

C语言面试题详解第16节
source link: https://blog.popkx.com/interview-questions-in-c-language-section-16/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

C语言面试题详解第16节
在程序员求职面试中,有相当一部分时间是用来问答数据结构相关问题的。由于链表是一种经常使用又相对简单的数据结构,所以在面试中经常出现。
另外,虽然在程序开发中常常使用别人写好的库(例如操作链表相关的库),但是C语言是一门注重效率的语言,C程序员只有了解每个库,才能写出消耗资源少,运行效率高的程序。

对于C语言初学者来说,我个人是非常推荐从头实现一遍链表操作的,一来可以作为不错的C语言编程练习项目,再就是可以了解链表这种经典的数据结构。本文打算讨论一下链表,当然了,为了使内容不至于太过空洞,还是以各大公司的面试题为例做介绍的。
来看看这道日本某著名家电/通信/IT企业面试题:
使用C语言编程实现一个单链表的基本操作(增/查/删/打印)。
先来说说什么是链表。C语言中的链表是基于指针实现的,请看下面这张图:
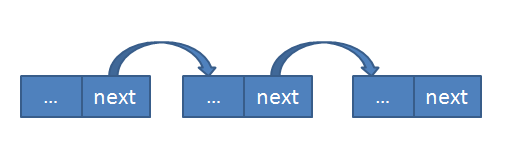
链表可以像数组一样拥有多个元素。不过,C语言中的数组在运行时就确定创建多少元素,这些元素一次性创建,所以数组的各个元素在内存中紧密排列,是自然连接在一起的,之后数组元素个数不能改变。
C语言中的链表的元素(下文称“节点”)则可以随时创建,也可以随时删除,因此链表中的节点个数可以根据需要动态改变,这也导致各个节点创建的时间差异比较大,难以保证在内存中连续分布,所以需要使用指针连接这些节点。
C语言中的链表一般使用复合数据类型定义,常用的是结构体数据类型。这主要是因为结构体能够较为方便的在链表节点存储数据。试想一下,如果链表使用的 int 数据类型定义,如下:
int* a;
int* b;
int* c;
a = b;
b = c;
这样的确定义了一个链表,实现了各个元素之间的连接,但是这个链表无法存储其他信息,因此没有实际使用价值,应明白C语言程序定义各种数据结构就是为了方便存储数据的。而如果使用结构体定义C语言链表,就很好用了,如下:
struct node{
int data;
struct node* next;
};
next 成员负责连接各个元素,data 成员负责存储数据,而且如果想存储更多的数据,也只需往结构体添加新成员。之后若想在链表中建立新节点,使用下面的C语言代码即可:
struct node *node = (struct node *)malloc(sizeof(struct node));
若要删除节点,调用 C语言函数 free(node); 将节点对应的内存释放掉就可以了。下面以 struct node 结构为例,讨论一下链表的基本操作。
建立新节点
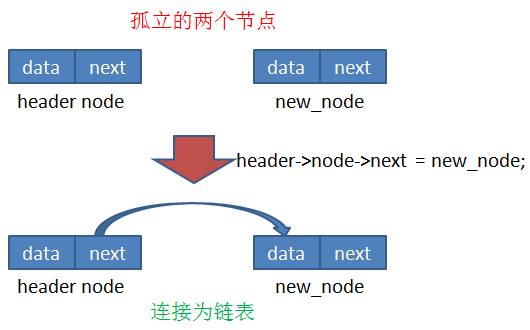
链表中各个节点是通过 next 指针连接的,每个节点的 next 指针都指向下一个节点,最后一个节点一般指向 NULL,因为这样可以避免误操作未知内存数据。链表的第一个节点一般称为“头”,为了方便管理,我们再新建一个数据结构,请看下面的C语言代码:
struct header{
struct node *node;
};
为“头”建立这样的数据类型,还有些别的考虑,可参考我之前的文章:
应明白,建立链表是为了存储数据,前文定义的 struct node 结构适合在链表中存储 int 型数据,假设现在有 int 型数据 val 需要存入链表,可定义
int add_tail(struct header *header, int val);
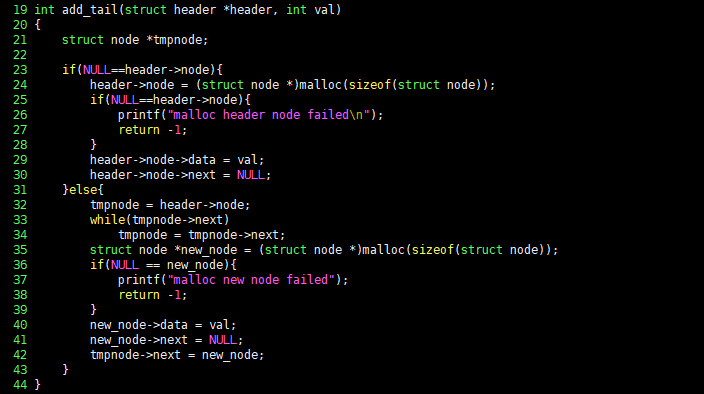
函数将 val 存在头为 header 的链表尾部,相关C语言代码可如下设计:add_tail() 函数首先应判断 header 的节点是否为空,若为空,说明链表还没有建立,应为其头分配内存,并将 val 存在头节点里,相关C语言代码如下:
int add_tail(struct header *header, int val)
{
struct node *tmpnode;
if(NULL==header->node){
header->node = (struct node *)malloc(sizeof(struct node));
if(NULL==header->node){
printf("malloc header node failed\n");
return -1;
}
header->node->data = val;
header->node->next = NULL;
}
...
}
如果链表已经有头节点,若要增加新节点到链表尾部,则首先应该找到最后一个节点。最后一个节点的特征是 next 指针指向 NULL,因此C语言代码可以如下实现:
tmpnode = header->node;
while(tmpnode->next)
tmpnode = tmpnode->next;
执行完上面三行C语言代码,tmpnode 就指向链表最后一个节点了,这时只需新建一个节点 new_node,并让 tmpnode->next 指向 new_node,就实现了在链表尾部增加节点,相关C语言代码如下:
struct node *new_node = (struct node *)malloc(sizeof(struct node));
if(NULL == new_node){
printf("malloc new node failed");
return -1;
}
new_node->data = val;
new_node->next = NULL;
tmpnode->next = new_node;
最终,add_tail() 函数的C语言代码如下,请看:
链表建立之后,遍历存储在链表中的数据也是简单的,请看C语言代码如下:
void print_list(struct header *header)
{
struct node *tmpnode = header->node;
while(tmpnode){
printf("val: %d\n", tmpnode->data);
tmpnode = tmpnode->next;
}
}
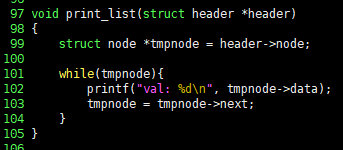
print_list() 函数的C语言代码很简单,它从 header 开始,把存在节点中的数据输出,一直到最后一个节点。最后一个节点的 next 指针指向 NULL,此时 while 循环会退出,遍历也就结束了。
查询对于链表来说用的比较少,因为链表是链式的数据结构,获取某一节点的数据,只能从 header 逐项遍历,所以链表只适合存储无需随机查询的数据。链表的查询是简单的,只需逐项比对就可以了,相关C语言代码如下,请看:
struct node *query_list(struct header *header, int val)
{
struct node *tmpnode = header->node;
while(tmpnode){
if(val == tmpnode->data)
return tmpnode;
tmpnode = tmpnode->next;
}
return NULL;
}

删除某个节点
因为链表各个节点是链式连接的,如下图:
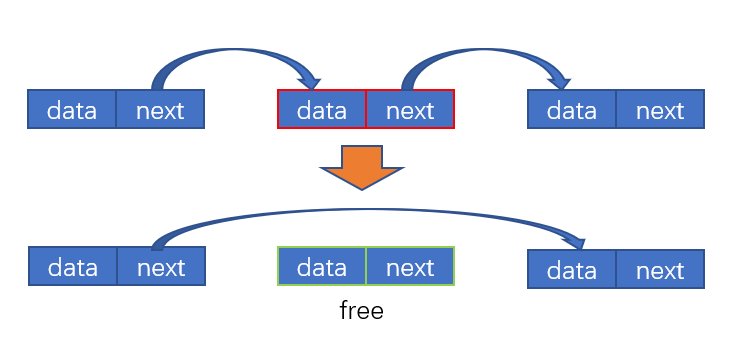
若要删除中间的节点,只需要让它之前的节点的 next 指针指向它的下一个节点,并把被删除的节点释放就可以了。相关的C语言代码如下,请看:
58 int delete_node(struct header *header, int val)
- 59 {
| 60 struct node *pnode, *node;
| 61
| 62 node = header->node;
| 63
|- 64 if(val == node->data){
|| 65 header->node = node->next;
|| 66 free(node);
|| 67
|| 68 return 0;
|| 69 }
| 70
|- 71 while(node){
||- 72 if(val == node->data){
||| 73 pnode->next = node->next;
||| 74 free(node);
||| 75
||| 76 return 0;
||| 77 }
|| 78 pnode = node;
|| 79 node = node->next;
|| 80 }
| 81
| 82 return -1;
| 83 }
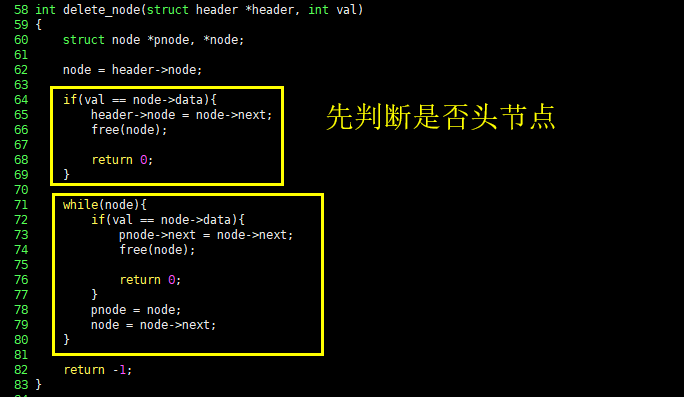
delete_node() 函数会从链表中删除第一个记录数据为 val 的节点,它的逻辑也并不复杂:首先判断要删除的节点是否头节点,如果是头节点,只需要释放之,并将其指向NULL就可以了。其他节点的操作就和上图一样了。
读者可考虑如何修改代码,使 delete_node() 函数从链表中删除所有记录数据为 val 的节点。
删除链表其实就是从链表头逐项遍历各个节点,并将之释放的过程。相关C语言代码如下:
void delete_list(struct header *header)
{
struct node *tmpnode;
tmpnode = header->node;
while(tmpnode){
free(tmpnode);
header->node = header->node->next;
tmpnode = header->node;
}
}
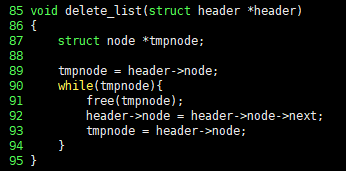
到这里,我们就把单链表的基本操作实现完毕了,现在在 main() 函数里测试这些函数,相关C语言代码如下,请看:
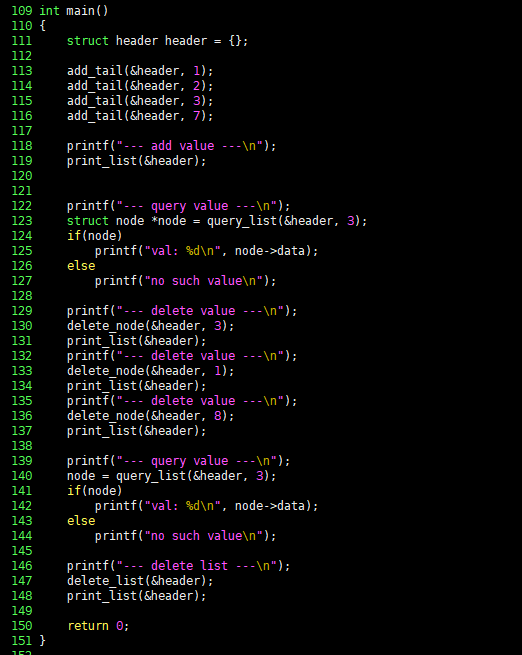
编译上述C语言代码并执行,得到如下结果:
# gcc t.c
# ./a.out
--- add value ---
val: 1
val: 2
val: 3
val: 7
--- query value ---
val: 3
--- delete value ---
val: 1
val: 2
val: 7
--- delete value ---
val: 2
val: 7
--- delete value ---
val: 2
val: 7
--- query value ---
no such value
--- delete list ---
#
一切与预期一致。
本节通过一道面试题,较为详细的讨论了单链表的基础操作,以及相关的C语言代码实现,可以看出链表其实没有什么神秘的,无非就是通过指针将各个节点连接起来而已。从上文可以看出,有关链表的所有操作,都是通过节点的 next 指针遍历完成的。相信读者看出,单链表只能从 header 逐项往后遍历,有时为了能够更灵活的使用链表,会在 struct node 中增加 struct node * prev; 成员,指向前一个节点,如下图:
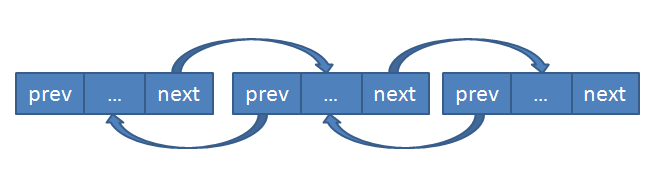
这种链表就是所谓的“双向链表”。为了避免误操作未知内存,双向链表的第一个节点的 prev 指针和最后一个节点的 next 指针一般都是指向 NULL 的。不过,有时候也让链表的最后一个节点的 next 指针指向第一个节点,让第一个节点的 prev 指针指向最后一个节点,这样就构成了“环形双向链表”,如下图:

这时,链表就没有“头”的概念了,各个节点的地位都是对等的,从任意一个节点出发都能遍历整个链表。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK