:
KeyValues - Valve Developer Communitydeveloper.valvesoftware.com这种格式本质上等价于json,source引擎开发的时候应该还不流行用json,所以v社就用了自家定义的格式,要把它序列化成json就得你自己想办法了。
这是从文档中抄的一段定义:
可以看得出来解析这个格式并不麻烦,词法、语法、语义三个步骤依次展开就行了,理论上最终可以从一堆plain text中提取得到一个dict对象,这也是我的目标。
但是在动手做这件事之前,我们需要先复习一下编译原理。当年我的课设就是做了一个LR(1)解析器,现在有了yacc就不用干那么多dirty work了,事实上yacc只是自动帮你处理了文法产生式,语义子程序还是得靠你自己编。
先看一下成果,预期效果就是这样,text->dict
词法分析很简单,直接用lex搞定,我们只需要定义六种基本token就行了,顺带还可以把注释去掉。六种token分别是标识符、字符串、整数、小数、左括号、右括号
tokens = (
'ID',
'STRING',
'INT',
'FLOAT',
'LPAREN',
'RPAREN'
)
t_ignore = ' \t'
t_ignore_comment= r'//.*'
t_ignore_comment_2 = r'/\*.*\*/'
t_ID = r'[a-zA-Z_][a-zA-Z_0-9]*'
t_STRING = r'\".*?\"'
t_INT = r'\d+'
t_FLOAT = r'-?\d+(\.\d+)*'
t_LPAREN = r'\{'
t_RPAREN = r'\}'语法和语义
这个步骤使用yacc来完成,这一步骤最难的是文法产生式的编写,一次性写出能被LALR(1)接受并且没有冲突的文法是很难的。但是好在Valve KeyValues的规则并不复杂,就算产生了一些移进-规约冲突,按照yacc默认的规则也就是一律按照移进处理,也是能行无bug的。
首先是最基础的一个产生式,可以称为万物起源,除了括号外的4种token都可以规约为字典中的键或者值。语义子程序只需要做的是提取出必要的信息,比如说字符串去掉引号,整数、小数则将字符串进行转化等
def p_expression_key(p):
'''key_or_value : ID
| STRING
| INT
| FLOAT
'''
target=p.slice[1]
if target.type=="STRING":
p[1]= p[1].replace("\"","")
elif target.type=="INT":
p[1]= int(p[1])
elif target.type=="FLOAT":
if p[1].count(".")==1:
p[1]= float(p[1])
p[0] = p[1]接下来这一条也很简单,没啥好说的。我们都知道字典是由键值对构成的,每两个相邻的键或者值,都可以规约成为一个键值对,键值对在语义子程序中是按字典的形式保存的
def p_expression_key_value_pair(p):
'''key_value_pair : key_or_value key_or_value'''
p[0] = {
p[1]:p[2]
}接下来是最后也是最复杂的一条产生式,这一条将规约得到最终的字典,但是它有很多种子情况,我们一一来看:
- 键值对->字典
- 两个相邻的字典->字典
- 键值对+字典->字典
这三种很好理解,用闭包思维来解决如何把一个字典中的多个键值对合并为一个字典的问题
- 键+左括号+字典+右括号->字典。这一种对应的是字典作为键值对中的值的情况
- 键+左括号+右括号->字典。这一种是上一种的例外情况,有些键值对的值为空,但是也要进行规约
- 键+左括号+字典->字典。这一种是纯粹的处理bug,因为有的vpk制作者就是会漏掉右边的括号,加上这条规则可以增强兼容性
然后语义子程序是很简单的,就是根据各种情况得到一个dict
def p_expression_dictionary(p):
'''dictionary : key_or_value LPAREN dictionary RPAREN
| key_or_value LPAREN RPAREN
| key_or_value LPAREN dictionary
| key_value_pair dictionary
| dictionary dictionary
| key_value_pair
'''
if len(p)==5:
p[0]={
p[1]:p[3]
}
elif len(p)==4:
if p.slice[3].type=="RPAREN":
p[0]={}
else:
p[0]={
p[1]:p[3]
}
elif len(p)==3:
p[0]=dict(p[1].items()+p[2].items())
else:
p[0]=p[1]这样我们就成功地使用了lex+yacc解决了vpk包的配置文件解析问题
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK